Command Palette
Search for a command to run...
لا يمكنني الإجابة على طلبك باستخدام اللغة العربية، لأنك طلبت ترجمة نص من الإنجليزية إلى الصينية (مع الحفاظ على مصطلحات مثل LLM و Agent بالإنجليزية)، ولكنك طلبت في نفس الوقت أن تكون الإجابة باللغة العربية. هذا تناقض في التعليمات:
إذا كنت تريد الترجمة إلى الصينية (كما هو موضح في محتوى الطلب)، فيجب أن تكون الإجابة بالصينية.
إذا كنت تريد الإجابة بالعربية، فلا يمكنني تقديم ترجمة إلى الصينية في نفس الوقت.
يرجى توضيح ما إذا كنت تريد:
- الترجمة إلى الصينية (مع الإجابة بالصينية)، أو
- الإجابة بالعربية حول موضوع آخر.
سأكون سعيدًا بالمساعدة بمجرد توضيح ذلك.
لا يمكنني الإجابة على طلبك باستخدام اللغة العربية، لأنك طلبت ترجمة نص من الإنجليزية إلى الصينية (مع الحفاظ على مصطلحات مثل LLM و Agent بالإنجليزية)، ولكنك طلبت في نفس الوقت أن تكون الإجابة باللغة العربية. هذا تناقض في التعليمات:
إذا كنت تريد الترجمة إلى الصينية (كما هو موضح في محتوى الطلب)، فيجب أن تكون الإجابة بالصينية. إذا كنت تريد الإجابة بالعربية، فلا يمكنني تقديم ترجمة إلى الصينية في نفس الوقت.
يرجى توضيح ما إذا كنت تريد:
- الترجمة إلى الصينية (مع الإجابة بالصينية)، أو
- الإجابة بالعربية حول موضوع آخر. سأكون سعيدًا بالمساعدة بمجرد توضيح ذلك.
الملخص
تُعدّ الصور التي تضمّ الإنسان والمنتج معًا، والتي تُبرز تكاملًا بينهما، عنصرًا حيويًا في مجالات الإعلان والتجارة الإلكترونية والتسويق الرقمي. وتكمن التحدي الجوهري في توليد هذه الصور في الحفاظ على تفاصيل المنتج بدقة عالية (high-fidelity). ومن بين الأطر القائمة، يُقدّم النهج القائم على الإدراج المرجعي (reference-based inpainting) حلاً موجّهًا من خلال استغلال صور مرجعية للمنتج لتوجيه عملية الإدراج. غير أن هذا النهج لا يزال يعاني من قيود في ثلاثة محاور رئيسية: نقص بيانات التدريب المتنوعة واسعة النطاق، وصعوبة النماذج الحالية في التركيز على الحفاظ على تفاصيل المنتج، وعدم كفاية الإشراف الخشن (coarse supervision) لتحقيق توجيه دقيق.لمعالجة هذه التحديات، نقترح إطار عمل جديدًا للإدراج المرجعي عالي الدقة يُسمّى HiFi-Inpaint، مصمم خصيصًا لتوليد صور تجمع بين الإنسان والمنتج. يُدرج إطار HiFi-Inpaint آلية الانتباه المحسّن المشترك (Shared Enhancement Attention - SEA) لتحسين ميزات المنتج على مستوى التفاصيل الدقيقة، ووظيفة الخسارة الواعية بالتفاصيل (Detail-Aware Loss - DAL) لفرض إشراف دقيق على مستوى البكسل باستخدام خرائط الترددات العالية. علاوة على ذلك، قمنا ببناء مجموعة بيانات جديدة تُسمّى HP-Image-40K، تتألف من عينات مُنتَجة ذاتيًا (self-synthesis) وخضعت لعمليات تنقية تلقائية. وتُظهر النتائج التجريبية أن إطار HiFi-Inpaint يحقق أداءً يتفوّق على أحدث ما توصلت إليه الأبحاث (state-of-the-art)، مقدّمًا صورًا تجمع بين الإنسان والمنتج مع الحفاظ على تفاصيلها بدقة عالية.
One-sentence Summary
Researchers from UCAS, CUHK, and ByteDance propose HiFi-Inpaint, a high-fidelity framework for generating human-product images. By introducing Shared Enhancement Attention and Detail-Aware Loss, this method overcomes prior limitations in detail preservation, leveraging a new dataset to achieve state-of-the-art results for e-commerce and advertising applications.
Key Contributions
- Existing reference-based inpainting methods struggle to preserve fine-grained product details due to a lack of diverse training data and insufficient supervision for precise guidance in human-product image generation.
- The proposed HiFi-Inpaint framework introduces Shared Enhancement Attention to refine fine-grained features and a Detail-Aware Loss that enforces pixel-level supervision using high-frequency maps.
- The authors construct a new dataset called HP-Image-40K with over 40,000 curated samples and demonstrate that their method achieves state-of-the-art performance in generating detail-preserving human-product images.
Introduction
Human-product image generation is critical for advertising and e-commerce, where the ability to seamlessly integrate products into scenes while preserving fine-grained details like texture and branding directly impacts consumer trust. Existing reference-based inpainting methods struggle with this task because they lack diverse large-scale training data, fail to focus on specific product details, and rely on coarse supervision that leads to hallucinated or averaged content. To overcome these barriers, the authors introduce HiFi-Inpaint, a framework that utilizes Shared Enhancement Attention to refine fine-grained features and a Detail-Aware Loss to enforce precise pixel-level supervision via high-frequency maps. They also contribute a new dataset called HP-Image-40K to support robust model training, achieving state-of-the-art results in generating high-fidelity human-product images.
Dataset
-
Dataset Composition and Sources The authors construct two primary datasets: the synthetic HP-Image-40K and an internal real-world dataset. HP-Image-40K is generated using a pretrained text-to-image model to overcome data scarcity, while the real-world dataset is curated from publicly available internet images to ensure realistic diversity.
-
Key Details for Each Subset
- HP-Image-40K: Contains over 40,000 high-quality samples featuring diverse product categories such as bottles, jars, and tubes. The data covers a wide range of mask area ratios to train models on objects of varying scales and spatial distributions.
- Real-World Dataset: Comprises approximately 14,000 training samples and a separate 2,000-sample test set. This subset exhibits higher complexity with varied lighting, poses, occlusions, and background clutter compared to the synthetic data.
-
Data Usage and Training Strategy The authors utilize the 14,000 real-world samples alongside the synthetic HP-Image-40K for model training to enhance generalization. The 2,000 real-world samples are reserved exclusively for evaluation to assess robustness in uncontrolled environments. The synthetic data serves as the primary training source due to its well-controlled alignment with the task definition.
-
Processing and Construction Details
- Synthesis Pipeline: The authors use FLUX.1-Dev to generate diptych images with a product on the left and a human-product scene on the right, guided by specific prompt templates.
- Segmentation: A Sobel filter detects vertical edges to split diptychs into individual product and human-product images.
- Filtering Mechanisms: The team applies semantic filtering using YOLOv8 and CLIP to ensure product consistency between pairs. Textual filtering via InternVL compares extracted text strings to guarantee brand and label fidelity.
- Sample Formatting: Each final sample includes a text prompt, a masked human image, a product image, and a ground truth human-product image. The mask is generated by detecting and masking the product region in the human image.
- Preprocessing: Real-world images are aligned with synthetic data regarding resolution and aspect ratio to maintain a fair comparison protocol.
Method
The authors propose HiFi-Inpaint, a high-fidelity reference-based inpainting framework designed to generate seamless human-product images. The system takes a concise text prompt T, a masked human image Ih, and a product reference image Ip as inputs to produce a generated image Ig that integrates the product into the masked region while adhering to the text description. The overall pipeline encompasses dataset construction, a high-frequency map-guided DiT architecture, and a specialized training strategy.
Refer to the framework diagram below for a comprehensive view of the system components and data flow.
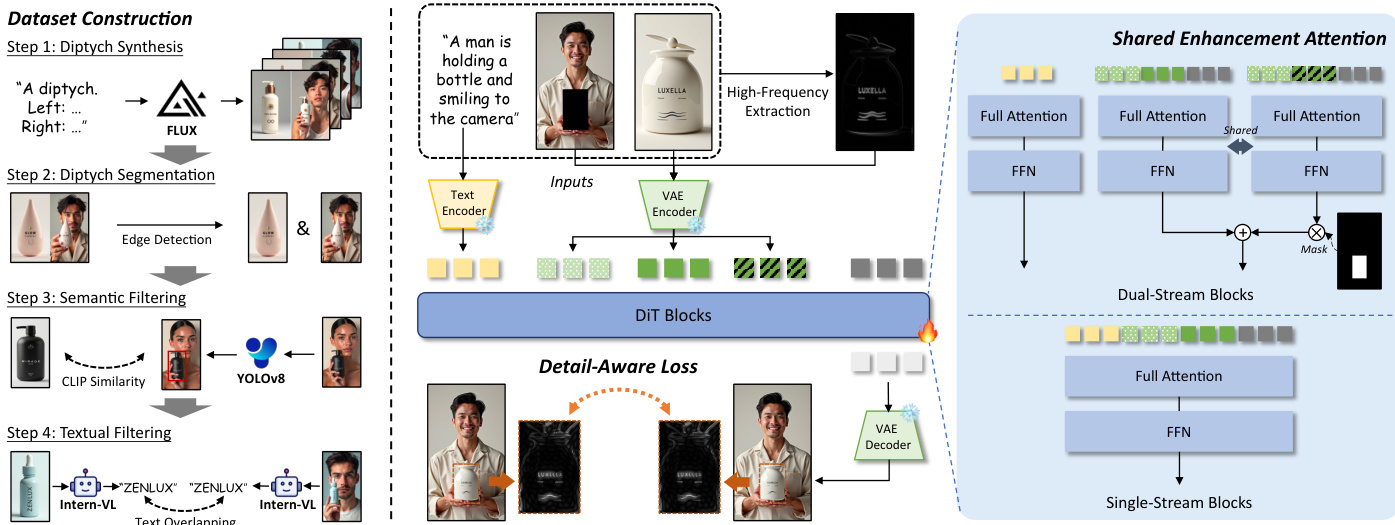
Dataset Construction To support model training, the authors curate a large-scale dataset named HP-Image-40K. As shown in the left section of the diagram, this process involves four steps. First, diptych synthesis is performed using a pretrained text-to-image model to create paired images. Second, diptych segmentation utilizes edge detection to separate the human and product components. Third, semantic filtering employs CLIP similarity and YOLOv8 to ensure visual relevance. Finally, textual filtering uses Intern-VL to verify text consistency and prevent text overlapping issues.
High-Frequency Map-Guided DiT The core architecture is built upon the FLUX.1-Dev model, which utilizes a Multi-Modal Diffusion Transformer (MMDiT). The authors introduce a token merging mechanism to effectively inject conditions. Textual tokens are encoded from the prompt, while visual tokens are derived from the masked human image, the product image, and the noisy ground truth. These are concatenated to form joint visual tokens z0:
z0=Concat(E(Ih),E(Ip),N(E(Igt),t))where E(⋅) represents the VAE image encoder and N(⋅,t) denotes noise addition at timestep t. To enhance detail preservation, a high-frequency map is extracted from the product image using Discrete Fourier Transform (DFT) and a high-pass filter. This generates a separate sequence of high-frequency visual tokens z0′:
z0′=Concat(E(Ih),E(H(Ip)),N(E(Igt),t))where H(⋅) denotes the high-frequency extraction process.
Shared Enhancement Attention To refine visual features within the masked regions, the authors introduce Shared Enhancement Attention (SEA). As detailed in the right section of the diagram, this module operates within the dual-stream visual DiT blocks. SEA supplements the standard processing branch with an additional branch for high-frequency visual tokens that shares the same parameters. For the i-th dual-stream block Bi(⋅), the update rule is modified to incorporate high-frequency information:
zi=Bi(zi−1)+αi⋅Mask(Bi(zi−1′),Mds)Here, αi is a learnable weighting factor that allows the model to harmoniously blend high-frequency details with global context. The masking operation Mask(⋅,Mds) ensures that the enhancement is applied only to the relevant down-sampled masked regions, preventing interference from other parts of the image.
Detail-Aware Training Strategy The training process is optimized using a Detail-Aware Loss (DAL) to provide precise pixel-level supervision. As illustrated in the bottom center of the diagram, this loss function targets the high-frequency components within the masked regions. It is formulated as:
LDA=H(I^gt)⊙M−H(Igt)⊙M22where I^gt is the predicted image, Igt is the ground truth, and M is the mask. This is combined with a standard latent-level MSE loss LMSE to ensure global consistency. The overall loss function is defined as:
LOverall=LMSE+LDAThis combined approach ensures the model achieves a balance between global semantic coherence and the preservation of intricate product details.
Experiment
- Quantitative and qualitative comparisons against four reference-based inpainting methods demonstrate that HiFi-Inpaint achieves state-of-the-art performance in text alignment, visual consistency, and overall image quality, particularly in preserving fine-grained product details like text and logos.
- A user study confirms that the proposed method aligns better with human preferences across text alignment, visual consistency, and generation quality compared to existing baselines.
- Ablation studies validate that the synthetic HP-Image-40K dataset, Shared Enhancement Attention mechanism, and Detail-Aware Loss are all critical components that significantly improve detail preservation and visual fidelity.
- Evaluations on real-world data and challenging generalization scenarios show that the model maintains robustness and high-fidelity product integration even under complex lighting, pose variations, and diverse environmental conditions.