Command Palette
Search for a command to run...
MMR-Life: تجميع مشاهد الحياة الواقعية للاستدلال متعدد الوسائط متعدد الصور
MMR-Life: تجميع مشاهد الحياة الواقعية للاستدلال متعدد الوسائط متعدد الصور
Jiachun Li Shaoping Huang Zhuoran Jin Chenlong Zhang Pengfei Cao Yubo Chen Kang Liu Jun Zhao
الملخص
أدى التقدم الأخير في قدرات التفكير لدى النماذج الكبيرة متعددة الوسائط للغة (MLLMs) إلى تمكينها من التعامل مع مهام أكثر تعقيدًا مثل التحليل العلمي والتفكير الرياضي. وعلى الرغم من الإمكانات الكبيرة التي تمتلكها، تظل قدرات التفكير لدى نماذج MLLMs في السياقات المختلفة في الحياة الواقعية ما زالت غير مُستكشفة بشكل واسع، كما تعاني من نقص في المعايير القياسية لتقييمها. ولسد هذه الفجوة، نقدّم MMR-Life، وهو معيار شامل مصمم لتقييم القدرات المتعددة للتفكير متعدد الصور في نماذج MLLMs ضمن سياقات واقعية. يتكون MMR-Life من 2,646 سؤالًا متعدد الخيارات مبنيًا على 19,108 صورة تم جمعها بشكل رئيسي من سياقات واقعية، ويغطي بشكل شامل سبعة أنواع من التفكير: الاستدلال الاستنتاجي (الاستنتاج التأملي)، الاستدلال بالتشابه، الاستدلال السببي، الاستدلال الاستنتاجي، الاستدلال الاستقرائي، والتفكير المكاني والزمني. على عكس المعايير الحالية للاستدلال، لا يعتمد MMR-Life على خبرة متخصصة في مجال معين، بل يتطلب من النماذج دمج المعلومات عبر صور متعددة وتطبيق مهارات تفكير متنوعة. وقد أظهر تقييم 37 نموذجًا متقدمًا التحدي الكبير الذي يفرضه MMR-Life، حيث حقق حتى أفضل النماذج مثل GPT-5 دقة بلغت 58% فقط، مع ملاحظة تباين كبير في الأداء بين أنواع التفكير المختلفة. علاوةً على ذلك، قمنا بتحليل نماذج التفكير المتبعة في النماذج الحالية من MLLMs، ودرسنا كيف تؤثر عوامل مثل طول عملية التفكير، وطريقة التفكير، ونوع التفكير على الأداء. في الختام، يُعد MMR-Life أساسًا شاملاً لتقييم وتحليل وتحسين الجيل القادم من أنظمة التفكير متعددة الوسائط.
One-sentence Summary
Researchers from UCAS and CAS introduce MMR-Life, a real-world multimodal benchmark with 2,646 questions across seven reasoning types, challenging 37 models including GPT-5; it reveals critical gaps in multi-image reasoning and guides future MLLM development beyond domain-specific tasks.
Key Contributions
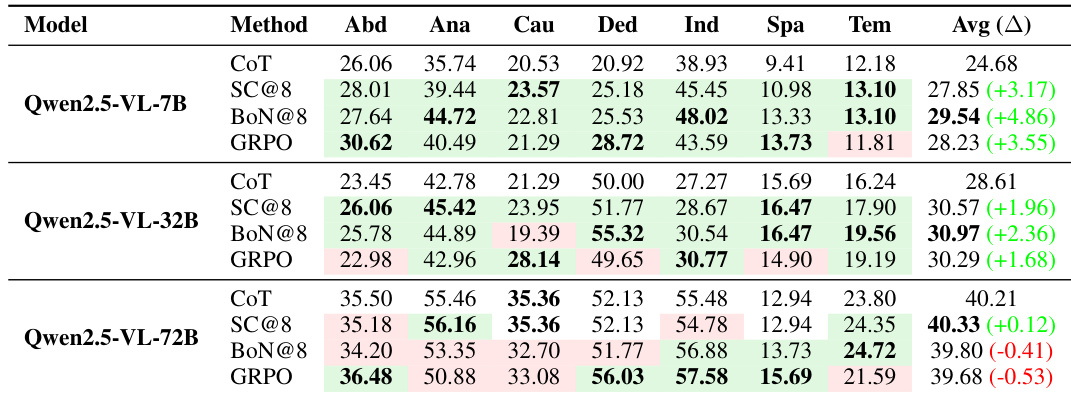
- We introduce MMR-Life, the first comprehensive benchmark for evaluating multimodal multi-image reasoning in real-life scenarios, featuring 2,646 questions across seven reasoning types—abductive, analogical, causal, deductive, inductive, spatial, and temporal—based on 19,108 real-world images without requiring domain-specific expertise.
- Evaluations on 37 state-of-the-art MLLMs, including GPT-5 and Gemini-2.5-Pro, reveal significant performance gaps, with top models achieving only ~58% accuracy and showing strong disparities across reasoning types, particularly struggling in causal, spatial, and temporal reasoning.
- Through in-depth analysis using MMR-Life, we uncover key insights into MLLM reasoning paradigms, such as the limited benefit of extended thinking length for most reasoning types and the clustering of reasoning behaviors, offering actionable directions for improving next-generation multimodal systems.
Introduction
The authors leverage the growing capabilities of multimodal large language models (MLLMs) to tackle complex reasoning tasks, but note that most existing benchmarks focus on either expert-level knowledge or synthetic puzzles — both poorly aligned with real-world visual reasoning, which typically involves multiple images and commonsense logic. Prior work also largely ignores multi-image inputs or restricts evaluation to narrow reasoning types, failing to capture the diversity of everyday scenarios. Their main contribution is MMR-Life, a new benchmark comprising 2,646 questions across seven reasoning types — abductive, analogical, causal, deductive, inductive, spatial, and temporal — all grounded in real-life image sets. Evaluating 37 state-of-the-art models reveals even top performers like GPT-5 struggle, achieving only 58% accuracy and showing significant weaknesses in causal, spatial, and temporal reasoning, highlighting critical gaps in current MLLM capabilities.
Dataset

The authors use MMR-Life, a novel multimodal benchmark designed to evaluate MLLMs on real-life reasoning tasks. Here’s how the dataset is structured and used:
-
Composition and Sources:
MMR-Life contains 2,646 multiple-choice questions based on 19,108 real-world images, covering 7 reasoning types (abductive, analogical, causal, deductive, inductive, spatial, temporal) across 21 tasks. Images are sourced from:- Public datasets (e.g., Kaggle) with high-resolution, contextually related images
- Web screenshots (e.g., eBird for bird distribution)
- Public video frames, extracted and filtered for clarity
- Existing multi-image or video reasoning benchmarks
All images are natural photos—no symbolic diagrams or artificial graphics are included.
-
Key Subset Details:
- Each question requires at least two images.
- Questions are generated via automated rules (for explicit visual cues) or manual annotation (for implicit reasoning).
- Five answer options per question: one correct, four incorrect. Incorrect options are generated via heuristic sampling (for image choices) or LLMs (GPT-5-mini, GPT-4o, Qwen2.5-VL-32B) and manually refined.
- 3.2K total QA pairs were initially created; filtered down to 2,646 via quality control.
- Filtering steps:
- Difficulty: Remove questions answered correctly by 3 small MLLMs (Qwen2.5-VL-7B, Gemma3-4B, InternVL3.5-8B).
- Format: Manual revision to align incorrect options with correct ones in length and structure.
- Quality: Co-authors review and remove ambiguous, multi-answer, or domain-specific questions.
-
Usage in Training/Experiments:
- The dataset is used for evaluation only—not for training.
- No mixture ratios or training splits are applied; all models are tested on the full benchmark.
- The paper does not mention cropping or resizing; images are used as collected, with quality and clarity prioritized during extraction.
-
Processing and Metadata:
- All annotations follow strict guidelines: English-only, no domain expertise required, unambiguous, and aligned with reasoning type definitions.
- Metadata includes reasoning type, source, and image count per question.
- Ethical compliance: No copyrighted, private, or harmful content; no crowdsourcing; all annotators volunteered.
- Reproducibility: Full data sources, annotation prompts, and a 210-item subset are provided in appendices and supplementary materials.
Method
The authors leverage a structured prompting framework to guide multimodal reasoning models through complex tasks involving multiple images. This framework is designed to enforce consistent output formats while encouraging step-by-step reasoning, which is critical for generating reliable negative options and validating correct answers. Each prompt template is tailored to a specific output structure, ensuring that the model’s response aligns with the expected semantic and syntactic constraints of the task.
For instance, in the case of generating negative options for reasoning tasks, the authors employ a series of prompts that progressively constrain the output format. One such prompt instructs the model to produce a sequence of image indices, formatted as “x-x-x-x…”, where each ‘x’ corresponds to a specific image in the input set. This structured output facilitates downstream evaluation and comparison against ground truth sequences.

Another variant of the prompt restricts the output to directional responses, requiring the model to select from a predefined set of eight common directions. This constraint is particularly useful in navigation or spatial reasoning tasks where directional accuracy is paramount.

In tasks requiring sequential action planning, the authors introduce a numbered action format, where each step must be prefixed with an integer and selected from a limited set of actions such as “Turn Left,” “Turn Right,” or “Go forward until the xxx.” This ensures that the generated sequences are both semantically valid and executable.

For multiple-choice question answering, the authors adopt a Chain-of-Thought (CoT) style prompt that explicitly directs the model to select from a fixed set of options (A/B/C/D/E). This format not only standardizes the output but also encourages the model to articulate its reasoning before arriving at the final selection.

Across all prompt variants, the authors consistently include the directive “Let’s think step by step before answering,” which serves as a meta-instruction to activate the model’s reasoning capabilities. This design choice reflects a deliberate effort to scaffold complex reasoning through structured output constraints and explicit reasoning prompts.
Experiment
- MMR-Life benchmark reveals significant gaps between current MLLMs and human performance, especially in real-life reasoning scenarios, with even top models like GPT-5 scoring 14% below humans.
- Models show strong performance in analogical and deductive reasoning but struggle notably in spatial, temporal, and causal reasoning, highlighting a bias toward pattern association over abstract world modeling.
- Adding “thinking” modes improves performance in closed-source models but offers little to no benefit for open-source models, suggesting current open-source thinking frameworks lack generalization to real-world contexts.
- Longer reasoning chains correlate logarithmically with higher accuracy overall, but this benefit is task-dependent—inductive reasoning often degrades with extended CoT, while analogical reasoning improves.
- Standard reasoning-enhancement methods like BoN and GRPO show diminishing returns or even performance drops on larger models, indicating limited generalizability as model scale increases.
- Reinforcement learning methods underperform compared to inference-time techniques like Best-of-N on small models, raising questions about RL’s effectiveness for reasoning generalization.
- Reasoning types exhibit varying correlations; analogical and inductive reasoning are highly correlated, while spatial reasoning is isolated, suggesting distinct underlying cognitive patterns.
- Error analysis of top models reveals dominant failures in logical reasoning (e.g., causal inversion, temporal confusion), abstraction, knowledge recall, and perception, pointing to core limitations in current MLLMs.
The authors evaluate 37 multimodal language models on the MMR-Life benchmark, revealing that even top closed-source models like GPT-5 fall significantly short of human performance, particularly in spatial and temporal reasoning. While longer reasoning chains generally correlate with better accuracy, this benefit is not universal and varies by reasoning type, with some tasks like inductive reasoning showing no improvement or even degradation with extended CoT. Open-source thinking models show little to no advantage over their non-thinking counterparts, suggesting current reasoning enhancements are not yet effective for real-world generalization.
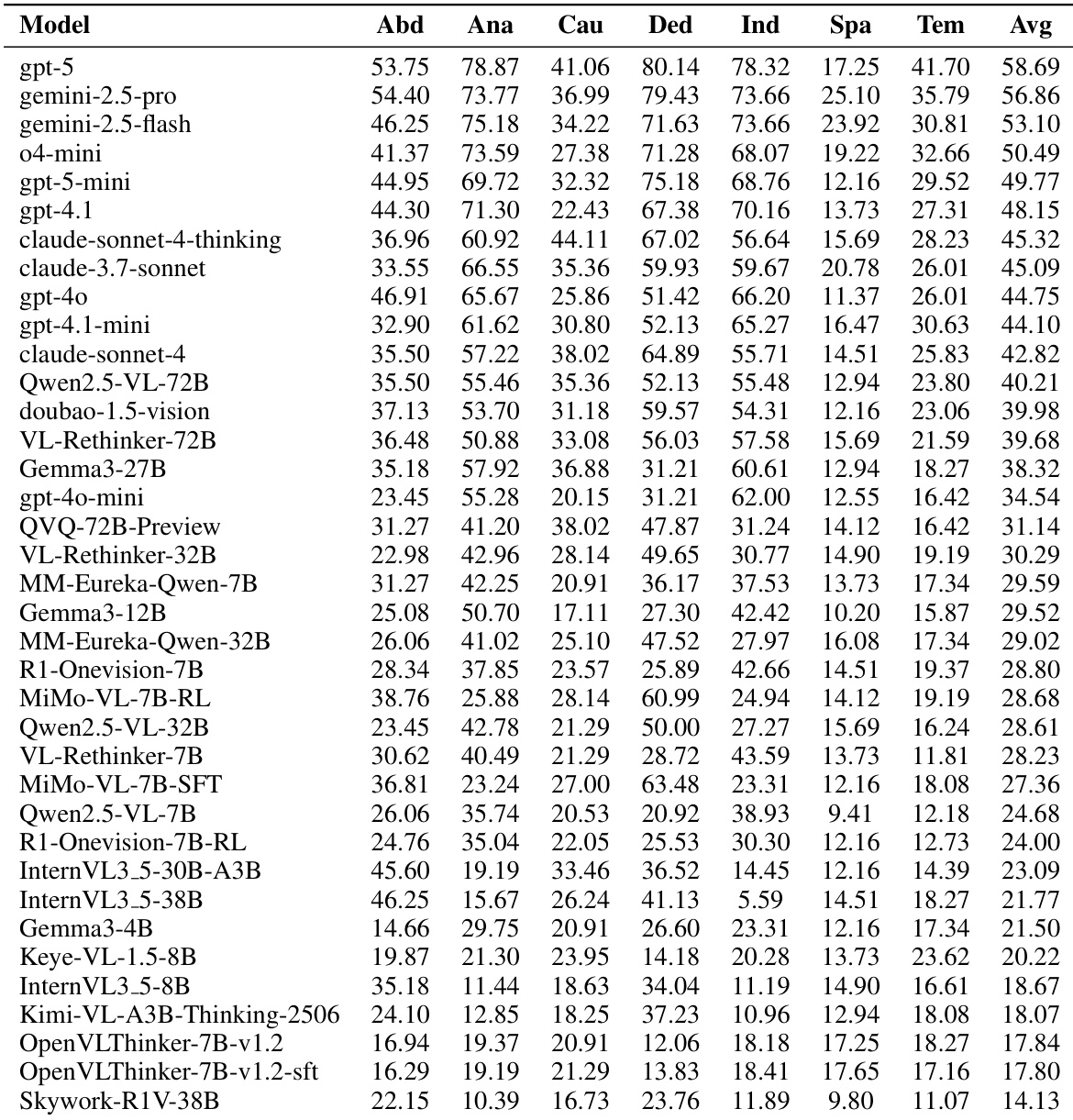
The authors use a diverse set of 2,646 questions across seven reasoning types to evaluate multimodal language models, revealing that even top-performing models struggle with real-world reasoning tasks compared to human performance. Results show significant performance gaps in spatial and temporal reasoning, while analogical and deductive reasoning are relatively better handled, highlighting a need for models to better learn abstract world representations. Current open-source thinking models do not consistently outperform their non-thinking counterparts, suggesting limited generalization in real-world contexts despite longer reasoning processes.
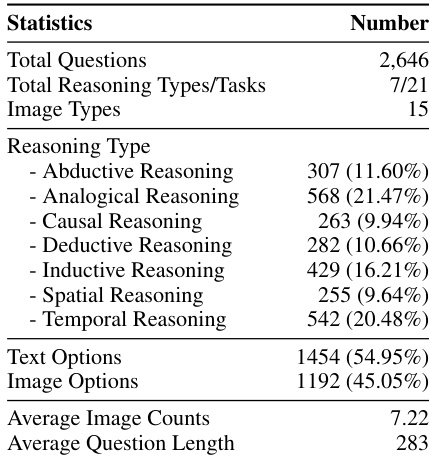
The authors evaluate multiple reasoning enhancement methods across Qwen2.5-VL models of varying sizes and find that performance gains from techniques like Self-Consistency and Best-of-N diminish as model scale increases, with larger models sometimes performing worse under these methods than with basic CoT. For the 72B model, GRPO and BoN show no consistent advantage over CoT, suggesting that advanced reasoning methods may not generalize well to larger architectures. Results indicate that model scale alone does not guarantee improved reasoning, and enhancement techniques must be carefully matched to model capacity and task type.
The authors evaluate 37 multimodal language models on the MMR-Life benchmark, revealing that even top closed-source models like GPT-5 fall significantly short of human performance, particularly in spatial and temporal reasoning. While thinking modes improve closed-source models, they offer little to no benefit for open-source models, and longer reasoning chains do not consistently enhance accuracy across reasoning types. Results also show that current reasoning-enhancement methods like BoN and GRPO provide diminishing returns or even degrade performance on larger models, highlighting a need for more effective generalizable techniques.
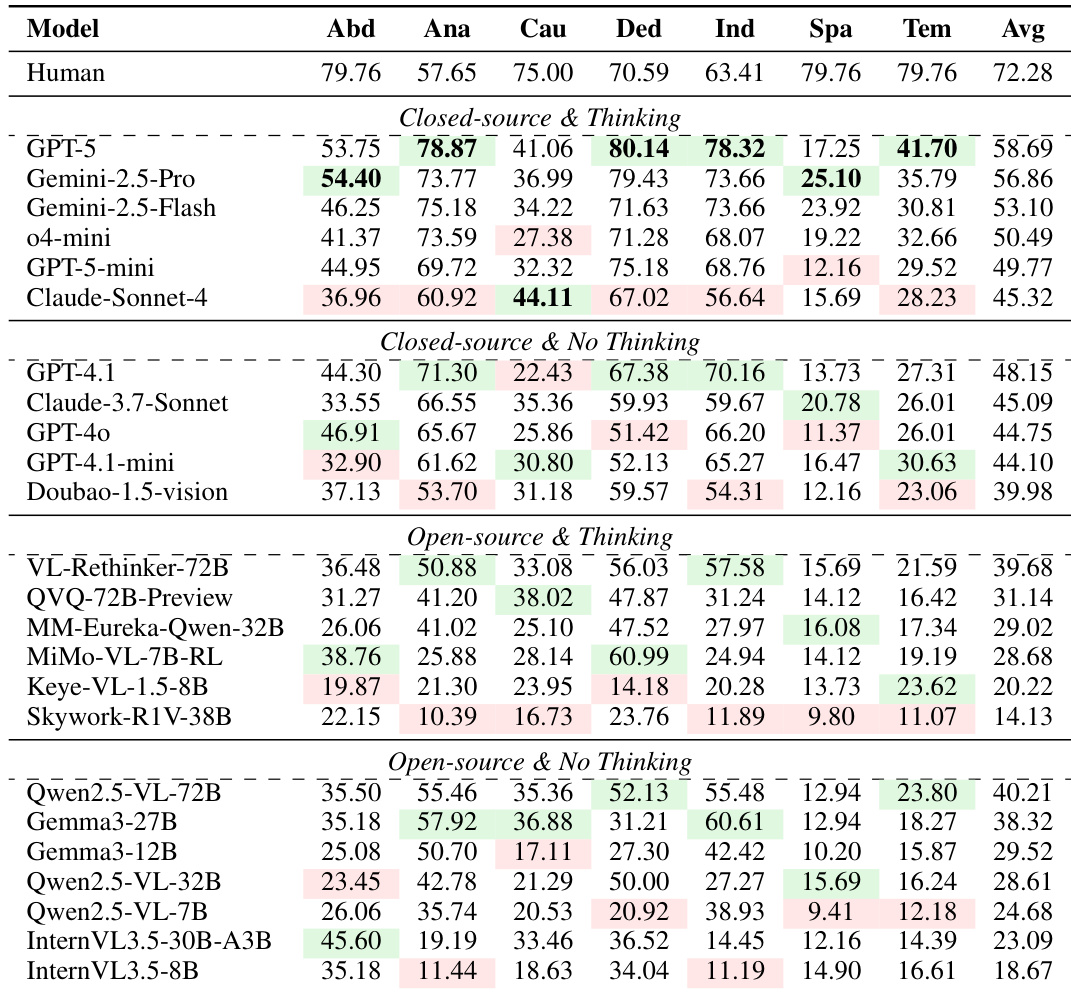
The authors evaluate 37 multimodal language models on the MMR-Life benchmark, revealing that even top closed-source models like GPT-5 fall significantly short of human performance, particularly in spatial and temporal reasoning. While thinking modes improve closed-source models, they offer no consistent benefit for open-source models, and longer reasoning chains do not universally enhance accuracy across reasoning types. Results indicate that current models struggle with abstract, real-world reasoning despite excelling in analogical and deductive tasks, highlighting a need for training approaches that better generalize to everyday scenarios.