Command Palette
Search for a command to run...
تحسين الصور متعددة الأطياف عبر المقاييس المختلفة باستخدام ScaleFormer ومعيار PanScale
تحسين الصور متعددة الأطياف عبر المقاييس المختلفة باستخدام ScaleFormer ومعيار PanScale
Ke Cao Xuanhua He Xueheng Li Lingting Zhu Yingying Wang Ao Ma Zhanjie Zhang Man Zhou Chengjun Xie Jie Zhang
الملخص
تهدف عملية تحسين حدة الصور متعددة الأطياف (Pansharpening) إلى توليد صور متعددة الأطياف عالية الدقة من خلال دمج التفاصيل المكانية للصور البانكروماتية (panchromatic images) مع الثراء الطيفي للبيانات متعددة الأطياف (MS) منخفضة الدقة. ومع ذلك، يتم تقييم معظم الطرق الحالية في ظل إعدادات محدودة ومنخفضة الدقة، مما يحد من قدرتها على التعميم في السيناريوهات الواقعية عالية الدقة. ولتجسير هذه الفجوة، نقوم باستقصاء منهجي للتحديات المتعلقة بالبيانات، والخوارزميات، والحوسبة في عملية pansharpening عابرة النطاقات (cross-scale).نقدم أولاً PanScale، وهو أول مجموعة بيانات ضخمة لعملية pansharpening عابرة النطاقات، مرفقة بـ PanScale-Bench، وهو benchmark شامل لتقييم القدرة على التعميم عبر مختلف الدقة والنطاقات. ولتحقيق التعميم عبر النطاقات (scale generalization)، نقترح ScaleFormer، وهي بنية (architecture) مبتكرة مصممة لعملية pansharpening متعددة النطاقات. يعيد ScaleFormer صياغة التعميم عبر دقة الصور كتعميم عبر أطوال التسلسلات (sequence lengths)؛ حيث يقوم بتحويل الصور إلى sequences من الـ patches بنفس الدقة ولكن بأطوال متغيرة تتناسب مع نطاق الصورة. كما تتيح وحدة Scale-Aware Patchify التدريب على مثل هذه الاختلافات باستخدام crops ذات حجم ثابت. بعد ذلك، يقوم ScaleFormer بفصل تعلم الميزات المكانية داخل الـ patch (intra-patch) عن نمذجة الاعتماد التسلسلي بين الـ patches (inter-patch)، مع دمج Rotary Positional Encoding لتعزيز القدرة على الاستقراء (extrapolation) إلى نطاقات غير مرئية.
One-sentence Summary
The authors introduce PanScale, the first large-scale cross-scale pansharpening dataset, and PanScale-Bench alongside ScaleFormer, a novel architecture that tokenizes images into variable-length patch sequences and employs Rotary Positional Encoding to decouple intra-patch spatial feature learning from inter-patch sequential dependency modeling for enhanced extrapolation to unseen scales.
Key Contributions
-
PanScale, a large-scale cross-scale pansharpening dataset, is introduced alongside PanScale-Bench, a comprehensive benchmark for evaluating generalization across varying resolutions. This standardized platform enables systematic testing and assessment of methods in diverse multi-scale scenarios encountered in real-world applications.
-
ScaleFormer is proposed as a novel architecture that reframes resolution generalization as sequence length generalization by tokenizing images into patch sequences of variable length. A Scale-Aware Patchify module enables training from fixed-size crops, and the method decouples intra-patch spatial feature learning from inter-patch sequential dependency modeling using Rotary Positional Encoding.
-
Extensive experiments across multiple datasets within the PanScale benchmark demonstrate that the method achieves accurate and efficient fusion at multiple scales. Results indicate the approach maintains high performance even when processing ultra-high-resolution inputs, highlighting strong generalization ability.
Introduction
High-resolution multi-spectral imagery is essential for environmental monitoring and precision agriculture, but satellite hardware limitations necessitate fusing panchromatic and low-resolution spectral data through pansharpening. Current approaches often fail to generalize to real-world high-resolution scenarios due to steep computational costs, tiled inference artifacts, and distribution shifts between training and inference scales. To bridge this gap, the authors present PanScale, the first large-scale cross-scale dataset, and PanScale-Bench for standardized evaluation. They further propose ScaleFormer, a novel architecture that treats resolution changes as sequence length variations to decouple spatial feature learning from sequential dependency modeling. This design enables efficient inference and robust generalization across varying image scales without relying on tiling.
Dataset
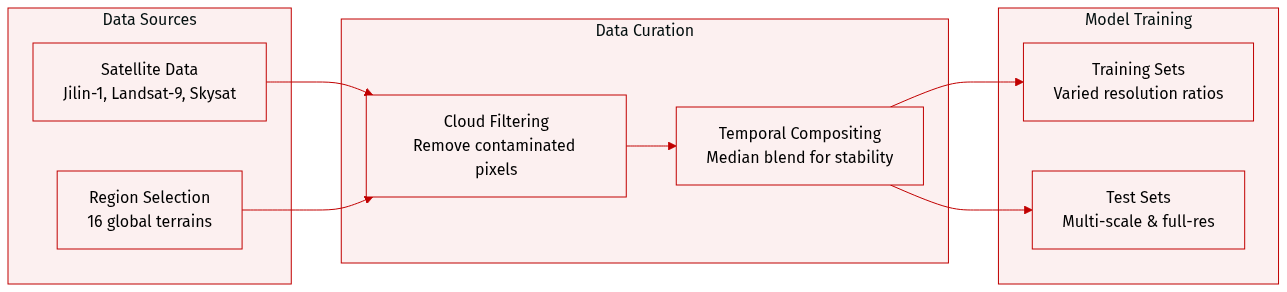
- Composition and Sources: The authors leveraged Google Earth Engine to acquire multi-source remote sensing data from Jilin-1, Landsat-9, and Skysat satellites. They selected 16 geographically diverse regions globally to cover terrains such as urban, mountainous, oceanic, and desert areas.
- Preprocessing Steps: Cloud-contaminated pixels are removed using quality assessment bands to generate binary cloud masks. The team applies pixel-wise median compositing across cloud-free observations within a time interval to create temporally stable and noise-reduced composite bands.
- Training Data: Each sub-dataset includes a training set with distinct upsampling ratios to expose models to diverse resolution levels. Jilin-1 uses a 4x ratio, while Landsat-9 and Skysat use 2x and 2.5x ratios respectively.
- Testing Framework: The benchmark includes multi-scale reduced-resolution test sets at 1600x1600, 800x800, 400x400, and 200x200 pixels. The Jilin subset excludes the 1600x1600 variant due to maximum resolution limits. Full-resolution test sets are also provided to evaluate robustness across real-world spatial variations.
Method
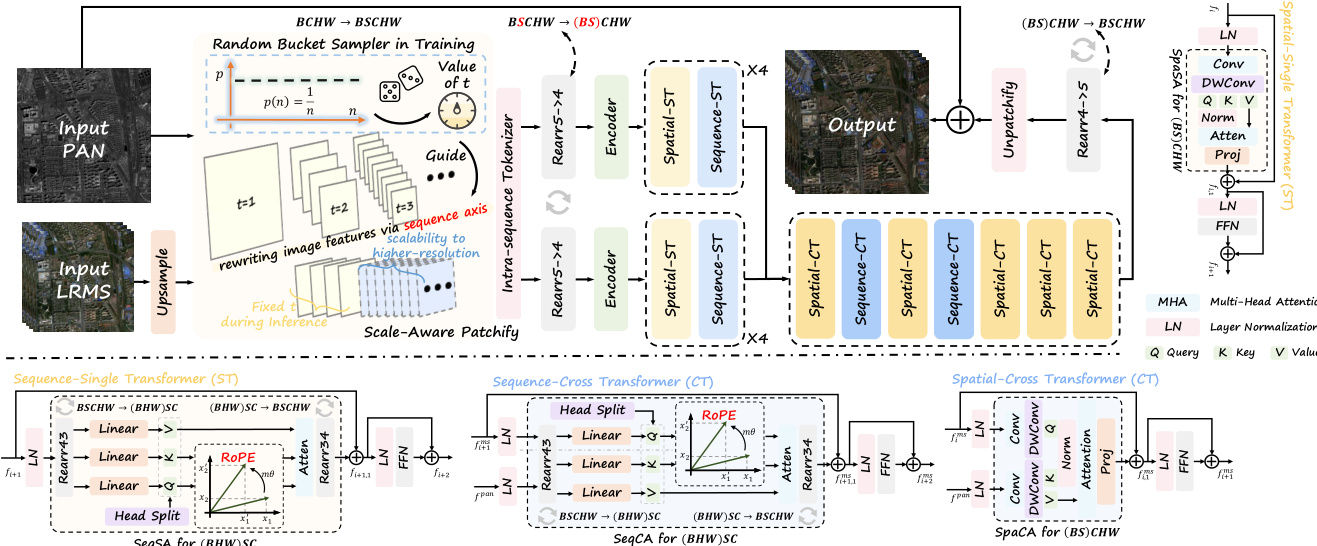
The authors propose ScaleFormer, a framework designed to address the challenges of cross-scale pansharpening by decoupling spatial information from scale-specific features. The overall architecture, as illustrated in the framework diagram, processes panchromatic (PAN) and low-resolution multi-spectral (LRMS) inputs through a series of specialized modules to generate high-resolution multi-spectral outputs.
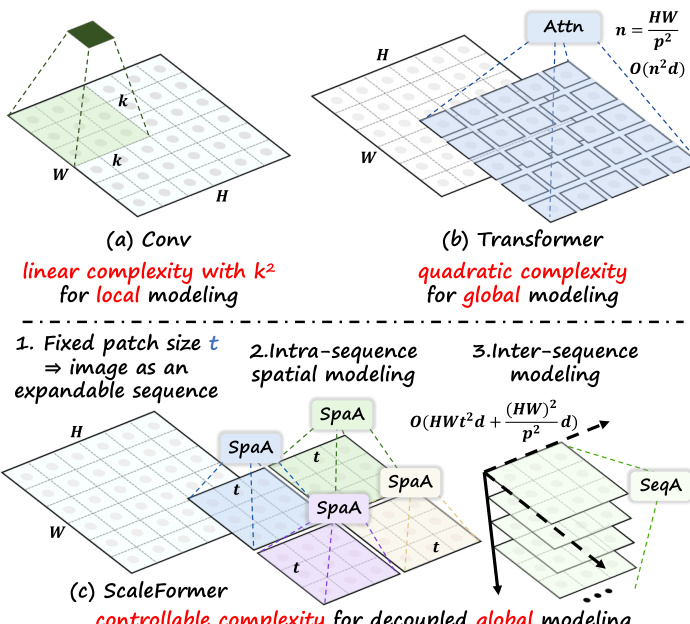
The design philosophy behind ScaleFormer is motivated by the trade-offs between local and global modeling. As shown in the figure below, standard convolutional operations offer linear complexity for local modeling but lack global receptive fields, while standard Transformers provide global modeling but incur quadratic complexity. ScaleFormer achieves controllable complexity for decoupled global modeling by treating the image as an expandable sequence.
Scale-Aware Patchify The pipeline begins with the Scale-Aware Patchify (SAP) module. To mitigate distribution shifts caused by varying input resolutions, the authors employ a bucket-based sampling strategy during training. Given the input PAN image P and upsampled MS image L, the SAP module randomly samples a bucket index t to determine a window size. This partitions the inputs into a sequence of multi-scale tokens, effectively rewriting local image evidence into an additional sequence axis. The operation can be expressed as:
P5d,L5d=SAP(P),SAP(L)where P5d∈RB×T×C×h×w. During inference, a fixed window size is used deterministically, ensuring that higher spatial resolutions are handled by lengthening the sequence along the scale axis while maintaining stable per-token statistics.
Single Transformer Modules Following patchification, the features pass through lightweight encoders and then into the Single-Transformer modules. These modules are specialized to independently capture dependencies within spatial and sequential domains. The architecture consists of a Spatial Transformer and a Sequence Transformer.
The Spatial Transformer focuses on modeling local and global spatial relationships within each patch. In parallel, the Sequence Transformer operates along the newly introduced sequence dimension to learn cross-patch correlations and capture scale-aware contextual dependencies. This separation allows the model to decouple spatial encoding from scale modeling. The processing flow for a feature map fi involves residual connections with self-attention and feed-forward networks:
fi,1=fi+SAspa(LN(fi)) fi+1=fi,1+FFN(LN(fi,1)) fi+1,1=fi+1+SAseq(LN(fi+1)) fi+2=fi+1,1+FFN(LN(fi+1,1))To enhance scale extrapolation, Rotary Position Embedding (RoPE) is incorporated into the mapped queries and keys, encoding continuous relative positional information.
Cross Transformer Modules To facilitate effective feature fusion between the panchromatic and multi-spectral modalities, the framework employs Cross Transformer modules. These include the Spatial-Cross Transformer and Sequence-Cross Transformer, which enable bidirectional information exchange via cross-attention mechanisms along spatial and scale dimensions, respectively.
Given input feature maps fims and fipan, the cross-attention operations are defined as:
fi,1ms=fims+CAspa(LN(fims),LN(fpan)) fi+1ms=fi,1ms+FFN(LN(fims)) fi+1,1ms=fi+1ms+CAseq(LN(fi+1ms),LN(fpan)) fi+2,1ms=fi+1,1ms+FFN(LN(fi+1,1ms))Similar to the single-modality attention, rearrangement operations are applied during CAseq to merge batch and spatial dimensions, and RoPE is injected to support generalization across scales.
Loss Function Finally, the model is trained to minimize the pixel-wise discrepancy between the reconstructed high-resolution multi-spectral image Hout and the ground truth G. The authors employ the L1 norm as the loss function:
L=∥Hout−G∥1Experiment
The evaluation framework compares the proposed method against representative traditional and deep learning baselines using the PanScale datasets and standardized metrics. Comparative experiments validate that the model achieves superior fusion quality and scalability, maintaining stable performance as input resolution increases while utilizing fewer parameters and lower computational resources than state-of-the-art techniques. Additionally, ablation studies confirm that specific architectural designs are necessary to ensure effective scale-awareness and generalization when handling diverse remote sensing data.
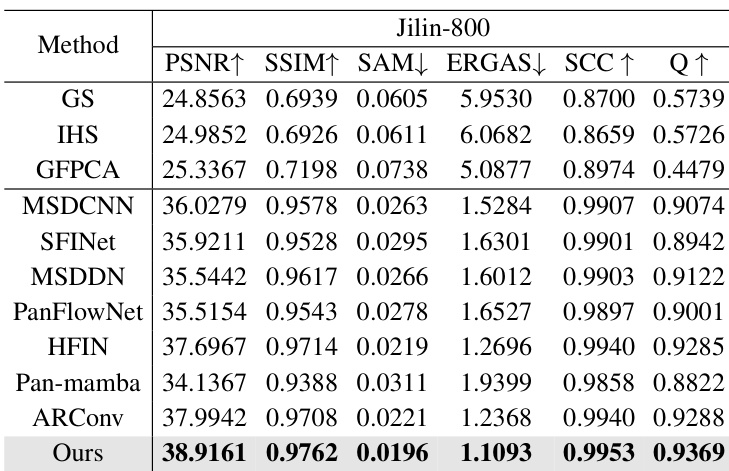
The authors compare their proposed method against traditional algorithms and state-of-the-art deep learning models on the Jilin-800 dataset. The experimental results show that the proposed approach consistently outperforms all competing methods across every evaluation metric. This demonstrates superior capability in preserving both spatial details and spectral fidelity compared to existing techniques. The proposed method achieves the highest scores in spatial fidelity metrics such as PSNR and SSIM. Results indicate the lowest levels of spectral distortion among all tested methods. The approach outperforms recent deep learning baselines like HFIN and ARConv across all categories.
The the the table details the configuration of the PanScale datasets, including Jilin, Landsat, and Skysat, across training, reduced-resolution, and full-resolution testing phases. It illustrates that while training sets utilize a single fixed image scale, the test sets encompass a wide variety of scales to evaluate performance across different resolutions. Additionally, the datasets differ in their base spatial resolution, with the Landsat dataset being notably coarser than the others. Training sets consist of images at a single scale, while test sets cover a broader spectrum of image dimensions. The Landsat dataset features a coarser spatial resolution compared to the Jilin and Skysat datasets. Full-resolution test sets include multiple scales to validate model robustness on high-resolution imagery.
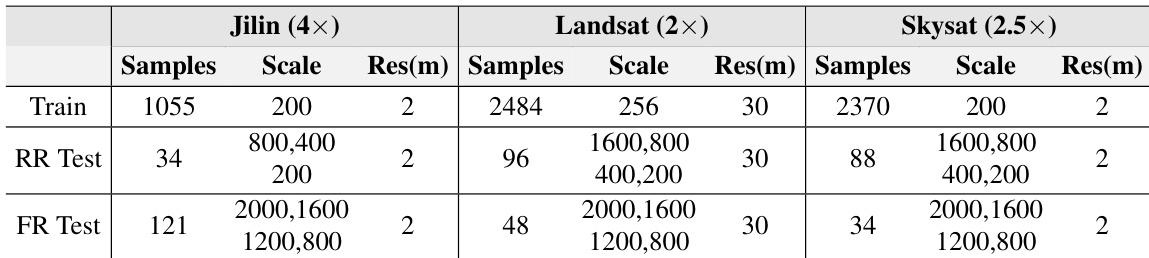
The authors compare their proposed approach against various traditional and deep learning-based pansharpening methods on Landsat datasets. Results indicate that the proposed method consistently outperforms all competing techniques across every evaluated metric, demonstrating superior spatial detail preservation and spectral fidelity. The proposed method achieves the highest scores in spatial fidelity metrics such as PSNR and SSIM while maintaining the lowest spectral distortion errors. Performance advantages are consistent across both Landsat-200 and Landsat-400 datasets, showing robustness to resolution changes. The method surpasses state-of-the-art deep learning baselines as well as classical image fusion techniques in overall image quality assessment.
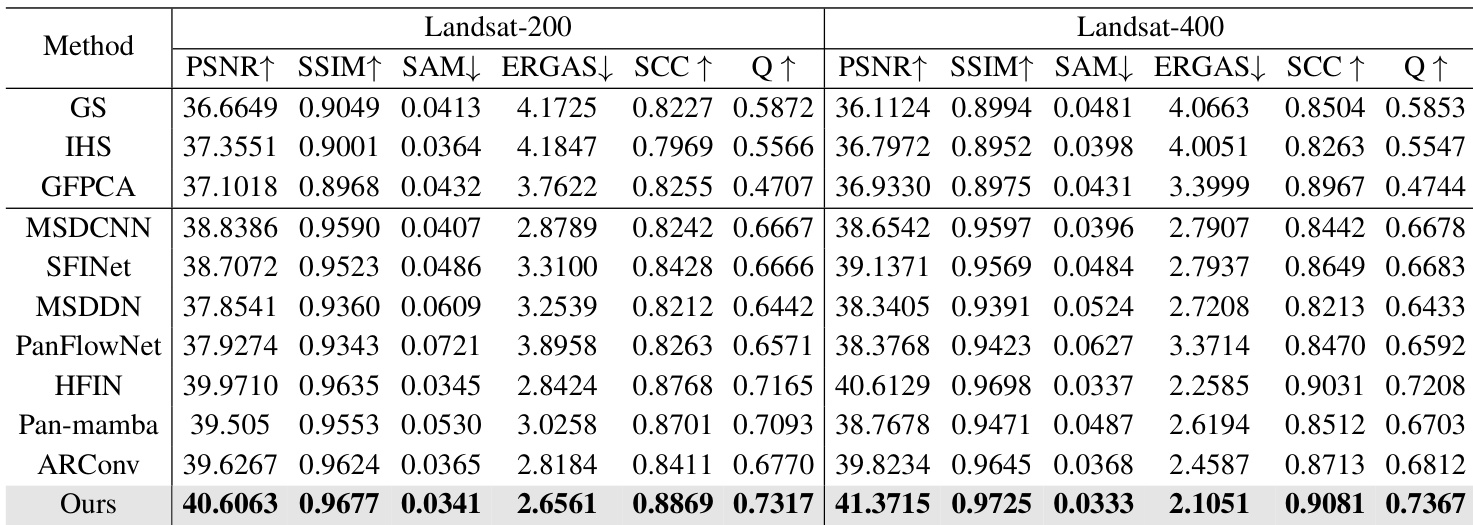
The authors compare their proposed method against traditional and deep learning baselines on Skysat datasets. The results indicate that the proposed approach generally outperforms competing methods, achieving leading scores in most spatial and quality metrics. The proposed method achieves top performance in spatial fidelity and quality indices such as PSNR, SSIM, and SCC. It demonstrates superior spectral synthesis quality by achieving the lowest ERGAS scores on both datasets. The approach outperforms strong deep learning baselines like ARConv and HFIN across the majority of measured criteria.
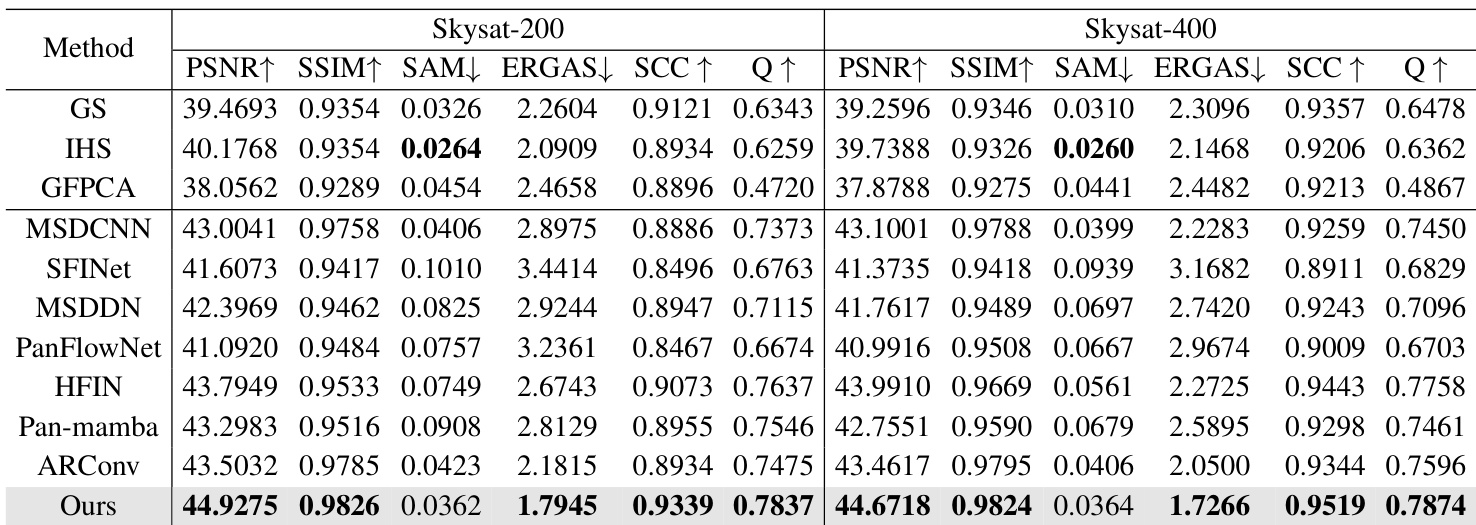
The authors compare their proposed method against a wide range of traditional and deep learning baselines on full-resolution Jilin datasets using no-reference quality metrics. The results indicate that the proposed approach consistently achieves superior or highly competitive performance across all tested spatial scales. The proposed method achieves the lowest spectral distortion across all tested resolution scales. Spatial distortion is minimized effectively, with the method consistently ranking as the second-best performer. Overall image quality remains high, outperforming most competing approaches in the majority of test cases.
The authors evaluate their proposed method against traditional algorithms and state-of-the-art deep learning models across Jilin, Landsat, and Skysat datasets with varying spatial resolutions and scales. This setup validates model robustness by testing performance on both reduced and full-resolution imagery to ensure reliability across different conditions. Experimental results indicate that the proposed approach consistently outperforms competing techniques in preserving spatial details and spectral fidelity while minimizing distortion to achieve superior overall image quality.