Command Palette
Search for a command to run...
AgentVista: تقييم الوكلاء متعددو الوسائط في سيناريوهات بصرية واقعية فائقة التحدي
AgentVista: تقييم الوكلاء متعددو الوسائط في سيناريوهات بصرية واقعية فائقة التحدي
الملخص
تُحلّ الوكلاء متعددو الوسائط في العالم الحقيقي سير عمل متعددة الخطوات بالاستناد إلى أدلة بصرية. فعلى سبيل المثال، يمكن لوكيل استكشاف عطل في جهاز ما من خلال ربط صورة لأسلاك بالمخطط الكهربائي المعني، ثم التحقق من صحة الإصلاح باستخدام التوثيق المتاح عبر الإنترنت؛ أو يمكنه تخطيط رحلة عبر تفسير خريطة مواصلات عامة والتحقق من الجداول الزمنية في ظل قيود التوجيه. غير أن معايير التقييم متعددة الوسائط الحالية تركز في الغالب على الاستدلال البصري في دور واحد أو على مهارات أدوات محددة، ولا تعكس بشكل كافٍ واقعية المهام، والدلالات البصرية الدقيقة، واستخدام الأدوات على مدى زمني طويل، وهو ما تتطلبه الوكلاء العملية. في هذا السياق، نقدّم «AgentVista»، وهو معيار تقييم لوكلاء متعددو الوسائط من النوع العام (generalist)، يغطي 25 نطاقًا فرعيًا موزعة على 7 فئات رئيسية، ويقرن سيناريوهات بصرية واقعية غنية بالتفاصيل باستخدام أدوات هجينة طبيعية. وتتطلب المهام في هذا المعيار تفاعلات طويلة المدى مع أدوات عبر وسائط متعددة، تشمل البحث على الويب، والبحث عن الصور، والتنقل بين صفحات الويب، والعمليات القائمة على الكود لمعالجة الصور والبرمجة العامة على حد سواء. وكشف التقييم الشامل للنماذج الأحدث عن فجوات كبيرة في قدرتها على تنفيذ استخدام أدوات متعددة الوسائط على مدى زمني طويل. فحتى أفضل نموذج في تقييمنا، وهو Gemini-3-Pro مع الأدوات، حقق دقة إجمالية بلغت 27.3% فحسب، فيما تتطلب الحالات الصعبة أكثر من 25 دورة استدعاء للأدوات. وننتظر أن يُسرّع معيار AgentVista من تطوير وكلاء متعددي الوسائط أكثر كفاءة وموثوقية، قادرة على حلّ مسائل واقعية وشديدة التحدي.
One-sentence Summary
Researchers from HKUST and collaborating institutions introduce AgentVista, a comprehensive benchmark spanning 25 subdomains to evaluate generalist multimodal agents on long-horizon, hybrid tool-use tasks. This work exposes critical gaps in current models like GEMINI-3-PRO, aiming to drive progress in realistic, multi-step visual problem solving.
Key Contributions
- Existing benchmarks fail to capture the realism and long-horizon tool interactions required for practical multimodal agents that solve multi-step workflows grounded in visual evidence.
- The paper introduces AgentVista, a benchmark spanning 25 subdomains that pairs detail-rich visual scenarios with natural hybrid tool use including web search, image search, and code-based operations.
- Comprehensive evaluation reveals significant capability gaps in state-of-the-art models, with the best performer achieving only 27.3% accuracy on tasks that can require over 25 tool-calling turns.
Introduction
Real-world multimodal agents must solve complex, multi-step problems by grounding their reasoning in visual evidence and utilizing diverse tools like web search and code execution. Current benchmarks fall short because they focus on single-turn reasoning or isolated skills, failing to capture the realism, visual subtlety, and long-horizon tool interactions required for practical deployment. To address this, the authors introduce AgentVista, a comprehensive benchmark spanning 25 subdomains that pairs detail-rich visual scenarios with natural hybrid tool use to evaluate generalist agents on ultra-challenging tasks. Their work reveals significant performance gaps in state-of-the-art models, with even top systems achieving low accuracy on tasks requiring over 25 tool-calling turns.
Dataset
-
Dataset Composition and Sources The authors introduce AgentVISTA, a benchmark comprising 209 tasks grounded in real images and authentic user needs. Data originates from three primary channels: public vision-language model arenas (providing over 284,000 images), annotator-captured daily scenarios, and private community help-seeking forums. The dataset spans seven major categories including Technology, Commerce, Geography, Entertainment, Society, Academics, and Culture, which further divide into 25 specific sub-domains.
-
Key Details for Each Subset Each task is designed to be vision-centric, requiring the model to extract key evidence from complex visual inputs like product catalogs, maps, or technical diagrams rather than relying on text shortcuts. Tasks mandate natural interleaved tool use, forcing agents to combine at least two tool categories such as web search, image search, page navigation, and code execution. Every instance features a deterministic, verifiable answer in a fixed format, such as a specific number, entity name, or date, to ensure objective evaluation.
-
Model Usage and Training Strategy AgentVISTA functions exclusively as an evaluation benchmark rather than a training dataset. The authors utilize it to test generalist multimodal agents on long-horizon workflows that require multi-step reasoning and constraint tracking. Experiments reveal that even top-tier models like GEMINI-3-PRO achieve only 27.3% accuracy, highlighting significant gaps in visual grounding and reliable tool use. The benchmark measures performance by tracking the number of tool-calling turns and the ability to synthesize visual and external information correctly.
-
Processing and Construction Pipeline The dataset creation follows a rigorous four-stage pipeline starting with 300,000+ candidate images.
- Stage 1 (Agent-centric filtering): Models like CLAUDE-Opus-4 filter out images with limited visual information or weak agentic potential, followed by human screening to retain only rich visual evidence.
- Stage 2 (Expert finalization): Annotators rewrite queries into realistic user requests, ensuring tasks require fine-grained visual cues and interleaved tool use, while recording the ground truth and evidence steps.
- Stage 3 (Execution filtering): Tasks are validated by executing them in a tool environment to confirm reproducible outputs and remove instances solvable without tools.
- Stage 4 (Two-round verification): A separate verification team checks visual dependency and answer stability, removing any tasks with unclear evidence or unrealistic workflows. The final dataset excludes simple OCR tasks, direct Q&A, and subjective opinions, focusing strictly on complex, multi-hop reasoning scenarios.
Method
The authors design AgentVista to support a compact set of tools that cover common multimodal agent workflows. Models can call web_search to retrieve web pages, visit to open and navigate a page, and image_search to locate images when a query requires external visual references. The system also provides a code_interpreter, which supports both programming and image processing. This tool enables arithmetic and parsing, structured extraction, and operations such as cropping, resizing, measuring, and comparing visual regions when needed. All tools are exposed with detailed descriptions and structured inputs and outputs, so the model can decide when to call a tool and how to use the returned results.
The agent follows a specific instruction protocol to solve tasks. It begins by analyzing the image and the user's question, followed by a step-by-step reasoning process. The agent then calls appropriate tools to gather information and iterates as needed until confident in its findings. Finally, the agent provides the answer inside specific tags. An example of this workflow is illustrated below, where the agent processes a query about flooring styles by comparing images, verifying the target room, and calculating material costs.

To ensure the quality and challenge level of the tasks, the authors employ a multi-stage filtering and validation pipeline. Refer to the framework diagram for the overall process, which transforms a raw data pool of over 300,000+ images and scenarios into a final dataset of 209 ultra-challenging tasks.
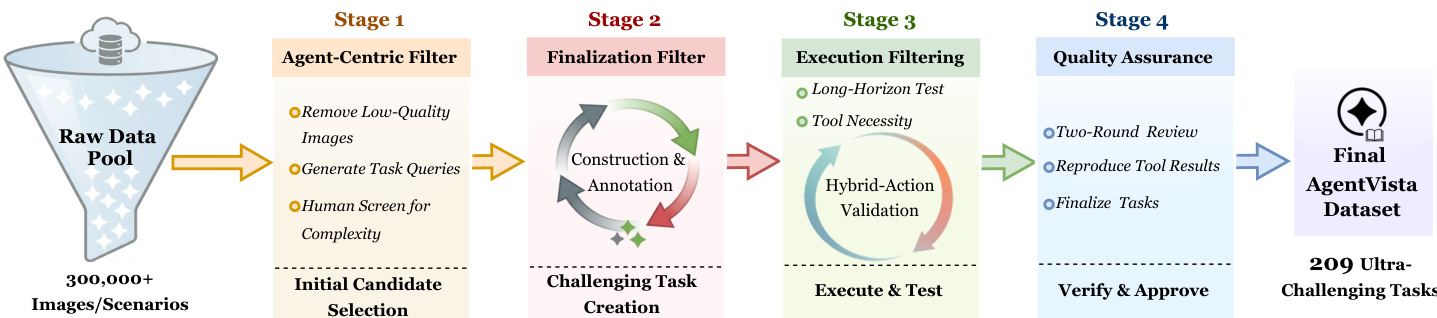
The process begins with Stage 1, the Agent-Centric Filter, which removes low-quality images, generates task queries, and involves human screening for complexity. Stage 2 focuses on Finalization Filter through construction and annotation to create challenging tasks. Stage 3 involves Execution Filtering, including long-horizon tests and tool necessity checks, alongside hybrid-action validation. Finally, Stage 4 ensures Quality Assurance through a two-round review, reproduction of tool results, and final task approval.
Experiment
- Evaluation of frontier multimodal models on the AgentVista benchmark reveals that current agents struggle with complex, long-horizon tasks requiring multi-step tool use grounded in real visual evidence, with even the best-performing model achieving only moderate accuracy.
- Performance varies significantly across model families and domains, indicating that no single model possesses uniform competence; GPT models excel in practical categories, Gemini leads in geography and overall accuracy, and Claude models show strength in tasks requiring careful constraint following.
- Experiments comparing input modes demonstrate that multi-image inputs often improve accuracy by providing complementary evidence and reducing ambiguity, suggesting that the primary bottleneck lies in long-horizon reasoning rather than the complexity of processing multiple images.
- Tool ablation studies confirm that hybrid workflows combining visual manipulation and external retrieval yield the best results, though the reliance on specific tools differs by model, with some prioritizing code-based image analysis and others favoring web search.
- Error analysis identifies visual misidentification as the dominant failure mode, followed by knowledge hallucination, highlighting critical weaknesses in fine-grained visual understanding and the ability to ground reasoning in provided evidence.
- Test-time scaling experiments show that generating multiple samples and selecting the best answer improves performance, yet a significant gap remains between selected outputs and the theoretical upper bound, indicating a need for better optimization methods to handle complex tool interactions.