Command Palette
Search for a command to run...
SkyReels-V4: نموذج متعدد الوسائط لإنشاء الفيديو والصوت، وإعادة التعبئة، والتحرير
SkyReels-V4: نموذج متعدد الوسائط لإنشاء الفيديو والصوت، وإعادة التعبئة، والتحرير
الملخص
SkyReels V4 هو نموذج أساسي متعدد الوسائط للفيديو موحد، يُستخدم لإنجاز إنشاء الفيديو والصوت معًا، وإعادة التعبئة (Inpainting)، والتحرير. يعتمد النموذج على بنية مُزدوجة تُسمى "مُحول التشتت متعدد الوسائط ثنائي المسارات (MMDiT)"، حيث يُولِّد أحد الفروع الفيديو، بينما يُولِّد الآخر الصوت المتماشي زمنيًا، مع مشاركة نموذج ترميز نصي قوي مستند إلى نماذج اللغة الكبيرة متعددة الوسائط (MMLM). يقبل SkyReels V4 تعليمات متعددة الوسائط غنية، تشمل النصوص، والصور، ومقاطع الفيديو، والخرائط (Masks)، والمرجع الصوتي. من خلال دمج قدرة نماذج MMLM على اتباع التعليمات متعددة الوسائط مع التعلم السياقي داخل فرع MMDiT الخاص بالفيديو، يمكن للنموذج دمج توجيهات بصرية دقيقة تحت ظروف تشغيل معقدة، في حين يستخدم فرع MMDiT الخاص بالصوت المرجع الصوتي لتحسين إنشاء الصوت بشكل متزامن. من ناحية الفيديو، نستخدم صيغة دمج القنوات (Channel Concatenation) التي توحد مجموعة واسعة من مهام إعادة التعبئة، مثل تحويل الصورة إلى فيديو، وتمديد الفيديو، والتحرير الفيديو تحت واجهة واحدة، وتمتد بشكل طبيعي إلى إعادة التعبئة والتحرير المرتبط بالرؤية عبر أوامر متعددة الوسائط. يدعم SkyReels V4 دقة تصل إلى 1080 بكسل، ومعدل إطارات 32 إطارًا في الثانية، ومدة تصل إلى 15 ثانية، ما يمكّن من إنشاء فيديوهات عالية الوضوح، متعددة المشاهد، وبجودة سينمائية مصحوبة بصوت متماشٍ. ولجعل هذه العملية عالية الدقة وطويلة المدة قابلة للتنفيذ من الناحية الحسابية، نقدّم استراتيجية كفاءة: إنشاء تسلسل منخفض الدقة بالكامل معًا، ثم إنشاء الإطارات عالية الدقة الأساسية، يتبعها نماذج مخصصة للتحسين العالي للدقة (Super-resolution) وتفصيل الإطارات (Frame Interpolation). إلى حد علمنا، فإن SkyReels V4 هو أول نموذج أساسي للفيديو يدعم في آن واحد إدخال متعدد الوسائط، وإنشاء متماثل للصوت والفيديو، ومعالجة موحدة للإطلاق، وإعادة التعبئة، والتحرير، مع الحفاظ على كفاءة قوية وجودة عالية على دقة وطول سينمائيين.
One-sentence Summary
SkyReels Team and Skywork AI propose SkyReels-V4, a unified multi-modal video foundation model using dual-stream MMDiT architecture with shared MMLM text encoder, enabling joint video-audio generation, editing, and inpainting at 1080p/32fps/15s via efficient low-high resolution generation, setting a new standard for cinematic multi-modal content creation.
Key Contributions
- SkyReels-V4 introduces a dual-stream MMDiT architecture that jointly generates synchronized video and audio from diverse inputs—including text, images, video clips, masks, and audio references—by leveraging a shared MMLM text encoder for unified multi-modal conditioning.
- The model unifies generation, inpainting, and editing via a channel-concatenation formulation in the video branch, enabling tasks like image-to-video, video extension, and mask-guided editing under a single interface, while the audio branch uses reference audio to guide sound synthesis.
- It achieves cinematic quality (1080p, 32 FPS, 15s) through an efficiency strategy of generating low-res sequences and high-res keyframes followed by super-resolution and interpolation, and outperforms state-of-the-art models on benchmarks including SkyReels-VABench and Artificial Analysis Arena.
Introduction
The authors leverage recent advances in multimodal diffusion modeling to address the fragmentation in video-audio generation systems, where prior models either handled modalities separately or lacked unified editing and inpainting capabilities. Existing approaches—whether commercial like Sora-2 or open-source like Kling-Omni—struggle with full audio-visual alignment, multimodal conditioning, or scalable editing under a single architecture, often sacrificing synchronization, resolution, or flexibility. SkyReels-V4 introduces a dual-stream MMDiT framework that jointly generates synchronized video and audio from diverse inputs (text, images, video, masks, audio) while unifying generation, inpainting, and editing through a channel-concatenation paradigm. It further enables cinematic-scale outputs (1080p, 32 FPS, 15s) via an efficient low/high-resolution keyframe strategy, making it the first system to integrate all these capabilities at production-grade quality and speed.
Dataset
-
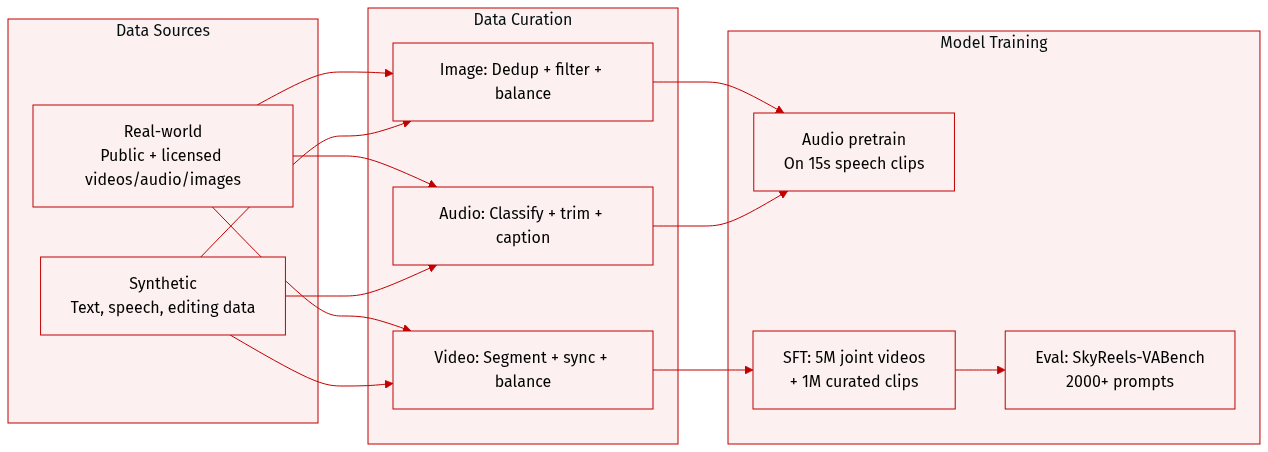
The authors use a multimodal training dataset combining real-world and synthetic data across images, videos, and audio.
-
Real-world data comes from public sources (LAION, Flickr, WebVid-10M, Koala-36M, OpenHumanVid, Emilia, AudioSet, VGGSound, SoundNet) and licensed in-house content (movies, TV series, short videos, web series).
-
Synthetic data fills gaps in multilingual text generation, speech synthesis, and multimodal editing. Text generation covers Chinese, English, Japanese, Korean, German, French, etc., with font-aware rendering and context-aware styling. Video-text data includes motion-matched text effects. Speech data uses multiple TTS models and rare-script corpora. Inpainting/editing data is built via segmentation, editing, and controllable generation pipelines.
-
Image processing includes deduplication, quality filtering (resolution, IQA, watermarks), and balancing via clustering (pretraining) or entity/scene matching (fine-tuning).
-
Audio processing classifies clips into sound effects, music, speech, or singing using Qwen3-Omni; filters by SNR, MOS, clipping, and silence ratio; segments or concatenates clips to 15 seconds; transcribes speech/singing with Whisper; and generates unified captions via Qwen3-Omni.
-
Video processing uses intelligent segmentation (VLM-enhanced TransNet) for narrative coherence, deduplicates via VideoCLIP, filters by basic, content, and motion quality, balances by concept and motion taxonomy, and syncs audio-video via SyncNet (retaining clips with |offset| ≤ 3 and confidence > 1.5, min volume -60 dB).
-
The audio backbone is pretrained from scratch on hundreds of thousands of hours of variable-length speech (up to 15s) to capture speaker traits like pitch and emotion.
-
In supervised fine-tuning, the authors train on 5M multimodal joint generation videos (20% of data), then refine with 1M manually curated high-quality videos to boost motion coherence and audio-visual alignment.
-
For evaluation, they introduce SkyReels-VABench: a 2000+ prompt benchmark testing text-to-video+audio models across languages (Chinese, English), content types (advertising, education, storytelling), subjects, environments, motion dynamics, and audio modalities (speech, singing, SFX, music).
Method
The authors leverage a dual-stream Multimodal Diffusion Transformer (MMDiT) architecture to enable joint video and audio generation, inpainting, and editing under a unified framework. The model processes video and audio modalities through parallel, symmetric branches that share a common text encoder derived from a Multimodal Large Language Model (MMLM). This design allows the system to accept rich multi-modal conditioning signals—including text, images, video clips, masks, and audio references—while maintaining computational efficiency at cinematic resolutions and durations.
Refer to the framework diagram, which illustrates the overall architecture. The input pipeline begins with multi-modal conditioning: visual references (images or video clips) are encoded via a Video-VAE, while audio references are processed through an Audio-VAE. These are combined with noisy latents and spatial-temporal masks via channel concatenation for the video branch, and with text embeddings from the MMLM encoder for both branches. The MMLM encoder produces a unified semantic context that is consumed independently by both video and audio streams through self-attention and cross-attention mechanisms.

Each transformer block in the video and audio branches follows a hybrid design: the initial M layers employ a Dual-Stream configuration where video/audio and text tokens maintain separate parameters for normalization and projections but interact during joint self-attention. This facilitates strong cross-modal alignment early in the network. The subsequent N layers transition to a Single-Stream architecture that processes concatenated tokens with shared parameters, maximizing computational efficiency. To counteract potential semantic dilution in the single-stream stages, the video branch incorporates an additional text cross-attention layer after self-attention, reinforcing textual guidance throughout generation.
Bidirectional cross-attention between video and audio streams is embedded in every transformer block, enabling continuous temporal synchronization. The audio stream attends to video features, and vice versa, ensuring that generated audio remains temporally aligned with visual content. Despite differing temporal resolutions—21 video frames versus 218 audio tokens—the authors apply Rotary Positional Embeddings (RoPE) with a frequency scaling factor of 21/218≈0.09633 to the audio tokens, aligning their temporal structure with the video stream.
Training proceeds under a flow matching objective, where the model predicts the velocity field that guides noisy latents toward clean data. The loss function jointly optimizes both video and audio branches:
Lflow=Et,zv0,za0,ϵv,ϵa[vθv(t,Zvt,Zat,c)−(zv0−ϵv)2+vθa(t,Zat,Zvt,c)−(za0−ϵa)2]where c includes multi-modal embeddings and optional masks.
For video inpainting and editing, the authors adopt a channel-concatenation formulation that unifies diverse tasks—including text-to-video, image-to-video, video extension, and spatiotemporal editing—under a single interface. The input to the video MMDiT is formed as:
Zinput=Concat(V,I,M)where V is the noisy video latent, I contains VAE-encoded conditional frames, and M is a binary mask indicating regions to be generated (0) or preserved (1). This mechanism is applied exclusively to the video stream; the audio branch generates synchronized audio from scratch conditioned on the (partially edited) video content.
To achieve high-resolution, long-duration generation efficiently, the authors introduce a cascaded Refiner module that performs joint video super-resolution and frame interpolation. As shown in the figure below, the Refiner accepts low-resolution full sequences and high-resolution keyframes from the base model, along with multi-modal conditioning signals. It employs Video Sparse Attention (VSA) to reduce computational cost by approximately 3× while preserving quality, enabling practical inference at 1080p and 32 FPS.
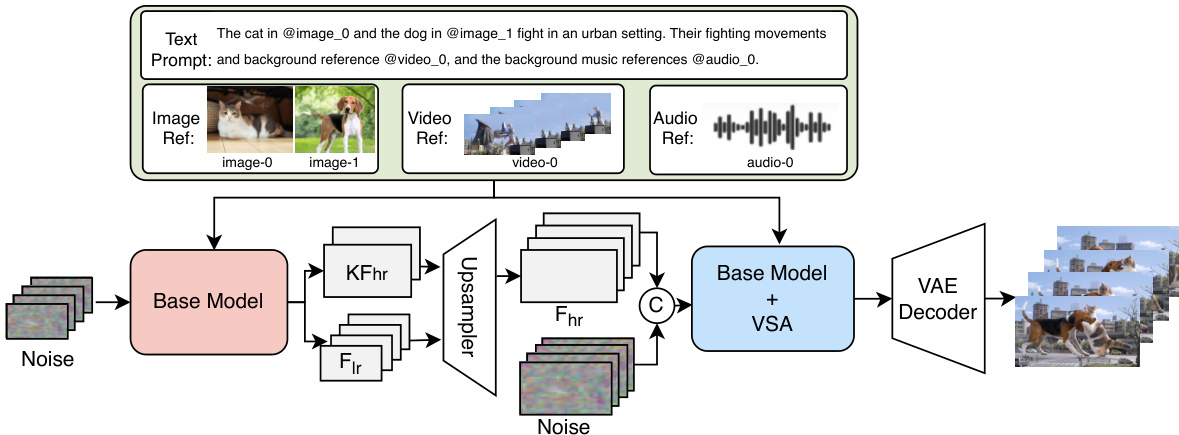
The Refiner is initialized from the pre-trained video generation model and trained under the same flow matching paradigm. It supports both unconditional enhancement and conditional inpainting via a spatial mask that guides refinement only in target regions. This design enables the model to handle complex editing scenarios—including watermark removal, subject manipulation, and global style transfer—while maintaining temporal coherence and acoustic synchronization.
Experiment
- Ranked third on the Artificial Analysis public leaderboard for text-to-video with audio, indicating strong user-preferred audiovisual synthesis among top models.
- Achieved highest overall score in human evaluations across five dimensions: Instruction Following, Audio-Visual Synchronization, Visual Quality, Motion Quality, and Audio Quality, with standout performance in Instruction Following and Motion Quality.
- Outperformed major baselines (Veo 3.1, Kling 2.6, Seedance 1.5 Pro, Wan 2.6) in pairwise comparisons, consistently rated “Good” more often across most evaluation dimensions.
- Demonstrated practical multimodal editing capabilities including subject insertion, attribute modification, background replacement, and reference-guided synthesis, validated through real-world application examples.