Command Palette
Search for a command to run...
دريم: تقييم البحث العميق باستخدام مقاييس عاملية
دريم: تقييم البحث العميق باستخدام مقاييس عاملية
الملخص
تُولِّد الوكالات البحثية العميقة تقارير بمستوى خبراء التحليل، ومع ذلك تظل عملية تقييمها تحديًا كبيرًا نظرًا لغياب الحقيقة المطلقة وطبيعة الجودة البحثية متعددة الأبعاد. وقد اقترح المعايير الحديثة مناهج مختلفة، لكنها تعاني من "وهم التجميع" (Mirage of Synthesis)، حيث يمكن أن تُخفي السلاسة السطحية القوية والانسجام في الاستشهاد بوجود أخطاء واقعية وعُقليّة خفية. نُصِف هذا الفجوة من خلال تقديم تصنيف يغطي أربعة جوانب رأسية، يكشف عن تناقض جوهري في القدرات: فالوكلاء الثابتين في التقييم يفتقرون بشكل جوهري إلى القدرات اللازمة لاستخدام الأدوات، مما يعيق قدرتهم على تقييم الصدق الزمني والواقعية المعرفية. ولحل هذه المشكلة، نقترح إطار DREAM (التصنيف البحثي العميق بالتقييمات العاملة)، الذي يُطبّق مبدأ التكافؤ في القدرات من خلال جعل عملية التقييم نفسها عاملة بذاتها. يُنظَم DREAM تقييم الأداء من خلال بروتوكول تقييم يدمج مقاييس غير مُربوطة بالاستعلام مع مقاييس مُعدّة تلقائيًا بواسطة وكيل يعتمد على استدعاء الأدوات، ما يتيح تغطية واعية زمنيًا، وتحقق مدعوم بالأساس، وتحاليل منهجية منظمة. أظهرت التقييمات المُتحكم بها أن DREAM أكثر حساسية بكثير تجاه الانهيار الواقعية والزمني مقارنة بالمعاير الحالية، مقدّمًا نموذج تقييم قابل للتوسع ومستقل عن المرجع.
One-sentence Summary
Researchers from AWS Agentic AI and Georgia Tech propose DREAM, an agentic evaluation framework that overcomes static benchmarks’ inability to assess temporal validity and reasoning by using tool-calling agents for grounded, adaptive assessment—enabling scalable, reference-free evaluation of deep research agents.
Key Contributions
- We identify the "Mirage of Synthesis" in current Deep Research Agent evaluation benchmarks, where surface fluency and citation alignment mask critical failures in factual accuracy, temporal validity, and reasoning, due to static evaluators lacking tool-use capabilities.
- We introduce a four-vertical taxonomy for Deep Research Evaluation that exposes a capability mismatch: existing evaluators cannot independently retrieve or verify information, making them unfit to assess the very dimensions they claim to measure.
- We propose DREAM, an agentic evaluation framework that enforces capability parity by using a tool-calling agent to generate adaptive metrics, demonstrating superior sensitivity to factual and temporal decay in controlled experiments.
Introduction
The authors leverage the rise of Deep Research Agents—LLMs that autonomously retrieve, synthesize, and report on complex topics—to address a critical gap in evaluation: existing benchmarks reward fluent, well-cited outputs while ignoring factual decay, logical flaws, and temporal obsolescence, a problem they term the “Mirage of Synthesis.” Prior methods rely on static evaluators or fixed datasets that lack the tools to verify claims against live, evolving sources, creating a capability mismatch. Their main contribution is DREAM, an agentic evaluation framework that mirrors the researcher’s own tool-using behavior—dynamically generating adaptive metrics via a tool-calling agent to verify facts, assess reasoning, and track temporal validity, thereby offering a scalable, reference-free method more sensitive to real-world degradation than current benchmarks.
Dataset
-
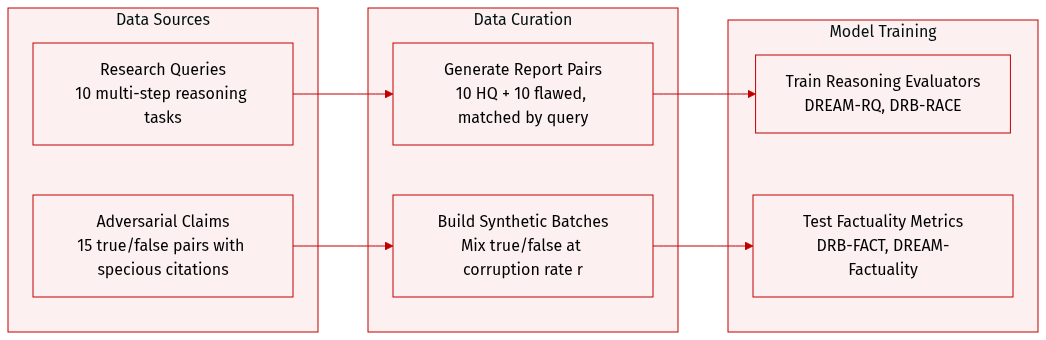
The authors use a curated set of 10 research queries designed to test multi-step reasoning across domains like policy analysis and causal explanation. These queries were processed using Smolagents’ Deep Research agent to generate 20 reports: 10 high-quality (logically sound, well-supported) and 10 malformed (intentionally flawed with unsupported claims, circular reasoning, cherry-picked evidence) — forming 10 matched pairs for controlled comparison.
-
For evaluating factual grounding beyond citation alignment, they built a 15-pair adversarial dataset. Each pair includes a ground truth claim with a valid source and a false claim with a specious but citation-aligned source (e.g., outdated stats, fringe narratives). These false claims pass standard citation faithfulness checks but contradict objective reality.
-
To test metric sensitivity, they bypassed claim extraction and directly constructed synthetic evaluation batches of size 15, mixing true and false variants at varying corruption rates (r ∈ [0,1]). These were fed into DRB-FACT and DREAM-Factuality evaluators to measure how each responds to increasing misinformation.
-
The datasets are used to benchmark evaluation frameworks: DREAM-RQ and DRB-RACE assess reasoning quality on the report pairs, while DRB-FACT and DREAM-Factuality are tested on the adversarial claim pairs to expose their differing sensitivity to real-world falsehoods versus citation alignment.
Method
The authors leverage a two-phase agentic evaluation framework called DREAM to dynamically construct and execute query-specific evaluation protocols for deep research agents. The system is designed to close capability gaps between the evaluator and the agent being assessed by matching each metric to an evaluator with the appropriate tooling and reasoning capacity. The overall architecture is modular, comprising a Protocol Creation phase that generates adaptive and static metrics, and a Protocol Execution phase that routes each metric to a specialized evaluator.
In the Protocol Creation phase, a Protocol Creation Agent—implemented as a CodeAgent equipped with retrieval tools such as web search, ArXiv, and GitHub—analyzes the research query to generate adaptive metrics. These include Key-Information Coverage (KIC), which transforms essential facts into verifiable yes/no questions, and Reasoning Quality (RQ), which generates open-ended questions paired with structured validation plans specifying how to extract and cross-reference reasoning chains from the report and external sources. Static metrics, which apply uniformly across tasks, are predefined and include Writing Quality (WQ), Factuality, Citation Integrity (CI), and Domain Authoritativeness (DA). As shown in the figure below, this phase outputs a comprehensive evaluation protocol that combines both adaptive and static components.
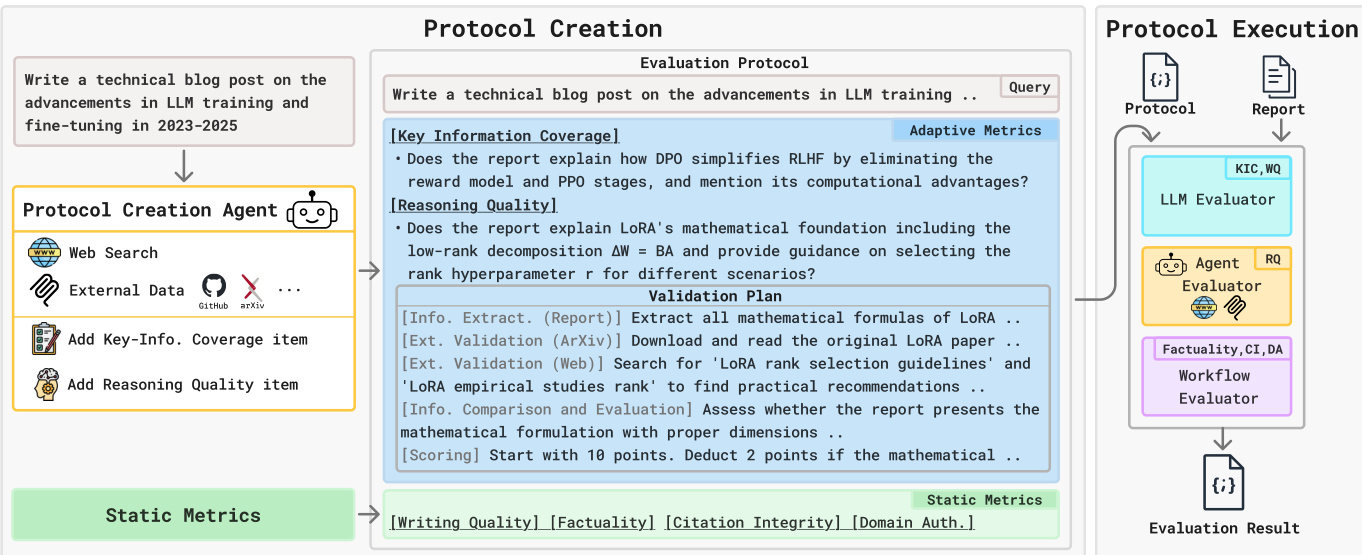
In the Protocol Execution phase, DREAM routes each metric to one of three evaluator types based on capability parity. The LLM Evaluator handles metrics requiring judgment without external tool use: it assesses Writing Quality using fixed rubrics and verifies Key-Information Coverage against the agent-generated checklist. The Agent Evaluator, also a CodeAgent, executes the Reasoning Quality metric by autonomously following the validation plan, retrieving external evidence, and scoring the coherence and validity of the report’s reasoning. The Workflow Evaluator implements a multi-stage pipeline for Factuality, Citation Integrity, and Domain Authoritativeness. For Factuality, it extracts salient claims, generates neutralized search queries to avoid confirmation bias, and performs dual-stream evidence extraction to retrieve both supporting and contradicting evidence before assigning a judgment. Citation Integrity is computed as the harmonic mean of Claim Attribution (CA) and Citation Faithfulness (CF), ensuring that both citation presence and content alignment are required for a high score. Domain Authoritativeness evaluates the credibility of cited domains by extracting root domains, scoring them on a 1–10 scale based on institutional reputation, and averaging normalized scores.
Refer to the framework diagram for a visual breakdown of the evaluator types and their respective metric assignments. The LLM Evaluator handles WQ and KIC, the Agent Evaluator handles RQ, and the Workflow Evaluator handles Factuality, CI, and DA. Each evaluator’s internal workflow is modular and designed to isolate specific verification tasks—for example, the Workflow Evaluator’s Factuality module includes claim extraction, neutral query generation, dual-stream evidence retrieval, and final judgment.
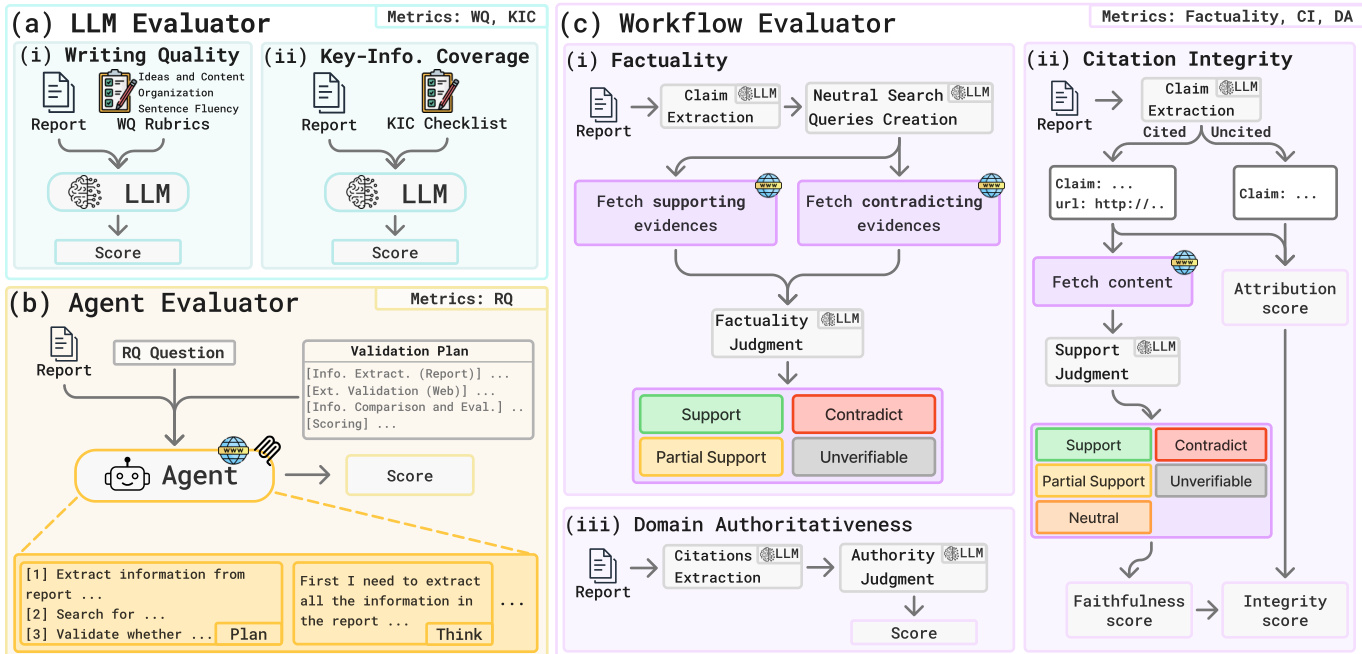
The scoring for each metric is formalized to ensure quantitative comparability. For example, Factuality is computed as a weighted average of supported and partially supported claims:
Ft=Nsupp,t+Npart,t+Ncon,tNsupp,t+0.5Npart,tCitation Integrity is defined as the harmonic mean of CA and CF:
CI=CA+CF2⋅CA⋅CFAnd Key-Information Coverage is a simple recall rate over the K generated questions:
KICt=K1k=1∑Kvk,tThis architecture enables DREAM to adapt to the open-ended nature of deep research tasks while maintaining rigorous, grounded evaluation through agentic tool use and multi-faceted verification pipelines.
Experiment
- DREAM introduces a novel evaluation framework that dynamically constructs adaptive metrics via agentic reasoning and external tool access, overcoming limitations of static human-crafted rubrics or LLM-generated checklists.
- Human evaluations confirm that agent-generated protocols are highly interpretable, clear, and verifiable, especially when retrieval capabilities are integrated.
- DREAM demonstrates superior sensitivity to temporal obsolescence, penalizing outdated reports far more effectively than static benchmarks that rely on fixed criteria.
- It reliably detects subtle reasoning flaws in fluent, well-structured reports—where existing metrics often fail or even reward flawed content.
- DREAM exposes the insufficiency of citation alignment alone for factual correctness, showing that well-cited claims can still be factually wrong without external verification.
- Benchmarking reveals that leading open-source research agents produce high-quality, fluent reports but suffer from systemic citation grounding failures, either citing inaccurately or rarely citing at all.
- DREAM’s evaluation signals are robust across different LLM backbones, maintaining consistent agent rankings despite minor score fluctuations.
The authors use report length statistics to compare three open-source deep research agents across three benchmarks, revealing that Smolagents Open DR consistently generates significantly longer and more variable reports, while Tongyi Deep Research produces the most concise and stable outputs. LangChain Open DR falls in between, with moderate length and variability. These differences in output scale persist across datasets, suggesting distinct design priorities or generation behaviors among the agents.

The authors use an agent-based framework to generate evaluation criteria, finding that combining multi-step reasoning with external retrieval significantly improves the relevance, verifiability, and clarity of generated metrics compared to static LLMs or agents without tool access. Human evaluators consistently rate retrieval-augmented protocols higher, confirming that grounding evaluation in external evidence enhances both interpretability and validation soundness. This structural advantage enables more reliable detection of temporal obsolescence, reasoning flaws, and factual inaccuracies that static or citation-aligned methods miss.

The authors use DREAM to evaluate three deep research agents across multiple judge models, revealing that while absolute scores vary by evaluator, the relative performance rankings of the agents remain consistent. Smolagents Open DR consistently leads in adaptive metrics like Key-Information Coverage and Reasoning Quality, while LangChain Open DR shows stronger citation attribution but weaker faithfulness. Tongyi Deep Research scores highest in Writing Quality but exhibits near-zero citation integrity, highlighting a persistent gap in reliable source grounding across open-source systems.

The authors use DREAM to benchmark three open-source deep research agents across multiple datasets, revealing that while agents can produce fluent and factually grounded reports, they consistently fail to establish reliable citation integrity. Smolagents Open DR leads in most adaptive and static metrics except citation-related ones, while LangChain Open DR shows stronger citation attribution but poor faithfulness. Results confirm that current agents lack robust grounding to external sources, exposing a critical gap in trustworthy research synthesis despite strong content quality.

The authors use DREAM-KIC to evaluate temporal sensitivity in deep research reports, revealing that it consistently penalizes outdated information, unlike static metrics such as DRB-RACE, which show minimal or inconsistent degradation with older knowledge cutoffs. Results demonstrate that agentic evaluation grounded in up-to-date evidence is necessary to detect temporal obsolescence, as static rubrics fail to capture time-sensitive factual gaps.
