Command Palette
Search for a command to run...
مهارات Agent لنماذج Large Language Models: البنية، والاكتساب، والأمن، والمسار المستقبلي
مهارات Agent لنماذج Large Language Models: البنية، والاكتساب، والأمن، والمسار المستقبلي
Ranjun Xu Yang Yan
الملخص
يمثل الانتقال من النماذج اللغوية المتجانسة (Monolithic language models) إلى الوكلاء (Agents) المكونين من وحدات برمجية ومزودين بمهارات محددة، تحولاً جذرياً في كيفية نشر واستخدام النماذج اللغوية الكبيرة (LLMs) في التطبيقات العملية. فبدلاً من ترميز كافة المعارف الإجرائية ضمن أوزان النموذج (Model weights)، تتيح "مهارات الوكيل" (Agent skills) — وهي حزم قابلة للتركيب من التعليمات، والتعليمات البرمجية، والموارد التي يقوم الوكيل بتحميلها عند الطلب — توسيع القدرات بشكل ديناميكي دون الحاجة إلى إعادة التدريب. ويتجسد هذا التحول في نموذج يعتمد على الإفصاح التدريجي (Progressive disclosure)، وتعريفات المهارات القابلة للنقل، والتكامل مع بروتوكول سياق النموذج (Model Context Protocol - MCP).تقدم هذه الدراسة مسحاً شاملاً لمشهد مهارات الوكيل، والذي تطور بسرعة كبيرة خلال الأشهر القليلة الماضية. وقد قمنا بتنظيم هذا المجال وفق أربعة محاور رئيسية:(i) الأسس الهيكلية (Architectural foundations): حيث نبحث في مواصفات SKILL.md، والتحميل التدريجي للسياق (Progressive context loading)، والأدوار التكاملية بين المهارات وبروتوكول MCP.(ii) اكتساب المهارات (Skill acquisition): ويشمل التعلم التعزيزي باستخدام مكتبات المهارات (SAGE)، والاكتشاف الذاتي للمهارات (SEAgent)، والتركيب التجميعي للمهارات (Compositional skill synthesis).(iii) النشر على نطاق واسع (Deployment at scale): ويتضمن حزمة وكيل استخدام الكمبيوتر (CUA stack)، والتقدم في ربط واجهة المستخدم الرسومية (GUI grounding)، والتقدم في المقاييس المرجعية (benchmark) مثل OSWorld و SWE-bench.(iv) الأمن (Security): حيث تكشف التحليلات التجريبية الأخيرة أن 26...
One-sentence Summary
Ranjun Xu and Yang Yan provide a recent survey defining agent skills as modular packages enabling dynamic capability extension without retraining and organizing the field across architectural foundations such as SKILL.md and the Model Context Protocol, acquisition methods including SAGE and SEAgent, deployment at scale with the computer-use agent stack, GUI grounding advances, and benchmarks on OSWorld and SWE-bench, and security analyses.
Key Contributions
- This survey organizes the agent skills landscape along four axes covering architectural foundations, skill acquisition, deployment, and security. It examines specifications like SKILL.md and benchmarks such as OSWorld to map the field's rapid evolution.
- A Trust and Lifecycle Governance Framework is introduced to address security challenges by decoupling trust decisions from binary accept or reject actions. This approach aligns permissions with provenance and verification depth to manage the tension between openness and safety.
- The analysis highlights a disconnect between model-internal skill learning in systems like SAGE and SEAgent and the ability to externalize skills as portable, auditable artifacts. Bridging this gap would unify acquisition and deployment paradigms for better governance.
Introduction
The transition to modular agent skills resolves the tension between general-purpose models and the specialized procedural expertise required for real-world deployment. Prior approaches such as fine-tuning are costly and lack composability, while retrieval-augmented generation offers passive knowledge that cannot execute complex workflows. The authors deliver the first comprehensive survey focused specifically on this emerging skill abstraction layer instead of broad agent tool use. They categorize the landscape across architecture, acquisition, deployment, and security while proposing a new Skill Trust and Lifecycle Governance Framework to mitigate vulnerabilities in community-contributed skills.
Dataset
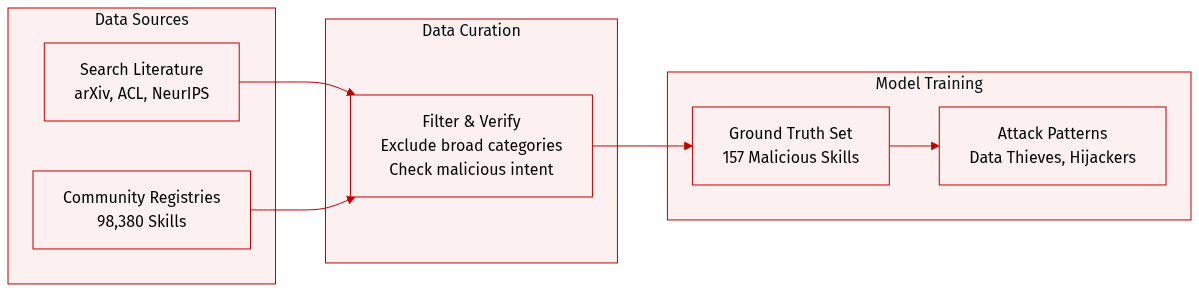
Dataset Composition and Sources
- The authors gather literature from arXiv, ACL Anthology, NeurIPS, ICML, ICLR proceedings, and Anthropic publications.
- A ground truth dataset is constructed from two community registries containing 98,380 skills.
Key Details for Each Subset
- Survey data targets skill abstraction layers and excludes general LLM agent architectures.
- The malicious skills subset includes 157 confirmed cases with 632 identified vulnerabilities.
- Attack patterns are categorized as Data Thieves or Agent Hijackers.
Data Usage and Processing
- Search queries focus on terms like agent skills and computer use agents.
- Skills undergo behavioral verification to establish ground truth for malicious intent.
- Analysis reveals one industrialized actor is responsible for 54.1% of confirmed cases.
Metadata and Filtering
- Filtering rules exclude earlier surveys covering broad tool use taxonomies.
- Metadata construction identifies specific vulnerability counts and attack archetypes per skill.
Method
The proposed framework centers on a structured approach to encoding procedural knowledge, termed "Agent Skills." This methodology addresses the limitations of standard context windows by employing a progressive disclosure architecture. Rather than loading entire skill definitions at once, the system utilizes a three-tiered loading mechanism to balance information density with computational efficiency.
Refer to the framework diagram below to visualize this hierarchical structure.
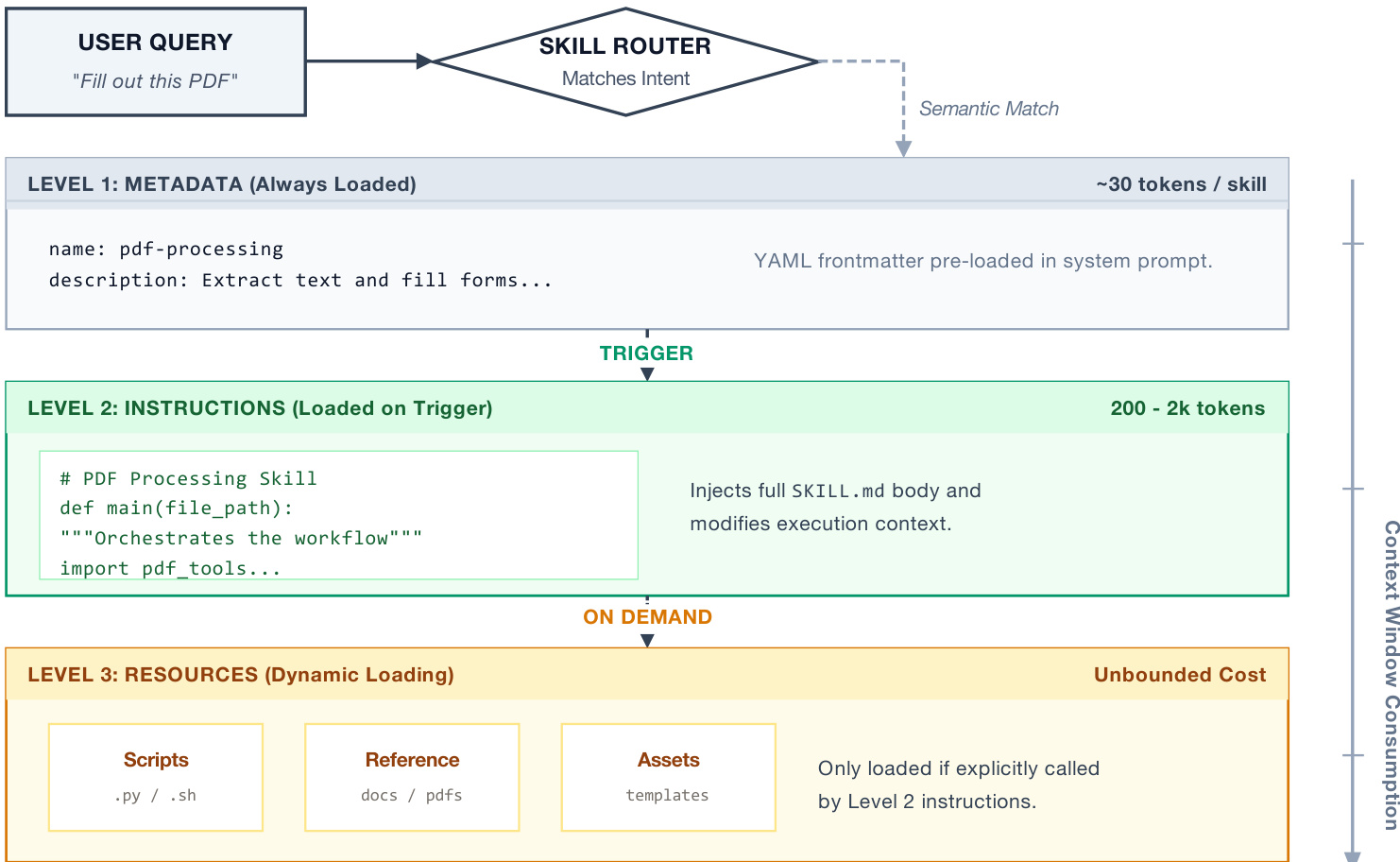
Level 1 consists of metadata, such as the skill name and description, which is pre-loaded into the system prompt. This requires only approximately 30 tokens per skill, allowing for large libraries without significant context penalty. Level 2 contains the full procedural instructions found in the SKILL.md body. These are loaded only when a specific skill is triggered by a semantic match. Level 3 comprises dynamic resources, including scripts, reference documents, and assets. These are loaded strictly on demand if explicitly called by the Level 2 instructions. This design ensures that the agent maintains access to deep procedural knowledge while keeping the active context window minimal.
The execution of these skills follows a specific lifecycle within the agentic stack. When a user intent is specified, a Skill Router matches the request to a skill in the library. The execution process involves two distinct phases: the injection of the skill's instructions and resources into the conversation context as a hidden message, and the modification of the agent's execution environment to activate pre-approved tools.
The operational flow is detailed in the architecture diagram below.
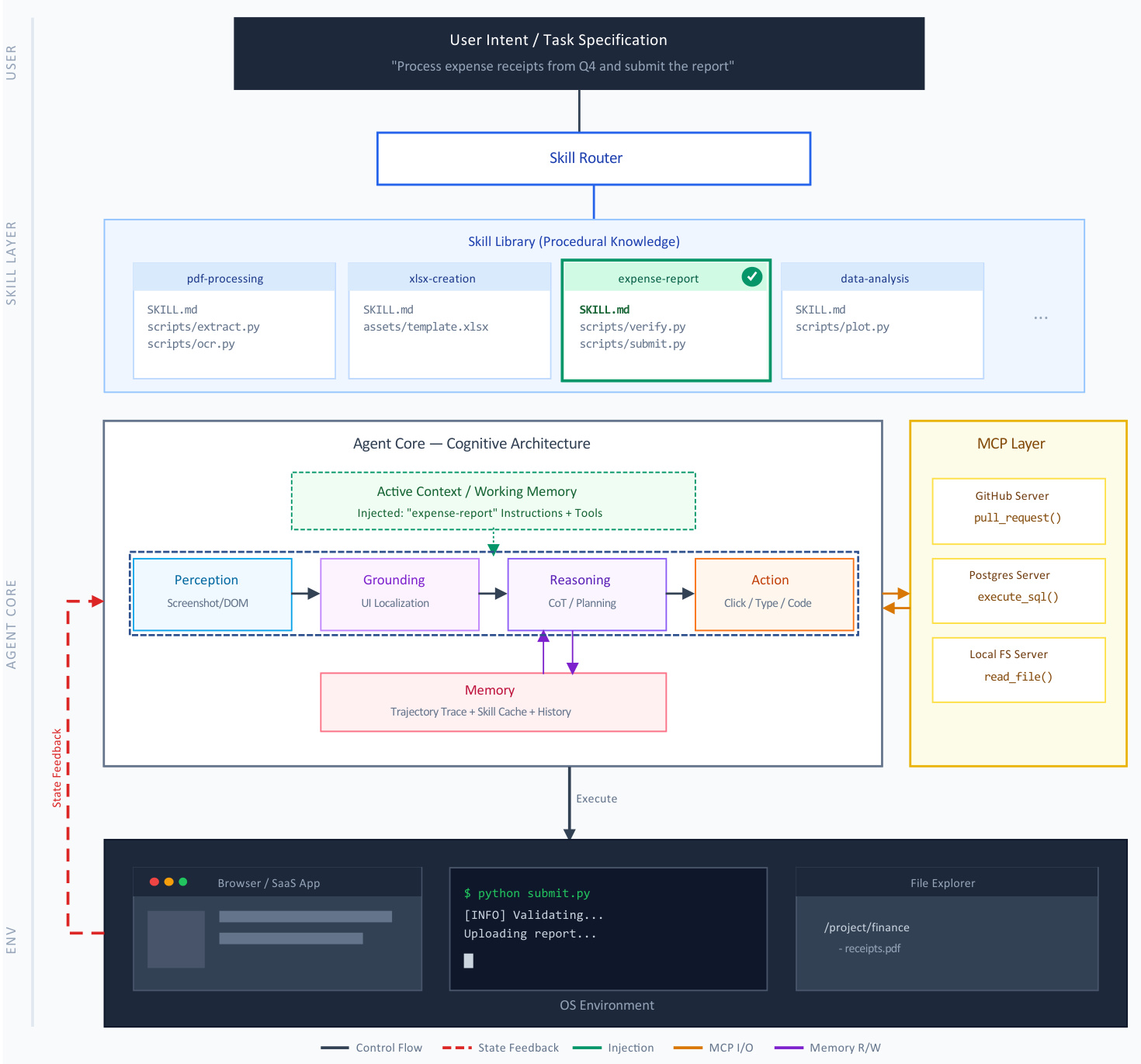
The Agent Core processes the enriched context through a cycle of Perception, Grounding, Reasoning, and Action. This core interacts with an external Model Context Protocol (MCP) layer, which standardizes connections to data sources and tools like GitHub or PostgreSQL. Skills and MCP function as orthogonal layers. While MCP provides the connectivity primitives, the skills provide the procedural intelligence, instructing the agent on how to interpret outputs and handle failures.
To ensure safety across diverse acquisition pathways, the authors propose a Skill Trust and Lifecycle Governance Framework. This system accounts for the varying origins of skills, ranging from human-authored documents to RL-learned or autonomous agents.
The governance model is illustrated in the diagram below.
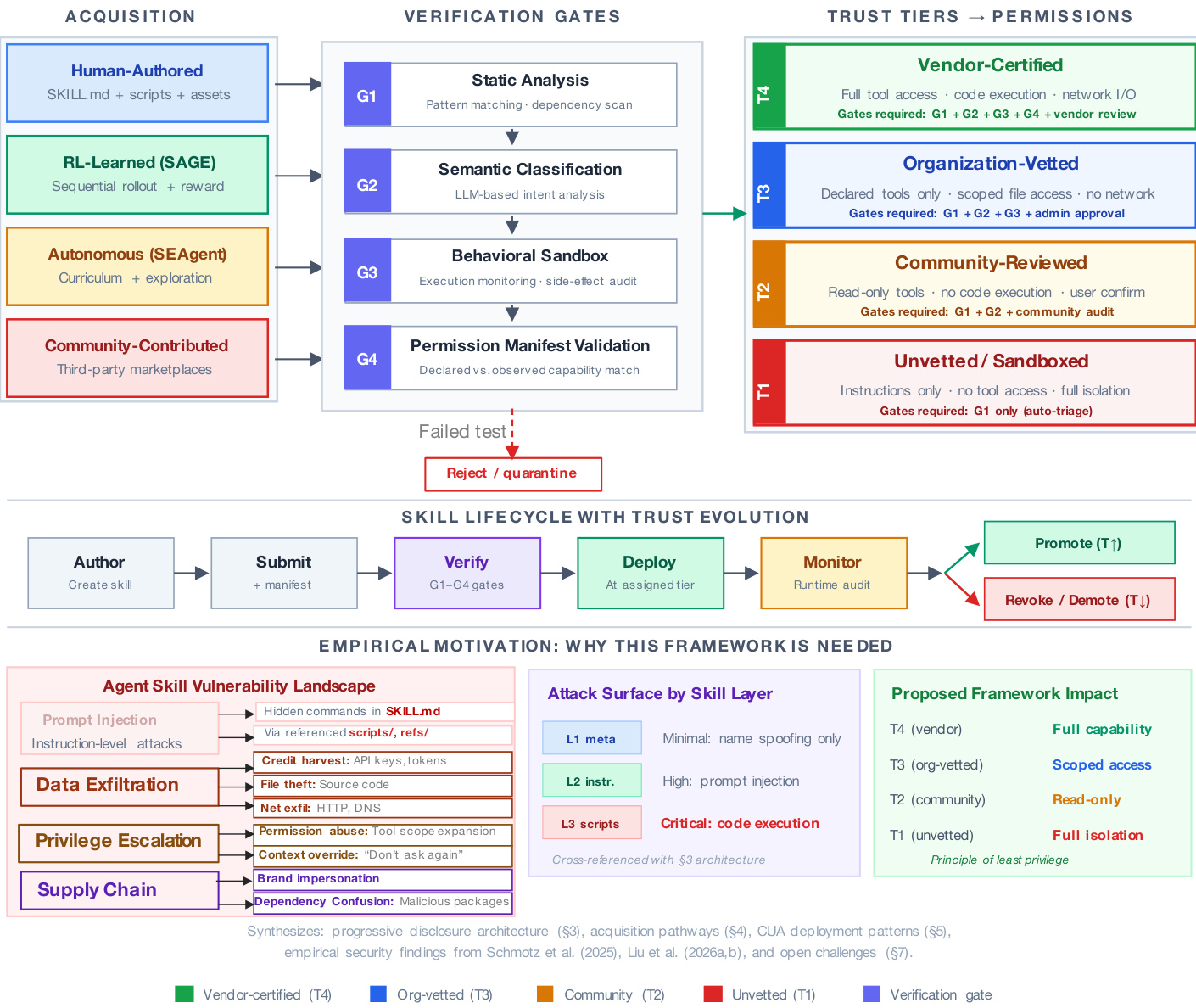
Security is enforced through four sequential verification gates. G1 applies static analysis and dependency scanning. G2 uses LLM-based semantic classification to detect intent mismatches. G3 executes the skill in a behavioral sandbox to monitor side effects. G4 validates a permission manifest against observed behavior. Based on the results of these gates and the skill's provenance, the framework assigns the skill to a specific trust tier. This tiered approach adheres to the principle of least privilege. For example, unvetted skills (T1) receive instructions-only access with full isolation, whereas vendor-certified skills (T4) are granted full tool access and code execution capabilities. This mapping aligns governance decisions with the specific attack surface of the progressive disclosure levels, ensuring that executable scripts are only accessible to highly trusted tiers.
Experiment
Experiments validate that integrating skill libraries via reinforcement learning, autonomous discovery, and structured representations significantly improves task completion and efficiency across software environments. While GUI grounding and compositional synthesis enable smaller models to outperform larger counterparts on complex benchmarks, challenges remain in professional applications and extended tasks. Security analyses further indicate that these architectures introduce critical risks, such as prompt injection and data exfiltration vulnerabilities within marketplace repositories.
The the the table outlines the current performance landscape of Computer-Using Agents across diverse benchmarks, identifying top-performing models and their success rates relative to human baselines. It demonstrates that while agents have reached human-level proficiency on certain general operating system tasks, significant performance gaps persist in specialized domains like professional applications. Proprietary models achieve performance comparable to human baselines on OSWorld-V. Specialized agents like CUA-Skill lead performance on Windows-specific benchmarks. Success rates are generally higher for coding tasks than for professional GUI interactions.
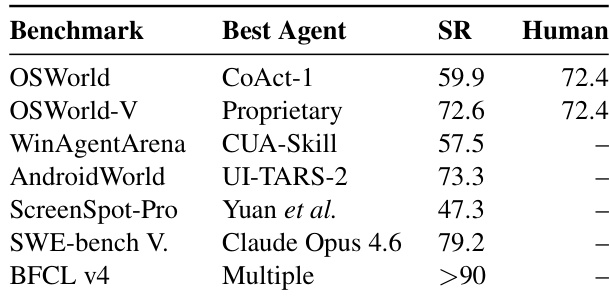
This evaluation assesses the performance landscape of Computer-Using Agents across diverse benchmarks relative to human baselines. Results indicate that while proprietary models achieve human-level proficiency on general operating system tasks and specialized agents excel in Windows-specific environments, significant gaps remain in professional application domains. Additionally, success rates are generally higher for coding tasks than for professional graphical user interface interactions, highlighting ongoing challenges in complex GUI manipulation.