Command Palette
Search for a command to run...
ديب جين 1.0: نموذج متعدد الوسائط موحد خفيف الوزن للتقدم في توليد الصور وتحريرها
ديب جين 1.0: نموذج متعدد الوسائط موحد خفيف الوزن للتقدم في توليد الصور وتحريرها
الملخص
النماذج الموحدة الموحدة الحالية لتخليق الصور وتحريرها تعتمد عادةً على أحجام كبيرة من المعاملات (مثلاً >10B)، مما يؤدي إلى تكاليف تدريب باهظة ومساحات تشغيل كبيرة. في هذه الدراسة، نقدم DeepGen 1.0، وهو نموذج خفيف الوزن بحجم 5B يحقق قدرات شاملة تتفوق أو توازي نماذج أكبر بكثير. وللتغلب على القيود التي تواجه النماذج المدمجة فيما يتعلق بالفهم الدلالي والتحكم الدقيق، نُقدّم إطار التوافق العميق عبر القنوات المتعددة (SCB)، وهو إطار مُعدّ لمحاذاة عميقة يستخرج ميزات هرمية من طبقات متعددة لنموذج التمثيل البصري-اللغوي (VLM) ويدمجها مع "رموز تفكير" قابلة للتعلم لتزويد النموذج التوليدي بدلالة منظمة وغنية بالاستدلال. كما صممنا استراتيجية تدريب مبنية على البيانات وتشمل ثلاث مراحل متسلسلة: (1) التدريب الأولي على المُحاذاة باستخدام أزواج صورة-نص وثلاثيات تحرير على نطاق واسع لتوحيد تمثيلات VLM وDiT، (2) التدريب المُراقب المشترك على خليط عالي الجودة من المهام المتعلقة بالتخليق، والتحرير، والاستدلال لتعزيز القدرات الشاملة، و(3) التعلم المعزز باستخدام خوارزمية MR-GRPO، التي تعتمد على مزيج من دوال المكافأة وإشارات المراقبة، مما أدى إلى تحسين كبير في جودة التوليد والانسجام مع تفضيلات الإنسان، مع الحفاظ على استقرار عملية التدريب وتجنب العيوب البصرية. وعلى الرغم من تدريبه على عينات فقط بحوالي 50 مليون عينة، يحقق DeepGen 1.0 أداءً متفوقًا في مجموعة متنوعة من المعايير، متفوقًا على نموذج HunyuanImage بحجم 80B بنسبة 28% في معيار WISE، وعلى نموذج Qwen-Image-Edit بحجم 27B بنسبة 37% في معيار UniREditBench. وبإطلاق كود التدريب، والوزن، والبيانات مفتوحة المصدر، نوفر بديلاً فعّالاً وعالي الأداء لتمكين البحث الموحد متعدد الوسائط وجعله متاحًا للجميع.
One-sentence Summary
Researchers from Shanghai Innovation Institute, Fudan, USTC, and others propose DeepGen 1.0, a 5B lightweight multimodal model using Stacked Channel Bridging and staged training to outperform larger models in generation and editing, achieving state-of-the-art results while democratizing access via open-sourced code and datasets.
Key Contributions
- DeepGen 1.0 introduces a lightweight 5B-parameter unified model for image generation and editing, challenging the assumption that large-scale models (>10B) are necessary for high performance, and achieves state-of-the-art results despite training on only ~50M samples.
- It proposes Stacked Channel Bridging (SCB), a novel alignment framework that fuses hierarchical VLM features with learnable “think tokens” to deliver structured, reasoning-rich guidance to the DiT backbone, enhancing semantic understanding and fine-grained control without increasing model size.
- Through a three-stage data-centric training pipeline—including alignment pre-training, joint supervised fine-tuning, and reinforcement learning with MR-GRPO—DeepGen 1.0 outperforms larger models like 80B HunyuanImage (by 28% on WISE) and 27B Qwen-Image-Edit (by 37% on UniREditBench), while avoiding visual artifacts and maintaining training stability.
Introduction
The authors leverage a unified VLM-DiT architecture to build DeepGen 1.0, a 5B-parameter model that handles image generation, editing, and reasoning tasks—challenging the assumption that only massive models (10B+) can deliver high-quality, semantically accurate visual outputs. Prior work relied on expensive, multi-model setups or large-scale training data, while smaller models failed to match performance due to weak cross-modal alignment and limited reasoning support. DeepGen 1.0 overcomes these limits with Stacked Channel Bridging (SCB), which fuses multi-layer VLM features and learnable “think tokens” to guide the DiT with structured, hierarchical semantics, plus a three-stage training pipeline that emphasizes data efficiency and human preference alignment via MR-GRPO. The result is a compact model that outperforms much larger counterparts—including 80B and 27B baselines—on reasoning and editing benchmarks, while being trained on just 50M samples and fully open-sourced for broader adoption.
Dataset
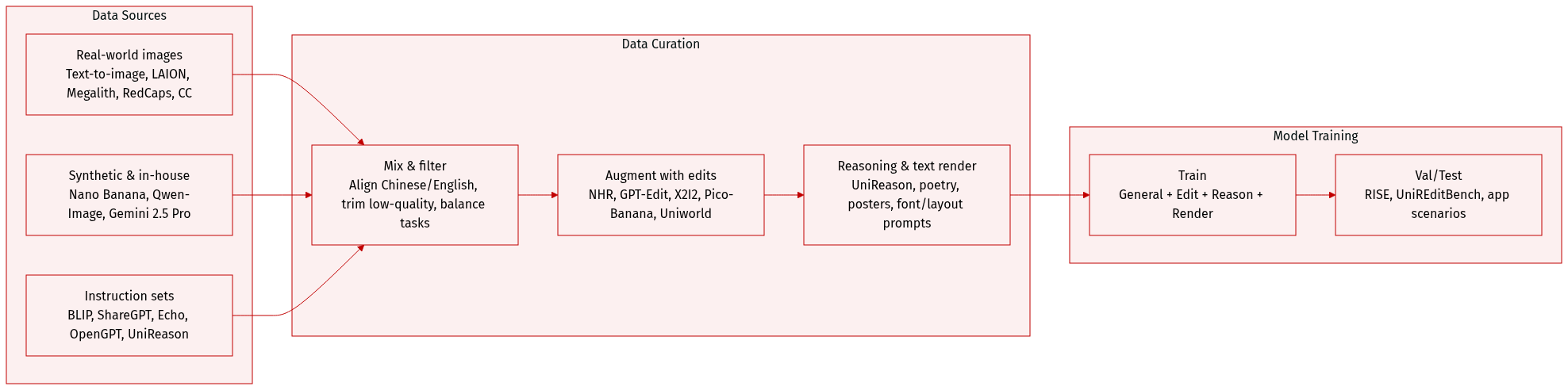
The authors use a diverse, multi-source training dataset combining real-world, synthetic, and curated open-source data to support general generation, editing, reasoning, text rendering, and application-specific tasks.
-
General Generation:
- Sources: Text-to-image-2M, LAION-Aesthetic-6M, Megalith-10M, RedCaps-5M, CC-12M.
- Instruction fine-tuning: BLIP-3o (60k), ShareGPT-4o-Image (45k), Echo-4o-Image (100k), OpenGPT4o-Image (40k), plus 10M in-house samples (3:1 long-to-short prompt ratio).
- Augmented with ~50k synthetic photorealistic images via Nano Banana, paired with fine-grained prompts in both Chinese and English.
-
General Editing:
- Sources: NHR-Edit (720k), GPT-Image-Edit (1.5M), ShareGPT-4o-Image-Edit (50k), OpenGPT4o-Image-Edit (40k), Nano-banana-consist (150k), Pico-Banana (250k), X2I2 (1.6M), Uniworld-Edit (1.2M), plus 1.1M in-house editing samples (Chinese and English).
-
Reasoning-based Generation and Editing:
- Sources: UniReason (150k generation, 100k editing samples) covering cultural commonsense, natural science, spatial, temporal, and logical reasoning.
-
Text Rendering & Application Scenarios:
- Sources: Multimodal QA datasets for captions; Gemini 2.5 Pro generates diverse rendering attributes (font, layout, color); Qwen-Image synthesizes 500k text-rendering images.
- Extended with 60k application samples (e.g., Chinese poetry, poster design).
-
Processing & Usage:
- Datasets are mixed per training stage as detailed in Appendix A, Table 8.
- No explicit cropping strategy mentioned; metadata is constructed via prompt engineering and synthetic image generation pipelines.
- All subsets are aligned to support multilingual (Chinese/English) and multimodal instruction following.
Method
The authors leverage a VLM-DiT architecture to unify multimodal understanding with high-fidelity image generation, as illustrated in the framework diagram. The system begins with a pretrained vision-language model (VLM), specifically Qwen-2.5-VL (3B), which processes interleaved visual and textual inputs—comprising system prompts, reference images, and user instructions—through its transformer blocks. To enhance reasoning, a fixed set of learnable “think tokens” is injected into the input sequence, enabling implicit Chain-of-Thought behavior across all VLM layers via self-attention. These tokens progressively summarize hidden representations, enriching the model’s ability to extract and retain knowledge.
Rather than relying on a single-layer VLM output, the authors introduce the Stacked Channel Bridging (SCB) framework to aggregate features from multiple layers. Six hidden states are uniformly sampled across low-, mid-, and high-level VLM blocks, preserving both fine-grained visual details and semantic abstractions. These selected states, including the think token representations, are stacked along the channel dimension and projected via a lightweight MLP to match the DiT’s input width. A Transformer encoder then fuses these multi-layer features into a robust conditional input c∈RL×dDiT, formalized as:
c=Encoder(MLP(Concatch(x1,…,xn))).This conditional signal is fed into the DiT decoder—initialized from SD3.5-Medium (2B)—which generates images through a sequence of DiT blocks conditioned on both the multimodal context and a noisy latent input. The DiT is further guided by a VAE encoder for latent space alignment and a noisy refiner for iterative refinement. The entire pipeline is connected via a streamlined connector module based on SigLIP and six transformer layers, maintaining a compact 5B parameter footprint.
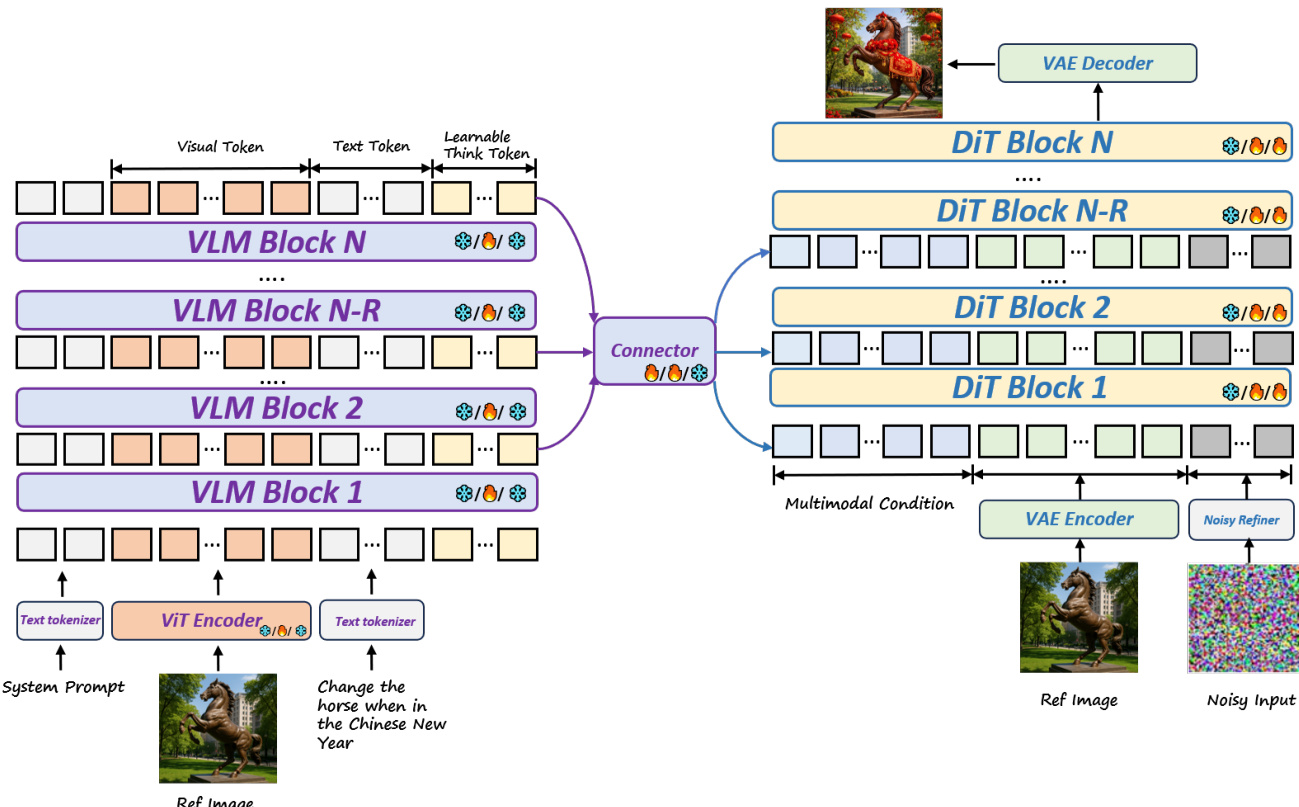
Training proceeds in two main stages. In Stage 2, the authors perform joint supervised fine-tuning over 400,000 iterations on a diverse multi-task dataset encompassing general text-to-image generation, reasoning-based generation, text rendering, and image editing. To preserve the VLM’s pretrained capabilities, they apply LoRA for parameter-efficient adaptation. Images are processed at 512×512 resolution with dynamic aspect ratio preservation, and optimization uses a learning rate of 5×10−5 with 20,000 warm-up steps.
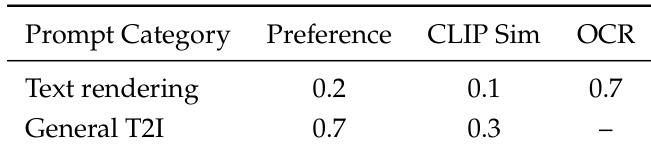
In Stage 3, reinforcement learning is applied via the MR-GRPO framework to align outputs with human preferences. The model samples a group of G=8 images per prompt using a noise-preserving stochastic sampler that maintains scheduler-consistent noise levels, ensuring stable reward signals. Each generated image is evaluated by three complementary reward functions: a VLM-based pairwise preference model for semantic and visual quality, an OCR reward for text rendering accuracy, and a CLIP similarity score for overall alignment. Rewards are normalized per group and aggregated with category-specific weights—prioritizing OCR for text-rendering prompts and preference rewards for general generation.
The policy optimization objective combines GRPO with an auxiliary supervised diffusion loss to prevent capability degradation:
Ltotal=(1−λ)LGRPO+λLSFT,where LGRPO includes clipped advantage terms and KL regularization computed in velocity space:
DKL(πθ∣∣πref)=∣∣v^θ(xt,t)−v^ref(xt,t)∣∣2.Training runs for 1,500 steps with a learning rate of 2×10−6, using 50 denoising steps per sample and batch-wise advantage normalization to preserve multi-reward granularity.
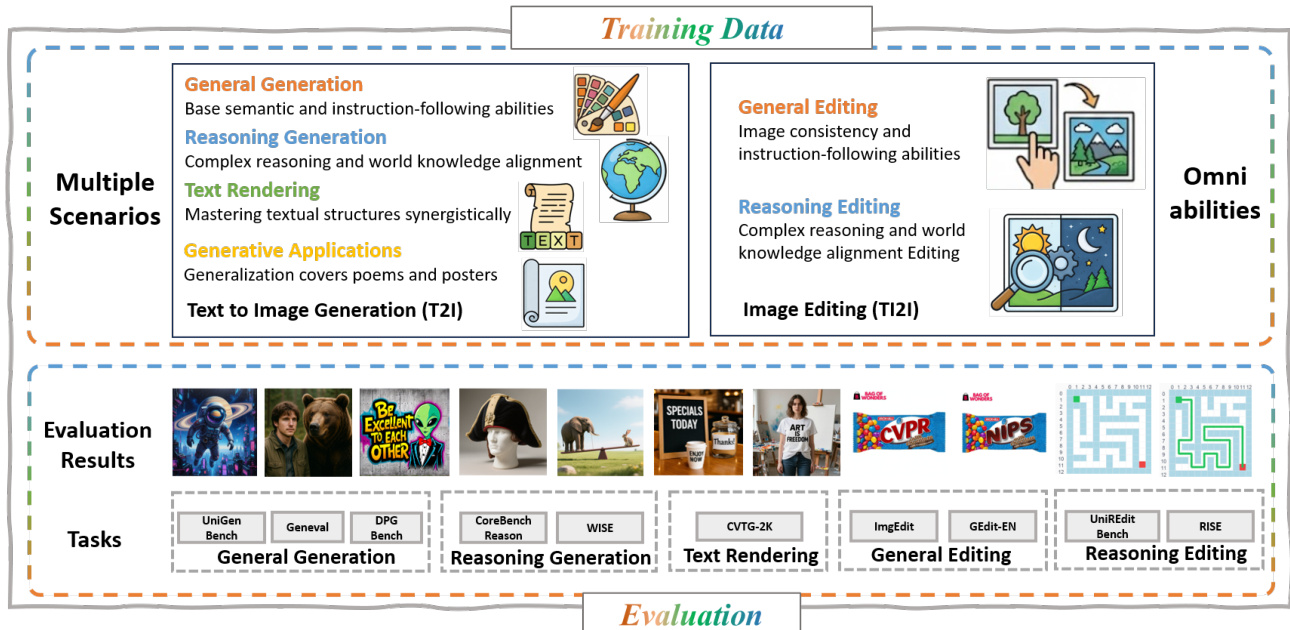
Experiment
- Alignment pre-training successfully bridges VLM and DiT using only connector and think tokens, enabling foundational text-to-image and editing capabilities without full model tuning.
- DeepGen 1.0 excels across general generation and editing benchmarks, matching or surpassing larger models despite its compact 5B parameter size, demonstrating strong semantic alignment and instruction following.
- The model achieves top-tier reasoning performance on world-knowledge tasks, outperforming open-source peers and narrowing gaps with closed-source systems across cultural, scientific, and logical domains.
- Reasoning-based editing shows robustness in real and game-world scenarios, leading in key benchmarks and exceeding some closed-source models in overall performance.
- Text rendering improves significantly with RL training, enhancing word accuracy and legibility while preserving semantic alignment, validating the effectiveness of the reinforcement learning framework.
- Ablation studies confirm that stacked channel bridging, think tokens, and VLM activation are critical for performance, particularly in reasoning tasks, by enriching multimodal conditioning and knowledge distillation.
- RL training stability and effectiveness rely on auxiliary SFT loss, KL regularization, and reward-wise advantage normalization, which collectively prevent capability drift and ensure balanced multi-objective optimization.
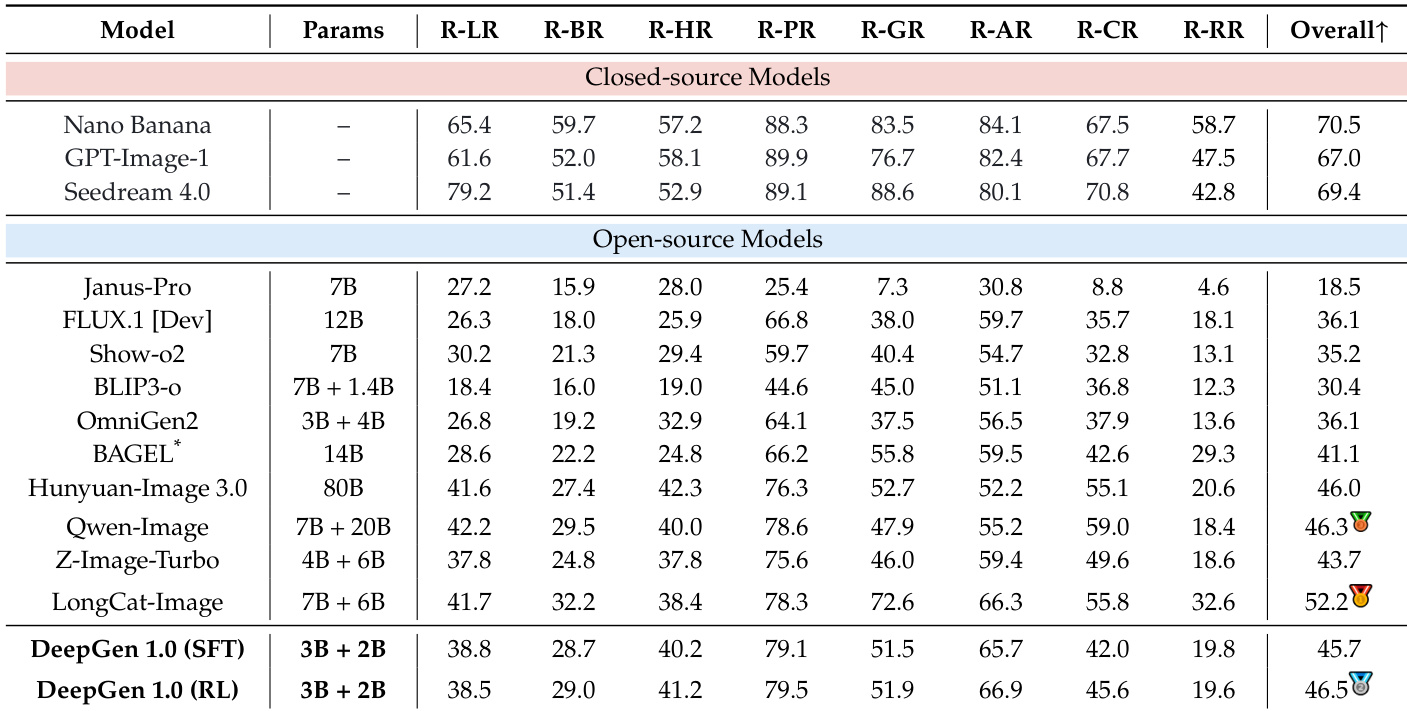
The authors evaluate DeepGen 1.0 on reasoning-based text-to-image generation using the T2I-CoREBench benchmark, which covers eight distinct reasoning categories. Results show that DeepGen 1.0, with only 5B parameters, matches or slightly surpasses larger open-source models across most reasoning types and achieves a competitive overall score, demonstrating broad reasoning capability despite its compact size.
The authors use a multi-objective reward framework to balance text rendering and general image generation, assigning higher preference weight to general T2I tasks while relying on OCR accuracy to specifically guide text synthesis. Results show that this approach prioritizes overall image quality during generation while still enabling precise text rendering through targeted signal alignment.
The authors evaluate DeepGen 1.0’s architectural components by ablating key elements and observe consistent performance drops across generation, editing, and reasoning benchmarks when removing stacked channel bridging, think tokens, or VLM activation. Results show that think tokens contribute most significantly to reasoning tasks, while stacked channel bridging and VLM activation support broader multimodal alignment. These findings confirm that each component plays a distinct and necessary role in maintaining the model’s overall capability.

The authors evaluate the impact of key reinforcement learning components in DeepGen 1.0 by ablating auxiliary SFT loss, KL regularization, and reward-wise advantage normalization. Results show that removing any of these components leads to measurable performance drops across generation and editing benchmarks, with the auxiliary SFT loss being especially critical for maintaining stability and preventing capability degradation during training. The full RL configuration consistently outperforms ablated variants, confirming that these components work synergistically to optimize multi-objective learning.

The authors evaluate DeepGen 1.0 on text rendering using the CVTG-2K benchmark, comparing it against both closed-source and open-source models. Results show that DeepGen 1.0, despite its compact 5B parameter size, achieves competitive CLIPScore and significantly improves Word Accuracy after RL training, outperforming several larger open-source models while maintaining strong semantic alignment.