Command Palette
Search for a command to run...
DRACO: معيار عبر المجالات لدقة البحث العميق واكتماله وموضوعيته
DRACO: معيار عبر المجالات لدقة البحث العميق واكتماله وموضوعيته
Joey Zhong Hao Zhang Clare Southern Jeremy Yang Thomas Wang Kate Jung Shu Zhang Denis Yarats Johnny Ho Jerry Ma
الملخص
نقدّم DRACO (اختصار لـ: دقة البحث العميق، اكتماله، وموضوعيته)، وهو معيار (Benchmark) لمهام بحث عميق معقدة. تنتمي هذه المهام إلى 10 مجالات مختلفة، وتستمد معلوماتها من مصادر في 40 دولة، وقد استُخلصت من أنماط استخدام حقيقية مجهولة الهوية ضمن نظام بحث عميق واسع النطاق. تم أخذ العينات من مجموعة بيانات مجهولة الهوية لطلبات "Perplexity Deep Research"، ثم تمّ تصفيتها وإغناؤها لضمان أن تكون المهام مجهولة الهوية، مفتوحة النهاية، ومعقدة، وقابلة للتقييم الموضوعي، وتمثّل النطاق الواسع لحالات الاستخدام الواقعية للبحث العميق. تُقيّم مخرجات المهام وفق قوائم تقييم خاصة بكل مهمة، بناءً على أربعة أبعاد: الدقة الواقعية (Accuracy)، واتساع وعمق التحليل (بما في ذلك الاكتمال)، وجودة العرض (بما في ذلك الموضوعية)، وجودة الاستشهادات المرجعية. يتوفر معيار DRACO علنًا على الرابط: https://hf.co/datasets/perplexity-ai/draco.
One-sentence Summary
Perplexity AI researchers introduce DRACO, a cross-domain benchmark for deep research accuracy, completeness, and objectivity derived from anonymized Perplexity Deep Research requests spanning 10 domains and 40 countries, evaluating outputs from open-ended and complex tasks via task-specific rubrics assessing factual accuracy, breadth and depth of analysis, presentation quality, and citation quality.
Key Contributions
- We present DRACO, a benchmark of complex deep research tasks sourced from anonymized real-world usage patterns spanning 10 domains and 40 countries. The dataset originates from de-identified Perplexity Deep Research requests and is publicly available at https://hf.co/datasets/perplexity-ai/draco.
- Outputs are graded against task-specific rubrics along four dimensions: factual accuracy, breadth and depth of analysis, presentation quality, and citation quality. This evaluation framework ensures the tasks are objectively evaluable and representative of the broad scope of real-world deep research use cases.
- The methodology filters and augments raw queries to ensure tasks are open-ended, complex, and objectively evaluable. Techniques include adding deliverable formats, retrieval directives, and temporal boundaries.
Introduction
Deep research agents frequently encounter challenges when processing ambiguous queries that yield subjective or unverifiable information. Current systems often lack standardized protocols for enforcing temporal boundaries and specific metrics across diverse domains. The authors introduce DRACO, a cross-domain benchmark designed to evaluate and enhance the accuracy, completeness, and objectivity of AI-driven research. They leverage a multi-stage pipeline that preprocesses queries for clarity and augments them with authoritative retrieval directives. This framework integrates web search and code execution tools to validate findings against concrete data rather than opinions.
Dataset

Dataset Composition and Sources
- The authors introduce DRACO, a benchmark consisting of 100 complex deep research tasks derived from production Perplexity Deep Research requests.
- The tasks cover 10 general and specialized domains and require information sourcing from 40 different countries.
- Data originates from a de-identified dataset of tens of millions of real-world user requests.
Subset Details and Processing
- Initial sampling selects 1,000 high-difficulty English queries identified by negative user sentiment or thumbs-down ratings.
- An automated pipeline removes personally identifiable information by replacing names, addresses, and IDs with generic placeholders.
- Queries undergo augmentation to add context such as user persona and desired output format while broadening the analytical scope.
- Final filtering retains only objective, tractable, and challenging tasks before manual expert review confirms security and quality.
Usage in Model Evaluation
- The dataset serves as a benchmark for evaluating deep research systems rather than for training.
- Outputs are graded against task-specific rubrics across four dimensions including factual accuracy and citation quality.
- Evaluation is conducted on single-turn text-to-text interactions in English to assess reasoning and retrieval capabilities.
- The authors compare leading systems such as OpenAI Deep Research and Gemini Deep Research using this framework.
Metadata and Rubric Construction
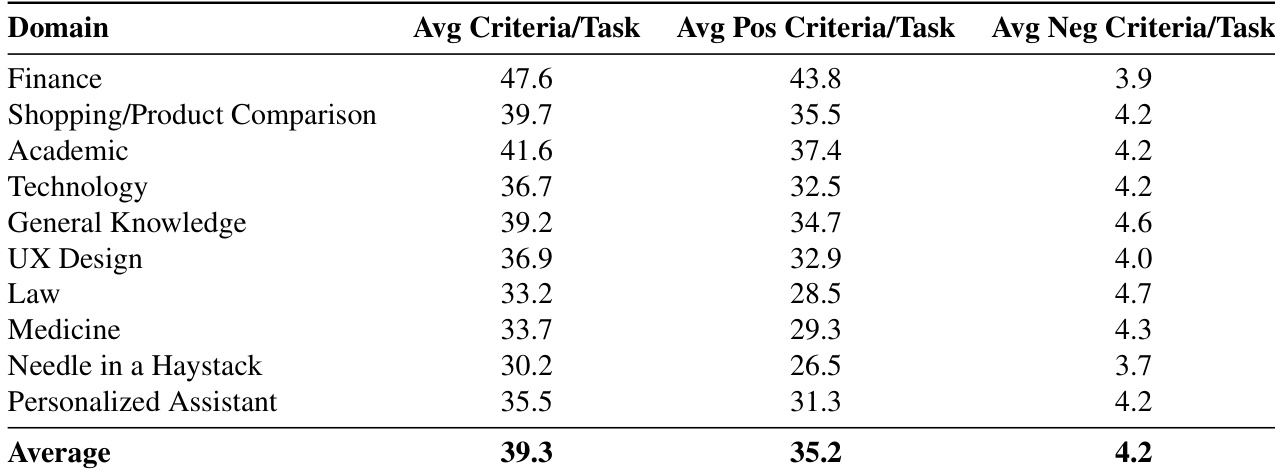
- Domain experts design rubrics containing an average of 39.3 criteria per task to ensure rigorous evaluation.
- Criteria include positive requirements and negative penalties with specific weights for severity such as harmful medical content.
- The construction process involves iterative review and saturation testing to prevent tasks from being too simple.
- The pipeline is designed to be automatable for future refreshes while maintaining human safety gates.
Method
The authors leverage a multi-stage pipeline to construct and evaluate challenging deep research tasks, designed to reflect real-world complexity and ensure high-quality outputs. The framework begins with Stage 1: Sampling, where a large pool of tens of millions of potential deep research queries is drawn from diverse sources to achieve broad coverage and reflect the distribution of real-world usage. This stage selects a subset of 1,000 samples from a one-month production window, focusing on tasks that are inherently challenging.
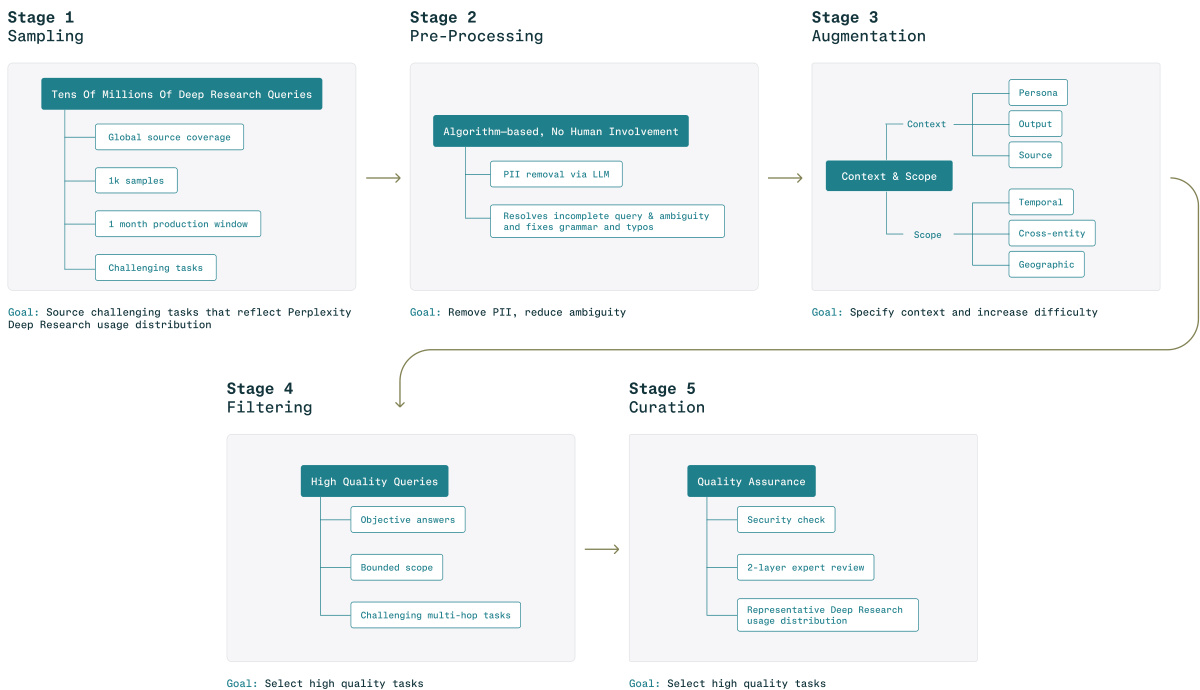
As shown in the figure below, the process proceeds to Stage 2: Pre-Processing, which is algorithmically driven and requires no human involvement. The primary goal is to remove personally identifiable information (PII) through a large language model (LLM)-based pipeline. This stage also resolves incomplete queries by addressing ambiguity and fixing grammar and typographical errors, ensuring the query is clear and answerable.
In Stage 3: Augmentation, the framework enriches the pre-processed query to increase its difficulty and specificity. This stage operates in a structured, chained manner, focusing on different aspects of the task. It begins by inferring a professional persona from the query's domain and complexity, ensuring the task is framed appropriately. It then expands the query's context and scope by adding peer entities or competitors, and conducting geographic scope expansion to include key regions with distinct information sources. The goal is to specify context and increase the task's difficulty while preserving the original query intent. The output is a refined, augmented query, with no preamble or explanation.
The augmented queries are then passed to Stage 4: Filtering, where high-quality tasks are selected based on three criteria: objective answers, bounded scope, and challenging multi-hop tasks. This stage aims to select tasks that are well-defined, not overly broad, and require significant research effort. The filtered queries move to Stage 5: Curation, which ensures quality through a security check, a two-layer expert review, and a representative deep research usage distribution.
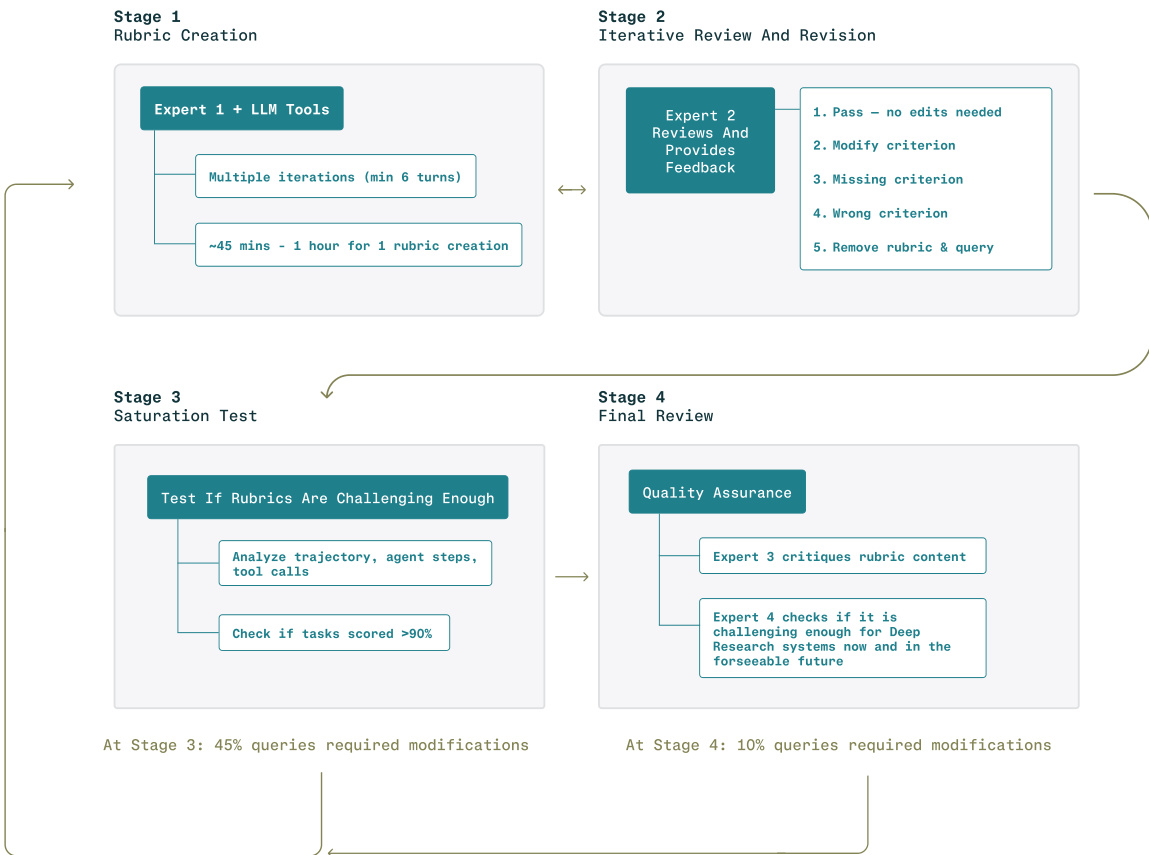
The evaluation protocol involves a separate process for rubric creation and task evaluation. Stage 1: Rubric Creation involves experts working with LLM tools in multiple iterations, taking approximately 45 minutes to an hour per rubric. This is followed by Stage 2: Iterative Review and Revision, where a second expert reviews and provides feedback on the rubric, identifying issues such as missing criteria or incorrect content. The rubrics are then tested in Stage 3: Saturation Test to ensure they are challenging enough, analyzing the trajectory of agent steps and tool calls, and checking if tasks score above 90% on the rubric. Finally, in Stage 4: Final Review, a third expert critiques the rubric content, and a fourth expert checks if the task is challenging enough for deep research systems now and in the foreseeable future.

The evaluation of the generated reports is conducted by judges using a predefined rubric. Each criterion is evaluated independently, with the judge determining if the response meets or fails a specific requirement. The scoring formula is based on the sum of the weights of criteria met, clamped to the range [0,1]. As shown in the figure below, judges grade the reports against the rubrics, with an example criterion requiring the response to state FY2024 revenue as 60.92B(+/−0.1B), which is weighted at 8. The final scores of various models are displayed in a bar chart, showing the performance of different large language models on the Perplexity Deep Research benchmark.
Experiment
The evaluation utilizes an LLM-as-a-judge protocol with weighted rubrics to assess deep research systems across normalized scores and pass rates. Perplexity Deep Research consistently outperformed competitors from OpenAI, Gemini, and Claude across all domains and rubric axes, highlighting the importance of agent orchestration over base model capabilities alone. System rankings remained stable across different judge models, validating the robustness of the methodology despite variations in absolute score magnitudes. Additionally, the top-performing system achieved superior latency efficiency compared to more verbose alternatives, demonstrating a favorable balance between quality and resource usage.
The authors evaluate deep research systems using multiple LLM judges with different configurations. The judge settings vary in reasoning effort and temperature to assess the robustness of the evaluation methodology. Different LLM judges are used with varying reasoning and temperature settings to ensure evaluation robustness. GPT-5.2 uses no reasoning effort and a temperature of 0.0 for deterministic outputs. Gemini-3-Pro employs low reasoning effort and a temperature of 0.2 to limit variability.

Results show that Perplexity Deep Research achieves the highest normalized scores across all rubric axes, with consistent top performance on Factual Accuracy, Breadth and Depth of Analysis, Presentation Quality, and Citation Quality. The second-best results vary by axis, with different models leading in specific categories. Perplexity Deep Research leads in all four rubric axes Presentation Quality shows the highest scores across systems Opus 4.6 and Opus 4.5 show similar performance on most axes, with slight variations

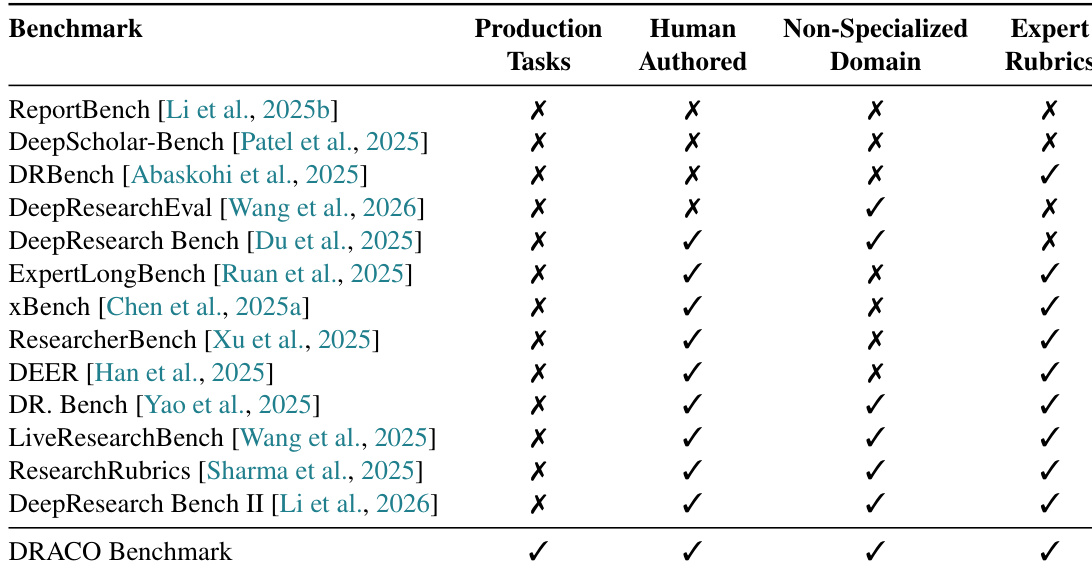
The the the table compares various research benchmarks based on their inclusion of production tasks, human-authored content, non-specialized domains, and expert rubrics. The DeepResearch Benchmark is positioned as a comprehensive evaluation framework that incorporates all four criteria, distinguishing it from other benchmarks. The DeepResearch Benchmark includes production tasks, human-authored content, non-specialized domains, and expert rubrics. Other benchmarks either lack one or more of these features, such as production tasks or expert rubrics. The DeepResearch Benchmark is designed to evaluate deep research systems in a holistic manner, covering real-world scenarios and expert criteria.
Results show that Perplexity Deep Research with Opus 4.6 consistently achieves the highest normalized scores across all rubric axes. The gap between Perplexity and other systems is most pronounced in Breadth and Depth of Analysis and Factual Accuracy, while performance differences are smaller for Presentation Quality. Perplexity Deep Research with Opus 4.6 leads in all four rubric axes. The performance gap between Perplexity and the second-best model is largest in Breadth and Depth of Analysis and Factual Accuracy. Presentation Quality shows the smallest gap between top-performing systems.

The the the table presents the average number of positive and negative criteria per task across different domains, showing the overall balance of evaluation metrics. The average values indicate a consistent distribution of criteria types across tasks, with a higher count of positive criteria compared to negative ones. The average number of positive criteria per task exceeds the average number of negative criteria across all domains. Finance has the highest average criteria per task, indicating a more complex evaluation structure. The average number of negative criteria per task is relatively consistent across domains, with minor variations.
The authors evaluate deep research systems using multiple LLM judges with varied configurations to ensure assessment robustness. Experimental results indicate that Perplexity Deep Research consistently outperforms competing models across all rubric axes, particularly excelling in factual accuracy and the breadth of analysis. Additionally, the study validates the DeepResearch Benchmark as a comprehensive framework that distinguishes itself by incorporating production tasks and expert rubrics alongside human-authored content.