Command Palette
Search for a command to run...
Recurrent-Depth VLA: التوسع الضمني في حسابات الوقت الاختباري لنموذج الرؤية واللغة والفعل من خلال الاستدلال التكراري في الفضاء المخفي
Recurrent-Depth VLA: التوسع الضمني في حسابات الوقت الاختباري لنموذج الرؤية واللغة والفعل من خلال الاستدلال التكراري في الفضاء المخفي
Yalcin Tur Jalal Naghiyev Haoquan Fang Wei-Chuan Tsai Jiafei Duan Dieter Fox Ranjay Krishna
الملخص
تعتمد النماذج الحالية لرؤية-لغة-عمل (VLA) على عمق حسابي ثابت، حيث تُنفق نفس الكمية من العمليات الحسابية على التصحيحات البسيطة والمهام المعقدة متعددة الخطوات. وعلى الرغم من أن تقنية التوجيه بالتفكير المتسلسل (Chain-of-Thought, CoT) تتيح حسابًا متغيرًا، إلا أنها تزداد استهلاكًا للذاكرة بشكل خطي، وهي غير مناسبة جدًا لفضاءات الإجراء المستمرة. نقدّم معمارية RD-VLA (VLA ذات العمق المتكرر)، التي تحقق التكيف الحسابي من خلال تحسين تكراري في الفضاء الخفي، بدلًا من إنشاء الرموز صراحةً. تستخدم RD-VLA رأسًا للإجراء متكرر ومُربوط بالوزن، مما يتيح عمق استنتاج غير محدود مع استهلاك ثابت للذاكرة. يتم تدريب النموذج باستخدام التراجع المقطوع عبر الزمن (TBPTT) لضمان توجيه فعّال لعملية التحسين. أثناء الاستنتاج، تقوم RD-VLA بتخصيص الموارد الحسابية ديناميكيًا باستخدام معيار توقف تكيفي يعتمد على تقارب الفضاء الخفي. أظهرت التجارب على مهام صعبة للتحكم أن العمق المتكرر أمر بالغ الأهمية: حيث تصل المهام التي تفشل تمامًا (بنسبة نجاح 0%) عند استخدام الاستنتاج بمرحلة واحدة إلى أكثر من 90% من النجاح عند استخدام أربع مراحل، في حين تصل المهام الأسهل إلى التشبع بسرعة. توفر RD-VLA طريقًا قابلاً للتوسع لاستخدام الموارد الحسابية أثناء الاختبار في الروبوتات، بدلًا من التفكير القائم على الرموز، تُستخدم التفكير في الفضاء الخفي، مما يحقق استهلاكًا ثابتًا للذاكرة، ويوفر تسريعًا يصل إلى 80 مرة في الاستنتاج مقارنة بالنماذج السابقة القائمة على التفكير. صفحة المشروع: https://rd-vla.github.io/
One-sentence Summary
Researchers from NVIDIA and Stanford introduce RD-VLA, a vision-language-action model that dynamically scales computation via latent-space iterative refinement rather than token-based reasoning, enabling 80× faster inference and 90%+ success on complex robotic tasks while maintaining constant memory usage.
Key Contributions
- RD-VLA introduces a recurrent, weight-tied action head that enables adaptive test-time compute via latent iterative refinement, eliminating fixed-depth constraints and supporting arbitrary inference depth with constant memory usage.
- The model is trained with truncated backpropagation through time and dynamically stops inference based on latent convergence, allowing it to allocate more compute to complex tasks while rapidly saturating on simpler ones—boosting success rates from 0% to over 90% on challenging manipulation tasks.
- Evaluated on LIBERO and CALVIN benchmarks, RD-VLA achieves state-of-the-art performance with 93.0% success on LIBERO and 45.3% task-5 success on CALVIN, while delivering up to 80× faster inference than prior reasoning-based VLA models.
Introduction
The authors leverage a recurrent, weight-tied architecture to enable adaptive test-time compute in Vision-Language-Action (VLA) models, addressing a key limitation of prior systems that expend fixed computational resources regardless of task complexity. Existing reasoning-based VLAs rely on explicit token generation—like Chain-of-Thought—which scales memory linearly and forces reasoning through lossy, discretized output spaces, making them inefficient for continuous robotic control. RD-VLA instead performs iterative refinement entirely within a fixed-dimensional latent space, using truncated backpropagation through time for training and an adaptive stopping criterion at inference to dynamically allocate compute. This design enables up to 80x faster inference than token-based reasoning models while maintaining constant memory usage, and achieves state-of-the-art performance on benchmarks like LIBERO and CALVIN, including real-world transfer to tasks like towel folding and bread toasting.
Method
The authors leverage a novel architecture called Recurrent-Depth Vision-Language Action (RD-VLA) to decouple computational depth from the fixed structural constraints of pretrained vision-language backbones. Rather than relying on fixed-depth MLP heads or output-space iterative methods such as diffusion, RD-VLA shifts the computational burden into a weight-tied recurrent transformer core that operates entirely within a continuous latent manifold. This enables dynamic test-time compute scaling by unrolling the recurrent block to an arbitrary depth r, allowing the model to allocate more computation to complex tasks and less to simpler ones, as illustrated in the performance curve on LIBERO-10.
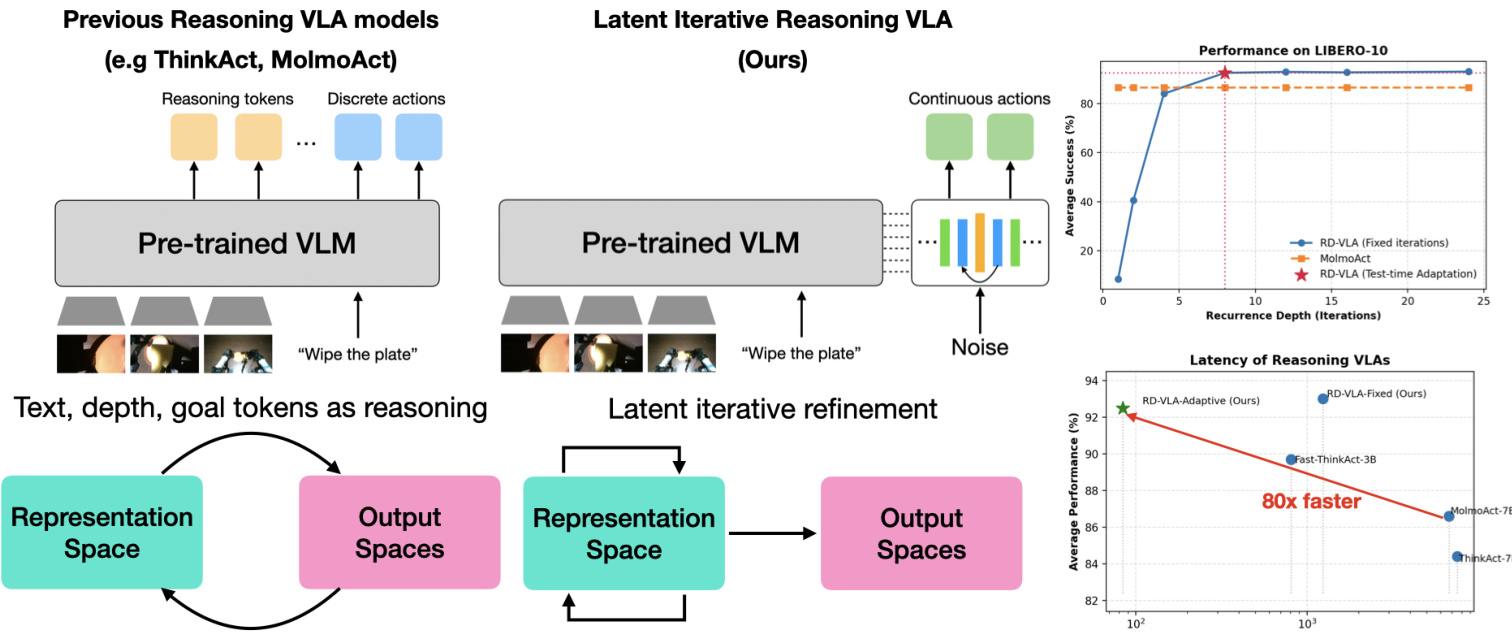
The RD-VLA action head is designed to be backbone-agnostic and is instantiated here using a Qwen2.5-0.5B-based VLM, augmented with 64 learned latent tokens that attend to the multi-modal context during the LLM’s forward pass. After VLM execution, hidden states are partitioned into task/vision representations hvis∈R512×D and latent-specific representations hlat∈R64×D. These are concatenated with proprioception p to form a static conditioning manifold [hvis+lat(24);p], which grounds the recurrent reasoning process.
The architecture follows a functional triplet: Prelude, Recurrent Core, and Coda. The Prelude Pϕ consumes K=8 learned queries, which first self-attend bidirectionally and then cross-attend to the VLM’s middle-layer features hvis+lat(12) to produce a grounded latent foundation:
Spre=Pϕ(Queries,hvis+lat(12))∈RK×DIn parallel, a latent scratchpad S0 is initialized from a high-entropy truncated normal distribution:
S0∼TruncNormal(0,γinit⋅σinit)This noisy initialization ensures the model learns a stable refinement operator rather than overfitting to a fixed starting point.
The Recurrent Core Rθ performs iterative refinement by maintaining representational stability through persistent Input Injection. At each iteration k, the current scratchpad state Sk−1 is concatenated with the static foundation Spre, mapped back to the manifold dimension via a learned adapter, and normalized:
xk=RMSNorm(γadapt⋅Wadapt[Sk−1;Spre])The scratchpad is then updated via the weight-tied transformer block:
Sk=Rθ(xk,[hvis+lat(24);p])Here, Rθ performs bidirectional self-attention across the K queries and gated cross-attention using keys/values derived from the concatenated conditioning manifold. This ensures the model remains grounded in the physical observation throughout unrolling.

Once the recurrence reaches depth r, the converged scratchpad Sr is processed by the Coda Cψ, which performs final decoding by attending to self and high-level VLM features. The output is projected to the robot’s action space:
a=Wout⋅RMSNorm(Cψ(Sr,[hvis(24);hlat(24);p]))Training employs randomized recurrence: the number of iterations N is sampled from a heavy-tailed log-normal Poisson distribution with μrec=32. Truncated BPTT is used, propagating gradients only through the final d=8 iterations, forcing the model to learn iterative refinement from any noisy initialization into a stable manifold.
At inference, adaptive computation is implemented by monitoring convergence via the L2 distance between consecutive predicted actions:
∣∣ak−ak−1∣∣22<δwhere δ=1e−3. This allows the model to self-regulate compute: terminating early for simple tasks and allocating more iterations for complex ones.
Adaptive execution further couples reasoning depth with action horizon. For high-uncertainty states (k∗>τ), the execution horizon is truncated to Hshort; otherwise, it remains Hlong. Alternatively, a linear decay schedule reduces horizon inversely with iteration count:
Hexec(k∗)=max(Hmin,Hmax−max(0,k∗−τbase))This ensures the agent replans more frequently under high computational demand, prioritizing safety in complex scenarios.
Experiment
- Recurrent computation significantly boosts performance on manipulation tasks, with gains plateauing after 8–12 iterations, indicating diminishing returns beyond that point.
- Task complexity varies widely, requiring different numbers of reasoning steps; adaptive computation dynamically allocates compute based on task difficulty without predefined rules.
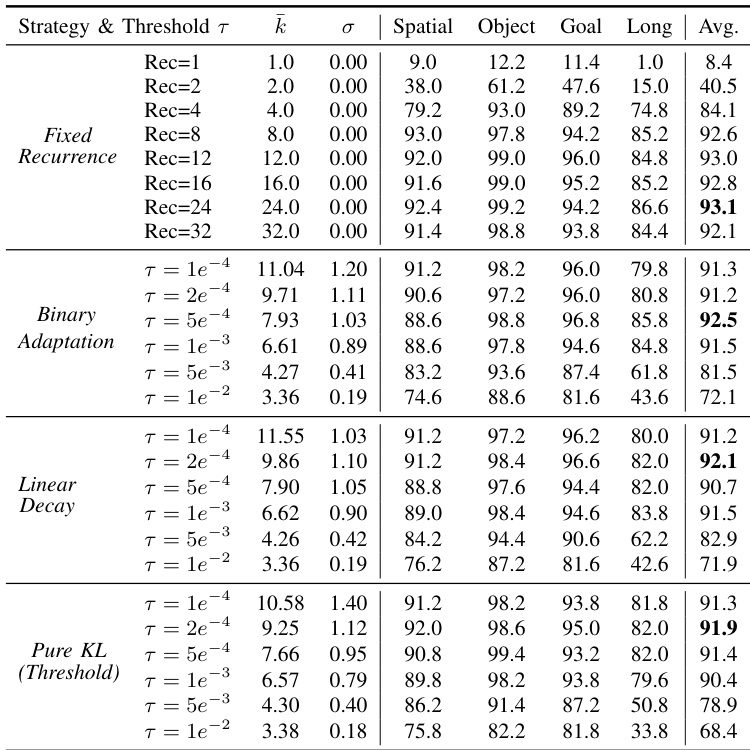
- Adaptive strategies (especially Binary Adaptation) match fixed-depth performance while cutting inference cost by up to 34%, confirming that condition-dependent compute allocation is more effective than uniform budgets.
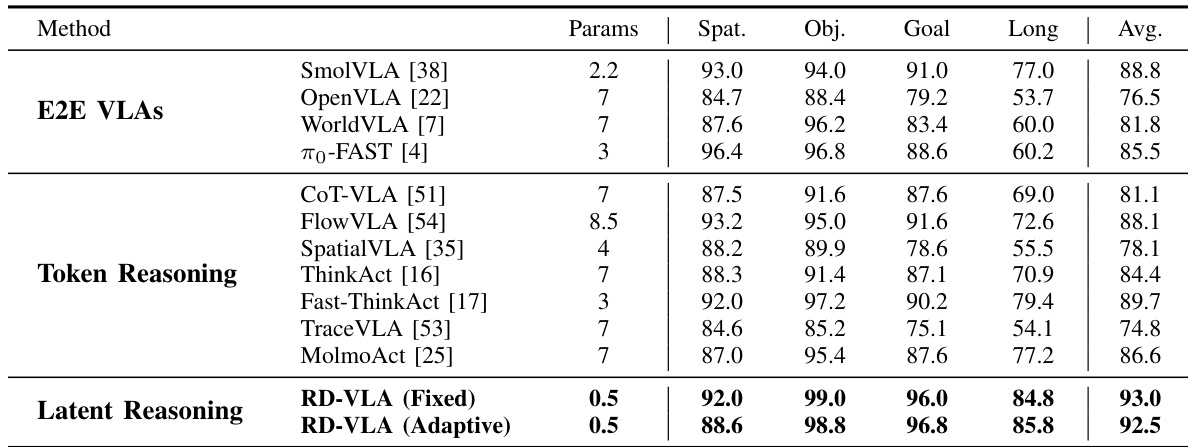
- Latent reasoning outperforms both end-to-end and token-level reasoning methods, achieving state-of-the-art results on LIBERO and CALVIN benchmarks with a smaller model size (0.5B parameters).
- Real-world deployment on a bimanual robot shows strong robustness across household tasks, with fixed-depth variants excelling in most scenarios and adaptive variants remaining competitive while enabling efficiency.
- The approach demonstrates viability for physical systems and opens pathways for uncertainty-aware execution, though depth generalization and saturation remain key limitations for future work.
The authors evaluate their latent reasoning approach against end-to-end and token-level reasoning methods, showing that RD-VLA achieves state-of-the-art performance on the LIBERO benchmark with significantly fewer parameters. Results indicate that both fixed and adaptive variants of RD-VLA outperform prior methods across task categories, with the adaptive version maintaining strong performance while reducing average inference cost. The findings support that iterative latent-space reasoning is more parameter-efficient and effective for robotic manipulation than token-based or direct action prediction approaches.
The authors evaluate adaptive computation strategies for their recurrent reasoning model, showing that dynamic allocation of inference steps based on task complexity achieves performance comparable to fixed-depth models while reducing average compute cost. Results indicate that different task categories naturally require varying numbers of iterations, and adaptive methods like Binary Adaptation strike the best balance between efficiency and success rate. The model’s ability to self-calibrate computation based on state uncertainty demonstrates practical viability for real-world deployment.
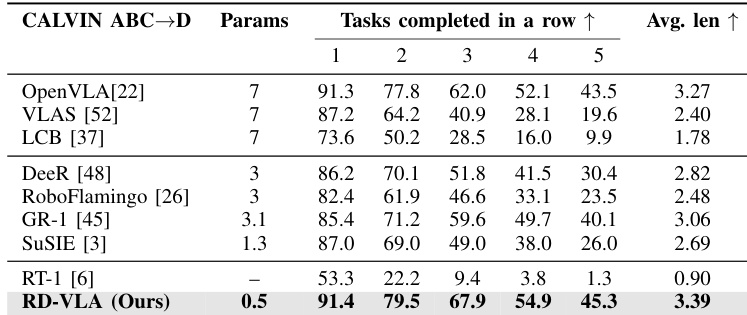
The authors evaluate their RD-VLA model on the CALVIN ABC→D benchmark, showing it completes longer task sequences than prior methods, achieving the highest average chain length of 3.39. Despite using only 0.5B parameters—significantly fewer than most baselines—the model demonstrates strong sequential planning capability through latent iterative reasoning. Results confirm that recurrent depth enhances performance on long-horizon manipulation tasks without requiring large-scale architectures.