Command Palette
Search for a command to run...
تحسين سياسة التسلسل غير المُحَيَّز طوله: كشف التغير في طول الاستجابة وتحكم فيه في التعلم بالتعزيز القائم على التقييم
تحسين سياسة التسلسل غير المُحَيَّز طوله: كشف التغير في طول الاستجابة وتحكم فيه في التعلم بالتعزيز القائم على التقييم
Fanfan Liu Youyang Yin Peng Shi Siqi Yang Zhixiong Zeng Haibo Qiu
الملخص
أظهرت التطبيقات الحديثة للتعلم بالتعزيز مع المكافآت القابلة للتحقق (RLVR) على النماذج اللغوية الكبيرة (LLMs) والنماذج البصرية-اللغوية (VLMs) نجاحًا كبيرًا في تعزيز القدرات الاستدلالية في المهام المعقدة. خلال تدريب RLVR، يُعتبر الزيادة في طول الاستجابة عاملًا رئيسيًا يسهم في تطوير القدرة الاستدلالية. ومع ذلك، تختلف أنماط التغير في طول الاستجابة بشكل كبير بين مختلف خوارزميات RLVR خلال عملية التدريب. ولتقديم تفسير أساسي لهذه الاختلافات، تقوم هذه الورقة بتحليل معمق لمكونات خوارزميات RLVR الرئيسية. ونقدّم تحليلًا نظريًا للعوامل المؤثرة في طول الاستجابة، ونُحقق نظريتنا من خلال تجارب واسعة النطاق. استنادًا إلى هذه النتائج النظرية، نقترح خوارزمية تحسين تسلسل غير متحيز بطول الاستجابة (LUSPO). وبشكل خاص، نُصحّح التحيّز الطولي المتأصّل في خوارزمية تحسين سياسة التسلسل المجموعة (GSPO)، مما يجعل دالة الخسارة غير متحيزة بالنسبة لطول الاستجابة، وبالتالي حل مشكلة انهيار طول الاستجابة. ونُجري تجارب واسعة النطاق على معايير استدلال رياضي وسيناريوهات استدلال متعددة الوسائط، حيث تحقق LUSPO أداءً متفوقًا باستمرار. تُظهر النتائج التجريبية أن LUSPO تمثل استراتيجية تحسين جديدة ومتقدمة، تفوق الطرق الحالية مثل GRPO وGSPO.
One-sentence Summary
Researchers from Meituan propose LUSPO, a length-unbiased RLVR algorithm that corrects GSPO’s response length bias, enabling stable reasoning growth in LLMs and VLMs across math and multimodal tasks, outperforming GRPO and GSPO without length collapse.
Key Contributions
- We identify and theoretically explain how GRPO and GSPO introduce length bias during RLVR training, causing models to favor shorter responses under GSPO and undermining reasoning performance.
- We propose LUSPO, a length-unbiased policy optimization method that scales sequence loss by response length to eliminate this bias, enabling stable training and accelerated growth in reasoning depth.
- Empirical results across dense and MoE models on benchmarks like AIME24, MathVista, and MathVision show LUSPO outperforms GRPO and GSPO, achieving up to 6.9% higher accuracy on reasoning tasks.
Introduction
The authors leverage Reinforcement Learning with Verifiable Rewards (RLVR) to improve reasoning in large language and vision-language models, where response length often correlates with reasoning depth. Prior methods like GRPO and GSPO suffer from implicit length bias: GRPO penalizes longer correct responses, while GSPO’s sequence-level clipping exacerbates bias by disproportionately suppressing negative samples, leading to response collapse during training. To fix this, they propose Length-Unbiased Sequence Policy Optimization (LUSPO), which scales each sequence’s loss by its length to neutralize bias. LUSPO stabilizes training across dense and MoE models, accelerates response length growth, and improves accuracy on math and multimodal benchmarks without requiring architectural changes.
Dataset
- The authors use two primary datasets: DAPO-MATH-17K for training the main model and ViRL39K for training the vision-language (VL) model.
- Both datasets are sourced from recent academic work (Yu et al., 2025 and Wang et al., 2025) and focus on scientific problem-solving, with an emphasis on math and logic.
- The datasets serve as core evaluation benchmarks, chosen for their rigor and extensibility to other domains.
- No further details on subset sizes, filtering rules, or processing steps are provided in this section.
Method
The authors leverage a policy optimization framework for autoregressive language models, treating the model as a policy πθ that generates responses y conditioned on queries x. Each response is evaluated by a verifier that assigns a scalar reward r(x,y), forming the basis for reinforcement learning updates. The core innovation lies in the design of group-based policy optimization objectives that compare multiple responses per query to compute relative advantages, thereby stabilizing training and reducing variance.
The foundational method, Group Relative Policy Optimization (GRPO), samples a group of G responses per query from the old policy πθold, computes their rewards, and constructs a token-level objective that incorporates clipped importance sampling weights. The importance ratio wi,t(θ) for token yi,t is defined as the ratio of current to old policy probabilities, while the advantage Ai,t is shared across all tokens in response yi and normalized relative to the group’s mean and standard deviation of rewards. This design encourages the model to favor responses that outperform the group average.
Building on this, Group Sequence Policy Optimization (GSPO) replaces token-level importance weights with a sequence-level counterpart si(θ), defined as the geometric mean of token-level ratios over the entire response. This aligns more naturally with sequence-level rewards and provides a theoretically grounded basis for clipping. The GSPO objective retains the group-based advantage estimation but applies the sequence-level importance ratio directly to the advantage, simplifying the gradient computation and improving reward signal coherence.
However, both GRPO and GSPO exhibit a response-length bias: shorter responses receive higher per-token weight in the loss, leading the model to favor brevity, especially under GSPO’s sequence-level clipping regime. To address this, the authors introduce Length-Unbiased Sequence Policy Optimization (LUSPO), which scales each sequence’s contribution to the loss by its own length ∣yi∣. This simple modification ensures that longer responses are not penalized for their length, thereby eliminating the gradient bias inherent in GSPO.
The gradient analysis confirms that LUSPO’s objective yields a gradient expression where the length normalization factor cancels out, leaving a clean sum over token-level policy gradients weighted by the sequence-level advantage and importance ratio. In contrast, GSPO’s gradient retains a 1/∣yi∣ factor, which introduces length-dependent scaling. This theoretical insight validates LUSPO’s design as a principled correction to the length bias.
During training, the reward function combines three components: accuracy (Raccuracy∈{0,1}), format adherence (Rformat∈{0,0.5}), and a penalty for overlong responses Roverlong(y), which linearly penalizes responses exceeding a buffer length Lbuffer relative to the maximum allowed length Lmax. This composite reward encourages both correctness and conciseness while maintaining structural compliance with prompt requirements.
Experiment
- LUSPO consistently outperforms GSPO and GRPO across dense, MoE, and vision-language models, showing strong generalization in both text-only and multimodal benchmarks.
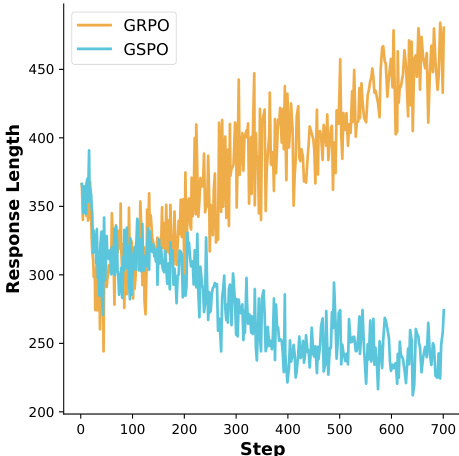
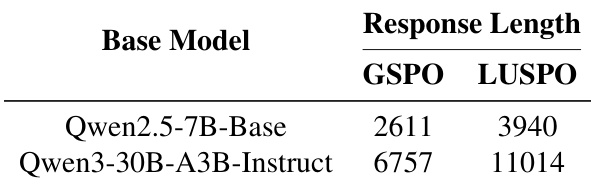
- LUSPO mitigates GSPO’s length bias, leading to significantly longer and more stable response lengths during training, which enhances exploration and complex reasoning.
- Models trained with LUSPO achieve higher accuracy rewards and better validation scores, indicating improved learning and generalization rather than overfitting.
- Ablation studies confirm LUSPO’s robustness across diverse datasets, maintaining superior performance even when length collapse is not inherent to the training data.
The authors evaluate LUSPO against GRPO and GSPO on multimodal benchmarks using Qwen2.5-VL-7B-Instruct, showing consistent performance gains across tasks. LUSPO outperforms GSPO by up to 6.0% on LogicVista and 5.1% on WeMath, while also maintaining longer response lengths during training. These results indicate LUSPO’s superior generalization in vision-language settings by mitigating the length bias inherent in GSPO.

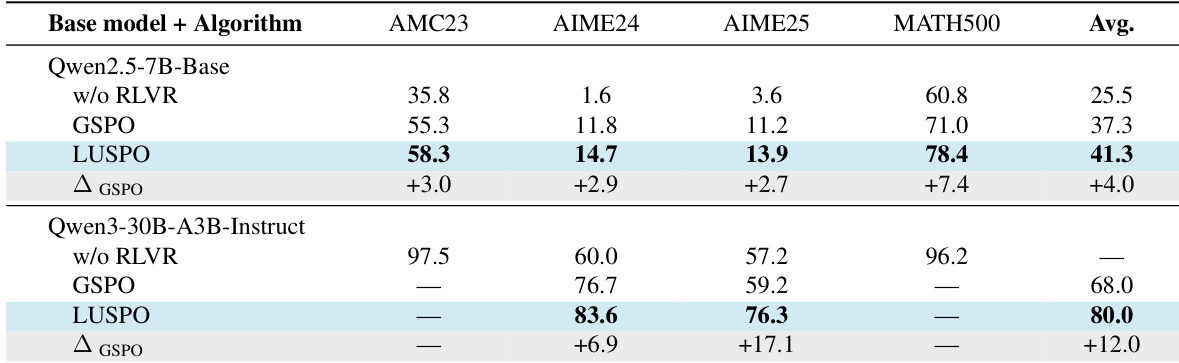
The authors use LUSPO to train both dense and MoE models, observing that LUSPO consistently generates significantly longer responses than GSPO across model types. This increased response length correlates with better performance on validation benchmarks, suggesting LUSPO mitigates the length bias inherent in GSPO. Results show LUSPO enhances model capability by enabling more extensive exploration and complex reasoning during training.
The authors evaluate LUSPO against GSPO on multimodal benchmarks using Qwen2.5-VL-7B-Instruct, showing consistent performance gains across all tasks. LUSPO outperforms GSPO by up to 6.0% on specific benchmarks, with an overall average improvement of 2.3 points. These results highlight LUSPO’s superior generalization in vision-language settings compared to the baseline.

The authors use LUSPO to train both dense and MoE models, achieving consistent performance gains over GSPO across multiple text-only benchmarks. Results show that LUSPO not only improves average scores but also delivers larger absolute improvements on challenging tasks like AIME25 and MATH500, indicating stronger generalization. The gains are especially pronounced in the MoE model, where LUSPO significantly boosts performance on AIME benchmarks compared to GSPO.