Command Palette
Search for a command to run...
إيغو أكتور: ترسيخ تخطيط المهام في الإجراءات المكانية الواعية ذات النظرة الذاتية للروبوتات البشرية من خلال نماذج الرؤية واللغة
إيغو أكتور: ترسيخ تخطيط المهام في الإجراءات المكانية الواعية ذات النظرة الذاتية للروبوتات البشرية من خلال نماذج الرؤية واللغة
Yu Bai MingMing Yu Chaojie Li Ziyi Bai Xinlong Wang Börje F. Karlsson
الملخص
إن نشر الروبوتات البشرية في البيئات الواقعية يُعد تحديًا جوهريًا، نظرًا للاحتياجات الكبيرة من التكامل الوثيق بين الإدراك والحركة والتفاعل في ظل ملاحظات جزئية وبيئات متغيرة ديناميكيًا، بالإضافة إلى القدرة على الانتقال بثبات بين المهام الفرعية المختلفة الأنواع. وللتعامل مع هذه التحديات، نقترح مهمة جديدة تُسمى "EgoActing"، والتي تتطلب ترسيخًا مباشرًا للتعليمات عالية المستوى في إجراءات بشرية دقيقة وواعية بالمكان. ونُطبّق هذه المهمة من خلال تقديم نموذج موحد قابل للتوسع يُدعى EgoActor، وهو نموذج لغوي بصري (VLM) قادر على توقع وحدات الحركة الأساسية (مثل المشي، والانعطاف، والحركة الجانبية، وتغيير الارتفاع)، والحركة الرأسية، وأوامر التفاعل، بالإضافة إلى التفاعلات بين الإنسان والروبوت، بهدف تنسيق الإدراك والتنفيذ في الزمن الحقيقي. ونستفيد من مراقبة واسعة النطاق على بيانات RGB ذات منظور ذاتي (egocentric) من تجارب واقعية، وتمارين الإجابة على أسئلة الاستدلال المكاني، وتجارب في بيئات محاكاة، ما يمكّن EgoActor من اتخاذ قرارات موثوقة وواعية بالسياق، وتنفيذ استنتاجات إجرائية سلسة (في أقل من ثانية) باستخدام نماذج بحجم 8B و4B من المعاملات. وتُظهر التقييمات الواسعة في بيئات محاكاة وواقعية أن EgoActor يُسهم فعّالًا في جسر الفجوة بين التخطيط المجرد للمهام والتنفيذ الحركي الملموس، مع القدرة على التعميم عبر مهام متنوعة وبيئات غير مألوفة.
One-sentence Summary
Researchers from Beijing Academy of Artificial Intelligence propose EgoActor, a unified vision-language model that grounds natural-language instructions into spatially aware, egocentric actions for humanoid robots—jointly predicting locomotion, manipulation, perception, and human interaction—enabling real-time, robust execution in dynamic, real-world environments without extra sensors or teleoperation.
Key Contributions
- EgoActing introduces a new task requiring humanoid robots to translate natural language instructions into precise, spatially grounded action sequences using egocentric vision, addressing real-world deployment challenges like partial observability and dynamic transitions between locomotion, manipulation, and interaction.
- EgoActor, a vision-language model trained on diverse egocentric data including real-world demonstrations and spatial reasoning tasks, unifies prediction of locomotion primitives, head movements, manipulation commands, and human-robot interactions—enabling real-time, sub-second inference on 4B and 8B models.
- Evaluated across simulated and real environments including mobile manipulation and traversability tasks, EgoActor demonstrates strong generalization to unseen settings and diverse task types, with released code, models, and datasets to support reproducibility and future research.
Introduction
The authors leverage vision-language models to tackle the challenge of grounding natural language instructions into precise, spatially aware actions for humanoid robots — a critical step toward real-world deployment. Prior approaches often treat locomotion, manipulation, and perception as separate modules, limiting coordination and adaptability in dynamic, cluttered environments. EgoActor unifies these capabilities into a single VLM that predicts low-level, egocentric actions — including movement, head orientation, manipulation, and human interaction — directly from RGB observations and instruction history. Trained on diverse real-world and simulated data, it enables real-time, sub-second inference and generalizes across unseen tasks and environments, bridging high-level planning with motor execution without requiring extra sensors or teleoperation.
Dataset
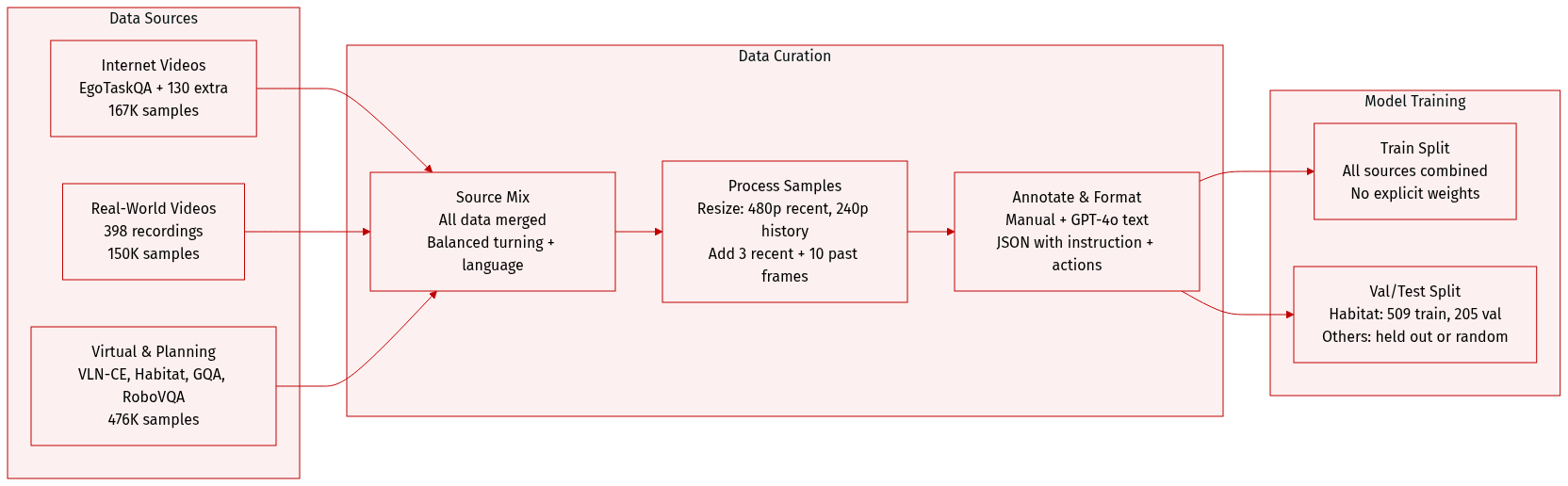
The authors use a multimodal, multimodal dataset composed of real-world, virtual, and internet-sourced egocentric video data, structured for egocentric action prediction under the EgoActing framework. Below is a breakdown of the dataset composition, processing, and usage:
-
Dataset Sources and Composition:
- Internet video data: EgoTaskQA (160,000 samples) + 130 additional egocentric videos (7,111 samples).
- Local environment data: 398 real-world egocentric videos → 150,214 samples.
- Virtual navigation: 3% of VLN-CE → 60,000 samples.
- Virtual EgoActing: 714 manually annotated Habitat-Sim trajectories → 76,821 samples (509 train, 205 val).
- Spatial reasoning: 50% of MindCube → 44,160 samples.
- Visual-language understanding: 300,000 GQA samples + 35,652 GPT-4o-annotated local descriptions.
- Visual-language planning: RoboVQA, EgoPlan, ALFRED → 241,603 samples.
- Unsupervised movement: 10,575 image-pair transition samples.
- DAgger experience: 70 real-world traces → 3,629 samples.
-
Key Subset Details:
- EgoTaskQA: Converted into EgoActing format via instruction concatenation (3 adjacent actions), recent observation-action triplets (backward stride of 5 frames), and 10 uniformly sampled historical frames. Navigation actions are aggregated from pose differences with thresholds (5°, 0.1m). Final training set: 160,000 samples (40k from full set, 120k from NL-action subset).
- Virtual data: Trajectories parsed into RGB-image + discrete action sequences, merged into continuous instructions with randomized perturbations, and sampled via sliding windows to produce recent 3 action pairs + historical context. Serialized in JSON.
- All subsets are augmented to balance turning and language actions.
-
Data Usage in Model Training:
- Training split: All subsets combined into a single training mixture.
- Mixture ratios: Not explicitly weighted; all sources contribute to a diverse, multimodal training corpus.
- Processing: Recent observations resized to 480p; historical observations to 240p to save compute. Each sample includes global instruction, 3 recent observation-action pairs, and 10 historical frames.
- Annotation: Manual annotation for real and virtual data; EgoTaskQA instructions derived from action concatenation; natural language actions appended to trajectories to ground behavior.
-
Additional Processing Details:
- Cropping/Resolution: No cropping; resolution downscaled for efficiency (480p for recent, 240p for historical).
- Metadata: Each sample includes instruction, recent action history, and historical visual context. Navigation actions derived from pose deltas with algebraic cancellation and magnitude thresholds.
- Sample Variants: For manipulation tasks, two variants are created — one predicting the next manipulation, another predicting Stop to signal task completion.
- Scalability: Lightweight annotation pipeline enables large-scale collection; supports future scaling with more compute or higher-res cameras.
Method
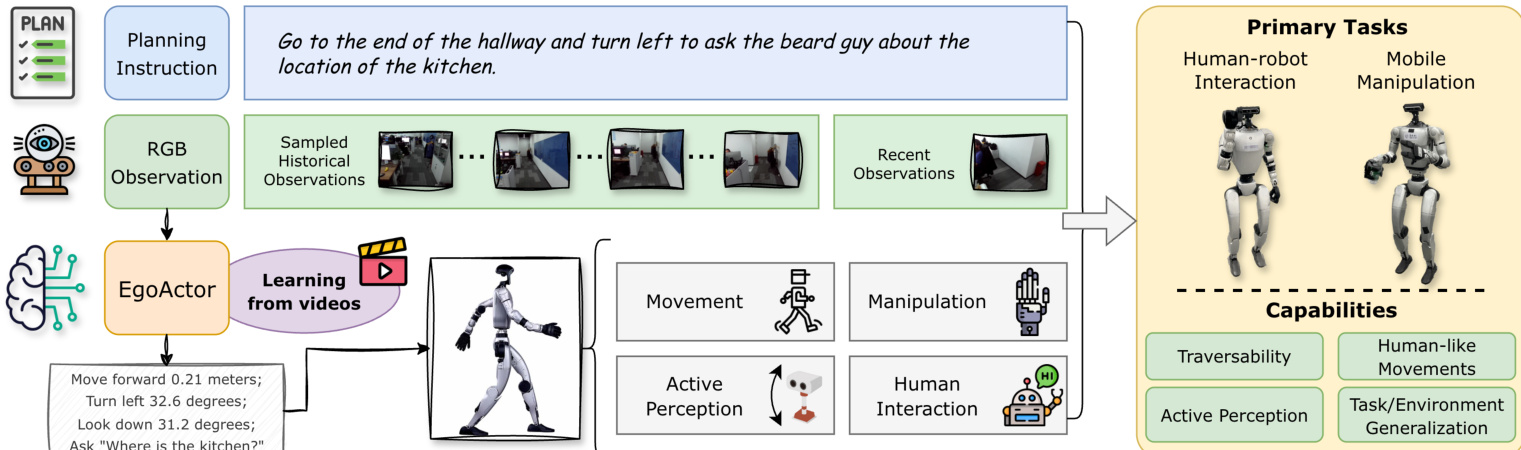
The authors leverage a unified vision-language framework to enable humanoid robots to execute complex, instruction-driven tasks by decomposing behavior into two complementary action modalities: structured language actions (SLAs) for spatial control and natural language actions (NLAs) for manipulation and interaction. This dual-action representation allows the system to ground high-level intentions in precise, executable motor commands while retaining the flexibility to handle open-ended, novel instructions.
The core model, EgoActor, operates on egocentric RGB observations and a temporally structured prompt that includes both sampled historical frames and recent observation-action pairs. This design encourages the model to reason over long-term context and short-term dynamics, ensuring spatially grounded and temporally coherent decision-making. The model is trained to predict a sequence of SLAs followed by an NLA—or interleaved sequences thereof—conditioned on the task instruction and visual history. As shown in the figure below, the system processes a planning instruction and visual input to generate a sequence of low-level actions that culminate in task completion.
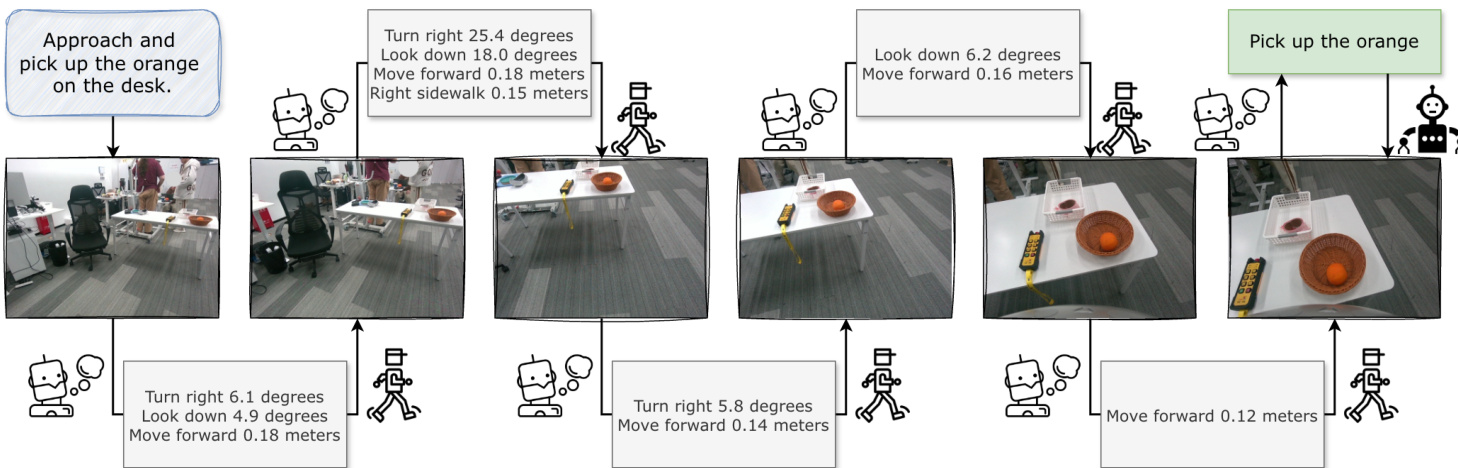
Structured language actions are defined as concise, interpretable templates specifying motion type, direction, and magnitude—such as “Turn left 30.5 degrees” or “Move forward 0.26 meters”—and cover yaw/pitch rotations, linear translations, and vertical adjustments. These actions are filtered to suppress negligible movements, ensuring stable and precise positioning. Natural language actions, in contrast, are unconstrained textual commands like “Pick up the orange” or “Ask Where is the kitchen?”, enabling generalization to unseen tasks and direct intent-to-action mapping. The model is trained to output these NLAs only after sufficient spatial pre-positioning via SLAs, ensuring that manipulation or interaction occurs in the correct context.
During inference, SLAs are parsed into velocity or angle commands for the robot’s locomotion controller, while NLAs are routed via keyword triggers: speech-related commands are synthesized into audio, predefined social actions invoke preset motions, and manipulation commands are forwarded to pre-trained vision-language-action (VLA) models. The authors implement this pipeline using Qwen3-VL as the base vision-language model, fine-tuned via LoRA on mixed datasets across 16 A100 GPUs. Both 4B and 8B variants are trained to balance inference speed and performance.
The operational workflow is illustrated in the figure below, which visualizes the step-by-step execution of the task “Approach and pick up the orange on the desk.” The model iteratively generates SLAs to navigate toward the target, adjusting orientation and position based on visual feedback, before issuing the final NLA to execute the manipulation.
For downstream skills, the authors integrate a finetuned GROOT-N 1.5 model for manipulation and the Unitree walking policy for locomotion, calibrated to achieve ~5 cm positional and ~5 degree angular precision. Forward motion is amplified by 1.2x to enhance speed, and discrete turning and forward steps are merged to produce more human-like trajectories. Stand-up and crouch-down behaviors are currently limited to simulation due to constraints in the deployed locomotion policy.
Experiment
- EgoActor successfully performs human-robot interaction tasks, including approaching and greeting individuals, with the 8B model outperforming the 4B variant in multi-person scenarios requiring fine-grained visual disambiguation.
- In mobile manipulation, EgoActor navigates to target objects in unseen layouts and executes pick-and-place actions robustly, even for out-of-distribution objects, though the 4B model occasionally fails by triggering manipulation too early.
- EgoActor demonstrates superior traversability in narrow spaces like doorways, reliably avoiding collisions where baseline VLM navigation models frequently fail or exhibit inefficient behaviors such as unnecessary rotations.
- In virtual environments, EgoActor generalizes well to unseen scenes and maintains performance under strict positioning criteria, while baseline models often fail to stop accurately for interaction.
- Qualitative case studies confirm EgoActor exhibits human-like behaviors including adaptive turning, height adjustment, active perception (e.g., looking up/down to resolve visual ambiguity), and spatial reasoning for obstacle avoidance and scene negotiation.
- The model’s training on real-world human videos contributes to its strong spatial understanding and natural movement patterns, enabling smooth transitions between navigation and interaction or manipulation tasks.
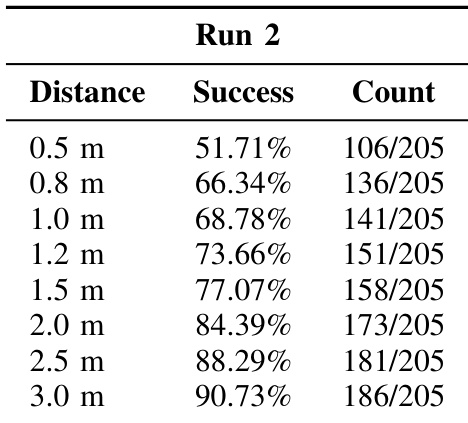
The authors evaluate EgoActor’s navigation precision in unseen virtual environments using multiple distance thresholds, with success rates increasing as the allowable error margin grows. Results show the model achieves over 88% success at 2.5 meters and nearly 90% at 3.0 meters, indicating strong generalization to novel scenes despite stochastic inference. Performance degrades at stricter thresholds, reflecting challenges in fine-grained positioning under ambiguous or visually degraded conditions.
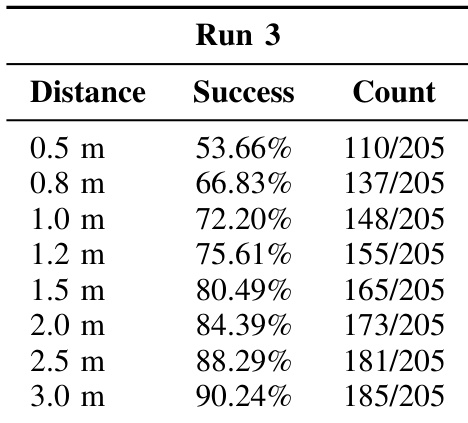
The authors evaluate EgoActor’s navigation precision in unseen virtual environments using multiple distance thresholds, with success rates increasing as the allowable error margin grows. Results show the model achieves over 90% success at 3.0 meters but drops to just over 50% at the stricter 0.5-meter threshold, indicating sensitivity to fine-grained positioning. Performance trends suggest the model generalizes reasonably well to novel scenes but struggles with highly precise stopping requirements.
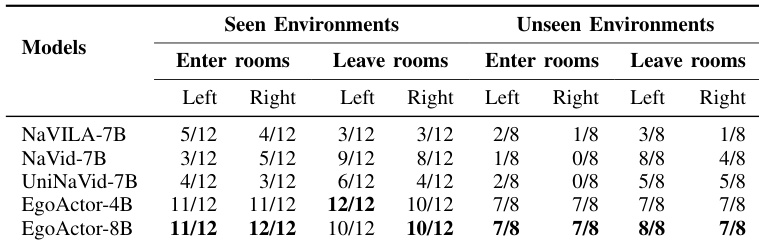
The authors evaluate EgoActor and several vision-language navigation baselines on traversability tasks involving room entry and exit in both seen and unseen environments. Results show that EgoActor, particularly the 8B variant, consistently outperforms baseline models in avoiding collisions and successfully navigating narrow doorways, especially in unseen settings. Baseline models such as NaVILA and NaVid exhibit lower success rates and often fail to handle spatial constraints or execute efficient trajectories.
The authors evaluate EgoActor’s ability to disambiguate individuals in multi-person scenarios based on visual attributes such as clothing, accessories, posture, direction, and gender. Results show that the 8B model consistently outperforms the 4B variant across all attributes, particularly in identifying targets by direction and accessories, indicating stronger visual reasoning and person discrimination capabilities at larger scale.

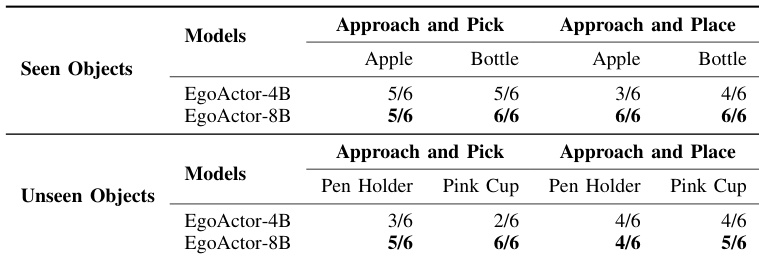
The authors evaluate EgoActor models on mobile manipulation tasks involving both seen and unseen objects, using a humanoid robot in an unseen environment layout. Results show that the 8B model consistently outperforms the 4B variant, particularly in handling novel object categories and executing precise pick-and-place actions. Both models demonstrate reasonable generalization, but the 8B version achieves higher success rates across all object types and task variants.