Command Palette
Search for a command to run...
AOrchestra: أوتوماتيكيّة إنشاء الوكلاء الفرعيين لتنظيم الوكلاء الوظيفيّة
AOrchestra: أوتوماتيكيّة إنشاء الوكلاء الفرعيين لتنظيم الوكلاء الوظيفيّة
الملخص
أظهرت الوكالات اللغوية وعدًا قويًا في أتمتة المهام. وقد دفعت الحاجة إلى تحقيق هذا الوعد في المهام المعقدة بشكل متزايد وذات مدى طويل إلى ظهور نموذج فرعي يُعرف بـ "الوكيل كأدوات" لحل المهام متعددة الدورات. ومع ذلك، ما زالت التصاميم الحالية تفتقر إلى رؤية تعميم ديناميكية للوكالات الفرعية، مما يؤثر سلبًا على قدرة التكيّف. نعالج هذه التحديات من خلال إطار تعميم موحد وغير مرتبط بمنصة معينة، يُمثّل أي وكيل كمُجمّع يتكوّن من أربع عناصر: التعليمات، السياق، الأدوات، النموذج. يُشكّل هذا المُجمّع وصفة تراكيبية للقدرات، مما يمكّن النظام من إنشاء نُفذين متخصصين لكل مهمة عند الحاجة. وبما يعتمد على هذا التعميم، نقدّم نظامًا وكليًا يُسمّى AOrchestra، حيث يقوم المحكم المركزي بتفعيل هذا المُجمّع في كل خطوة: فهو يُعدّ السياق المتعلق بالمهمة، ويختار الأدوات والنموذج، ويُسند التنفيذ من خلال إنشاء وكيل تلقائي وفقًا للحاجة. تتيح هذه التصاميم تقليل جهود الهندسة البشرية، وتبقى غير مربوطة بمنصة معينة، مع دعم سهل للتكامل مع أنواع مختلفة من الوكالات كمُنفّذين للمهام. كما تتيح نظامًا قابلاً للتحكم في التوازن بين الأداء والتكلفة، ما يسمح للنظام بالاقتراب من الكفاءة البورتية (Pareto-efficient). وقد حقق AOrchestra تحسينًا نسبيًا بنسبة 16.28% مقارنة بأقوى نموذج قاعدة في ثلاث بenchmark صعبة (GAIA، SWE-Bench، Terminal-Bench) عند استخدامه مع Gemini-3-Flash. يُمكن الوصول إلى الكود عبر: https://github.com/FoundationAgents/AOrchestra
One-sentence Summary
Researchers from multiple institutions propose AORCHESTRA, a framework-agnostic system using dynamic agent tuples (Instruction, Context, Tools, Model) to auto-generate specialized executors, reducing human effort and enabling Pareto-efficient performance-cost trade-offs, outperforming baselines by 16.28% on GAIA, SWE-Bench, and Terminal-Bench.
Key Contributions
- AORCHESTRA introduces a unified, framework-agnostic agent abstraction as a 4-tuple 〈Instruction, Context, Tools, Model〉, enabling dynamic on-demand creation of specialized sub-agents tailored to each subtask’s requirements.
- The system’s central orchestrator automatically concretizes this tuple at each step by curating context, selecting tools and models, and spawning executors—reducing human engineering and supporting plug-and-play integration of diverse agents.
- Evaluated on GAIA, SWE-Bench, and Terminal-Bench with Gemini-3-Flash, AORCHESTRA achieves a 16.28% relative improvement over the strongest baseline, demonstrating superior performance in complex, long-horizon tasks while enabling controllable cost-performance trade-offs.
Introduction
The authors leverage a dynamic, framework-agnostic agent abstraction—defined as a 4-tuple (Instruction, Context, Tools, Model)—to enable on-demand creation of specialized sub-agents for complex, long-horizon tasks. Prior systems either treated sub-agents as static roles (requiring heavy engineering and lacking adaptability) or as isolated context threads (ignoring capability specialization), limiting performance in open-ended environments. AORCHESTRA’s orchestrator automatically concretizes this tuple at each step, selecting tools, models, and context to spawn tailored executors, reducing human effort while enabling cost-performance trade-offs. Evaluated on GAIA, SWE-Bench, and Terminal-Bench, it delivers a 16.28% relative improvement over baselines when paired with Gemini-3-Flash, and supports learning-based optimization for even better efficiency.
Dataset

-
The authors use three benchmark datasets for evaluation: GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified. GAIA contains 165 tasks testing tool-augmented, multi-step reasoning; Terminal-Bench 2.0 includes 89 real-world command-line workflows (70 sampled for cost); SWE-Bench-Verified has 500 software engineering tasks (100 sampled), all verified via test execution and human screening.
-
Each task is structured with an instruction template including repository and instance ID fields. The agent system breaks down complex queries—like identifying 2015 Met exhibition zodiac figures—into delegated subtasks with detailed instructions, context, and model assignments.
-
The model uses a recursive delegation strategy: initial attempts identify the exhibition and accession numbers; later attempts refine object identification and hand visibility checks; final decisions synthesize findings into a single answer (e.g., “11” visible hands).
-
Third-party APIs (web search, sandboxed environments) are accessed only via a controlled tool interface. Responses are cached with metadata (URLs, timestamps, queries) to ensure reproducibility and consistent evaluation.
Method
The authors leverage a unified, orchestrator-centric architecture called AORCHESTRA to solve complex, long-horizon agentic tasks. The core innovation lies in treating sub-agents not as static roles or isolated threads, but as dynamically creatable executors parameterized by a four-tuple interface: (I,C,T,M), where I is the task instruction, C is the curated context, T is the tool set, and M is the underlying model. This abstraction decouples working memory (instruction and context) from capability (tools and model), enabling on-demand specialization for each subtask.
Refer to the framework diagram, which illustrates the orchestrator’s iterative process. The system begins with a user’s task, which the Orchestrator Agent decomposes into subtasks. At each step t, the Orchestrator samples an action at from its restricted action space AAORCHESTRA={Delegate(Φt),Finish(y)}. If the action is Delegate, the Orchestrator instantiates a Dynamic SubAgent with the specified four-tuple Φt=(It,Ct,Tt,Mt). This sub-agent executes the subtask using model Mt, restricted to tool set Tt, and conditioned only on (It,Ct). Upon completion, it returns a structured observation ot—typically including a result summary, artifacts, and error logs—which is integrated into the next system state st+1 via the state-transition function δ(st,at,ot). The process repeats until the Orchestrator selects Finish, outputting the final answer y.
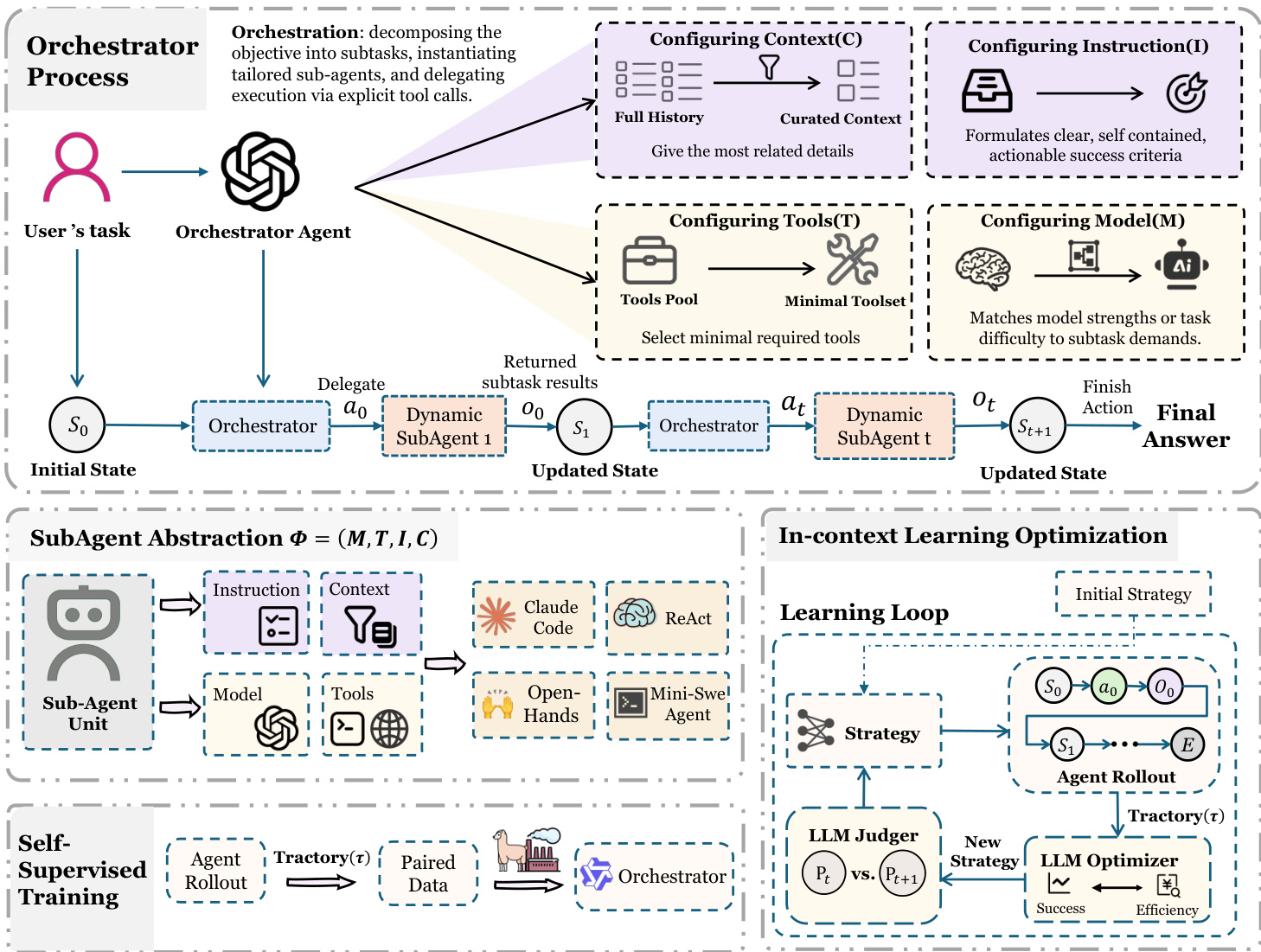
The Orchestrator’s design explicitly separates orchestration from execution: it never directly performs environment actions. Instead, it delegates all execution to dynamically instantiated sub-agents. This enables fine-grained control over context, tools, and model selection per subtask. For instance, the Orchestrator can curate context by filtering the full history to provide only the most relevant details, configure tools by selecting a minimal required subset from a pool, and match model capabilities to subtask demands—such as selecting a cheaper model for simple tasks or a more capable one for complex reasoning.
The framework also supports two complementary learning paradigms to improve the Orchestrator’s policy πθ(at∣st). First, supervised fine-tuning (SFT) distills expert trajectories to improve task orchestration—enhancing subtask decomposition and the synthesis of (It,Ct,Tt). Second, iterative in-context learning optimizes cost-aware orchestration without updating model weights. Here, the Orchestrator’s instruction Imain is treated as a learnable object. After rolling out trajectories τk, an optimizer analyzes performance and cost metrics to propose prompt edits ΔI, updating the instruction as Ik+1main=OPTIMIZE(Ikmain,τk,Perf(τk),Cost(τk)). This loop aims to discover Pareto-efficient trade-offs between performance and cost, such as selecting cheaper models for non-critical subtasks.
The sub-agent abstraction is implementation-agnostic, allowing diverse internal designs—from a simple ReAct loop to a mini-SWE agent—while maintaining a consistent interface for the Orchestrator. This flexibility, combined with explicit capability control and learnable orchestration, enables AORCHESTRA to achieve strong training-free performance and adapt to cost-performance trade-offs across benchmarks.
Experiment
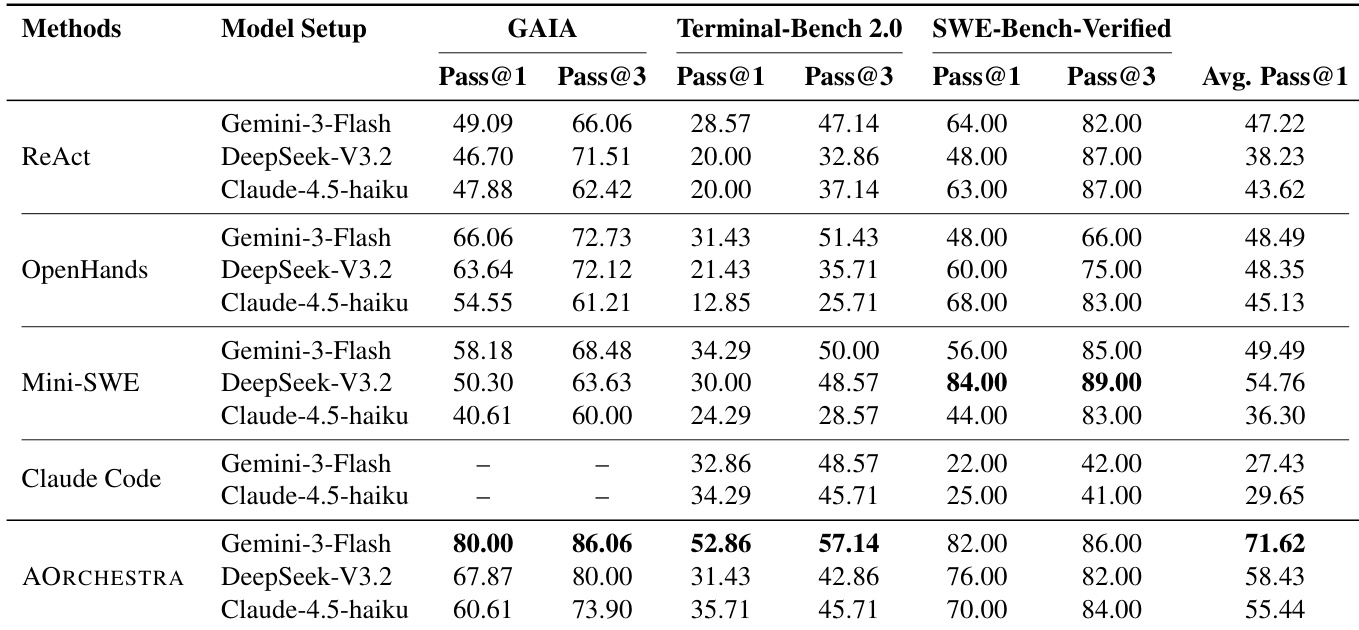
- AORCHESTRA consistently outperforms baseline systems across GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified, achieving significant gains in pass@1 and pass@3 metrics, particularly with Gemini-3-Flash as orchestrator.
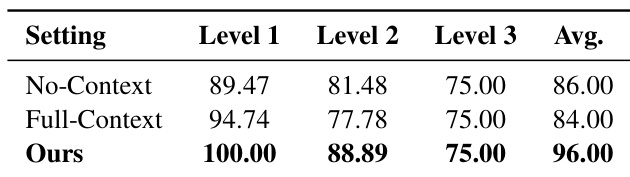
- Context sharing between orchestrator and sub-agents proves critical: curated, task-relevant context improves performance over no context or full context inheritance, reducing noise and preserving execution fidelity.
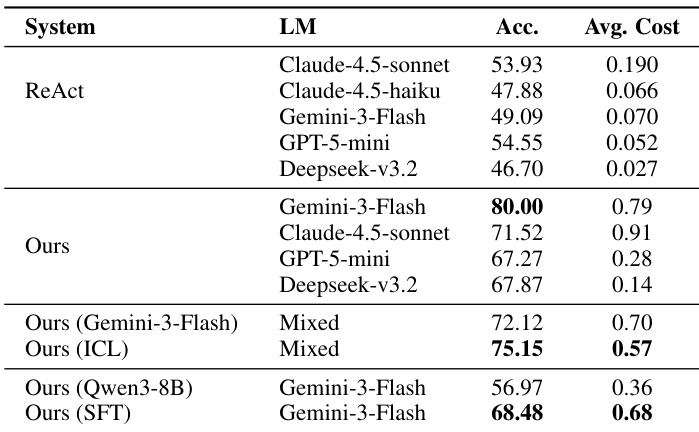
- Orchestration is a learnable skill: fine-tuning a smaller model (Qwen3-8B) for task delegation boosts performance, and in-context learning enables cost-aware model routing that improves both accuracy and efficiency.
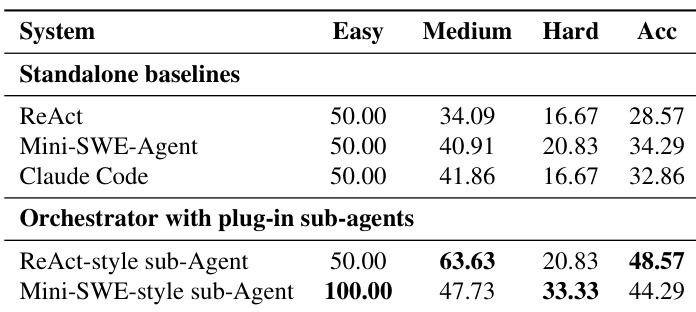
- Plug-and-play sub-agents demonstrate framework robustness: AORCHESTRA maintains strong performance when swapping sub-agent backends, confirming modular design and implementation independence.
- The system exhibits strong long-horizon reasoning and error recovery: it successfully resolves complex, multi-attempt tasks by iteratively refining hypotheses, propagating intermediate findings, and adapting based on sub-agent feedback.
The authors evaluate context-sharing strategies in their agent framework by comparing No-Context, Full-Context, and their proposed method. Results show that explicitly curating and passing relevant context to sub-agents significantly improves performance across all difficulty levels, achieving the highest average score. This design avoids the pitfalls of missing critical cues or introducing noise from irrelevant history.
The authors use a hierarchical agent framework where a main orchestrator delegates tasks to specialized sub-agents, achieving higher accuracy than baseline systems across multiple benchmarks. Results show that explicitly curating and passing context to sub-agents improves performance, and that fine-tuning or in-context learning of the orchestrator further enhances both accuracy and cost efficiency. The system also demonstrates robustness by maintaining strong performance even when using smaller models or different sub-agent backends.
The authors use an orchestrator framework that dynamically delegates tasks to specialized sub-agents, achieving higher overall accuracy than standalone baselines across difficulty levels. Results show that combining the orchestrator with different sub-agent styles improves performance, particularly on medium-difficulty tasks, while maintaining strong results on easy tasks. The framework demonstrates flexibility in sub-agent selection, with ReAct-style sub-agents yielding the best overall accuracy.
The authors use AORCHESTRA, a multi-agent orchestration framework, to outperform baseline systems across three diverse benchmarks: GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified. Results show consistent gains in pass@1 and pass@3 metrics, with the largest improvements observed on Terminal-Bench 2.0 and GAIA, indicating strong generalization across task types and model backbones. The system’s design—enabling context-aware sub-agent delegation, learnable orchestration, and plug-and-play execution—contributes to its robust performance and cost-efficiency.