Command Palette
Search for a command to run...
Quant VideoGen: توليد فيديو طويل متسلسل عبر التكميم ثنائي البت لذاكرة التخزين المؤقت KV
Quant VideoGen: توليد فيديو طويل متسلسل عبر التكميم ثنائي البت لذاكرة التخزين المؤقت KV
الملخص
رغم التقدم السريع في نماذج التمايز الفيديو ذات التوليد التلقائي (autoregressive video diffusion)، تظل عقبة خوارزمية نظام مُحددة تُحد من إمكانية التوظيف وقدرة التوليد: ذاكرة ذاكرة التخزين المؤقت للقيم (KV cache). في نماذج التوليد الفيديو ذات التوليد التلقائي، تزداد ذاكرة التخزين المؤقت للقيم (KV cache) مع تقدم عملية التوليد، وتُصبح هي المُهيمنة على ذاكرة وحدة معالجة الرسومات (GPU) بسرعة، وغالبًا ما تتجاوز 30 جيجابايت، مما يمنع تشغيل النماذج على الأجهزة المتاحة على نطاق واسع. وبشكل أكثر أهمية، فإن القيود المفروضة على ميزانية ذاكرة التخزين المؤقت للقيم (KV cache) تُحد من الذاكرة العاملة الفعّالة، مما يؤدي مباشرة إلى تدهور التماسك على المدى الطويل فيما يتعلق بالهوية والهيكلية والحركة. ولحل هذه التحديات، نقدّم "Quant VideoGen" (QVG)، وهي إطار عمل لترميز ذاكرة التخزين المؤقت للقيم (KV cache) بدون تدريب، مُصمم خصيصًا لنماذج التمايز الفيديو ذات التوليد التلقائي. يستفيد QVG من التكرار الفضائي الزمني (spatiotemporal redundancy) في الفيديو من خلال تقنية "التنعيم الواعي بالمعنى" (Semantic Aware Smoothing)، مما ينتج بقايا ذات مقدار منخفض وسهلة الترميز. كما يقدّم QVG تقنية "الترميز التدريجي للباقات" (Progressive Residual Quantization)، وهي خطة متعددة المراحل تبدأ من التقدير الأولي إلى التحسين الدقيق، والتي تقلل من خطأ الترميز مع تمكين توازن سلس بين الجودة وحجم الذاكرة. على معايير LongCat Video و HY WorldPlay و Self Forcing، يُحدِّد QVG حدود بارتو (Pareto frontier) جديدة بين الجودة وكفاءة الذاكرة، حيث يقلل من استهلاك ذاكرة التخزين المؤقت للقيم (KV cache) حتى 7 أضعاف، مع تجاوز 4% فقط في تأخير التوقيت الشامل، مع الحفاظ على تفوق مستمر على النماذج القائمة من حيث جودة التوليد.
One-sentence Summary
Researchers from MIT, UC Berkeley, and Tsinghua propose Quant VideoGen (QVG), a training-free KV-cache quantization method that leverages spatiotemporal redundancy and progressive residual quantization to cut memory use by 7× while preserving video consistency and quality across long-horizon generation tasks.
Key Contributions
- Auto-regressive video diffusion models face a critical KV-cache memory bottleneck that limits deployment on consumer hardware and degrades long-horizon consistency in identity, layout, and motion due to forced memory budgeting.
- Quant VideoGen (QVG) introduces a training-free quantization framework leveraging Semantic-Aware Smoothing and Progressive Residual Quantization to exploit spatiotemporal redundancy, producing low-magnitude, quantization-friendly residuals with coarse-to-fine error reduction.
- Evaluated on LongCat-Video, HY-WorldPlay, and Self-Forcing, QVG reduces KV memory up to 7.0× with <4% latency overhead, enables HY-WorldPlay-8B to run on a single RTX 4090, and achieves higher PSNR than baselines under constrained memory.
Introduction
The authors leverage auto-regressive video diffusion models to enable long-horizon video generation, which is critical for applications like live streaming, interactive content, and world modeling. However, these models face a severe memory bottleneck: the KV-cache grows linearly with video length and quickly exceeds GPU capacity, forcing short context windows that degrade consistency in identity, motion, and layout. Prior KV-cache quantization methods from LLMs fail on video due to its heterogeneous activation statistics and lack of spatiotemporal awareness. Their main contribution, Quant VideoGen (QVG), is a training-free framework that exploits video’s spatiotemporal redundancy via Semantic-Aware Smoothing—grouping similar tokens and subtracting centroids to create low-magnitude residuals—and Progressive Residual Quantization, a multi-stage compression scheme that refines quantization error. QVG reduces KV-cache memory by up to 7x with under 4% latency overhead, enabling high-quality, minute-long generation on consumer GPUs and setting a new quality-memory Pareto frontier.
Method
The authors leverage a two-stage quantization framework—Semantic-Aware Smoothing followed by Progressive Residual Quantization—to address the challenges of quantizing video KV-cache, which exhibits both high dynamic range and spatiotemporal redundancy. The overall pipeline is designed to progressively reduce quantization error by exploiting semantic similarity and temporal structure inherent in video tokens.
The process begins with Semantic-Aware Smoothing, which operates on chunks of tokens (e.g., N=HWTc tokens per chunk) extracted from the KV-cache tensor X∈RN×d. The authors apply k-means clustering to partition tokens into C disjoint groups G={G1,…,GC} based on their hidden representations. Each group’s centroid Ci∈Rd is computed as the mean of its members. The residual for each group is then derived via centroid subtraction:
Ri=XGi−Ci,Ri∈R∣Gi∣×dThis step effectively reduces the dynamic range within each group, as large outlier values are captured in the centroids and subtracted out. The result is a residual tensor R with significantly lower maximum magnitude, which directly reduces quantization error since E[∥x−x^∥]∝SX, and SX is proportional to the maximum absolute value in the group.
Refer to the framework diagram, which illustrates how the original KV-cache (a) is transformed through semantic grouping and centroid subtraction (b) into a smoother residual distribution, enabling more accurate low-bit quantization.
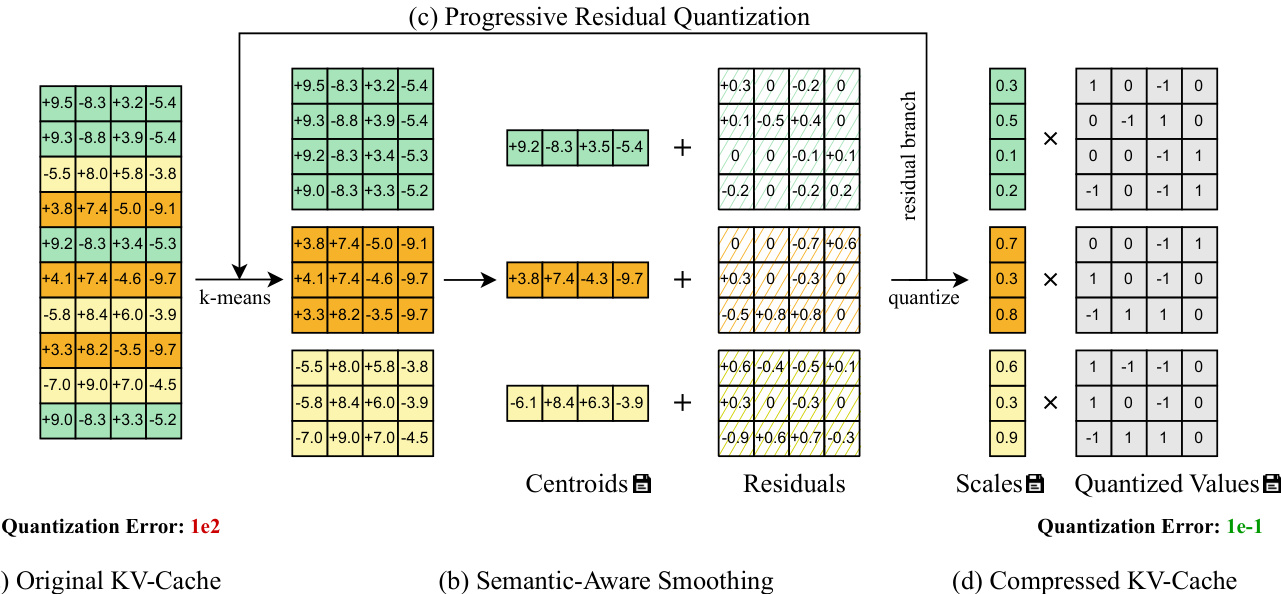
Building on this, Progressive Residual Quantization iteratively refines the residual tensor across T stages. Starting with R(0)=X, each stage applies Semantic-Aware Smoothing to the current residual to produce a new residual R(t), centroids C(t), and assignment vector π(t). After T stages, the final residual R(T) is quantized using symmetric per-group integer quantization:
XINT,SX=Q(R(T))The centroids and assignment vectors from all stages are stored in global memory, while intermediate residuals are discarded. During dequantization, the process is reversed: the quantized residual is dequantized and then iteratively reconstructed by adding back the assigned centroids from stage T down to stage 1, yielding the final reconstructed tensor X^(0).
This multi-stage approach allows the model to capture coarse semantic structure in early stages and fine-grained variations in later stages, leading to diminishing but cumulative reductions in quantization error. As shown in the figure, the quantization error drops from 1e2 in the original cache to 1e−1 in the final compressed representation, demonstrating the efficacy of the progressive refinement.
To support efficient deployment, the authors introduce algorithm-system co-design optimizations. They accelerate k-means by caching centroids from prior chunks, reducing clustering overhead by 3×. Additionally, they implement a fused dequantization kernel that reconstructs the full tensor by adding back centroids across all stages while keeping intermediate results in registers to minimize global memory access.
Experiment
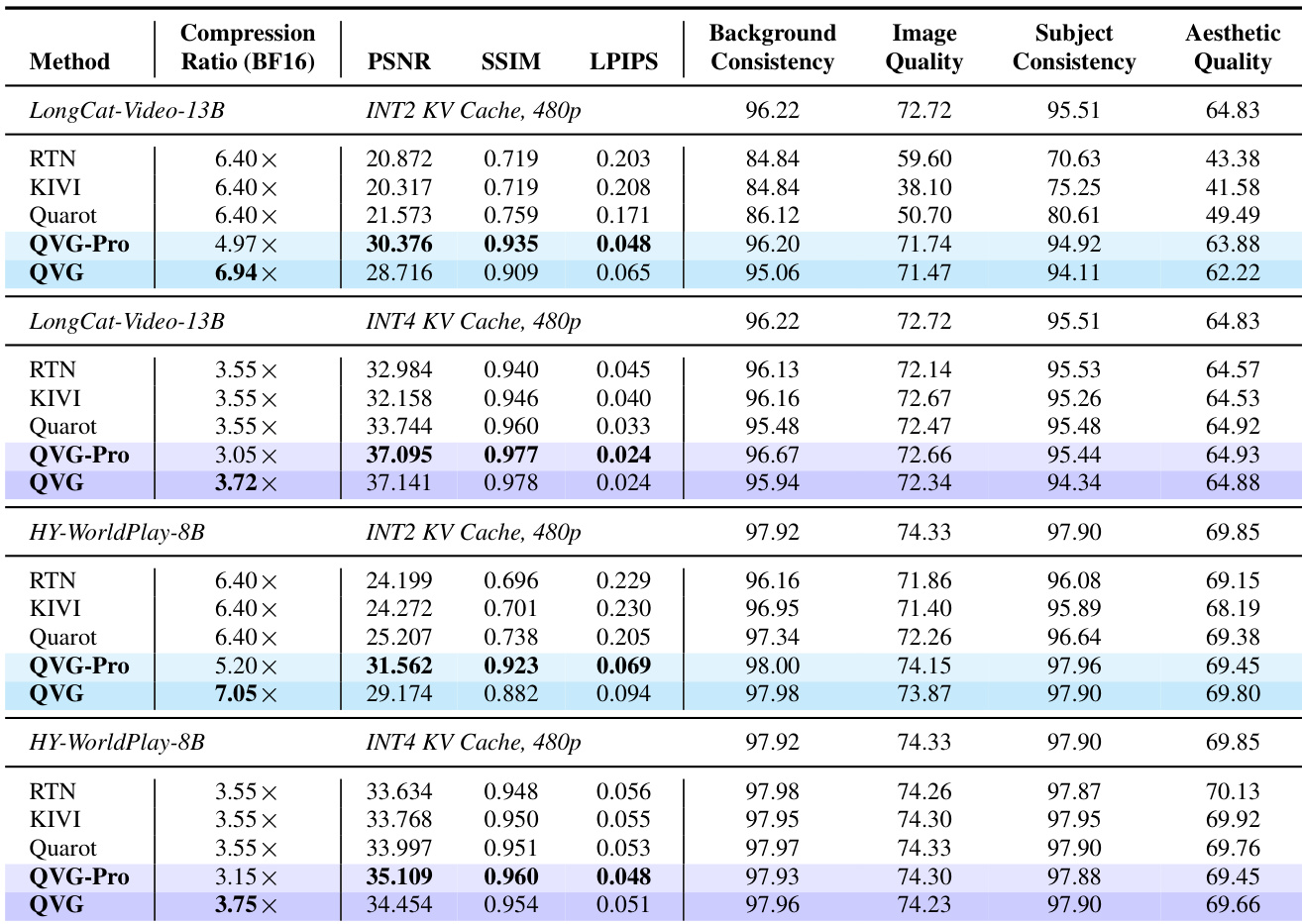
- QVG and QVG-Pro significantly reduce KV-cache memory usage (up to 7x compression) while preserving video fidelity and perceptual quality across LongCat-Video-13B, HY-WorldPlay-8B, and Self-Forcing-Wan models.
- Both variants maintain near-lossless performance on VBench metrics (Background, Subject, Image, and Aesthetic Quality), outperforming baselines like RTN, KIVI, and QuaRot, especially under INT2 quantization.
- QVG effectively mitigates long-horizon drift, sustaining stable image quality beyond 700 frames in Self-Forcing, whereas baselines degrade sharply after ~100 frames.
- End-to-end latency overhead is minimal (1.5%–4.3% across models), confirming QVG does not impede generation speed.
- Progressive Residual Quantization’s first stage delivers the largest MSE reduction; subsequent stages offer diminishing returns.
- Larger quantization block sizes (e.g., 64) improve compression but reduce quality, while smaller blocks (e.g., 16) preserve quality at the cost of lower compression.
The authors use QVG and QVG-Pro to compress the KV cache in video generation models, achieving high compression ratios while preserving perceptual quality across multiple metrics. Results show that QVG-Pro delivers the highest fidelity scores, while QVG offers the largest memory savings with only minor quality trade-offs, outperforming all baselines. Both methods maintain near-lossless performance over long video sequences, effectively mitigating drift without introducing significant latency.