Command Palette
Search for a command to run...
توسيع الوكالات الصغيرة من خلال المزادات الاستراتيجية
توسيع الوكالات الصغيرة من خلال المزادات الاستراتيجية
Lisa Alazraki William F. Shen Yoram Bachrach Akhil Mathur
الملخص
تُنظر إلى النماذج اللغوية الصغيرة بشكل متزايد على أنها منهجية واعدة وفعالة من حيث التكلفة للذكاء الاصطناعي الوظيفي (Agentic AI)، حيث يدّعي المُؤيدون أنها كافية الكفاءة لتنفيذ سير العمل الوظيفي. ومع ذلك، في حين أن الوكلاء الصغار يمكنهم التمايز بدقة مع الوكلاء الكبار في المهام البسيطة، لا يزال غير واضح مدى تطور أدائهم مع تعقيد المهمة، أو متى يصبح من الضروري استخدام النماذج الكبيرة، أو كيف يمكن الاستفادة بشكل أفضل من الوكلاء الصغار في المهام ذات الأفق الطويل. في هذه الدراسة، نُظهر تجريبيًا أن أداء الوكلاء الصغار لا يتوسع مع تعقيد المهمة في المهام ذات البحث العميق والبرمجة، ونُقدّم إطارًا جديدًا يُسمى "مزايدة الاستراتيجيات لتحسين كفاءة الحملات" (SALE)، مستوحى من أسواق العمل الحر. في هذا الإطار، يقدّم الوكلاء عروضًا بخطط استراتيجية قصيرة، تُقيّم عبر آلية منظمة تُقيّم التكلفة مقابل القيمة، ثم تُحسّن عبر ذاكرة مزودة مشتركة للمزايدة، ما يُمكّن من توجيه المهام حسب الحاجة، وتحقيق تحسّن ذاتي مستمر دون الحاجة إلى تدريب جهاز توجيه منفصل أو تشغيل جميع النماذج حتى اكتمالها. على مدى مهام بحث عميقة وبرمجة بمستويات مختلفة من التعقيد، يقلّل SALE من الاعتماد على أكبر وكيل بنسبة 53٪، ويقلّل التكلفة الإجمالية بنسبة 35٪، ويتخطى أداء أكبر وكيل في مؤشر "pass@1" بشكل مستمر، مع إضافة تكلفة زائدة ضئيلة جدًا تتجاوز فقط تكاليف تنفيذ المسار النهائي. في المقابل، تُظهر أنظمة التوجيه التقليدية التي تعتمد على وصف المهمة إما أن تؤدي أداءً أضعف من أكبر وكيل، أو فشلت في خفض التكلفة – وأحيانًا كلا الأمرين معًا – مما يُبرز مدى عدم ملاءمتها لسير العمل الوظيفي. تشير هذه النتائج إلى أن الوكلاء الصغار قد تكون غير كافية لمهام معقدة، لكنها يمكن "توسيعها" فعّالًا من خلال توزيع المهام المنسق وتحسين ذاتي أثناء وقت الاختبار. وعلى نطاق أوسع، تُحفّز هذه النتائج رؤية على مستوى النظام للذكاء الاصطناعي الوظيفي، حيث تأتي المكاسب في الأداء أقل من ازدياد حجم النماذج الفردية المستمرة، وأكثر من آليات تنسيق مستوحاة من السوق، تُنظّم الوكلاء المتنوعين في بيئات فعّالة وقابلة للتكيف.
One-sentence Summary
Researchers from Meta, Imperial College London, and the University of Cambridge propose SALE, a marketplace-inspired framework where small and large language models bid with strategic plans to handle complex agentic tasks; SALE reduces reliance on the largest model by 53% and overall cost by 35% while improving accuracy through test-time self-improvement and cost-value auctions.
Key Contributions
- Small agents perform nearly on par with large ones on simple tasks but degrade significantly as complexity increases in deep search and coding workloads, a scaling gap empirically quantified here for the first time using real-world tasks paired with human solution times via the new HST-BENCH benchmark.
- The paper introduces SALE, a marketplace-inspired framework where heterogeneous agents bid with strategic plans scored by cost-value metrics and refined through shared auction memory, enabling dynamic task routing and test-time self-improvement without requiring separate training or full model execution.
- SALE reduces reliance on the largest agent by 53% and cuts overall cost by 35% while matching or exceeding its performance on complex tasks, outperforming static routers that fail to adapt or reduce cost, demonstrating that auction-based coordination can effectively “scale up” small agents through adaptive orchestration.
Introduction
The authors leverage small language models as cost-effective agents for complex workflows but find their performance degrades sharply as task complexity increases—particularly in deep search and coding—making them insufficient alone for long-horizon tasks. Prior routing methods either require running all models to completion (too expensive) or rely on static, trained classifiers that fail to adapt or scale with difficulty. Their main contribution is SALE, a marketplace-inspired framework where agents bid with short strategic plans, which are scored and refined via shared auction memory to enable dynamic, test-time routing and self-improvement—without training a separate router. SALE reduces reliance on the largest agent by 53%, cuts overall cost by 35%, and outperforms both single models and existing routers, demonstrating that coordinated heterogeneous agents can deliver better performance-cost trade-offs than scaling individual models alone.
Dataset

The authors use HST-BENCH, a human-timed evaluation dataset of 753 agentic tasks, to measure performance across deep search and coding domains. Here’s how they construct and use it:
-
Dataset Composition and Sources
HST-BENCH combines existing open-source benchmarks: SimpleQA, PopQA, HotpotQA, GAIA, Humanity’s Last Exam (HLE), MBPP, and LeetCode. They supplement coding with a custom multiple-choice set (Coding-MCQ) to better populate low-complexity bins. -
Key Details per Subset
- Tasks are sampled from official test splits; invalid or unanswerable instances are discarded.
- HLE is restricted to expert-validated chemistry/biology questions.
- GAIA’s human solution times are reused from its validation split.
- LeetCode “Hard” tasks use published timing estimates (Siroš et al., 2024) due to annotation cost.
- Coding-MCQ includes short, conceptual questions targeting core programming knowledge (examples in Appendix A.4).
-
Complexity Binning and Annotation
- Human solution time (τ(t)) is annotated by 3+ expert annotators per task (CS graduates), using permitted tools only (e.g., browser, IDE).
- Times are filtered for correctness and outliers (>2 SD from mean), then averaged.
- Tasks are grouped into 5 non-overlapping bins based on τ(t): 0–0.1 min, 0.1–0.5 min, 0.5–2.5 min, 2.5–12.5 min, 12.5–60 min.
- Bins follow a geometric progression (5× spacing) to balance sample sizes across 3 orders of magnitude in solution time.
- Inter-annotator reliability is high (Krippendorff’s α = 0.86).
-
Use in Model Evaluation
- The test split contains 753 tasks; separate dev sets (68 for search, 88 for coding) are used for tuning.
- Model performance is analyzed per complexity bin to study how scaling affects agentic capability.
- The authors use Qwen3 models (4B–32B) for controlled scaling experiments, isolating size effects while holding architecture and training constant.
- Evaluation metrics include success rate and cost (token-based), with future extensions planned for tool pricing.
-
Processing and Metadata
- Metadata includes source dataset, complexity bin, and aggregated human solution time.
- Table 3 (in paper) shows dataset contribution per bin — low bins dominated by SimpleQA/Coding-MCQ, high bins by GAIA, HLE, and LeetCode Hard.
- No cropping or data augmentation is applied; tasks are used in original form with standardized timing protocols.
Method
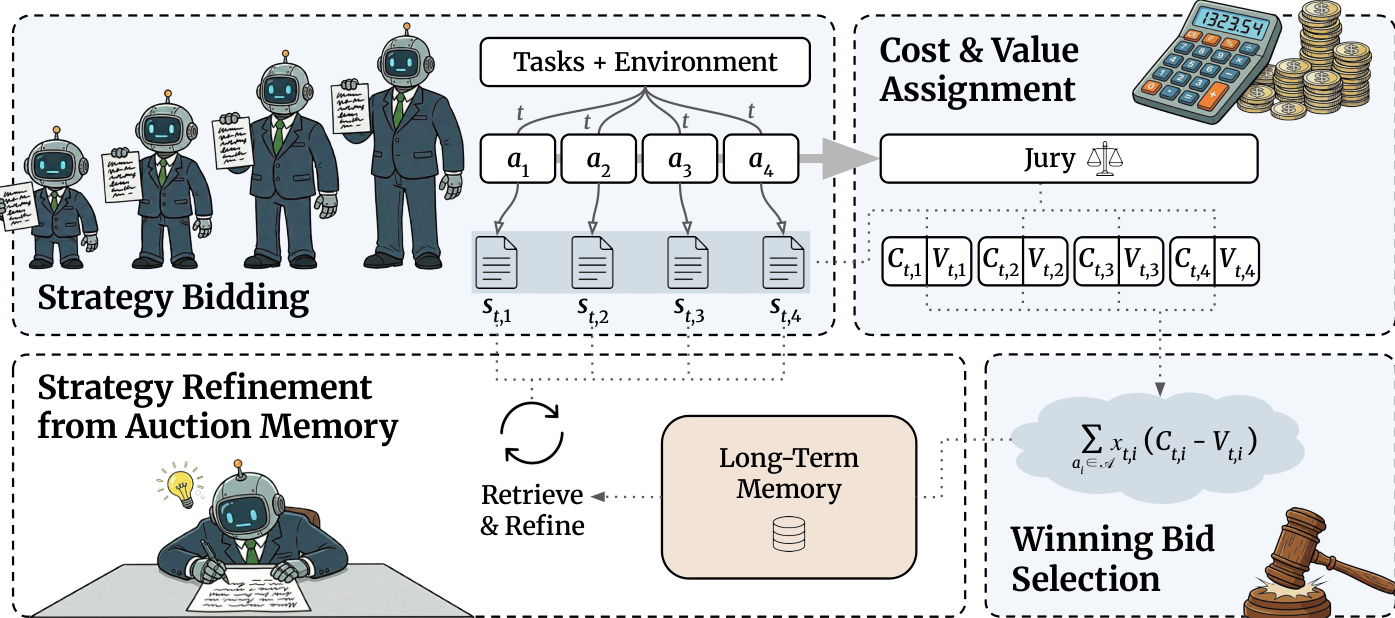
The authors leverage a novel auction-based framework, SALE, to dynamically route tasks to the most suitable agent within a heterogeneous pool by treating strategic plans as competitive bids. The architecture is structured around four core stages: strategy bidding, cost and value assignment, winning bid selection, and strategy refinement from auction memory. Each stage is designed to optimize the trade-off between computational cost and expected performance, with the entire process governed by learned scoring weights.
In the strategy bidding phase, each agent ai in the pool A generates a strategy st,i conditioned on the task t and environment E. These strategies are interpreted as bids, encoding the agent’s intended approach, including decomposition, tool selection, and anticipated challenges. The authors emphasize that these plans are not merely execution artifacts but serve as informative signals for model selection.
Refer to the framework diagram, which illustrates how multiple agents submit their strategies in parallel for a given task. The strategies are then passed to the cost and value assignment module. Cost Ct,i is estimated as a function of the agent’s token price π(ai), the length of the strategy ∣st,i∣, and a tunable weight wc:
Ct,i=wc⋅π(ai)⋅∣st,i∣.This formulation leverages strategy length as a proxy for total inference cost and execution risk, grounded in prior work showing that longer plans correlate with higher failure rates and token consumption.
Value Vt,i is computed as a weighted combination of intrinsic and extrinsic signals:
Vt,i=wh⋅H(st,i)+aj∈A∑wj⋅γj(st,i),where H(st,i) is the normalized entropy of the strategy, capturing informational richness, and γj(st,i) represents peer and self-assessments from a jury of agents. The entropy term is motivated by evidence that higher-entropy reasoning correlates with reduced redundancy and improved planning outcomes. The jury scoring mechanism, which includes both self- and peer-evaluation, is designed to enhance judgment reliability, as supported by literature on LLM juries.
The winning bid selection module employs a min-max optimization to learn scoring weights w=(wc,wh,{wj}) that minimize the worst-case cost-minus-value Ct,i−Vt,i across a training set of tasks. This objective ensures robustness by guarding against poor assignments on any single task. At inference time, for each new task t, the system assigns binary variables xt,i∈{0,1} to select exactly one agent, minimizing:
zt=ai∈A∑xt,i(Ct,i−Vt,i),which reduces to selecting the agent with the lowest Ct,i−Vt,i.
To further enhance cost-efficiency, the framework incorporates a strategy refinement mechanism powered by a long-term memory bank M. After each auction, all submitted strategies—winning and losing—are stored alongside task outcomes. For a new task t, if the provisional winner is not the cheapest agent, cheaper agents retrieve contrastive pairs of past winning and losing strategies from memory, conditioned on task similarity. These agents then generate refined strategies st,ir using a contrastive prompt template, which are re-evaluated for cost and value. If any refined bid improves the cost-value trade-off, it replaces the provisional winner; otherwise, the original selection is retained. This opportunistic refinement ensures that only cost-efficient agents incur the overhead of memory retrieval and re-planning, preserving the system’s overall efficiency.
The entire auction mechanism, including jury scoring and refinement, incurs minimal inference overhead—on the order of a few hundred tokens—compared to the tens of thousands or millions of tokens typically consumed during final execution, making the overhead negligible relative to total compute.
Experiment
- Smaller, cheaper agents perform nearly as well as larger ones on simple tasks but fall sharply behind as task complexity increases, showing strong stratification by model size and cost.
- Larger agents do not inherently solve complex tasks more token-efficiently; they often use similar or more tokens than smaller agents, failing to offset their higher per-token cost.
- SALE, a strategy-based auction system with memory-driven self-refinement, consistently outperforms single agents and existing routers by dynamically assigning tasks to the most cost-effective agent while improving or matching accuracy.
- SALE reduces cost by 17–53% across task bins while improving or maintaining pass@1, pushing the performance-cost Pareto frontier beyond any single model or baseline router.
- Smaller agents (4B, 8B) handle a significant share of workload even on complex tasks, and their contribution grows over time as auction feedback enables progressive refinement of their strategies.
- Shapley value analysis confirms that smaller agents contribute meaningfully to the ensemble through jury scoring and memory, even when rarely selected for final execution.
- Qualitative analysis reveals complementary failure modes: larger agents often over-engineer or skip verification, while smaller agents rely more on tools and checks, enabling SALE to exploit strategic differences at bid time.
- Ablations show that all components of SALE’s cost-value function and jury mechanism are essential; removing any degrades performance or efficiency, and jury diversity provides robust, low-overhead gains.
- SALE’s routing is conservative, favoring accuracy over cost—often over-escalating to larger agents on easy tasks—but rarely under-escalates, preserving correctness where it matters most.
Removing any single judge from the jury in the SALE system reduces overall pass@1 performance, confirming that each agent contributes unique signal to the ensemble. The full jury consistently outperforms any single judge configuration, with smaller judges like the 4B model playing a critical role in improving both accuracy and cost efficiency, particularly in coding tasks. This diversity in judgment provides a regularizing effect that enhances robustness without adding significant computational overhead.
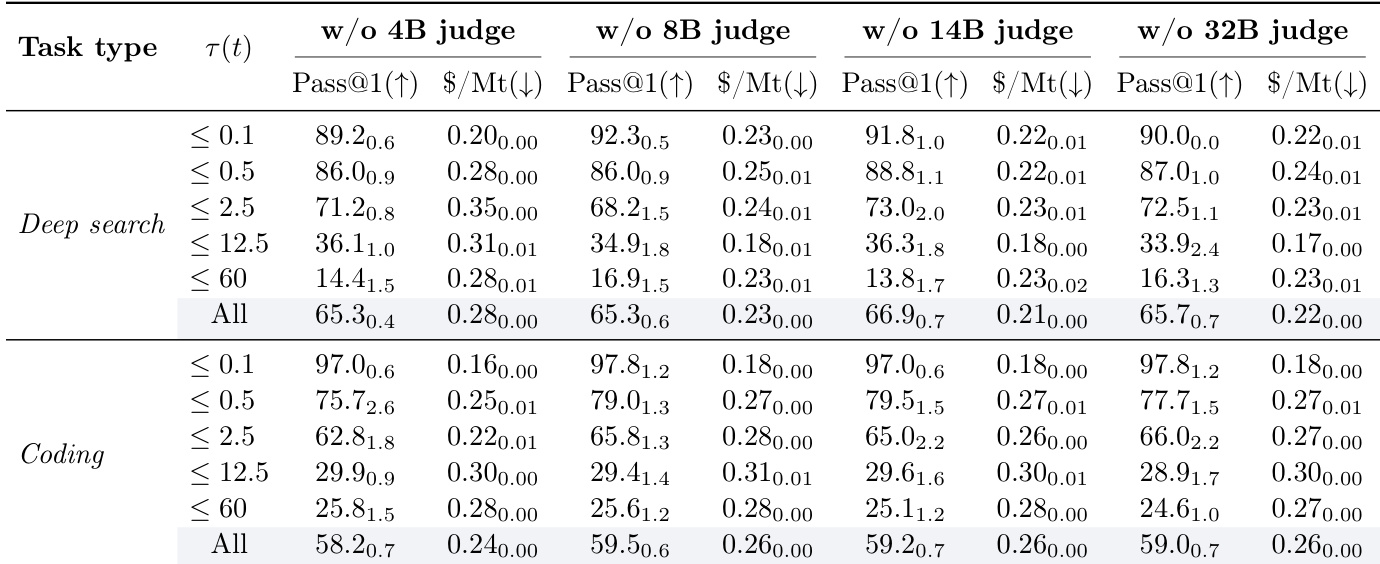
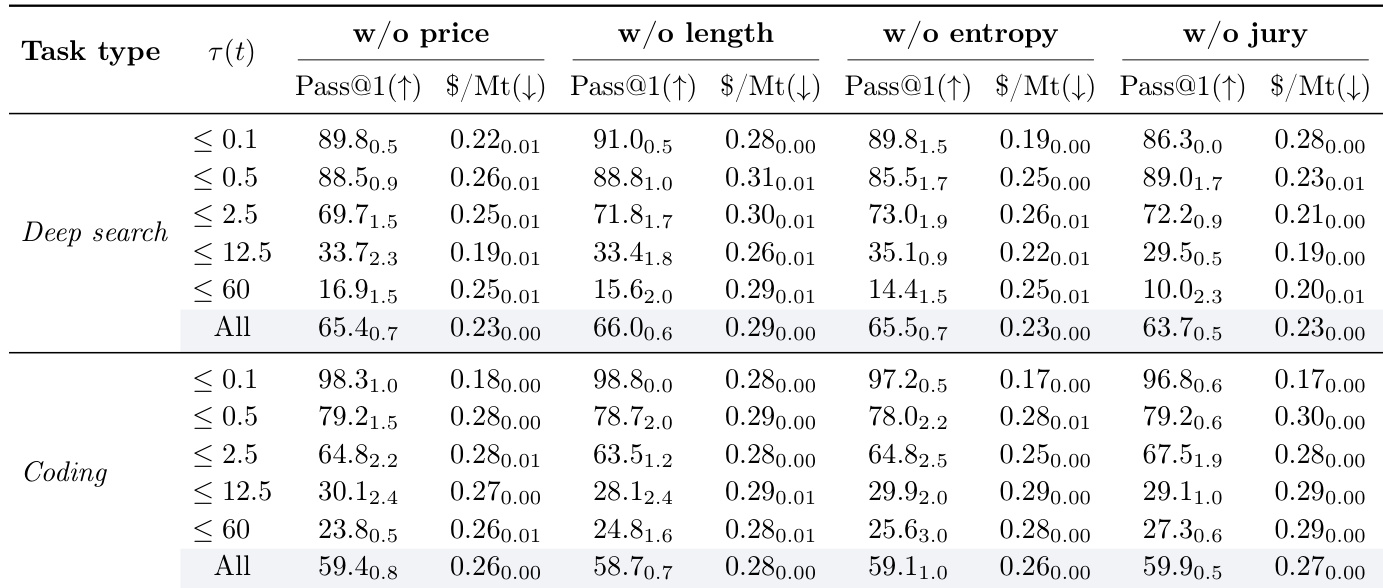
Ablating any component of the cost-value function—price, strategy length, entropy, or jury scoring—consistently reduces overall pass@1 performance, confirming that each term meaningfully contributes to the system’s effectiveness. While some ablations yield slightly lower costs in specific cases, these gains come at the expense of accuracy, particularly on more complex tasks. The full function strikes the optimal balance, enabling both higher performance and more efficient resource use across task types and complexity levels.
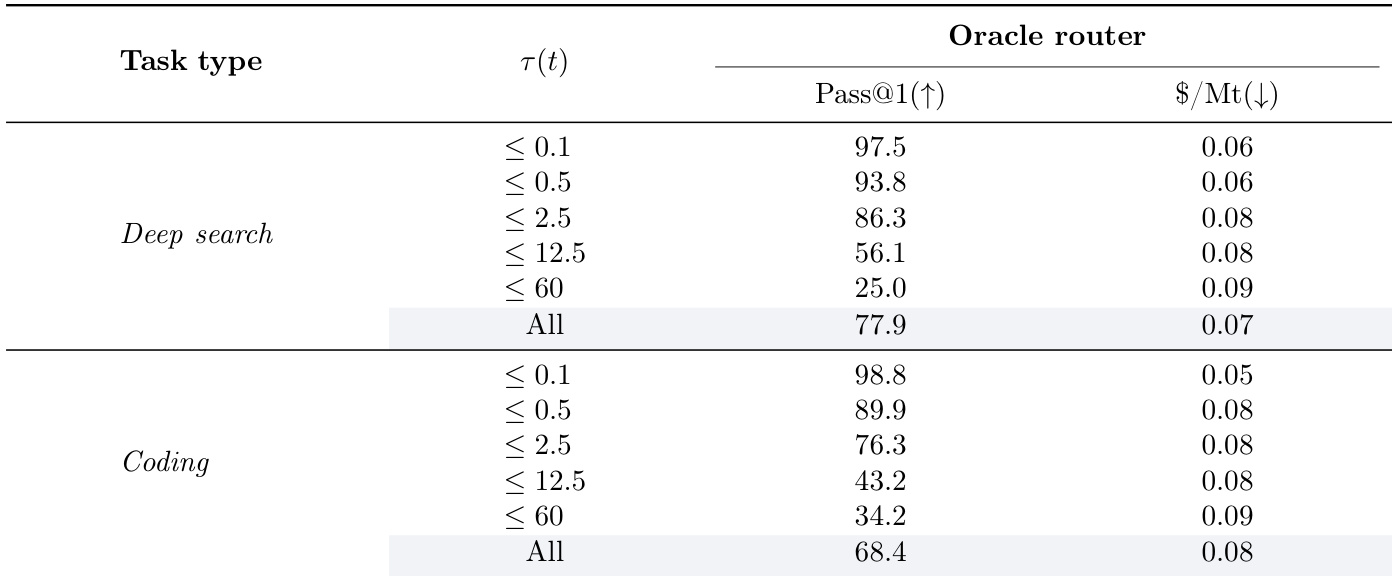
The oracle router, which selects the smallest agent capable of solving each task, achieves the highest possible pass@1 scores across all complexity levels for both deep search and coding tasks, while minimizing cost by defaulting to cheaper models when correctness is unattainable. Results show that performance declines sharply as task complexity increases, with the most complex tasks (τ(t) ≤ 60) yielding pass@1 scores as low as 25.0 for deep search and 34.2 for coding, indicating inherent difficulty rather than routing inefficiency. The consistent cost advantage of the oracle—especially on simpler tasks—highlights the potential for intelligent routing systems to approach this ideal by better matching agent capability to task demands.
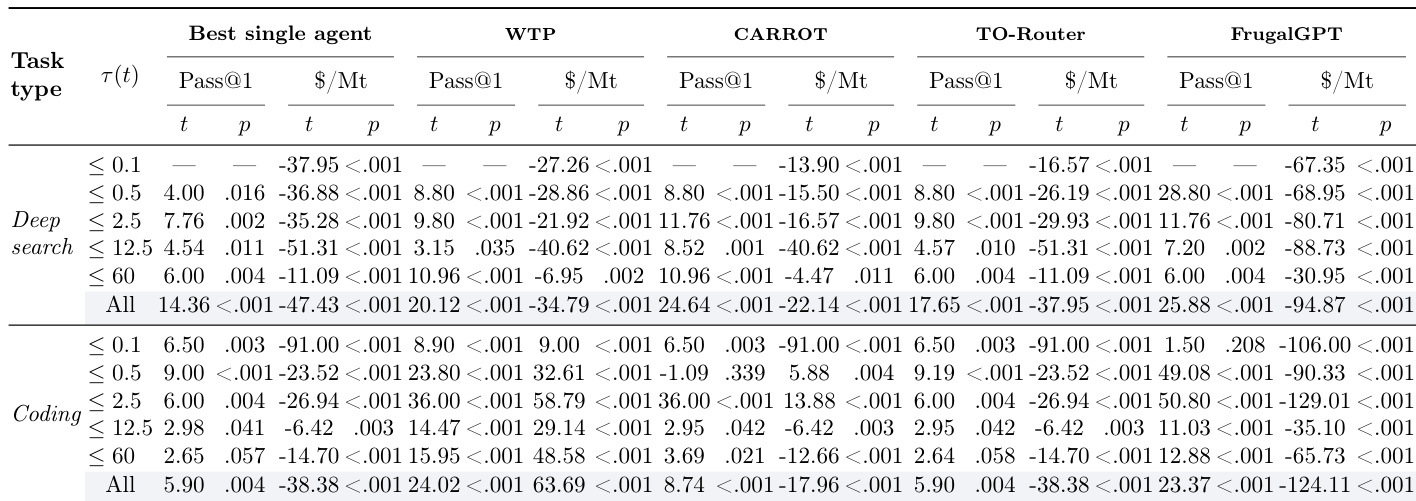
Results show that smaller, cheaper agents perform nearly as well as larger ones on simple tasks but fall significantly behind as complexity increases. The SALE routing system consistently outperforms single agents and alternative routers by dynamically assigning tasks to the most cost-effective agent without sacrificing accuracy, achieving better performance-cost trade-offs across all complexity levels. This advantage stems from strategy-based bidding, jury evaluation, and memory-driven refinement, which collectively enable more efficient resource allocation and gradual improvement in smaller agents’ competitiveness over time.
The authors evaluate the impact of removing self-feedback or peer-feedback from the SALE routing system, finding that both feedback types contribute meaningfully to performance. Without peer-feedback, pass@1 drops sharply, especially on complex tasks, while removing self-feedback leads to lower costs but reduced accuracy, indicating that peer-judgment provides essential external calibration for harder problems. Overall, the system performs best when both feedback mechanisms are active, highlighting their complementary roles in balancing accuracy and efficiency.