Command Palette
Search for a command to run...
WAXAL: مُجَمَّعُ كَلِمَاتٍ نَطْقِيَّةٍ لِلُّغَاتِ الْأَفْرِيْقِيَّةِ مُتَعَدِّدَةِ اللُّغَاتِ بِحَجْمٍ ضَخْمٍ
WAXAL: مُجَمَّعُ كَلِمَاتٍ نَطْقِيَّةٍ لِلُّغَاتِ الْأَفْرِيْقِيَّةِ مُتَعَدِّدَةِ اللُّغَاتِ بِحَجْمٍ ضَخْمٍ
الملخص
لقد أدى التقدم في تقنيات معالجة الكلام في الغالب إلى تفضيل اللغات عالية الموارد، مما خلق فجوة رقمية كبيرة أمام متحدثي معظم لغات أفريقيا جنوب الصحراء الكبرى. ولمعالجة هذه الفجوة، نقدم WAXAL، وهي مجموعة بيانات كلامية واسعة النطاق ومتاحة للجميع، تغطي 24 لغة تمثل أكثر من 100 مليون متحدث. تتكون المجموعة من مكونين رئيسيين: مجموعة بيانات للتعرف الآلي على الكلام (ASR) تضم ما يقرب من 1,250 ساعة من الكلام الطبيعي المُ transcribed (المُعرَّف نصيًا) من مجموعة متنوعة من المتكلمين، ومجموعة بيانات لتحويل النص إلى كلام (TTS) تضم أكثر من 235 ساعة من التسجيلات عالية الجودة لمتكلم واحد يقرأ نصوصًا متوازنة صوتيًا. توضح هذه الورقة منهجيتنا في جمع البيانات، والتعليق عليها، ومراقبة الجودة، والتي شملت شراكات مع أربع منظمات أكاديمية ومجتمعية أفريقية. ونقدم نظرة إحصائية مفصلة حول مجموعة البيانات، مع مناقشة محدودياتها المحتملة والاعتبارات الأخلاقية المرتبطة بها. وقد تم إصدار مجموعتي بيانات WAXAL عبر الرابط https://huggingface.co/datasets/google/WaxalNLP بموجب ترخيص CC-BY-4.0 المرن، بهدف تحفيز البحث، وتمكين تطوير تقنيات شاملة، وتوفير مورد حيوي للحفاظ الرقمي على هذه اللغات.
One-sentence Summary
To address the significant digital divide for Sub-Saharan African languages, WAXAL provides a large-scale, openly accessible speech corpus of 24 languages representing over 100 million speakers, consisting of approximately 1,250 hours of transcribed natural speech for Automated Speech Recognition and over 235 hours of high-quality single-speaker recordings reading phonetically balanced scripts for Text-to-Speech, developed in partnership with four African academic and community organizations and released under a CC-BY-4.0 license to catalyze research, enable inclusive technology development, and support digital preservation.
Key Contributions
- We introduce WAXAL, a large-scale speech dataset for 24 Sub-Saharan African languages representing over 100 million speakers. The collection comprises an Automated Speech Recognition (ASR) dataset with approximately 1,250 hours of transcribed natural speech and a Text-to-Speech (TTS) dataset with over 235 hours of high-quality recordings.
- We detail a methodology for data collection, annotation, and quality control established through partnerships with four African academic and community organizations. This process supports the inclusion of diverse speakers and maintains quality control standards for the resulting speech resources.
- The datasets are released at https://huggingface.co/datasets/google/WaxalNLP under a permissive CC-BY-4.0 license to catalyze research and enable the development of inclusive technologies. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations.
Introduction
Automatic speech recognition systems often lack sufficient training data for African languages, which limits technological accessibility and inclusivity in these regions. Existing datasets frequently do not offer the scale or multilingual diversity required for robust model performance across the continent. The authors introduce WAXAL, a large-scale multilingual African language speech corpus designed to address this resource gap. They also emphasize that releasing any large-scale human data requires careful consideration of its limitations and ethical implications.
Dataset
-
Dataset Composition and Sources
- The authors present WAXAL, a large-scale speech dataset covering 24 Sub-Saharan African languages spoken by over 100 million people.
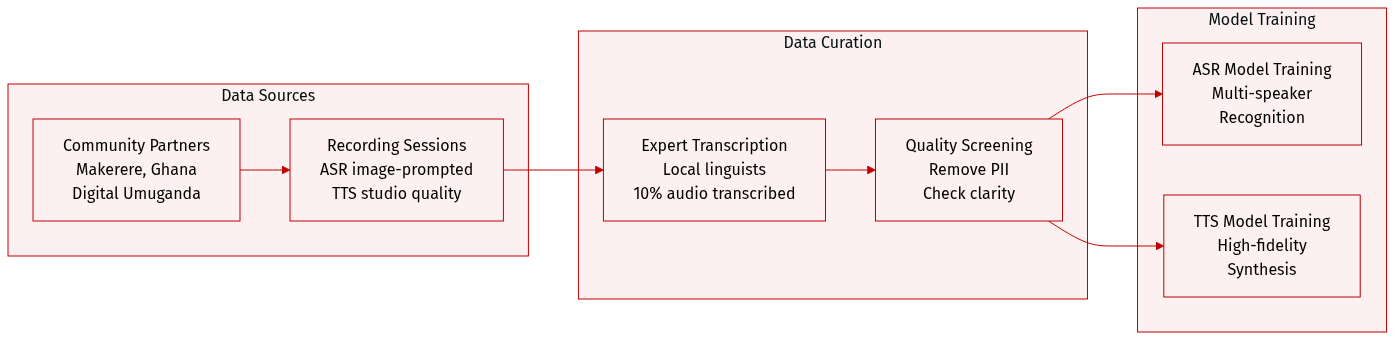
- Collection efforts were conducted in partnership with four African academic and community organizations, such as Makerere University and the University of Ghana.
- The entire collection is released under a CC-BY-4.0 license to encourage academic and commercial research.
-
Key Details for Each Subset
- ASR Subset: Includes approximately 1,250 hours of transcribed natural speech across 14 languages. Recordings were image-prompted to capture spontaneous speech with a minimum duration of 15 seconds.
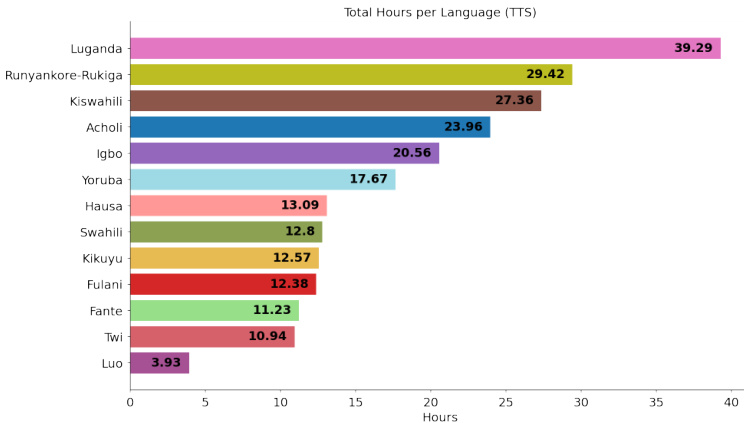
- TTS Subset: Comprises over 180 hours of studio-quality recordings from 72 voice actors across 10 languages. Speakers read phonetically balanced scripts in professional environments.
- File Statistics: The released ASR data occupies 1.7 TB, while the TTS data totals 99 GB.
-
Data Usage and Processing
- Intended Use: The ASR data is suitable for training and evaluating multi-speaker recognition models, whereas the TTS data is designed for high-fidelity voice synthesis.
- Annotation Strategy: Transcriptions were created by local linguistic experts using local scripts or English transliteration. Only 10% of the total collected audio was transcribed for the release.
- Metadata Construction: The dataset includes speaker demographics such as age, gender, and recording environment (e.g., indoor, outdoor).
- Quality Control: The authors removed personally identifiable information and screened audio for clarity, language accuracy, and appropriate content.