Command Palette
Search for a command to run...
MemSkill: تعلّم وتطور المهارات الذاكرةية للوكلاء الذاتية التطوّر
MemSkill: تعلّم وتطور المهارات الذاكرةية للوكلاء الذاتية التطوّر
Haozhen Zhang Quanyu Long Jianzhu Bao Tao Feng Weizhi Zhang Haodong Yue Wenya Wang
الملخص
تستند معظم أنظمة الذاكرة الخاصة بالنموذج اللغوي الكبير (LLM) على مجموعة صغيرة من العمليات الثابتة واليتم تصميمها يدويًا لاستخراج الذاكرة. تُدمج هذه الإجراءات الثابتة معرفة بشرية مسبقة حول ما يجب تخزينه وكيفية تحديث الذاكرة، مما يجعلها قاسية التكيف مع أنماط تفاعل متنوعة وغير فعالة عند التعامل مع سجلات طويلة. ولحل هذه المشكلة، نقدم "MemSkill"، الذي يعيد صياغة هذه العمليات على أنها مهارات ذاكرة قابلة للتعلم وقابلة للتطور، أي إجراءات منظمة قابلة لإعادة الاستخدام لاستخراج المعلومات وتوحيدها وحذفها من سجلات التفاعل. مستوحى من فلسفة تصميم المهارات الخاصة بالوكيل، يستخدم MemSkill مُتحكمًا يتعلم اختيار مجموعة صغيرة من المهارات ذات الصلة، مدعومًا بـ "مُنفّذ مبني على نموذج لغوي كبير" (LLM) يُنتج ذاكرة موجهة بالمهارات. وبالإضافة إلى تعلّم اختيار المهارات، يقدّم MemSkill مُصممًا يراجع دوريًا الحالات الصعبة التي تؤدي فيها المهارات المختارة إلى ذاكرة غير صحيحة أو غير كاملة، ويُطوّر مجموعة المهارات من خلال اقتراح تحسينات ومهارات جديدة. وبشكل متكامل، يشكّل MemSkill عملية مغلقة تُحسّن كلاً من سياسة اختيار المهارات وبنية المهارات نفسها. أظهرت التجارب على مجموعات بيانات LoCoMo وLongMemEval وHotpotQA وALFWorld تحسنًا في أداء المهام مقارنةً بالأساليب القوية، مع قدرة عالية على التعميم عبر السياقات المختلفة. كما ساهمت التحليلات الإضافية في كشف كيفية تطور المهارات، مقدمة رؤى نحو إدارة ذاكرة أكثر مرونة وذاتية التطور للوكالات القائمة على النماذج اللغوية الكبيرة.
One-sentence Summary
Haozhen Zhang et al. propose MemSkill, a self-evolving memory system for LLM agents that learns reusable memory skills via a controller-executor-designer loop, outperforming static methods on long-horizon tasks by dynamically refining skills based on failure cases, enabling more adaptive memory management.
Key Contributions
- MemSkill redefines static memory operations as learnable, reusable skills for extracting and revising memories from interaction traces, enabling flexible, span-level memory construction conditioned on selected skills rather than fixed turn-based heuristics.
- It introduces a closed-loop system where a reinforcement learning controller selects skills and an LLM-based designer evolves the skill bank by analyzing failure cases, allowing continual improvement of both skill selection and the skill set itself.
- Evaluated on LoCoMo, LongMemEval, HotpotQA, and ALF-World, MemSkill outperforms strong baselines and generalizes across tasks, demonstrating the effectiveness of its self-evolving memory framework for LLM agents.
Introduction
The authors leverage the idea that LLM agent memory should not rely on rigid, hand-crafted operations but instead be built from learnable, reusable memory skills—structured routines for extracting, consolidating, and pruning interaction traces. Prior methods suffer from hardcoded heuristics that scale poorly with long or diverse histories and fail to adapt to shifting task demands. MemSkill introduces a closed-loop system: a controller selects relevant skills from a shared bank, an LLM executor generates skill-guided memories in one pass, and a designer iteratively refines or adds skills based on hard cases, improving both selection policy and skill quality over time. This approach enables more adaptive, scalable memory management across benchmarks like LoCoMo and ALF-World, moving toward self-evolving agents that learn not just how to use memory, but how to improve how memory is built.
Dataset
-
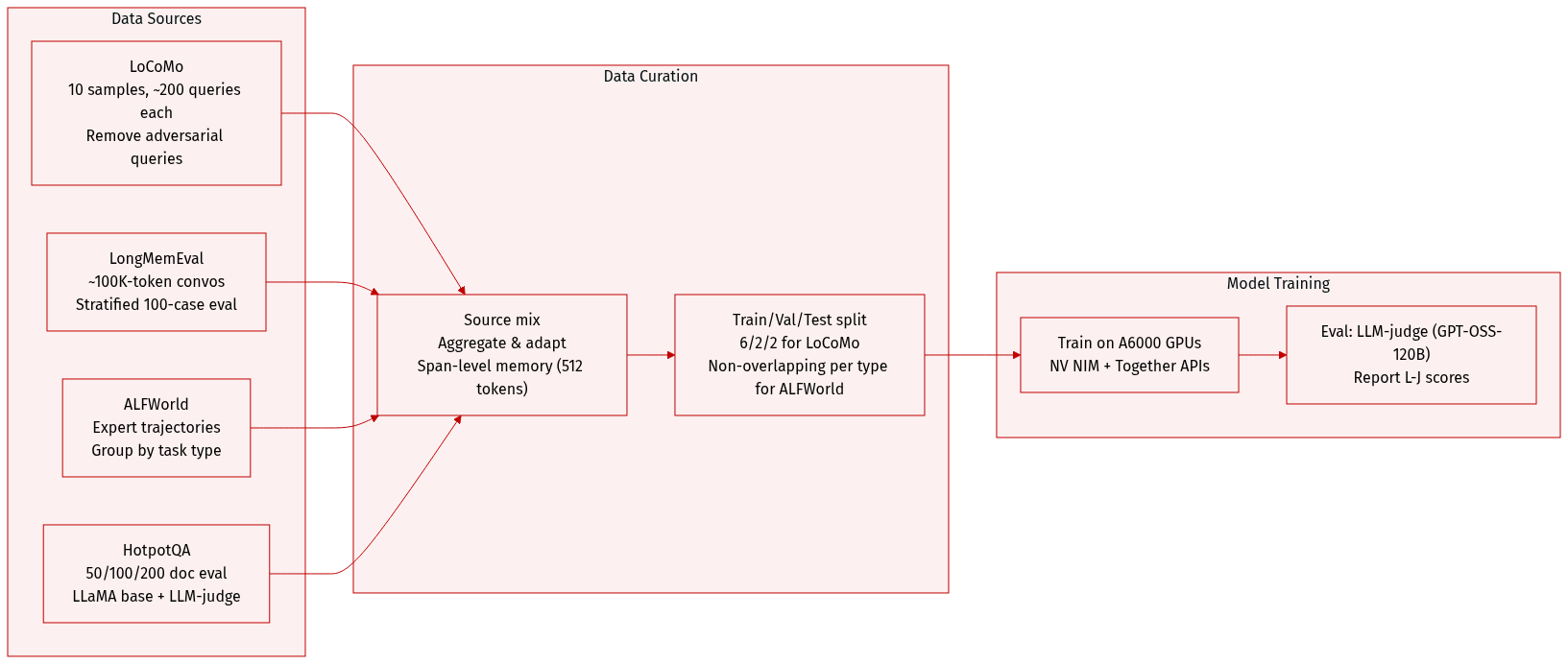
The authors use multiple datasets to train and evaluate MemSkill, including LoCoMo, LongMemEval, ALFWorld, and HotpotQA, each adapted to test long-context reasoning, memory construction, and transfer under distribution shifts.
-
LoCoMo: Contains 10 long interaction samples, each with ~200 training queries. Split 6/2/2 for train/val/test by sample. Adversarial queries are removed to avoid noisy supervision from missing evidence.
-
LongMemEval: Uses the LongMemEval-S split with ultra-long conversations (~100K tokens each). For evaluation, a stratified sample of ~100 cases (one-fifth of the dataset) is used to cover diverse question types.
-
ALFWorld: Converted into an offline protocol using expert trajectories from the training split. Trajectories are grouped by task type (e.g., PICK & PLACE, CLEAN & PLACE) to build type-specific memory banks. For each type, non-overlapping trajectory subsets are used: one for memory construction (experience corpus), another for evaluation. This enforces generalization within task templates.
-
HotpotQA: Used to study transfer under distribution shift. Evaluated under three context-length settings: 50, 100, and 200 concatenated documents (eval_50, eval_100, eval_200). LLaMA is used as the base model; results report LLM-judge scores.
-
Processing: Memory is constructed at the span level (default 512 tokens) during evaluation to reduce LLM calls and improve efficiency. Training uses NVIDIA A6000 GPUs; models are accessed via NV NIM and Together APIs; GPT-OSS-120B serves as the LLM judge.
Method
The authors leverage MemSkill, a framework that optimizes agent memory through two intertwined processes: learning to use a skill bank and evolving that bank based on hard cases. The architecture disentangles trace-specific memories from reusable memory management knowledge by maintaining two distinct stores. The memory bank is trace-specific and stores memories constructed for each training trace, such as a long dialogue. In contrast, the skill bank is shared across all traces and contains reusable memory skills. During training, the controller and executor interact with each trace to build its memory bank, while the designer updates the shared skill bank between phases. This alternating procedure gradually improves both the skill selection policy and the skill bank for memory construction.
As shown in the framework diagram, MemSkill processes interaction traces span by span. The controller selects a Top-K subset of skills from the shared skill bank conditioned on the current text span and retrieved memories. An LLM executor then applies the selected skills in one pass to update the trace-specific memory bank. The constructed memory is evaluated on memory-dependent training queries to provide task reward for optimizing the controller, while query-centric failures are logged into a sliding hard-case buffer. Periodically, the designer mines representative hard cases to refine existing skills and propose new ones, yielding alternating phases of skill usage and skill evolution.

The skill bank is initialized with four basic primitives: INSERT, UPDATE, DELETE, and SKIP. Each skill s∈S contains a short description for representation and selection, and a detailed content specification that instructs the executor on how to perform memory extraction or revision. The designer progressively refines existing skills and expands the bank by proposing new skills that address uncovered failure modes.
The controller selects a small set of relevant memory skills for the current context at each memory construction step. The authors split each interaction trace into contiguous text spans and process them sequentially. For each span, the controller conditions its selection on the current text span and the retrieved existing memories. To remain compatible with a variable-size skill bank, the controller scores each skill by measuring the semantic distance between the current state representation and the skill representation. The state embedding is computed as ht=fctx(xt,Mt), where xt is the current text span and Mt is the retrieved memories. The skill embedding is computed as νi=fskill(desc(si)) from the skill description. The controller scores each skill via zt,i=ht⊤ui, and the probability distribution is pθ(i∣ht)=softmax(zt)i. The controller selects an ordered Top-K set of skills At=(at,1,…,at,K) without replacement, for example via Gumbel-Top-K sampling, and passes only the selected skills to the executor.
The executor, a fixed LLM, constructs memory updates by conditioning on the current text span, the retrieved memory items, and the selected skills. This mirrors skill-conditioned inference in agent systems, where a small set of relevant skills guides behavior for the current context. The executor produces memory updates in a structured format, which are parsed and applied to update the trace's memory bank. By composing several skills for the same text span and extracting memory in one LLM call, MemSkill reduces repeated per-turn processing and scales to long interaction histories.
The controller is trained with reinforcement learning, using downstream task performance as feedback for its skill selections. For each training trace, the controller makes a sequence of Top-K selections while the executor incrementally builds the trace-specific memory bank. After construction, the resulting memory bank is evaluated on the trace's memory-dependent training queries, and the task performance (e.g., F1 or success rate) is used as the reward. The joint log-probability of the Top-K selection without replacement is computed as πθ(At∣st)=∏j=1K1−∑ℓ<jpθ(at,ℓ∣st)pθ(at,j∣st). The authors optimize the controller using proximal policy optimization (PPO), replacing the standard single-action log-probability with the Top-K joint log-probability. They also learn a value function and include an entropy bonus for exploration.
Beyond learning to select from a fixed set of skills, MemSkill evolves the skill bank using an LLM-based designer that operates periodically during training. The designer maintains a sliding-window buffer of challenging cases observed recently. Each case is query-centric, recording the query, ground-truth, metadata, and summary statistics. The buffer uses expiration rules to track recent failure patterns without growing unbounded. To focus updates on impactful failures, the designer clusters cases into groups reflecting different query or error types and prioritizes representative cases using a difficulty score that increases with low task performance and repeated failures. The designer updates the skill bank in two stages: first, it analyzes the selected hard cases to identify missing or mis-specified memory behaviors; second, it proposes concrete edits to existing skills and introduces new skills. The authors maintain snapshots of the best-performing skill bank and roll back if an update degrades performance, with early stopping when repeated updates fail to improve the training signal. After each evolution step, they bias selection toward newly introduced skills to encourage the controller to try them.
MemSkill alternates between learning to select and apply skills to build memory banks and evolving the skill bank based on hard cases mined from recent training steps. Each cycle begins with controller training on the current skill bank, during which the executor constructs memories and the system accumulates challenging cases. The designer then updates the skill bank using representative hard cases, optionally rolling back to a prior snapshot if the update regresses. The next cycle resumes controller training on the updated skill bank, with additional exploration to encourage early use of new skills. Through repeated cycles, MemSkill progressively improves both skill usage and the skill bank available for memory construction.
Experiment
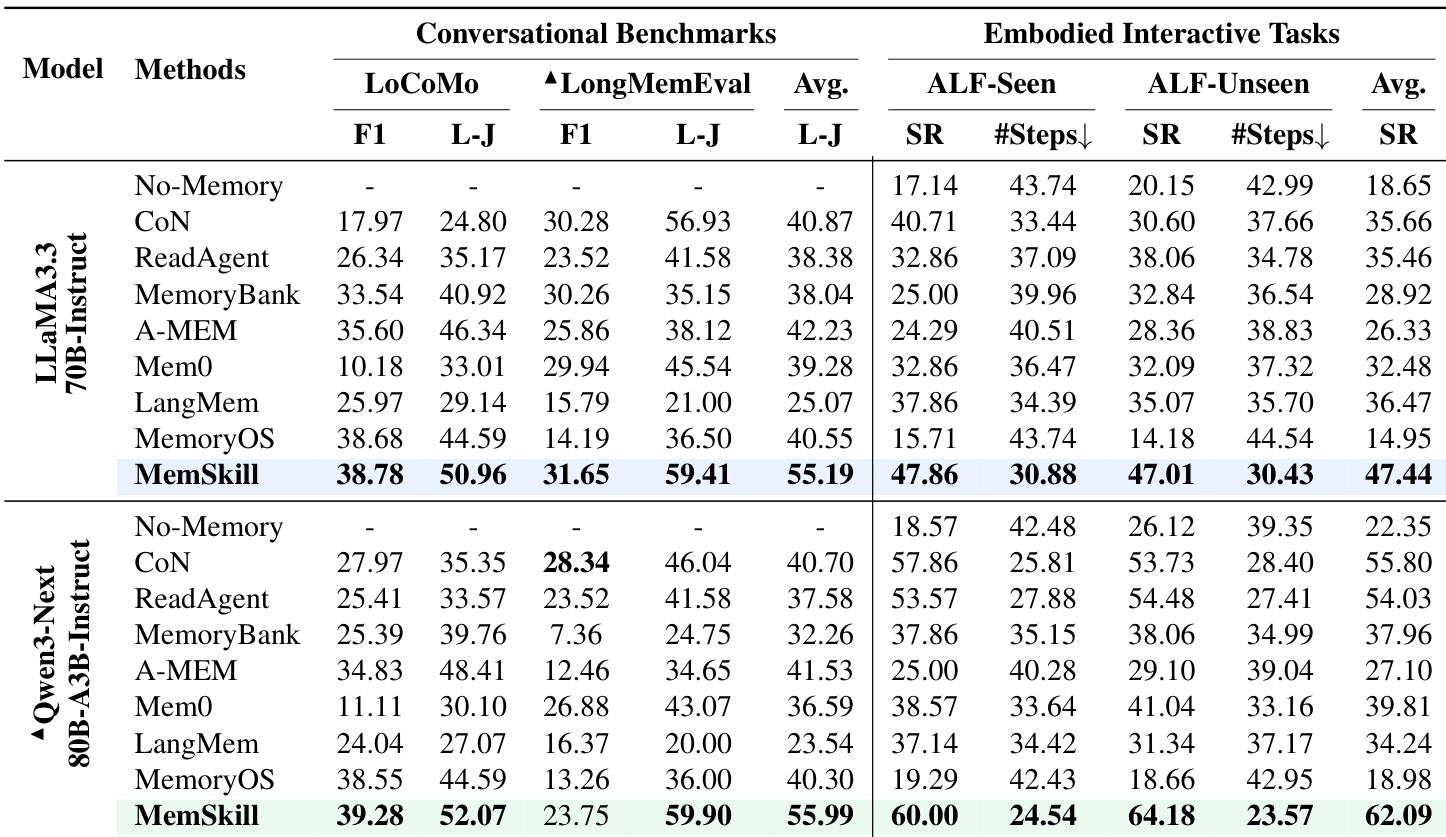
- MemSkill outperforms multiple strong baselines across conversational (LoCoMo, LongMemEval) and embodied (ALFWorld) benchmarks, demonstrating superior memory construction and decision-making capabilities.
- It generalizes effectively across different base LLMs (LLaMA to Qwen) without retraining, indicating learned skills capture reusable memory behaviors.
- Skills transfer successfully across datasets within the same setting (LoCoMo to LongMemEval) and under significant distribution shifts (LoCoMo to HotpotQA), maintaining strong performance despite differing input formats and context lengths.
- Ablation studies confirm that both the learned controller (for skill selection) and the skill designer (for evolution) are critical, with skill evolution contributing more significantly to performance, especially under new models or contexts.
- Evolved skills are domain-adapted: conversational tasks prioritize temporal and activity structure, while embodied tasks focus on action constraints and object states, reflecting task-specific memory needs.
- Performance improves with more selected skills in longer, noisier contexts, showing MemSkill benefits from compositional skill use without task-specific tuning.
The authors evaluate MemSkill’s core components through ablation, showing that both the learned controller for skill selection and the designer for skill evolution contribute significantly to performance. Removing either component degrades results, with static skills causing the largest drop—especially under Qwen—indicating that evolving the skill bank is critical for generalization. Refining existing skills helps but falls short of the full system, confirming that introducing new skills adds further value beyond mere refinement.

MemSkill consistently outperforms all compared methods across both conversational and embodied interactive tasks, achieving the highest scores in memory quality and task success rates under multiple base models. The method demonstrates strong generalization, maintaining superior performance when transferring learned skills across different datasets and base LLMs without retraining. Results confirm that its adaptive skill selection and evolution mechanism enables more effective memory construction than fixed or manually designed approaches.