Command Palette
Search for a command to run...
AdaReasoner: التنسيق الديناميكي للأدوات للاستدلال البصري التكراري
AdaReasoner: التنسيق الديناميكي للأدوات للاستدلال البصري التكراري
Mingyang Song Haoyu Sun Jiawei Gu Linjie Li Luxin Xu Ranjay Krishna Yu Cheng
الملخص
عندما يواجه البشر مشكلات تتجاوز قدراتهم الفورية، فإنهم يعتمدون على الأدوات، مما يُعد نموذجًا واعدًا لتحسين التفكير البصري في النماذج الكبيرة متعددة الوسائط للغة (MLLMs). وبالتالي، يعتمد التفكير الفعّال على معرفة الأدوات المناسبة للاستخدام، ومتى يجب استدعاؤها، وكيفية توليفها عبر خطوات متعددة، حتى عند مواجهة أدوات جديدة أو مهام جديدة. نقدّم AdaReasoner، وهي عائلة من النماذج متعددة الوسائط تتعلم استخدام الأدوات كمهارة تفكير عامة، بدلًا من اعتبارها سلوكًا مخصصًا لأداة معينة أو مُدرّبًا صراحةً عليها. يتم تمكين AdaReasoner من خلال (أ) خط أنابيب مُحكَم لجمع البيانات قابل للتوسع، يعرّض النماذج لتفاعلات أدوات متعددة الخطوات وطويلة المدى؛ (ب) خوارزمية التعلم بالتعزيز Tool-GRPO، التي تُحسّن اختيار الأدوات وتسلسلها بناءً على نجاح المهمة النهائية؛ و(ج) آلية تعلّم مُتكيفة تُنظّم استخدام الأدوات ديناميكيًا. تُمكّن هذه المكونات معًا النماذج من استخلاص فائدة الأدوات من السياق المهمة والنتائج الوسيطة، مما يتيح تنسيق استخدام عدة أدوات والتميّز في التعميم على أدوات لم تُرَ من قبل. من الناحية التجريبية، تُظهر AdaReasoner سلوكًا قويًا في التكيّف مع الأدوات والتميّز في التعميم: فهي تُستخدم بشكل مستقل أدوات مفيدة، وتُقلّل من استخدام تلك غير ذات صلة، وتكيف تكرار استخدام الأدوات وفقًا لاحتياجات المهمة، رغم أن النموذج لم يُدرّس صراحةً على هذه السلوكيات. تترجم هذه القدرات إلى أداءٍ من الطراز الرائد عبر معايير صعبة، حيث تُحسّن النموذج الأساسي بحجم 7 بيليون معامل بمتوسط +24.9٪، وتفوق أنظمة قوية مُلكية مثل GPT-5 في عدة مهام، بما في ذلك VSP وJigsaw.
One-sentence Summary
Researchers from Fudan, Tongji, NUS, UW, and UESTC propose AdaReasoner, a multimodal model that autonomously learns tool use via scalable data, Tool-GRPO reinforcement learning, and adaptive regulation, enabling generalization to unseen tools and outperforming GPT-5 on VSP and Jigsaw benchmarks.
Key Contributions
- AdaReasoner introduces a scalable data pipeline and Tool-GRPO reinforcement learning algorithm to train multimodal models on long-horizon, multi-step tool interactions, enabling them to autonomously select, sequence, and adapt tool usage based on task context and intermediate outcomes.
- The model incorporates an adaptive learning mechanism that decouples tool-use logic from specific tasks, allowing generalization to unseen tools and novel task distributions without explicit supervision or predefined invocation patterns.
- Evaluated on challenging benchmarks, AdaReasoner improves a 7B base model by +24.9% on average and outperforms proprietary systems like GPT-5 and Claude Sonnet 4 on tasks such as VSP and Jigsaw, demonstrating robust tool-adaptive reasoning in open-source multimodal models.
Introduction
The authors leverage external tools to enhance visual reasoning in multimodal large language models, recognizing that human-like problem solving often requires dynamic tool selection and multi-step coordination. Prior approaches either relied on rigid, pre-defined tool invocation patterns or were limited to single-tool use, failing to adapt to unseen tools or novel tasks. AdaReasoner addresses this by introducing a scalable data pipeline for long-horizon tool interactions, a reinforcement learning algorithm (Tool-GRPO) that optimizes tool sequencing based on task outcomes, and an adaptive learning mechanism that decouples tool logic from specific tasks. This enables the model to autonomously select, suppress, and modulate tools based on context and feedback, achieving state-of-the-art performance—even outperforming proprietary models like GPT-5—while generalizing to unseen tools and tasks.
Dataset

The authors use a curated dataset of high-fidelity, tool-augmented reasoning trajectories across three tasks: VSP, Jigsaw, and GUIQA. Each trajectory follows a structured, human-like problem-solving blueprint and includes reflection, backtracking, and tool failure cases to promote robustness.
-
VSP (Navigation & Verification):
- Source: Procedurally generated environments using Gymnasium, with training grids sized 4x4, 6x6, 8x8; test grids 5x5, 7x7, 9x9.
- Trajectory: Uses POINT to locate start/end/obstacles, textual reasoning, and DRAW2DPATH for path verification. Includes failure cases with self-correction.
- Processing: Tool calls executed programmatically; CoT generated via Gemini 2.5 Flash.
-
Jigsaw:
- Source: Images from COCO-2017 training set, split into 3x3 grids; one patch removed as target, one of five others as distractor.
- Trajectory: DETECTBLACKAREA to locate missing region, then iterative INSERTIMAGE attempts with visual feedback.
- Variations: Randomized patch order, tool failure cases, and tool-free solvable instances to encourage adaptive tool use.
-
GUIQA:
- Source: Filtered from 44k Guichat instances using Qwen-VL-2.5-72B; retained 7,100 where model failed.
- Processing: Manual inspection reduced to 1,800 valid cases; ground-truth answer coordinates rendered as bounding boxes.
- Trajectory: CROP to isolate relevant region, then OCR for extraction. CoT and tool sequence generated via Gemini 2.5 Flash; final dataset: 1,139 validated instances.
All trajectories are built via a two-stage pipeline: (1) programmatic tool execution to populate inputs/outputs, (2) LLM-generated CoT reasoning. The final dataset supports supervised fine-tuning (TC stage) and is designed to teach not just tool use, but strategic reasoning between steps, including fallback behavior during tool failure.
Method
The authors leverage a multi-stage training framework to develop AdaReasoner, a multimodal large language model (MLLM) capable of effective tool-augmented reasoning. The overall architecture is designed around a sequential decision-making process where the model, represented as a policy πθ, generates a reasoning trajectory τ to solve a problem. This trajectory is a sequence of state-action-observation tuples, where the state st represents the current problem context, the action at is a tool call encapsulated by special tokens, and the observation ot is the result from the tool's execution. The policy transitions from state st to st+1 based on the new information. The framework is built upon a diverse suite of visual tools categorized into perception (e.g., POINT, OCR), manipulation (e.g., DRAWLINE, INSERTIMAGE), and calculation (e.g., AStar), which are integrated into the reasoning process. The training process consists of two primary stages: a cold-start stage (TC) and a reinforcement learning stage (TG).
The first stage, Tool Cold Start (TC), is a supervised fine-tuning (SFT) phase. It begins with the generation of high-quality training data using the AdaDataCuration module, which leverages a Tool Server to execute tool calls and integrate results into a coherent dialogue. This stage uses a dataset derived from tasks like VSP, Jigsaw, and WebQA. The model is trained to generate multi-turn trajectories that follow a specific structure: a thinking phase enclosed in <think> tags, followed by either a tool call enclosed in <tool_Call> tags or a final response in <response> tags. The training data includes abstract problem-solving blueprints with chain-of-thought (CoT) placeholders, which are filled by a large language model to create detailed reasoning steps. The model learns to correctly format its output and execute the initial steps of the reasoning process.
The second stage, Tool-GRPO (TG), is a reinforcement learning phase that refines the model's ability to plan and execute complex, multi-turn tool sequences. This stage employs a Group Relative Policy Optimization (GRPO) algorithm. The policy πθ samples a group of N candidate trajectories for a given problem. Each trajectory is evaluated by a reward function, and a group-relative advantage is calculated for each trajectory by normalizing its reward against the group's mean and standard deviation. The policy is then updated to favor trajectories with higher relative advantages, using a clipped surrogate objective function that includes a Kullback-Leibler (KL) divergence penalty to ensure stable updates. The reward function is designed to be multi-faceted, with a total reward Rtotal that is a composite of a format reward, a tool reward, and an accuracy reward. The format reward acts as a binary gate, ensuring that rewards for tool usage and final answer accuracy are only granted if the output adheres to the required structural syntax. The tool reward provides a fine-grained evaluation of the tool-calling process, with a hierarchical scoring system from 0 to 4 based on the correctness of the invocation structure, tool name, parameter names, and parameter content. The accuracy reward is granted only if the final answer is correct.
To enhance the model's generalization capabilities, the authors introduce an Adaptive Learning strategy that is applied during both the TC and TG stages. This strategy randomizes tool definitions at two levels. At the token level, functional identifiers such as tool names and argument names are replaced with random alphanumeric strings (e.g., "GetWeather" becomes "Func_X7a2"), forcing the model to rely on the semantic descriptions rather than the identifiers themselves. At the semantic level, the descriptions of tools and arguments are paraphrased using a large language model to create diverse phrasings while preserving the original functional meaning. This prevents the model from overfitting to specific identifiers or phrasings and encourages robustness to variations in tool documentation. The effectiveness of this approach is demonstrated in evaluations where the model trained with randomized definitions shows significant improvements in generalizing to new tasks and new tools, outperforming models trained with standard definitions. The overall framework, AdaReasoner, is an end-to-end system that orchestrates the entire life-cycle of the model, from data curation to evaluation, with a central Tool Server managing all available tools.
Experiment
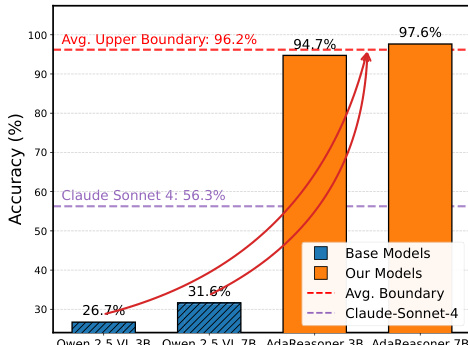
- Evaluated on VSP, Jigsaw, GUIQA, and Visual Search tasks using Qwen2.5-VL-3B/7B; tool augmentation (TC + TG) boosted 7B model by +38.66% avg, lifting VSP from ~31.64% to 97.64%, surpassing Direct SFT (46.64%) and Direct GRPO (30.18%).
- Achieved state-of-the-art on VSP (97.64%) and Jigsaw (96.60%), outperforming GPT-5 (80.10%) and closing gap between 3B/7B models—both reached ~95%+ accuracy, showing tools overcome scale limitations.
- AdaReasoner learns adaptive tool use: adopts A* for navigation (96.33% score), suppresses irrelevant tools (verification stays 99.20%), and modulates call frequency (e.g., Point tool: 3.2 calls/sample for navigation, ~1.0 for verification).
- Generalizes to unseen tools and tasks: on Jigsaw, achieved 88.60% accuracy with 3.54 CPS and 98.50% success; on VStar (no tool supervision), invoked tools 1.47 times/sample and scored 70.68%, outperforming baselines under zero-shot tool adaptation.
- Outperformed proprietary models (GPT-5, Claude, Gemini) and large open-source models (Qwen-32B/72B) on structured tasks; on WebMMU’s agent action subset, achieved 72.97% with pure GRPO, showing SFT can hinder open-ended domains.
The authors use a tool-augmented approach to enhance the performance of multimodal models on visual reasoning tasks, demonstrating that their method achieves near-perfect accuracy (97.6%) on the VSP benchmark, significantly surpassing the baseline models and even outperforming larger proprietary models like GPT-5. Results show that tool augmentation effectively overcomes scale-based limitations, enabling smaller models to reach performance levels comparable to much larger ones by shifting the bottleneck from internal reasoning to effective tool planning.
The authors use the Qwen2.5-VL-7B-Instruct model with a frozen vision tower and full finetuning, training on 332,649 samples with a maximum sequence length of 35,536 and 64 preprocessing workers. The model is trained for 3 epochs using a cosine learning rate scheduler with a warmup ratio of 0.1, a mixed precision of bfloat16, and a batch size of 1 per device, with logging and checkpoint saving every 10 and 100 steps respectively, and evaluated on a 90%/10% train/validation split with a validation batch size of 1.
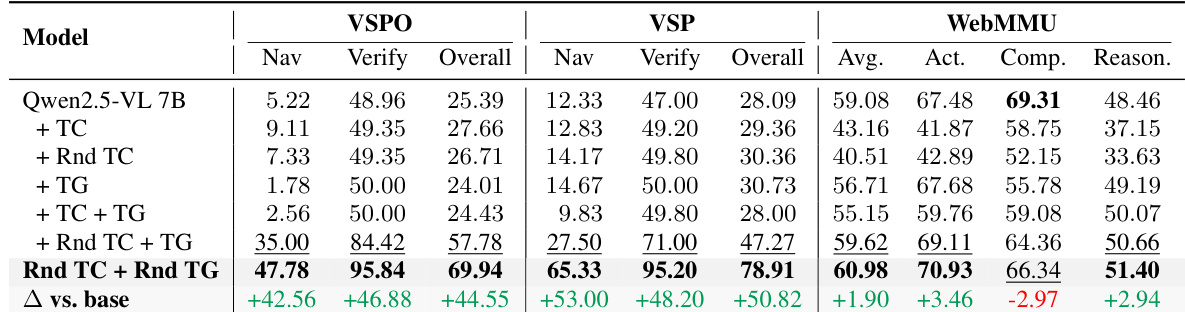
The authors use a combination of tool cold-start (TC) and tool-GRPO (TG) training to enhance model performance on visual reasoning tasks. Results show that the Rnd TC + Rnd TG method achieves the highest scores across all benchmarks, with significant improvements over the base model, particularly in VSP and WebMMU, where it outperforms other configurations by large margins.
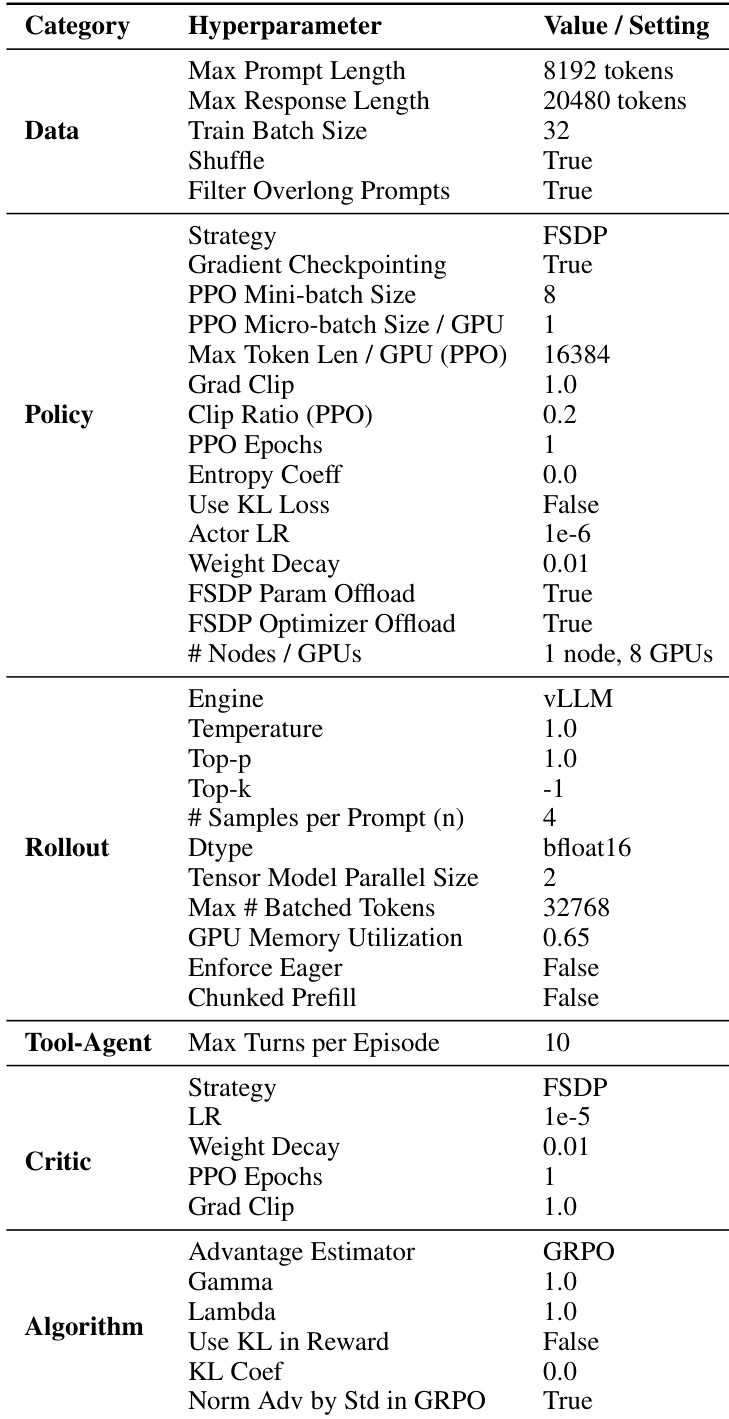
The authors use a comprehensive set of hyperparameters to train their model, with key settings including a maximum prompt length of 8192 tokens, a train batch size of 32, and a PPO micro-batch size of 16384 per GPU. The training employs a vLLM engine, FSDP for model parallelism, and a GRPO advantage estimator, with specific configurations for policy, rollout, and critic components to ensure stable and efficient reinforcement learning.
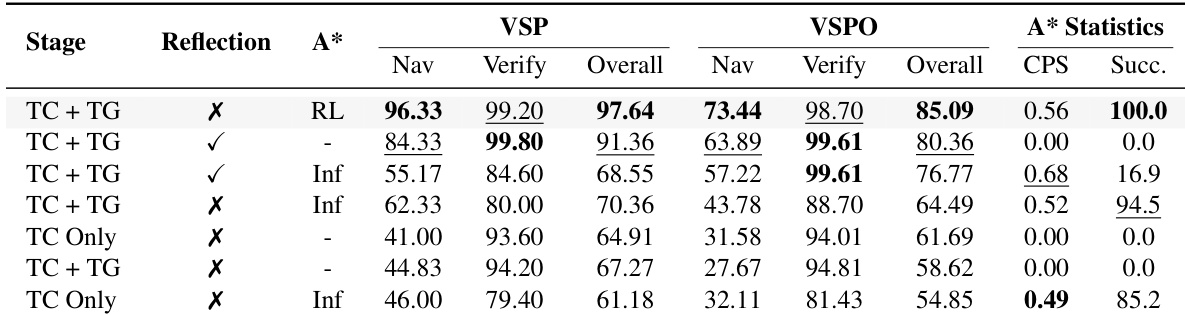
The authors use a controlled ablation study to evaluate the impact of reflection and tool availability on adaptive tool usage in the VSP task. Results show that enabling reflection during training significantly improves performance on both navigation and verification tasks, with the best results achieved when reflection is combined with A* availability at inference, leading to a 99.80% verification accuracy and a 96.33% navigation accuracy. The A* tool's effectiveness is highly dependent on its context, as its inclusion without reflection leads to unstable behavior and performance degradation, highlighting the importance of stable training signals for reliable tool adaptation.