Command Palette
Search for a command to run...
Memory-V2V: تعزيز نماذج التمايز من الفيديو إلى الفيديو باستخدام الذاكرة
Memory-V2V: تعزيز نماذج التمايز من الفيديو إلى الفيديو باستخدام الذاكرة
Dohun Lee Chun-Hao Paul Huang Xuelin Chen Jong Chul Ye Duygu Ceylan Hyeonho Jeong
الملخص
أظهرت النماذج الحديثة الأساسية لتحويل الفيديو إلى فيديو باستخدام التشتت (video-to-video diffusion) نتائج مبهرة في تعديل مقاطع الفيديو التي يوفرها المستخدم، من خلال تعديل المظهر أو الحركة أو حركة الكاميرا. ومع ذلك، فإن عملية تحرير الفيديو في العالم الحقيقي غالبًا ما تكون عملية تكرارية، حيث يقوم المستخدمون بتحسين النتائج عبر جولات متعددة من التفاعل. في هذا السياق متعدد الجولات، تواجه النماذج الحالية لتحرير الفيديو صعوبات في الحفاظ على الاتساق بين التحريرات المتتالية. في هذا العمل، نتناول، لأول مرة، مشكلة الاتساق عبر الجولات في تحرير الفيديو متعدد الجولات، ونقدم إطارًا يُسمى Memory-V2V، وهو إطار بسيط لكنه فعّال، يُضيف ذاكرة صريحة إلى النماذج الحالية لتحويل الفيديو إلى فيديو. معتمدًا على ذاكرة خارجية تحتوي على مقاطع فيديو تم تحريرها سابقًا، يستخدم Memory-V2V استراتيجيات دقيقّة للبحث واستراتيجيات تجزئة ديناميكية لتوجيه خطوة التحرير الحالية بناءً على النتائج السابقة. ولتقليل التكرار والحمل الحسابي الإضافي، نقترح مُضاعفًا قابلاً للتعلم داخل هيكل DiT، يقوم بضغط الرموز الشرطية الزائدة مع الحفاظ على الإشارات البصرية الأساسية، مما يحقق تسريعًا إجماليًا بنسبة 30٪. وقد تم التحقق من أداء Memory-V2V على مهام صعبة تشمل إنشاء مناظر جديدة للفيديو (video novel view synthesis) وتحرير الفيديو الطويل بشرط نصي. أظهرت التجارب الواسعة أن Memory-V2V ينتج مقاطع فيديو أكثر اتساقًا عبر الجولات بشكل ملحوظ، مع حمل حسابي ضئيل، مع الحفاظ على الأداء المخصص للمهام أو حتى تحسينه مقارنةً بالأساليب المتطورة الحالية. صفحة المشروع: https://dohunlee1.github.io/MemoryV2V
One-sentence Summary
Adobe Research and KAIST researchers propose Memory-V2V, a framework enhancing video-to-video diffusion models with explicit memory for iterative editing, using dynamic tokenization and a learnable compressor to maintain cross-consistency across edits while accelerating inference by 30% for tasks like novel view synthesis and long video editing.
Key Contributions
- Memory-V2V introduces the first framework for cross-consistent multi-turn video editing, addressing the real-world need for iterative refinement by augmenting diffusion models with explicit visual memory to preserve consistency across sequential edits.
- The method employs task-specific retrieval, dynamic tokenization, and a learnable token compressor within the DiT backbone to condition current edits on prior results while reducing computational overhead by 30% through adaptive compression of less relevant tokens.
- Evaluated on video novel view synthesis and text-guided long video editing, Memory-V2V outperforms state-of-the-art baselines in cross-iteration consistency and maintains or improves task-specific quality with minimal added cost.
Introduction
The authors leverage existing video-to-video diffusion models to address the real-world need for iterative video editing, where users refine outputs over multiple interactions. Prior methods fail to maintain cross-consistency across edits—whether synthesizing novel views or editing long videos—because they lack mechanisms to recall and align with previous generations. Memory-V2V introduces explicit visual memory by retrieving relevant past edits from an external cache, dynamically tokenizing them based on relevance, and compressing redundant tokens within the DiT backbone to reduce computation by 30% while preserving visual fidelity. This enables consistent, multi-turn editing without sacrificing speed or quality, advancing toward practical, memory-aware video tools.
Dataset

-
The authors construct a long-form video editing dataset by extending short clips from Señorita-2M, which provides 33-frame editing pairs with stable local edits. Each clip is extended by 200 frames using FramePack, yielding 233-frame sequences for training.
-
The extended 200 frames serve as memory during training. At each iteration, the model randomly samples segments from this extended portion to condition on past context, enabling long-horizon editing.
-
For positional encoding, they use RoPE with hierarchical temporal indexing: target frames get indices 0 to T−1, the immediately preceding segment gets T to 2T−1, and remaining memory segments get 2T to 3T−1. This preserves continuity with recent context while incorporating broader history.
-
To resolve the training-inference gap, they reverse the RoPE index order for memory frames during inference. This aligns the positional structure with training, ensuring consistency between how memory frames are indexed during training (chronological) and inference (reverse chronological).
-
The dataset enables efficient training of Memory-V2V, reducing FLOPs and latency by over 90% while scaling gracefully with memory video count.
Method
The Memory-V2V framework is designed to enable multi-turn video editing by maintaining cross-edit consistency through a hybrid retrieval and compression strategy. The overall architecture, as illustrated in the framework diagram, builds upon a pretrained video-to-video diffusion model, such as ReCamMaster for novel view synthesis or LucyEdit for text-guided editing, and introduces mechanisms to efficiently incorporate prior editing history. At each editing iteration, the model generates a new video conditioned on the current input and a set of relevant past videos retrieved from an external cache. This cache stores the latent representations of previously generated videos, indexed by their camera trajectories for novel view synthesis or by their source video segments for text-guided editing. The retrieval process ensures that only the most relevant historical videos are considered, mitigating the computational burden of conditioning on an ever-growing history.
The core of the framework lies in its dynamic tokenization and adaptive token merging components. For video novel view synthesis, relevance is determined by a VideoFOV retrieval algorithm that quantifies the geometric overlap between the field-of-view (FOV) of the target camera trajectory and those of the cached videos. This is achieved by sampling points on a unit sphere centered at the first camera position and determining visibility within the projected image bounds for each frame. The video-level FOV is the union of all frame-level FOVs, and two complementary similarity metrics—overlap and containment—are used to compute a final relevance score. The top-k most relevant videos are retrieved and dynamically tokenized using learnable tokenizers with varying spatio-temporal compression factors. Specifically, the user-input video is tokenized with a 1×2×2 kernel, the top-3 most relevant retrieved videos with a 1×4×4 kernel, and the remaining videos with a 1×8×8 kernel. This adaptive tokenization strategy allocates the token budget efficiently, preserving fine-grained details for the most relevant videos while managing the total token count.
To further enhance computational efficiency, the framework employs adaptive token merging. This strategy leverages the observation that DiT attention maps are inherently sparse, with only a small subset of tokens contributing meaningfully to the output. The responsiveness of each frame is estimated by computing its maximum attention response to the target queries. Frames with low responsiveness scores are identified as containing redundant information and are merged using a learnable convolutional operator. The merging is applied at specific points in the DiT architecture—Block 10 and Block 20—where responsiveness scores have stabilized, ensuring that essential context is preserved while reducing redundancy. This approach avoids the degradation that would result from completely discarding low-importance tokens.
For text-guided long video editing, the framework extends the multi-turn editing paradigm by reformulating the task as an iterative process. Given a long input video, it is divided into shorter segments that fit within the base model's temporal context. During the editing of each segment, the model retrieves the most relevant previously edited segments from the cache based on the similarity of their corresponding source video segments, using DINOv2 embeddings. The retrieved videos are then dynamically tokenized and processed with adaptive token merging. The edited segments are stitched together to form the final output video. This approach ensures consistency across the entire long-form video, as demonstrated by the ability to consistently add the same object or transform a specific element across all segments.
The framework also addresses the challenge of positional encoding during multi-turn editing. To prevent temporal drift and inconsistencies when generating videos longer than the training horizon or incorporating expanding conditioning sets, a hierarchical RoPE (Rotary Position Embedding) design is employed. The target, user-input, and memory videos are assigned disjoint ranges of temporal RoPE indices. A mixed training strategy, including Gaussian noise perturbation for memory tokens and RoPE dropout for user-input tokens, is used to ensure the model can correctly interpret and utilize this hierarchical structure during inference. Additionally, camera conditioning is made explicit by embedding camera trajectories on a per-video basis, allowing the model to handle heterogeneous viewpoints and improve viewpoint reasoning.
Experiment
- Evaluated context encoders for multi-turn novel view synthesis: Video VAE outperformed CUT3R and LVSM in preserving appearance consistency across generations; adopted for Memory-V2V.
- On 40 videos, Memory-V2V surpassed ReCamMaster (Ind/AR) and TrajectoryCrafter in cross-iteration consistency (MEt3R) and visual quality (VBench), maintaining camera accuracy and outperforming CUT3R/LVSM-based variants.
- On 50 long videos (Señorita), Memory-V2V beat LucyEdit (Ind/FIFO) in visual quality and cross-frame consistency (DINO/CLIP), enabling coherent edits over 200+ frames.
- Ablations confirmed dynamic tokenization + retrieval boosts long-term consistency (e.g., 1st–5th gen), while adaptive token merging cuts FLOPs/latency by 30% without quality loss; merging outperformed discarding in motion continuity.
- Dynamic tokenization reduced FLOPs/latency by >90% vs. uniform tokenization; adaptive merging added further 30% savings, keeping inference time comparable to single-video synthesis.
- Memory-V2V struggles with multi-shot videos due to scene transitions and accumulates artifacts from imperfect synthetic training extensions; future work includes multi-shot training and diffusion distillation integration.
Results show that cross-block consistency improves with increasing block distance, as indicated by higher Pearson correlation, Spearman correlation, and Bottom-k overlap values from Block 1 vs 2–30 to Block 21 vs 22–30. This suggests that the model maintains stronger semantic consistency across longer temporal intervals.

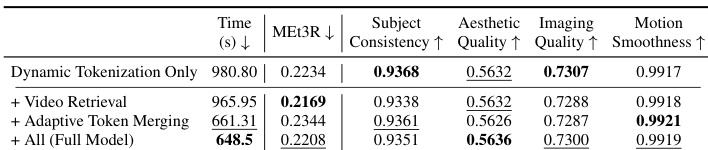
Results show that combining dynamic tokenization with video retrieval significantly improves subject consistency, while adding adaptive token merging further enhances this metric without degrading aesthetic or imaging quality. The full model, which includes all components, achieves the highest consistency and motion smoothness, demonstrating the effectiveness of the proposed memory management strategy.
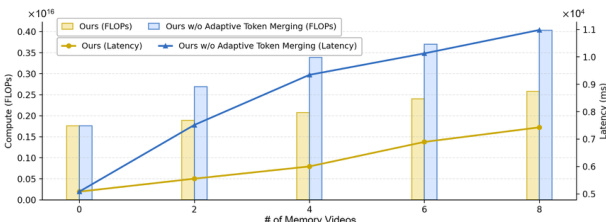
Results show that adaptive token merging significantly reduces computational cost, with the model achieving over 30% lower FLOPs and latency compared to the version without merging. The authors use this technique to maintain efficiency even when conditioning on a large number of memory videos, keeping inference time comparable to single-video synthesis.
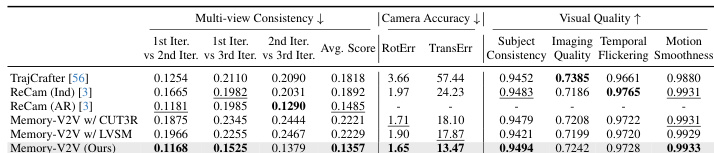
Results show that Memory-V2V consistently outperforms all baselines across multi-view consistency, camera accuracy, and visual quality metrics, with the best performance in cross-iteration consistency and visual fidelity. The model achieves superior results compared to ReCamMaster and TrajCrafter, particularly in maintaining consistency across multiple generations while preserving motion and appearance quality.
Results show that Memory-V2V outperforms both LucyEdit variants across all metrics, achieving the highest scores in background consistency, aesthetic quality, imaging quality, temporal flickering, and motion smoothness. It also demonstrates superior cross-frame consistency with higher DINO and CLIP similarity values, indicating more coherent and visually consistent long video editing.
