Command Palette
Search for a command to run...
التحليل الحركي لإنشاء الفيديو
التحليل الحركي لإنشاء الفيديو
Xindi Wu Despoina Paschalidou Jun Gao Antonio Torralba Laura Leal-Taixé Olga Russakovsky Sanja Fidler Jonathan Lorraine
الملخص
على الرغم من التقدم السريع في نماذج توليد الفيديو، لا يزال دور البيانات في التأثير على الحركة غير مفهوم بشكل جيد. نقدّم "موفي" (Motive)، وهي إطار عمل متمحور حول الحركة، قائم على التدرجات، يمكنه التوسع ليواكب المجموعات الكبيرة الحديثة عالية الجودة من بيانات الفيديو والنماذج. نستخدم هذا الإطار لدراسة أي مقاطع التدريب الدقيق (fine-tuning) تُحسّن أو تُضعف الديناميات الزمنية. يُعزل موفي الديناميات الزمنية عن المظهر الثابت من خلال أقنعة خسارة موزونة حسب الحركة، مما يُنتج حسابًا فعّالًا وقابلًا للتوسع لتأثير الحركة المحدّد. على نماذج التوليد من النص إلى الفيديو، يُحدد موفي المقاطع التي تؤثر بشكل قوي على الحركة، ويدل على عملية اختيار البيانات التي تُحسّن الاتساق الزمني والواقعية الفيزيائية. وباستخدام بيانات عالية التأثير تم اختيارها بواسطة موفي، يُحسّن نهجنا كلًا من سلاسة الحركة ودرجة الديناميكية على معيار VBench، ويحقق معدل رضا بشري بنسبة 74.1% مقارنةً بالنموذج الأساسي المُدرّب مسبقًا. إلى حد علمنا، فإن هذا هو الإطار الأول الذي يُسهم في تفسير تأثير الحركة بدلًا من المظهر البصري في نماذج توليد الفيديو، ويُستخدم لاختيار بيانات التدريب الدقيق.
One-sentence Summary
The authors from NVIDIA, Princeton University, and MIT CSAIL propose Motive, a motion-centric gradient-based attribution framework that isolates temporal dynamics from static appearance using motion-weighted loss masks, enabling scalable identification of influential fine-tuning clips to improve motion smoothness and physical plausibility in text-to-video generation, achieving a 74.1% human preference win rate on VBench.
Key Contributions
- Motive is the first framework to attribute motion rather than static appearance in video generation models, addressing the critical gap in understanding how training data influences temporal dynamics such as trajectories, deformations, and physical plausibility in generated videos.
- It introduces motion-weighted loss masks to isolate dynamic regions and compute motion-specific gradients efficiently, enabling scalable attribution across large video datasets and modern diffusion models.
- Using Motive to guide fine-tuning data curation improves motion smoothness and dynamic degree on VBench, achieving a 74.1% human preference win rate over the pretrained base model.
Introduction
Video generation models, particularly diffusion-based ones, rely heavily on training data to learn realistic motion dynamics such as object trajectories, deformations, and interactions. Unlike image generation, which focuses on static appearance, video models must capture temporal coherence and physical plausibility—properties deeply rooted in the training data. However, existing data attribution methods are largely designed for static images and fail to isolate motion-specific influences, often collapsing temporal structure into frame-level appearance. This limits their ability to explain how specific training clips shape motion, especially in complex, long-range sequences.
The authors introduce Motive, a motion-aware data attribution framework that computes gradients using dynamic motion masks to emphasize temporally coherent regions rather than static backgrounds. By integrating motion priors—such as optical flow—into the attribution process, Motive disentangles motion from appearance and traces generated dynamics back to influential training clips. The method enables targeted data curation and fine-tuning, improving motion quality while providing interpretability into how motion patterns emerge from data. It addresses key challenges: localizing motion, scaling across sequences, and capturing temporal relations like velocity and trajectory consistency. While limitations remain—such as sensitivity to motion tracking accuracy and difficulty separating camera motion from object motion—Motive offers a scalable, principled approach to understanding and controlling motion in video diffusion models.
Dataset

- The dataset includes a curated set of synthetic query videos designed to isolate specific motion primitives, sourced from Veo-3 [Google DeepMind, 2025], a video generation model.
- The query set comprises 10 motion types—compress, bounce, roll, explode, float, free fall, slide, spin, stretch, and swing—with 5 high-quality samples per category, totaling 50 query videos.
- Each video is generated using carefully crafted prompts and undergoes strict post-generation screening to ensure physical plausibility and visual realism, minimizing confounding factors like textured backgrounds or uncontrolled camera motion.
- The synthetic queries are not used for training but serve as target stimuli for attribution analysis and multi-query aggregation, enabling precise measurement of motion-specific influence in model behavior.
- The dataset is designed for controlled evaluation, with a small but representative scale that supports tractable attribution computation while covering the full motion taxonomy used in the study.
- No cropping or metadata construction is applied to the query videos; they are used in their original form as standardized, near-realistic stimuli.
Method
The authors present Motive, a framework for motion-centric data attribution in video generation models, designed to isolate and quantify the influence of training data on temporal dynamics. The overall architecture consists of two primary components: motion attribution and efficient gradient computation. The motion attribution process begins by detecting motion within a video using the AllTracker algorithm, which extracts optical flow maps to represent pixel displacements between consecutive frames. These flow maps are then used to create motion magnitude patches, which are normalized and downsampled to align with the latent space of the generative model. This motion mask is subsequently applied to the diffusion loss, creating a motion-weighted loss that emphasizes dynamic regions while de-emphasizing static content. The resulting motion-weighted gradients are computed and used to derive influence scores.
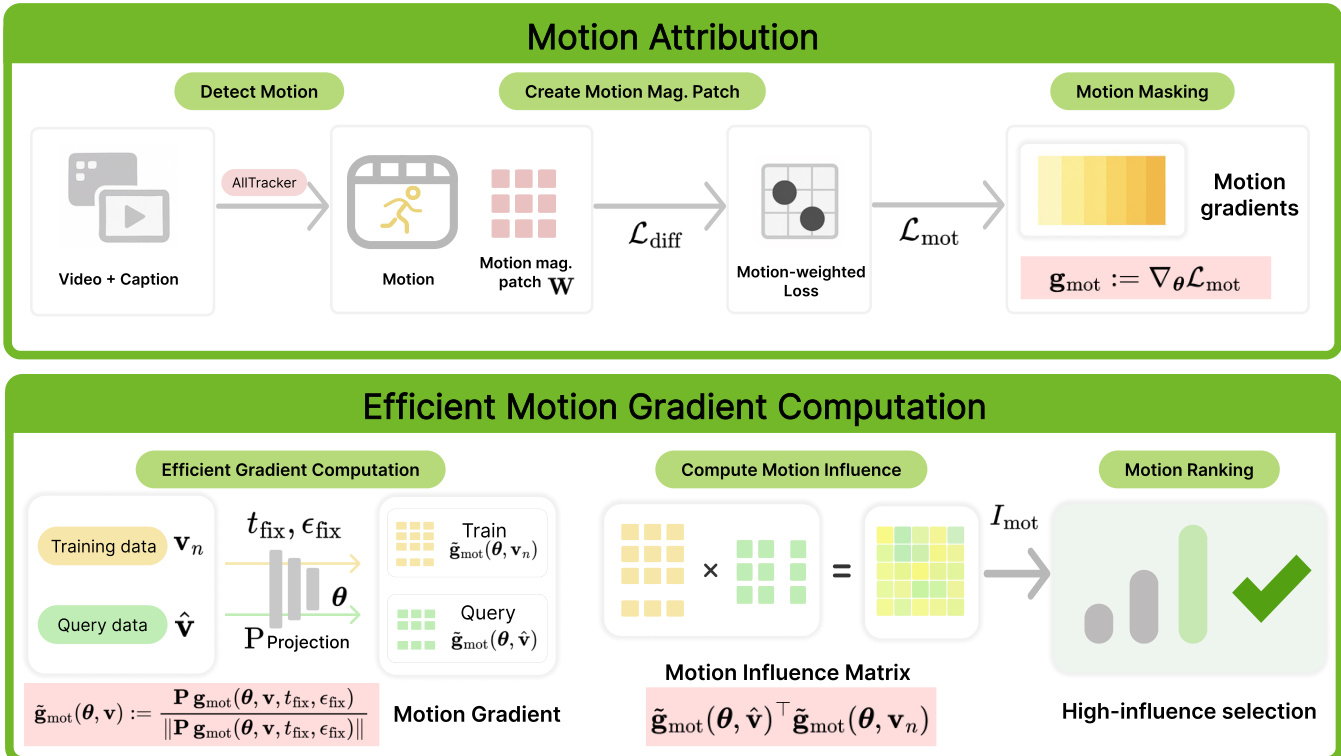
As shown in the figure below, the framework proceeds to compute gradients efficiently. This is achieved through a single-sample variant, where a fixed timestep tfix and a shared noise draw ϵfix are used for all training and query data, significantly reducing computational cost. The gradients are then projected into a lower-dimensional space using a Fastfood projection, which enables tractable storage and computation. The influence score for a training clip is computed as the cosine similarity between the projected, normalized gradients of the query and the training data. This process is repeated for multiple query videos, and the influence scores are aggregated using a majority voting scheme to select a fine-tuning subset that is consistently influential across different motion patterns. The final output is a ranked list of training clips, with the top-K examples selected for targeted fine-tuning to improve motion quality.
Experiment
- Main experiments validate motion-aware data selection using gradient-based attribution and negative filtering, demonstrating improved motion fidelity and temporal consistency across diverse motion types (compression, spin, slide, free fall, floating, planetary rotation).
- On VBench evaluation, Motive achieves 47.6% dynamic degree, surpassing random selection (41.3%) and whole-video attribution (43.8%), with 96.3% subject consistency and 46.0% aesthetic quality, outperforming the full fine-tuned model (42.0% dynamic degree, 95.9% subject consistency) using only 10% of training data.
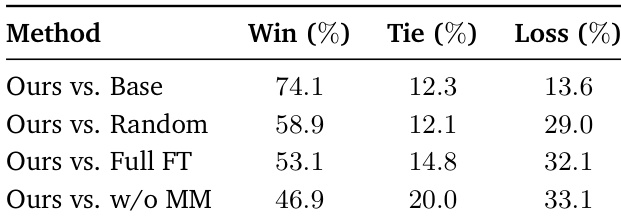
- Human evaluation shows 74.1% win rate against the base model and 53.1% against the full fine-tuned model, confirming perceptual motion quality improvements.
- Ablation studies confirm that single-timestep attribution at t=751 achieves high correlation (ρ=66%) with multi-timestep averaging, frame-length normalization reduces spurious length correlations by 54%, and 512-dimensional gradient projection preserves rankings (ρ=74.7%) with optimal efficiency.
- The method generalizes to larger models (Wan2.2-TI2V-5B), maintaining strong performance across architectures.
- Motion distribution analysis shows that high-influence videos span the full motion spectrum—mean motion magnitude difference between top and bottom 10% is only 4.3%—indicating the method selects for motion-specific influence, not just motion richness.
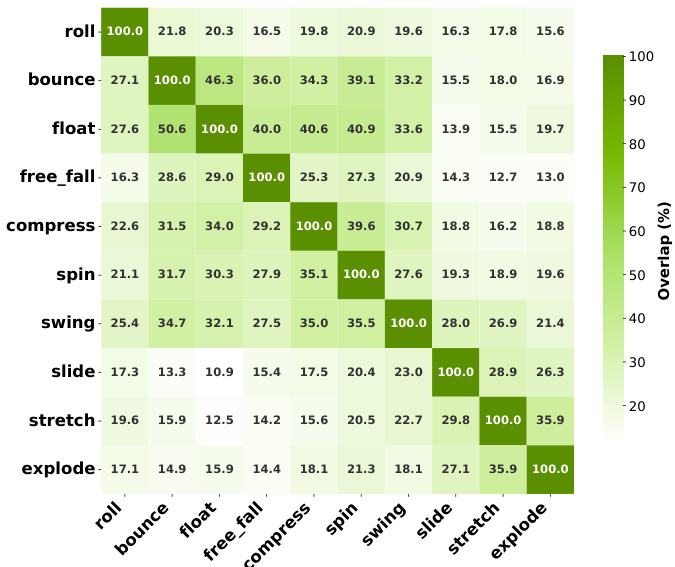
- Cross-motion influence patterns reveal consistent overlaps (e.g., bounce-float: 44.4%/46.3%) across datasets, reflecting fundamental dynamic similarities in model representations.
- Runtime analysis shows one-time gradient computation (≈150 hours on 1 A100) is amortized across queries, with new queries added in ≈54 seconds, enabling scalable data curation.
Results show that the proposed Motive method achieves the highest dynamic degree score (47.6%) and subject consistency (96.3%) among all evaluated approaches, outperforming both random selection and full fine-tuning on key motion fidelity metrics while maintaining strong performance across other quality dimensions. The authors use motion-aware attribution to select training data, which enables significant improvements in motion dynamics and temporal consistency compared to baseline methods, even when using only 10% of the training data.
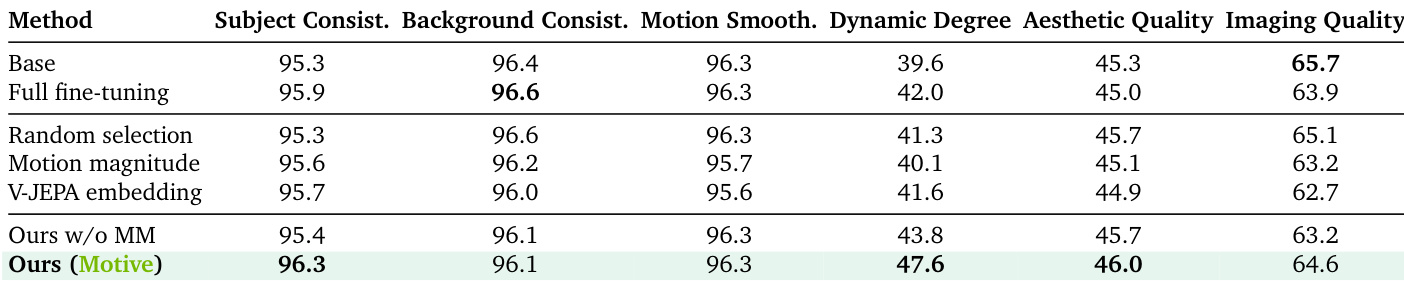
The authors use motion-aware attribution to select training data for fine-tuning, achieving higher motion fidelity and temporal consistency compared to baseline methods. Results show that their approach, Motive, outperforms random selection and full fine-tuning on key metrics such as dynamic degree and subject consistency, while maintaining strong performance in aesthetic and imaging quality.

The authors conduct a human evaluation comparing their method against baselines, showing that participants prefer their approach in 74.1% of pairwise comparisons against the base model and 53.1% against the full fine-tuned model. The results indicate that their motion-aware data selection leads to perceptually superior motion quality, with higher win rates and lower loss rates across all comparisons.
The authors compare the computational runtime of their method against several baselines for processing 10k training samples on a single GPU. Results show that their approach requires approximately 150 hours for the total computation, which is significantly longer than the baselines such as Random (<1 second), Motion Magnitude (~5.5 hours), Optical Flow (~5.7 hours), and V-JEPA (~3 hours). This high cost is attributed to the one-time gradient computation for training data, which is amortized across all queries and can be parallelized to reduce time.

Results show that Motive identifies influential training data with high overlap across motion categories, particularly for semantically similar motions like bounce and float (44.4% and 46.3% overlap), while dissimilar motions such as free fall and stretch exhibit low overlap (12.8% and 12.7%). The consistent patterns across datasets indicate that the method captures fundamental motion relationships, reflecting shared dynamics in video generation models.