Command Palette
Search for a command to run...
EnvScaler: أداة تكبير البيئات التفاعلية أداة-مُحَوَّلة للوكلاء LLM من خلال التركيب البرمجي
EnvScaler: أداة تكبير البيئات التفاعلية أداة-مُحَوَّلة للوكلاء LLM من خلال التركيب البرمجي
Xiaoshuai Song Haofei Chang Guanting Dong Yutao Zhu Zhicheng Dou Ji-Rong Wen
الملخص
من المتوقع أن تُدرَّب النماذج اللغوية الكبيرة (LLMs) للعمل كوكالات في بيئات واقعية متنوعة، لكن هذه العملية تعتمد على بيئة محاكاة غنية ومتنوعة تتيح التفاعل مع الأدوات. ومع ذلك، فإن الوصول إلى الأنظمة الحقيقية غالبًا ما يكون محدودًا؛ وبيئات المحاكاة المُنشَأة بواسطة النماذج اللغوية الكبيرة عُرضة للوهم والانعدام في الاتساق؛ كما أن بيئة المحاكاة التي تُبنى يدويًا صعبة التوسع. في هذا البحث، نُقدِّم EnvScaler، وهو إطار عمل تلقائي لبيئات التفاعل مع الأدوات قابلة للتوسع من خلال التوليد البرمجي. يتكوّن EnvScaler من مكونين رئيسيين: أولاً، يُنشئ SkelBuilder هياكل بيئات متنوعة من خلال استخراج المواضيع، ونمذجة المنطق، وتقييم الجودة. ثم، يُولِّد ScenGenerator سيناريوهات مهام متعددة، ووظائف تحقق مبنية على القواعد لمسار كل بيئة. وباستخدام EnvScaler، نُولِّد 191 بيئة وحوالي 7000 سيناريو، ونُطبِّقها في التدريب المُراقب (SFT) والتعلم التعلُّمي (RL) لنماذج سلسلة Qwen3. تُظهر النتائج على ثلاث معايير أداء أن EnvScaler يُحسِّن بشكل ملحوظ قدرة النماذج اللغوية الكبيرة على حل المهام في بيئات معقدة تتضمّن تفاعلات متعددة الدورات ومع عدة أدوات. نُطلق الكود والبيانات الخاصة بنا على الرابط التالي: https://github.com/RUC-NLPIR/EnvScaler.
One-sentence Summary
The authors from Renmin University of China propose EnvScaler, a programmatic framework that automates the scalable synthesis of diverse tool-interaction environments via skeleton construction and scenario generation, enabling effective SFT and RL training for LLMs like Qwen3 to solve complex, multi-turn, multi-tool tasks, significantly outperforming prior methods on benchmark evaluations.
Key Contributions
- Existing approaches to training LLM agents face limitations due to restricted access to real-world environments, hallucinations in LLM-simulated environments, and the scalability challenges of manually constructed sandboxes, highlighting the need for automated, large-scale environment synthesis.
- EnvScaler introduces SkelBuilder for automated construction of diverse, executable environment skeletons through topic mining, logic modeling, and iterative quality evaluation, and ScenGenerator for creating task scenarios with rule-based trajectory validation to ensure correctness and challenge.
- Evaluated on three benchmarks, EnvScaler-generated environments significantly improve the performance of Qwen3 series models in multi-turn, multi-tool tasks, demonstrating enhanced generalization and robustness through supervised fine-tuning and reinforcement learning.
Introduction
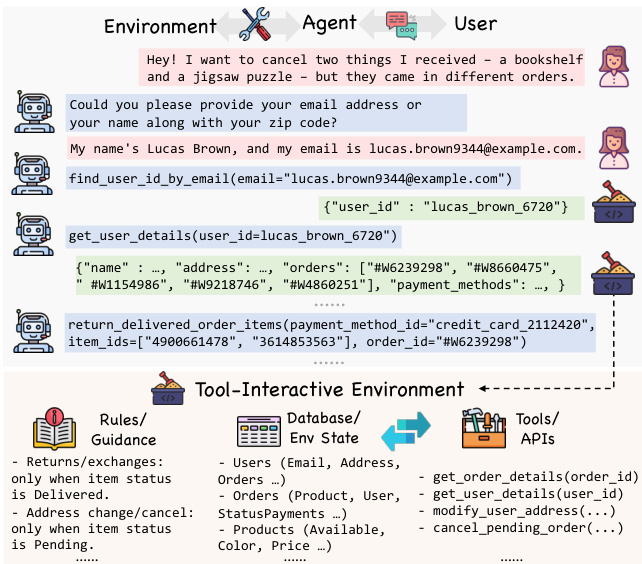
The authors leverage programmatic synthesis to address the critical challenge of scaling tool-interactive environments for training LLM agents, which are essential for real-world applications like e-commerce order management and flight rescheduling. Prior approaches face limitations: real-world systems are inaccessible, LLM-simulated environments suffer from hallucinations, and manually built sandboxes lack scalability and diversity. Existing automated methods either rely on pre-existing data, fail to model stateful interactions, or lack rigorous quality assessment. To overcome these issues, the authors introduce EnvScaler, a two-part framework. First, SkelBuilder automates the creation of diverse, executable environment skeletons through topic mining, logic modeling, and iterative quality evaluation using a testing and checking agent. Second, ScenGenerator produces realistic task scenarios with initial states, challenging tasks, and rule-based trajectory validation functions to enable accurate reward computation. The framework generates 191 environments and 7,000 scenarios, significantly improving LLM performance on multi-turn, multi-tool tasks in supervised fine-tuning and reinforcement learning.
Dataset

- The dataset is composed of synthetic environments generated using API-Bank (Li et al., 2023) and ToolACE (Liu et al., 2025b) as initial task sources, selected for their high task retention rates across LLMs.
- A total of 191 synthetic environments are produced, with an average of 18.58 tools and 21.38 state categories per environment, reflecting significant complexity and diversity.
- Environment generation involves multiple LLMs: GPT-4.1 and Qwen3-235B-Instruct-2507 are used for environment discovery and programming, while GPT-4.1-mini and Qwen3-30B-A3B-Instruct-2507 perform environment assessment.
- Each environment undergoes 100 test rounds with a filtering threshold of 0.85 to ensure quality, resulting in the final set of 191 validated environments.
- The synthetic environments include detailed state space definitions, specifying entities, their attributes, and roles within the environment.
- Example environments are illustrated with initial state configurations (Figure 25), task scenarios (Figure 26), and state check functions (Figure 11) used to compute reward scores for trajectories.
- The environments are used to train and evaluate the model across multiple benchmarks: BFCL-v3 Multi-Turn, Tau-Bench, and ACEBench-Agent, each testing different aspects of tool use and reasoning.
- Training leverages a mixture of tasks from these benchmarks, with specific subsets used to assess robustness—such as Missing Parameters, Missing Functions, Long Context, Multi-turn, and Multi-step scenarios.
- Evaluation applies dual criteria: state checking and response checking, ensuring both correctness of actions and alignment with task goals.
- Metadata for each environment is constructed from structured tool interfaces (Table 10) and state definitions, enabling consistent interpretation and automated validation.
Method
The authors leverage a modular framework, EnvScaler, to automate the synthesis of diverse, executable tool-interactive environments for training large language model (LLM) agents. The overall architecture consists of two primary components: SkelBuilder and ScenGenerator, which operate sequentially to construct environments and their associated scenarios. As shown in the framework diagram, SkelBuilder first generates the environment skeleton by mining themes from existing tasks, constructing executable program logic, and assessing the quality of the resulting environment. This process produces a set of environments, denoted as E={Fexec,Edoc,Σtool}, where Fexec is the executable program file, Edoc is the documentation, and Σtool is the tool interface set. The output of SkelBuilder, the environment structure, is then fed into ScenGenerator, which synthesizes the scenario content, including initial states, challenging tasks, and validation functions, to create a complete training dataset.
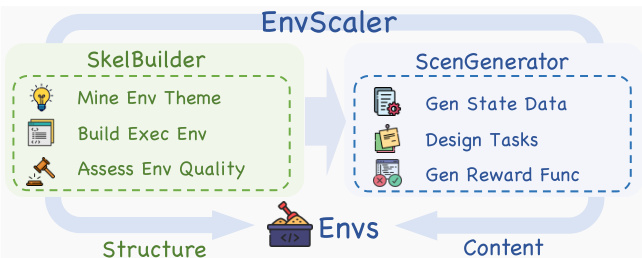
The first stage, task-guided environment discovery, begins with a set of existing tasks Texist. An LLM performs binary filtering to identify tasks that are situated within a domain-specific, stateful environment, retaining only those that require interaction with a persistent state. For each retained task, the LLM infers a corresponding environment description. These descriptions are aggregated and deduplicated using embedding-based clustering to yield a diverse and non-redundant set of environment themes, {Edes}.

The second stage, automated executable environment construction, transforms the environment description into a programmatically modeled environment through a three-stage pipeline. First, in the logic planning phase, an LLM enriches the environment description Edes to infer the environment state definition Estate, domain rules Erule, and a list of tool operations {Etooli}. The rules are concatenated with the description to form the environment documentation Edoc. Second, in the program modeling phase, the LLM converts the planned state space into class attribute definitions Fattr. For each tool operation, given the environment rules and class attributes, it generates the corresponding class-method implementation Fmethi, ensuring consistency with the rules and proper state transitions. Finally, in the program assembly phase, the generated code fragments are automatically merged into a complete Python class file Fexec, which implements all sandbox logic. Syntax validity is verified via the abstract syntax tree (AST), and the AST combined with regex extraction yields all method signatures, forming the tool interface set Σtool.
The third stage, dual-agent environment assessment, evaluates the actual tool-execution performance of the constructed environment. A frontend testing agent, Mtest, is instantiated with no access to the internal implementation. In each round, it receives the current environment state Sj and randomly generates a call request, which may be a positive or negative test case. The backend checking agent, Mcheck, then inspects the tool's source code Fmeth, the returned result Rj, and the state changes before and after execution to judge whether the behavior matches expectations. The testing and checking agents form a closed loop, iterating for N rounds. The average judging pass rate serves as the quantitative metric for the environment's quality, and environments below a pre-defined threshold are discarded.

The ScenGenerator component synthesizes scenarios by first generating the environment's initial state data Sinit using an LLM. It then derives challenging tasks based on the initial state, tool set, and rules. To achieve rule-based trajectory verification, the task is decomposed into a checklist of verifiable conditions. For each checkpoint, an LLM generates a terminal-state validation function that takes the environment's final state Sfinal as input and returns a boolean indicating whether the condition is satisfied. The proportion of passed functions is used as the trajectory's reward score.

Finally, the agent-environment interaction is modeled as a Partially Observable Markov Decision Process (POMDP). Two interaction settings are considered: Non-Conversation (Non-Conv.), where the environment provides the complete task information upfront, and Conversation (Conv.), where the environment includes an LLM-simulated user, requiring the agent to acquire information through dialogue. For supervised fine-tuning (SFT), trajectories from a teacher LLM are used as learning targets. For reinforcement learning (RL), trajectories are converted into rewards using the validation functions, which are then applied for policy optimization.
Experiment
- Pilot study with 50 synthetic scenarios shows Qwen3-8B (Thinking) achieves 57.78 score vs. Qwen3-4B (Non-Think) at 37.53, with trajectory length increasing from ~15 steps (Non-Conv) to over 25 steps (Conv), validating the difficulty and effectiveness of synthetic tasks in promoting long, complex reasoning.
- SFT on 140 synthetic environments followed by RL using Reinforce++ significantly improves performance across BFCL-MT, Tau-Bench, and ACEBench-Agent, with Qwen3-8B achieving 4.88 and 3.46 point gains on BFCL-MT and Tau-Bench respectively, demonstrating the effectiveness of synthetic environments and state-checking rewards.
- Scaling the number of training environments leads to steady performance gains on BFCL-MT and ACEBench-Agent, with the most significant improvement observed when scaling from 0 to 20 environments, indicating that diversity and quantity of synthetic environments enhance model adaptability.
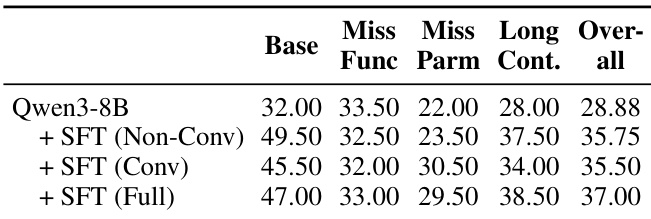
- Training on both Non-Conv and Conv interaction patterns (Full setting) yields the highest performance, showing that learning to handle both complete and incomplete information is crucial for robust tool-use across diverse scenarios.
- Performance gains from EnvScaler are consistent across environments with varying similarity to test sets, indicating that the model learns transferable problem-solving patterns rather than relying on direct environmental similarity.
- Direct RL training without SFT shows limited gains, especially for smaller models like Qwen3-1.7B, while Qwen3-8B achieves notable improvements, highlighting the importance of SFT initialization for high-quality policy learning.
- Training in non-thinking mode with EnvScaler improves performance on BFCL-MT and ACEBench-Agent but degrades results on Tau-Bench, underscoring the model’s reliance on reasoning chains for complex reasoning tasks.
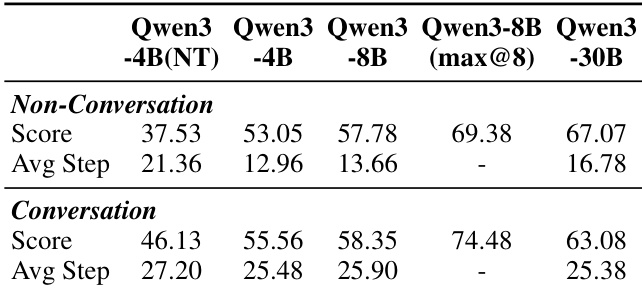
Results show that Qwen3 models achieve higher scores and longer average trajectories under the Conversation setting compared to the Non-Conversation setting. The performance increases with model size, with Qwen3-30B achieving the highest score in both settings, indicating that larger models benefit more from conversational interaction.
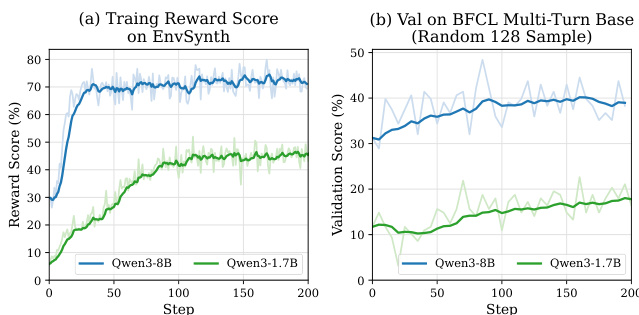
Results show that training with EnvScaler significantly improves model performance across all benchmarks, with SFT providing substantial gains and further boosting through RL. The improvements are most pronounced on BFCL-MT and ACEBench-Agent, while gains on Tau-Bench are more limited, indicating that the synthetic environments enhance multi-turn, multi-tool collaboration and domain adaptability more effectively than deep reasoning tasks.
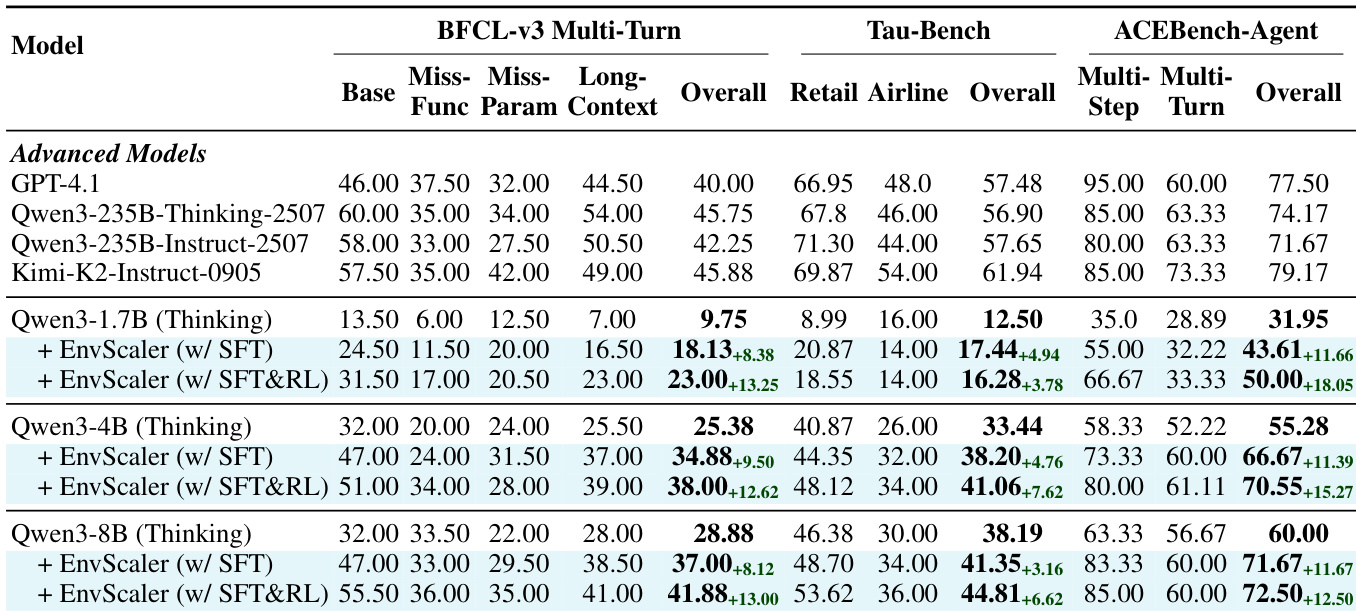
Results show that Qwen3-30B-A3B-Thinking-2507 achieves a higher win rate than Qwen3-4B across all comparison pairs, with the largest difference observed in the non-thinking mode comparison. The performance gap between models is most pronounced when comparing Qwen3-30B-A3B-Thinking-2507 to Qwen3-4B (Non-Thinking), where the win rate is 46.0% compared to 24.0% for losses, indicating a significant advantage for the larger model in this setting.
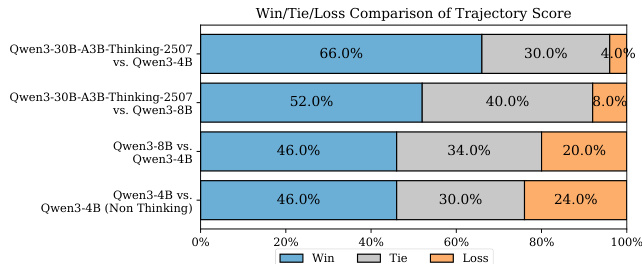
The authors use the Reinforce++ algorithm to train Qwen3-8B and Qwen3-1.7B models in synthetic environments, showing that Qwen3-8B achieves higher training reward scores and validation performance on BFCL-MT compared to Qwen3-1.7B. Results show that larger models benefit more from reinforcement learning in synthetic environments, with Qwen3-8B demonstrating stable improvement and higher final performance, while Qwen3-1.7B shows slower learning and lower overall gains.
Results show that combining non-conversational and conversational interaction patterns during SFT significantly improves Qwen3-8B's performance across all evaluation metrics. The Full SFT setting, which includes both interaction types, achieves the highest overall score, indicating that training on diverse interaction patterns enhances the model's adaptability in both complete and incomplete information scenarios.