Command Palette
Search for a command to run...
GDPO: تحسين سياسة التطبيع المُفصَّل بالعوائد الجماعية لتحسين التعلم بالتعويض المتعدد
GDPO: تحسين سياسة التطبيع المُفصَّل بالعوائد الجماعية لتحسين التعلم بالتعويض المتعدد
الملخص
مع تطور نماذج اللغة وزيادة قدرتها، يتوقع من المستخدمين أن توفر هذه النماذج لا فقط إجابات دقيقة، بل أيضًا سلوكًا متماشيًا مع تفضيلات بشرية متنوعة في سياقات مختلفة. ولتحقيق هذا الهدف، بدأت أنظمة التعلم بالتعزيز (Reinforcement Learning) في دمج مكافآت متعددة، كل منها يُمثّل تفضيلًا مميزًا، لتوجيه النماذج نحو السلوك المرغوب. ومع ذلك، أظهرت الدراسات الحديثة اعتمادها التلقائي على خوارزمية تحسين السياسة النسبية المجمّعة (Group Relative Policy Optimization - GRPO) في السياقات متعددة المكافآت، دون تقييم مدى ملاءمتها لهذا السياق. في هذه الورقة، نُظهر أن تطبيق GRPO مباشرةً لتوحيد مجموعات المكافآت الناتجة عن التوقيع (rollout) يؤدي إلى تلاشي الفروق بين القيم المميزة (advantage values)، مما يقلل من دقة الإشارة التدريبية ويؤدي إلى تقارب غير مثالي، وفي بعض الحالات إلى فشل مبكر في التدريب. ثم نُقدّم طريقة جديدة لتحسين السياسة تُسمّى تحسين السياسة المُفصّل لتصحيح المكافآت (Group reward-Decoupled Normalization Policy Optimization - GDPO)، التي تحل هذه المشكلات من خلال فصل عملية التوحيد لكل مكافأة على حدة، مما يُحافظ بشكل أدق على الفروق النسبية بين المكافآت، ويُمكّن من تحسين التدريب متعدد المكافآت بدقة أعلى، مع تحسين كبير في استقرار التدريب. قارنا بين GDPO وGRPO في ثلاث مهام: استدعاء الأدوات، التفكير الرياضي، والتفكير البرمجي، وتم تقييم الأداء من خلال معايير الدقة (الدقة، نسبة الأخطاء) ومعايير الالتزام بالقيود (التنسيق، الطول). في جميع السياقات، تفوقت GDPO بشكل متسق على GRPO، مما يُظهر فعاليتها وقابلية تعميمها في تحسين التعلم بالتعزيز متعدد المكافآت.
One-sentence Summary
The authors, affiliated with institutions including the University of Washington, University of Illinois Urbana-Champaign, and DeepSeek AI, propose GDPO, a novel policy optimization method for multi-reward reinforcement learning that decouples reward normalization per objective to preserve fine-grained advantage distinctions, overcoming the signal collapse issue in GRPO; this enables more accurate, stable, and generalizable training across tool calling, math reasoning, and coding tasks, significantly improving alignment with diverse human preferences.
Key Contributions
- Multi-reward reinforcement learning (RL) for language models is increasingly important for aligning with diverse human preferences, but directly applying Group Relative Policy Optimization (GRPO) to multiple heterogeneous rewards causes reward combinations to collapse into identical advantage values, degrading training signal resolution and leading to unstable or failed training.
- The proposed Group reward-Decoupled Normalization Policy Optimization (GDPO) addresses this by decoupling group-wise normalization per individual reward, preserving relative differences across reward dimensions, followed by batch-wise advantage normalization to maintain stable update magnitudes regardless of reward count.
- GDPO consistently outperforms GRPO across three tasks—tool calling, math reasoning, and coding reasoning—showing higher accuracy (up to 6.3% on AIME), better format compliance, and improved training stability, demonstrating its effectiveness and generalizability in multi-reward RL.
Introduction
As language models grow more capable, aligning them with diverse human preferences—such as accuracy, safety, coherence, and format adherence—has become critical. This is increasingly achieved through multi-reward reinforcement learning (RL), where multiple reward signals guide policy optimization. However, prior work often applies Group Relative Policy Optimization (GRPO) directly to summed rewards, which collapses distinct reward combinations into identical advantage values due to group-wise normalization. This signal compression reduces training precision, degrades convergence, and can cause early training failure, especially in complex tasks involving multiple objectives.
To address this, the authors propose Group reward-Decoupled Normalization Policy Optimization (GDPO), which decouples the normalization of individual rewards before applying batch-wise advantage normalization. This preserves fine-grained differences across reward combinations, leading to more accurate and stable policy updates. GDPO maintains numerical stability regardless of the number of rewards and avoids the signal collapse inherent in GRPO.
Evaluated on tool calling, math reasoning, and code generation tasks, GDPO consistently outperforms GRPO in both correctness and constraint adherence metrics. For example, it achieves up to 6.3% higher accuracy on AIME math benchmarks while producing shorter, more concise responses. The results demonstrate GDPO’s effectiveness and generalizability as a robust alternative to GRPO in multi-reward RL.
Method
The authors propose Group reward-Decoupled normalization Policy Optimization (GDPO), a method designed to address the issue of reward collapse in multi-reward reinforcement learning when using Group Relative Policy Optimization (GRPO). The core idea of GDPO is to decouple the normalization process by applying group-wise normalization independently to each individual reward before aggregating them into a final advantage signal. This contrasts with GRPO, which first sums all rewards and then applies group-wise normalization to the aggregated sum.
Refer to the framework diagram 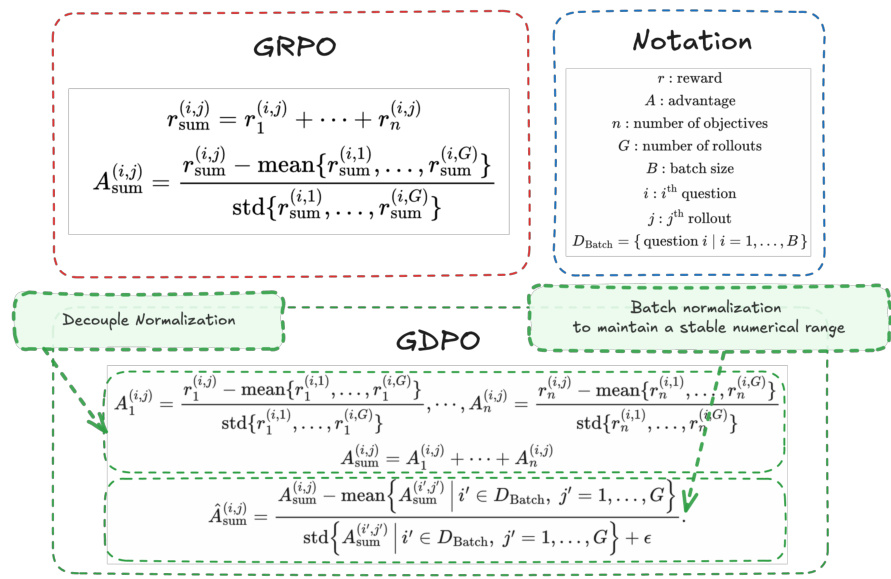 . As shown in the figure below, the GRPO framework computes the total reward rsum(i,j) by summing the individual rewards r1(i,j),…,rn(i,j) for a given rollout. The advantage Asum(i,j) is then calculated by normalizing this summed reward across all rollouts for the same question. In contrast, GDPO first normalizes each reward rk(i,j) separately using the mean and standard deviation of its values across all G rollouts for the ith question, resulting in normalized advantages Ak(i,j). The overall advantage is then obtained by summing these normalized advantages: Asum(i,j)=∑k=1nAk(i,j). This sum is subsequently normalized across the entire batch to ensure a stable numerical range, yielding the final advantage A^sum(i,j).
. As shown in the figure below, the GRPO framework computes the total reward rsum(i,j) by summing the individual rewards r1(i,j),…,rn(i,j) for a given rollout. The advantage Asum(i,j) is then calculated by normalizing this summed reward across all rollouts for the same question. In contrast, GDPO first normalizes each reward rk(i,j) separately using the mean and standard deviation of its values across all G rollouts for the ith question, resulting in normalized advantages Ak(i,j). The overall advantage is then obtained by summing these normalized advantages: Asum(i,j)=∑k=1nAk(i,j). This sum is subsequently normalized across the entire batch to ensure a stable numerical range, yielding the final advantage A^sum(i,j).
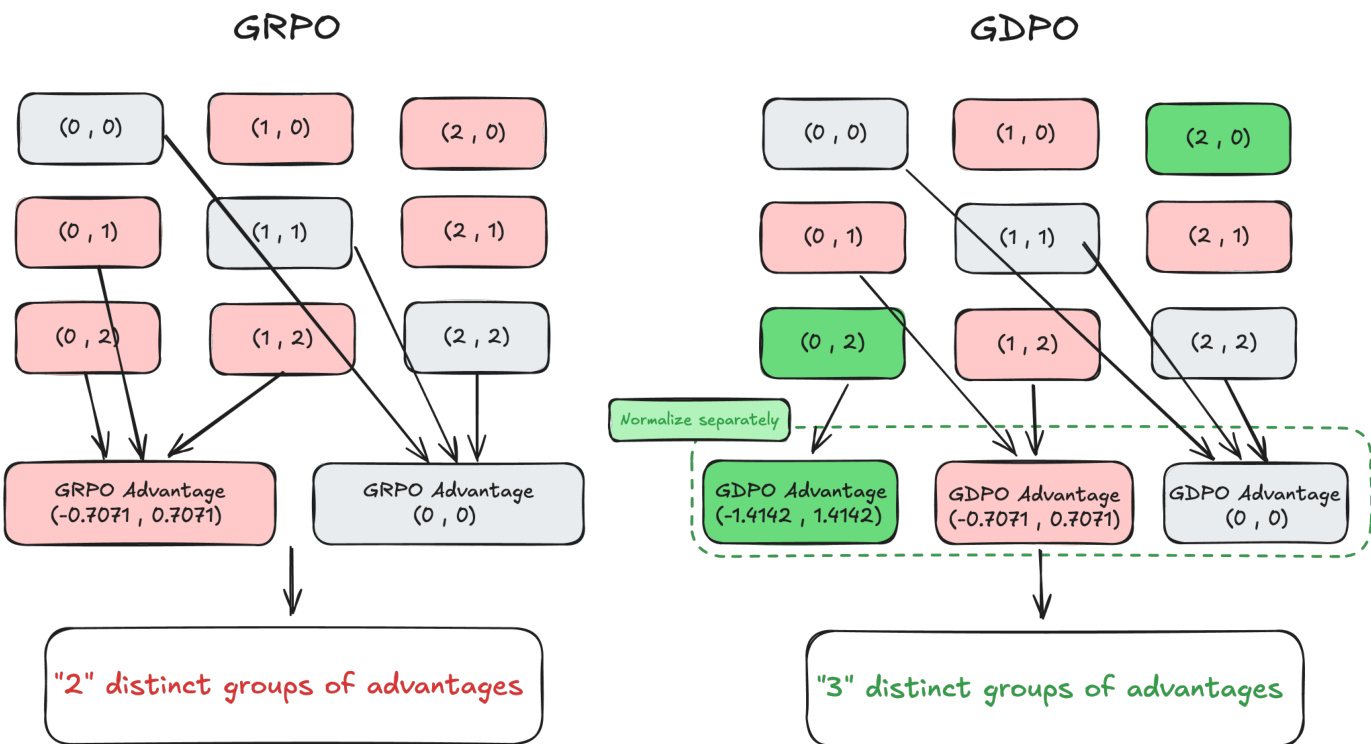 As shown in the figure below, this decoupled approach prevents the loss of information that occurs in GRPO. In the GRPO framework, distinct reward combinations, such as (0,2) and (0,1), can be normalized to the same advantage value, thereby collapsing distinct reward signals into a single group. This is illustrated by the fact that both (0,2) and (0,1) map to the same GRPO Advantage (−0.7071,0.7071), resulting in only two distinct groups of advantages. In contrast, GDPO normalizes each reward dimension separately, preserving the differences between these combinations. For example, the reward combination (0,1) becomes (−0.7071,0.7071) and (0,2) becomes (−1.4142,1.4142), resulting in three distinct groups of advantages. This allows GDPO to provide a more expressive and accurate training signal that better reflects the relative differences between reward combinations.
As shown in the figure below, this decoupled approach prevents the loss of information that occurs in GRPO. In the GRPO framework, distinct reward combinations, such as (0,2) and (0,1), can be normalized to the same advantage value, thereby collapsing distinct reward signals into a single group. This is illustrated by the fact that both (0,2) and (0,1) map to the same GRPO Advantage (−0.7071,0.7071), resulting in only two distinct groups of advantages. In contrast, GDPO normalizes each reward dimension separately, preserving the differences between these combinations. For example, the reward combination (0,1) becomes (−0.7071,0.7071) and (0,2) becomes (−1.4142,1.4142), resulting in three distinct groups of advantages. This allows GDPO to provide a more expressive and accurate training signal that better reflects the relative differences between reward combinations.
Experiment
- Evaluated GDPO against GRPO on tool-calling task (Sec. 4.1): GDPO achieved 2.7% higher average accuracy and over 4% better format correctness on BFCL-v3 compared to GRPO for Qwen2.5-1.5B, with consistent convergence to higher correctness and format rewards across five runs.
- Ablation study on GRPO with/without standard deviation normalization: GRPO w/o std matched correctness gains but failed to converge on format reward, achieving 0% correct format ratio on BFCL-v3, indicating instability in multi-reward optimization.
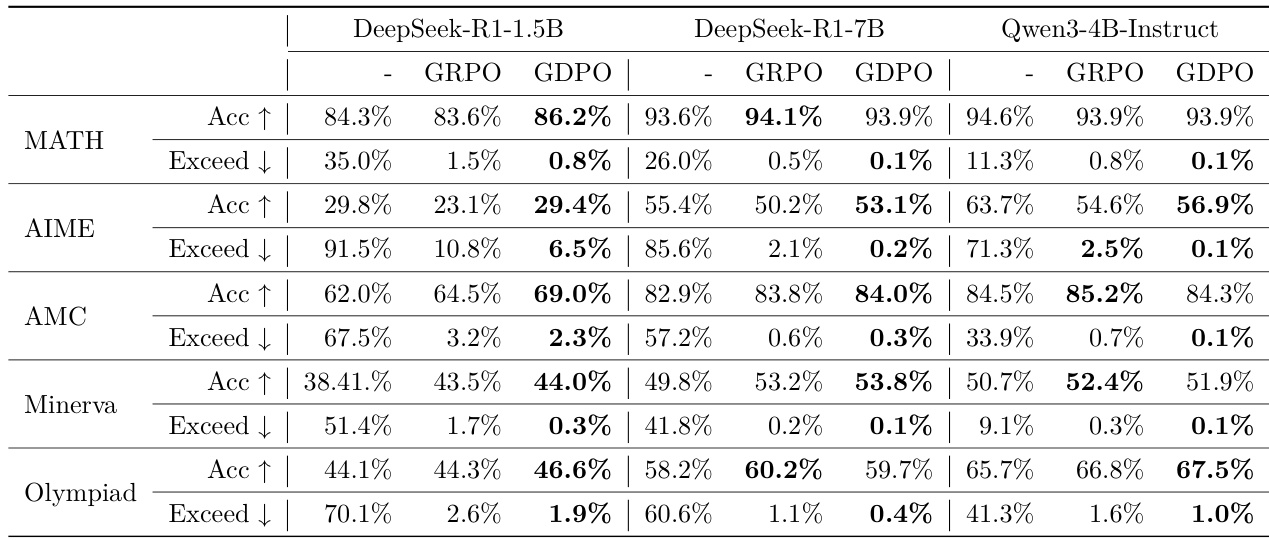
- Compared GDPO and GRPO on mathematical reasoning (Sec. 4.2): GDPO improved pass@1 accuracy by up to 6.7% on MATH and 3% on AIME, while reducing length-exceeding ratios to 0.1–0.2% (vs. 2.1–2.5% for GRPO), demonstrating superior trade-off between accuracy and efficiency.
- Analyzed reward weight and conditioned reward impact: Reducing length reward weight alone had limited effect; conditioning the length reward on correctness significantly improved alignment, with GDPO achieving 4.4% higher accuracy on AIME and 16.9% lower length violations than GRPO.
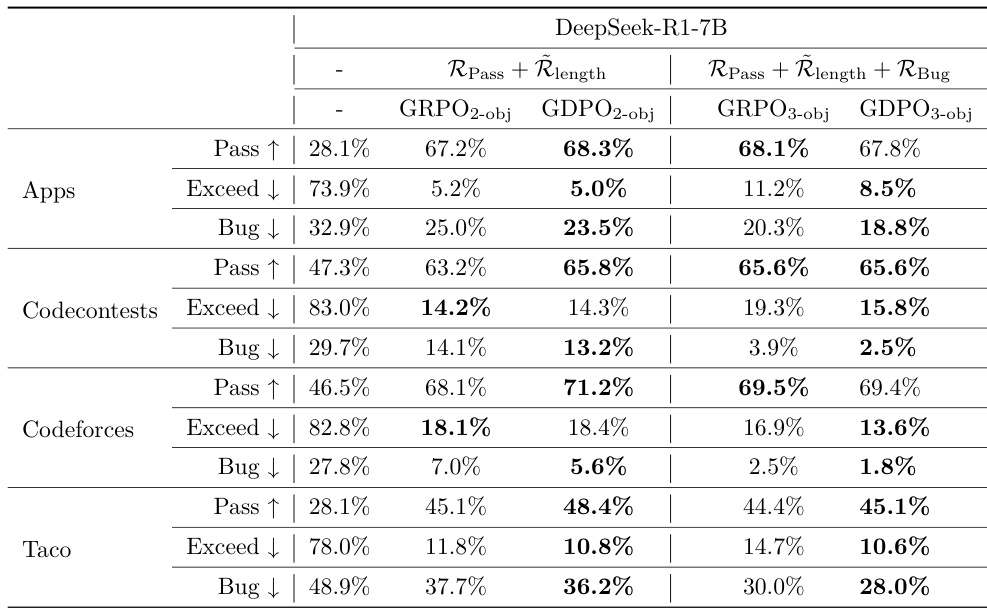
- Extended to three-reward coding reasoning (Sec. 4.3): GDPO achieved 2.6–3.3% higher pass rates on Codecontests and Taco with minimal increase in length violations, and reduced bug ratio while maintaining pass rate, showing strong generalization to three objectives.
The authors compare GDPO and GRPO on a mathematical reasoning task that optimizes accuracy and length constraints, finding that GDPO consistently achieves higher accuracy and better adherence to length limits. While both methods initially prioritize the easier length reward, GDPO recovers and improves correctness more effectively, leading to superior performance across all benchmarks.

The authors compare GDPO and GRPO on a coding reasoning task with three reward objectives: pass rate, length constraint, and bug ratio. Results show that GDPO consistently achieves a better balance across all objectives than GRPO, maintaining similar pass rates while significantly reducing both length-exceeding ratios and bug ratios.
Results show that GDPO consistently outperforms GRPO across all mathematical reasoning benchmarks, achieving higher accuracy and significantly lower length-exceeding ratios. The improvements are particularly notable on challenging tasks like AIME and Olympiad, where GDPO achieves up to 3% higher accuracy while reducing length violations to near zero.
The authors use GDPO to optimize two rewards—tool-calling correctness and format compliance—on the tool-calling task, and results show that GDPO consistently achieves higher correctness and format rewards compared to GRPO across five training runs. GDPO also outperforms GRPO in downstream evaluation on the BFCL-v3 benchmark, improving average tool-calling accuracy and format correctness by up to 5% and 4%, respectively.

The authors use GDPO to optimize two rewards—tool-calling correctness and format compliance—on the tool-calling task, and results show that GDPO consistently achieves higher correctness and format rewards compared to GRPO across five training runs. GDPO also outperforms GRPO in downstream evaluation on the BFCL-v3 benchmark, improving average tool-calling accuracy and format correctness by up to 5% and 4%, respectively.