Command Palette
Search for a command to run...
LongVideoAgent: الاستنتاج متعدد الوكلاء مع مقاطع الفيديو الطويلة
LongVideoAgent: الاستنتاج متعدد الوكلاء مع مقاطع الفيديو الطويلة
Runtao Liu Ziyi Liu Jiaqi Tang Yue Ma Renjie Pi Jipeng Zhang Qifeng Chen
الملخص
تشير التطورات الحديثة في نماذج اللغة متعددة الوسائط (multimodal LLMs) والأنظمة التي تستخدم أدوات لاستجابة الأسئلة حول مقاطع الفيديو الطويلة إلى إمكانات استنتاج منطقي حول الحلقات الطويلة التي تصل إلى ساعة. ومع ذلك، تستمر العديد من الطرق في تجميع المحتوى في ملخصات مفقودة التفاصيل أو الاعتماد على مجموعات أدوات محدودة، مما يُضعف التماسك الزمني ويؤدي إلى تفويت التفاصيل الدقيقة. نقترح إطارًا متعدد الوكلاء (multi-agent framework)، حيث يُسند إلى نموذج لغة رئيسي (master LLM) تنسيق عمل وكيل تأصيل (grounding agent) لتحديد الأجزاء المرتبطة بالسؤال، ووكيل بصرية (vision agent) لاستخراج ملاحظات نصية محددة. يخطط الوكيل الرئيسي ضمن حد معين من الخطوات، ويُدرَّب باستخدام التعلم المعزز (reinforcement learning) لتشجيع تعاون واعٍ، موجز، دقيق، وفعال بين الوكلاء. يُسهم هذا التصميم في تمكين الوكيل الرئيسي من التركيز على اللقطات ذات الصلة من خلال التأصيل، وتعزيز النصوص الترجمية بتفاصيل بصرية، وتقديم مسارات قابلة للتفسير. على مجموعة البيانات التي اقترحناها، LongTVQA وLongTVQA+، وهما مجموعتا بيانات على مستوى الحلقة مُجمَّعَتان من TVQA/TVQA+، تفوق نظامنا المتعدد الوكلاء بشكل ملحوظ على النماذج القوية غير الوكيلية. كما تُظهر التجارب أن التعلم المعزز يُعزز بشكل إضافي القدرة على الاستدلال والتخطيط لدى الوكيل المدرب.
One-sentence Summary
Researchers from Hong Kong University of Science and Technology et al. propose a reinforcement learning-trained multi-agent framework for long-video question answering, where a master LLM coordinates grounding and vision agents to replace lossy summarization. This approach enables precise temporal localization and visual detail extraction, significantly outperforming baselines on LongTVQA datasets through interpretable, step-limited cooperative reasoning.
Key Contributions
- Existing long-video QA methods suffer from lossy compression and limited toolsets, weakening temporal grounding and missing fine-grained cues; this work introduces a modular multi-agent framework where a master LLM coordinates a grounding agent for segment localization and a vision agent for targeted visual observation extraction.
- The master agent employs step-limited planning and reinforcement learning training with rewards that promote concise, correct, and efficient multi-agent cooperation, enabling focused reasoning on relevant clips while integrating subtitles with visual details for interpretable trajectories.
- Evaluated on the newly proposed episode-level LongTVQA and LongTVQA+ datasets, the system significantly outperforms strong non-agent baselines, with ablation studies confirming that both the multi-agent architecture and reinforcement learning enhance reasoning and planning capabilities.
Introduction
Multimodal large language models (MLLMs) struggle with long video understanding because critical information is often sparse across hours of footage, requiring fine-grained analysis of frames, audio, and dialogue. Prior approaches typically process videos through static, lossy compression or heavy downsampling in a single pass, which irreversibly discards temporal details and fails to handle complex, temporally extended queries. Even early agent-based systems like VideoAgent rely on limited toolsets (e.g., generic captioning models) that cannot capture precise object references or subtle visual cues, while underutilizing structured reasoning.
The authors address this by introducing LongVideoAgent, a multi-agent framework where a master agent coordinates specialized grounding and vision agents to actively retrieve task-relevant segments and extract fine-grained visual details through iterative, tool-augmented reasoning. They further propose a reward-driven training strategy that enforces concise, step-wise evidence gathering and a new LongTVQA benchmark for rigorous evaluation. This approach achieves state-of-the-art accuracy by dynamically focusing on sparse evidence while avoiding irreversible preprocessing.
Dataset
The authors construct LongTVQA and LongTVQA+ by extending TVQA and TVQA+ into episode-scale sequences. Key details:
-
Dataset composition and sources:
Built on TVQA (6 TV shows, 152.5K multiple-choice questions over 21.8K short clips) and TVQA+ (a refined subset with spatio-temporal annotations, focusing mainly on The Big Bang Theory). -
Subset specifics:
- LongTVQA: Aggregates all TVQA clips per episode into hour-long sequences. Retains 152.5K questions with subtitles, moment annotations, and clip-level context.
- LongTVQA+: Aggregates TVQA+ clips (29.4K questions from 4,198 clips), preserving 310.8K frame-level bounding boxes for entity grounding and precise timestamps.
-
Data usage in the paper:
- Uses the original validation splits after episode-level aggregation for all reported results.
- Tests models with frame-based inputs (leveraging visual evidence) versus subtitle-only inputs, showing frames generally improve performance.
- Applies a multi-agent framework (MASTERAGENT) and RL fine-tuning on these datasets.
-
Processing details:
- Clips from the same episode are merged into a single timeline, adjusting timestamps to the episode scale.
- Visual streams, subtitles, and questions are combined per episode; TVQA+ bounding boxes remain frame-aligned.
- No additional cropping—long videos are processed natively at the aggregated episode level.
Method
The authors leverage a multi-agent reasoning framework to address long-video question answering, where a master LLM orchestrates two specialized agents: a grounding agent for temporal localization and a vision agent for fine-grained visual observation extraction. This architecture enables iterative, evidence-gathering reasoning over hour-long video episodes without relying on lossy compression or fixed summarization.
As shown in the figure below, the system operates in a bounded multi-round loop, with the master agent maintaining a growing context that includes subtitles, localized clip tags, and extracted visual observations. At each round, the master emits one of three structured action tokens: <request_grounding> to refine temporal localization, to trigger visual observation extraction, or to terminate and produce the final response. The grounding agent, given the question and full subtitles, returns a symbolic tag (e.g., <clip_X>) identifying a relevant temporal segment. The vision agent, conditioned on that clip tag and a dynamically generated visual query, extracts textual descriptions of objects, actions, scene cues, or on-screen text from the corresponding frames. These outputs are appended to the master’s context, guiding subsequent decisions.
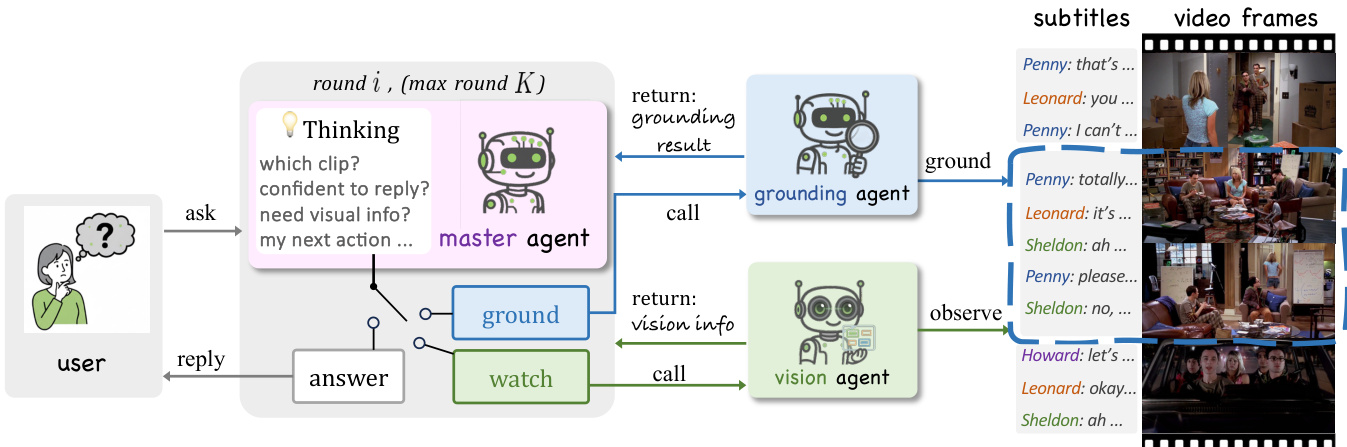
For open-source LLMs serving as the master agent, the authors apply reinforcement learning via GRPO to optimize policy behavior. The training objective combines two rule-based rewards: structural validity rtfmt, which rewards correct emission of exactly one action token per step, and answer correctness rans, which grants a terminal reward for exact match on the multiple-choice answer. The trajectory return is defined as R(τ)=α∑t=0Trtfmt+rans, where α>0 balances per-step structural shaping with the final task reward. Policy updates are computed using sequence-level advantages with a learned value baseline, while the grounding and vision agents remain frozen throughout training. This minimal reward structure encourages the master to produce concise, well-formed action sequences and accurate final answers without requiring dense intermediate supervision.
Refer to the framework diagram for the full interaction flow: the user submits a question and video, the master agent initiates reasoning, and the system iterates through grounding and vision calls until sufficient evidence is accumulated to generate a correct answer. The resulting trace is interpretable, step-by-step, and grounded in both temporal and visual evidence.
Experiment
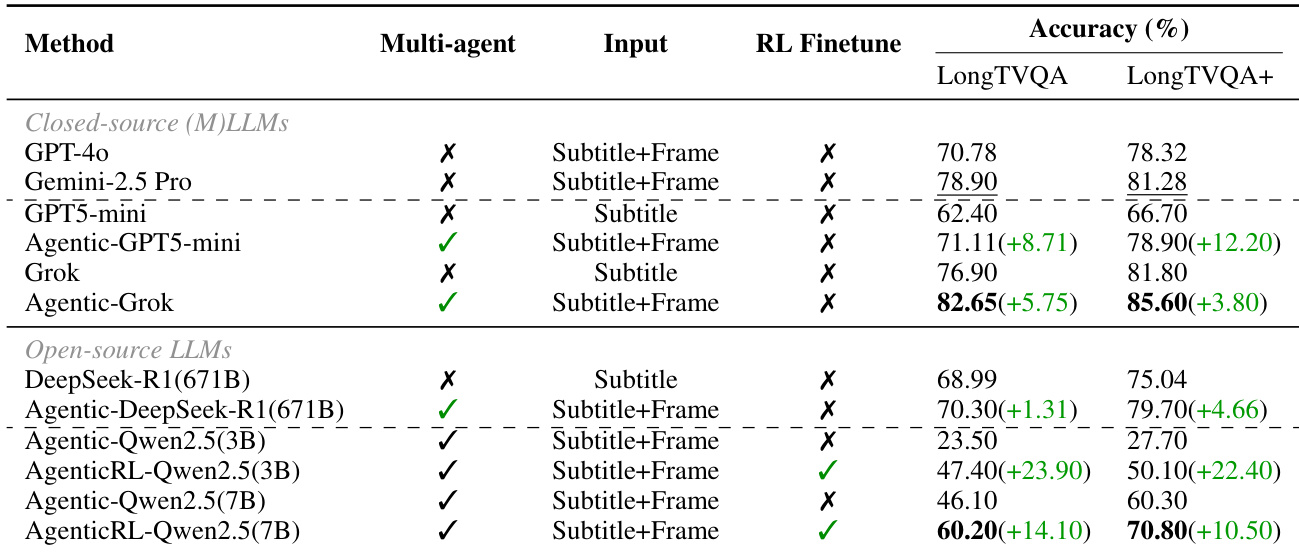
- Multi-agent framework versus non-agent baselines: On LongTVQA/LongTVQA+ validation sets, integrating grounding and vision agents achieved 74.8 Answer Accuracy, surpassing non-agent baselines by +10.5 points, validating agentic behavior's effectiveness in contextual localization and visual inspection.
- Reinforcement learning impact: Qwen2.5-7B with RL attained accuracy comparable to GPT-5-mini under identical evaluation protocols, demonstrating consistent gains over inference-only counterparts for open-source models.
- Execution step limit ablation: Increasing maximum steps from 2 to 5 raised Answer Accuracy to 73.67 (+5.37) and Grounding Accuracy to 71.0 (+4.0), with saturation beyond K=5 indicating optimal step efficiency.
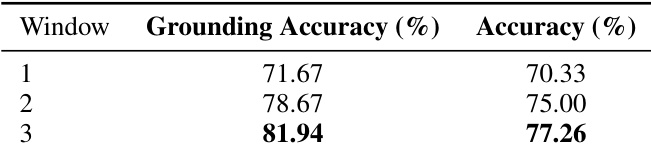
- Window context analysis: Expanding evidence windows from 1 to 3 clips improved Answer Accuracy to 77.26 (+6.93) and Grounding Accuracy to 81.94 (+10.27), confirming adjacent clip context aids disambiguation but with diminishing returns.
- Vision agent comparison: GPT-4o as vision backbone achieved 78.00 Answer Accuracy, surpassing Qwen3-VL-235B-a22b by +4.33 points, highlighting stronger visual recognition's role in end-task performance.
The authors evaluate the impact of increasing the maximum execution steps (K) for the master agent, finding that raising K from 2 to 5 improves both grounding accuracy (67.0% to 71.0%) and overall answer accuracy (68.30% to 73.67%). Further increasing K to 10 yields no additional gain in answer accuracy while only marginally improving grounding, indicating diminishing returns beyond K=5.

The authors use a multi-agent framework with grounding and vision modules to enhance long-form video QA, showing consistent accuracy gains over non-agent baselines across both closed-source and open-source LLMs. Results show that adding agentic components improves performance even when using the same backbone, with reinforcement learning further boosting open-source models like Qwen2.5-7B to near-parity with closed-source counterparts. The largest gains occur when combining multi-agent orchestration with frame-level visual input, particularly on LongTVQA+.
The authors compare two vision models within their multi-agent framework, finding that GPT-4o outperforms Qwen3-VL-235B in both grounding accuracy (73.30% vs. 71.00%) and overall answer accuracy (78.00% vs. 73.67%). Results show that stronger visual recognition capabilities in the vision agent directly contribute to higher end-task performance in long-form video QA.

The authors evaluate the effect of expanding the temporal evidence window size on grounding and answer accuracy. Results show that increasing the window from 1 to 3 clips improves grounding accuracy from 71.67% to 81.94% and answer accuracy from 70.33% to 77.26%. Larger windows provide richer context for disambiguation but yield diminishing returns and higher latency.
The authors evaluate a multi-agent system against a text-only baseline using the same backbone model. Adding temporal grounding improves accuracy from 64.3% to 69.0%, and further incorporating a vision agent raises it to 74.8%, demonstrating that agentic collaboration enhances reasoning by localizing relevant clips and extracting visual evidence. These gains are attributed to the structured use of tools rather than changes in the base model or prompts.
