Command Palette
Search for a command to run...
WorldWarp: انتشار الهندسة ثلاثية الأبعاد باستخدام تفتيت الفيديو غير المتزامن
WorldWarp: انتشار الهندسة ثلاثية الأبعاد باستخدام تفتيت الفيديو غير المتزامن
Hanyang Kong Xingyi Yang Xiaoxu Zheng Xinchao Wang
الملخص
تُشكّل إنشاء مقاطع فيديو طويلة المدى ومتسقة هندسيًا تحديًا جوهريًا: فبينما تتطلب التماسك التزامًا صارمًا بالهندسة ثلاثية الأبعاد في فضاء البكسل، تعمل النماذج التوليدية الرائدة بكفاءة عالية في فضاء لاتنتي مشروط بالكاميرا. يؤدي هذا الفصل بين المجالين إلى صعوبة في التعامل مع المناطق المُغطاة والمسارات المعقدة للكاميرا. ولسد هذه الفجوة، نقترح إطارًا يُدعى WorldWarp، يربط بين مُحَرِّكٍ هندسي ثلاثي الأبعاد ومحرّر توليد ثنائي الأبعاد. لضمان التماسك الهندسي، يُحافظ WorldWarp على ذاكرة هندسية ثلاثية الأبعاد حية مبنية باستخدام تقنية "البُقع الغاوسية" (3DGS). وباستخدام تحويل صريح للمحتوى التاريخي إلى زوايا جديدة، تعمل هذه الذاكرة كهيكل داعم هندسي، مما يضمن احترام كل إطار جديد للهندسة السابقة. ومع ذلك، فإن عملية التحويل الثابتة تترك دائمًا فجوات وتشوهات نتيجة التغطية. ولحل هذه المشكلة، نستخدم نموذجًا تدرجيًا فرعيًا-زمنيًا (ST-Diff) مصممًا لتحقيق هدف "الملء والتحديث". وتمثّل ابتكارنا الرئيسي خطة ضوضاء متغيرة فرعيًا-زمنيًا: حيث تتلقى المناطق الفارغة ضوضاء كاملة لتحفيز التوليد، بينما تتلقى المناطق المُحَوَّلة ضوضاء جزئية لتمكين التحسين. وبتحديث الذاكرة ثلاثية الأبعاد ديناميكيًا في كل خطوة، يحافظ WorldWarp على التماسك عبر أجزاء الفيديو. ونتيجة لذلك، يحقق أداءً متفوقًا من حيث الدقة، من خلال ضمان أن توجيه الهيكل يُدار بواسطة المنطق ثلاثي الأبعاد، بينما يُحسّن المنطق التدرجي النسيج. صفحة المشروع: https://hyokong.github.io/worldwarp-page/
One-sentence Summary
Researchers from National University of Singapore and The Hong Kong Polytechnic University propose WorldWarp, a novel view synthesis framework generating long coherent videos from a single image by coupling 3D Gaussian Splatting (3DGS) for geometric grounding with a Spatio-Temporal Diffusion (ST-Diff) model. Its key innovation is a spatio-temporal varying noise schedule that fills occlusions with full noise while refining warped content with partial noise, maintaining 3D consistency across 200-frame sequences where prior methods fail.
Key Contributions
- WorldWarp addresses the fundamental dilemma in long-range video generation where generative models operate in latent space while geometric consistency requires pixel-space 3D adherence, causing failures in occluded areas and complex trajectories by introducing a chunk-based framework that couples an online 3D geometric cache (built via Gaussian Splatting) with a 2D generative refiner to maintain structural grounding.
- The framework's core innovation is a Spatio-Temporal Diffusion (ST-Diff) model using a spatio-temporal varying noise schedule that applies full noise to blank regions for generation and partial noise to warped regions for refinement, enabling effective "fill-and-revise" of occlusions while leveraging bidirectional attention conditioned on forward-warped geometric priors.
- WorldWarp achieves state-of-the-art geometric consistency and visual fidelity on challenging view extrapolation benchmarks by dynamically updating the 3D cache at each step, preventing irreversible error propagation and demonstrating superior performance over existing methods in long-sequence generation from limited starting images.
Introduction
Novel view synthesis enables applications like virtual reality and immersive telepresence, but generating views far beyond input camera positions—view extrapolation—remains critical for interactive 3D exploration from limited images. Prior methods face significant limitations: camera pose encoding struggles with out-of-distribution trajectories and lacks 3D scene understanding, while explicit 3D spatial priors suffer from occlusions, geometric distortions, and irreversible error propagation during long sequences. The authors address this by introducing WorldWarp, which avoids error accumulation through an autoregressive pipeline using chunk-based generation. Their core innovation leverages a Spatio-Temporal Diffusion model with bidirectional attention, conditioned on forward-warped images from future camera positions as dense 2D priors, alongside an online 3D Gaussian Splatting cache that dynamically refines geometry using only recent high-fidelity outputs. This approach ensures geometric consistency and visual quality over extended camera paths where prior work fails.
Method
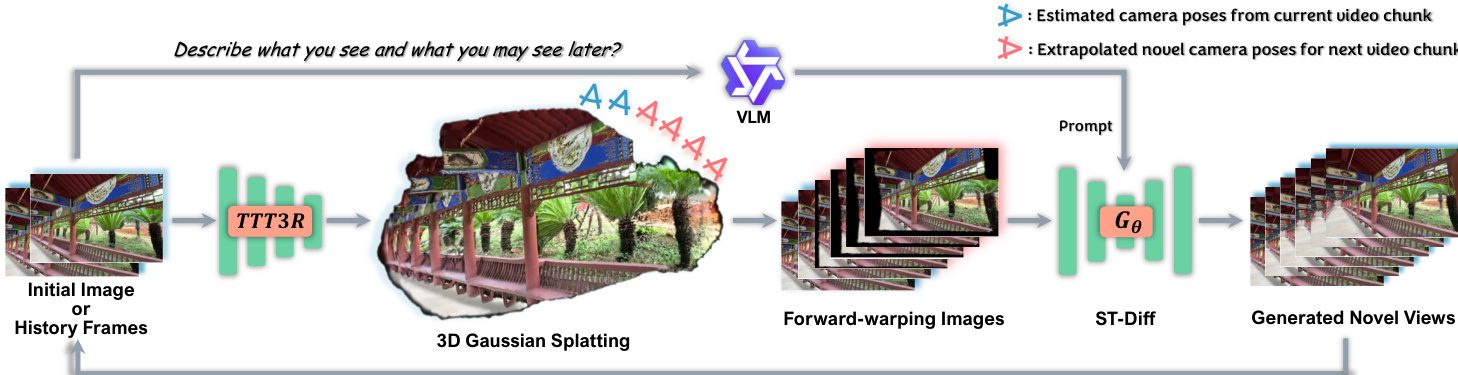
The authors leverage a dual-component architecture to achieve long-range, geometrically consistent novel view synthesis: an online 3D geometric cache for structural grounding and a non-causal Spatio-Temporal Diffusion (ST-Diff) model for texture refinement and occlusion filling. The framework operates autoregressively, generating video chunks iteratively while maintaining global 3D consistency through dynamic cache updates.
At the core of the inference pipeline is the online 3D geometric cache, initialized from either the starting image or the previously generated chunk. This cache is constructed by first estimating camera poses and an initial point cloud using TTT3R, followed by optimizing a 3D Gaussian Splatting (3DGS) representation over several hundred steps. This high-fidelity 3DGS model serves as a structural scaffold, enabling accurate forward-warping of the current history into novel viewpoints. Concurrently, a Vision-Language Model (VLM) generates a descriptive text prompt to guide semantic consistency, while novel camera poses for the next chunk are extrapolated using velocity-based linear translation and SLERP rotation interpolation.
Refer to the autoregressive inference pipeline: the forward-warped images and their corresponding validity masks, derived from the 3DGS cache, are encoded into the latent space. The ST-Diff model then initializes the reverse diffusion process from a spatially-varying noise level. For each frame, the noise map is constructed using the latent-space mask: valid (warped) regions are initialized with a reduced noise level σstart controlled by a strength parameter τ, preserving geometric structure, while occluded (blank) regions are initialized with pure noise (σfilled≈1.0) to enable generative inpainting. The model Gθ takes this mixed-noise latent sequence, the VLM prompt, and spatially-varying time embeddings as input, denoising the sequence over 50 steps to produce the next chunk of novel views. This newly generated chunk becomes the history for the next iteration, ensuring long-term coherence.
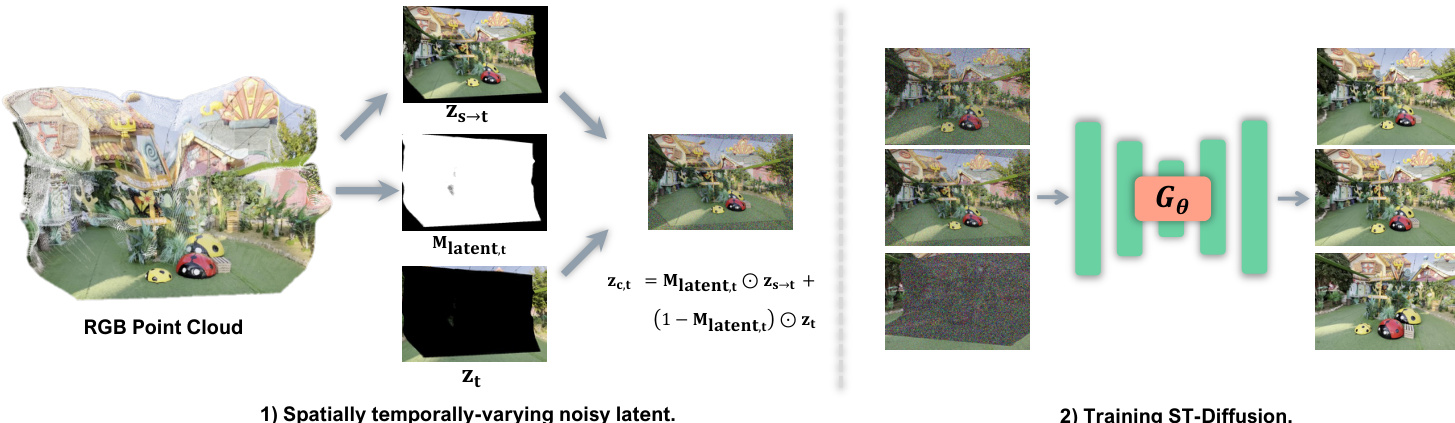
During training, the ST-Diff model is conditioned on a composite latent sequence Zc constructed from warped priors and ground-truth latents. The composite is formed by combining valid warped regions from zs→t with blank regions from zt, using the downsampled mask Mlatent,t:
zc,t=Mlatent,t⊙zs→t+(1−Mlatent,t)⊙ztThis composite sequence is then noised according to a spatio-temporally varying schedule: each frame t receives an independently sampled noise level, and within each frame, warped and filled regions receive distinct noise levels σwarped,t and σfilled,t. The resulting noisy latent sequence is fed into Gθ, which is trained to predict the target velocity ϵt−zt, forcing it to learn the flow from the noisy composite back to the ground-truth latent sequence. This training objective explicitly encodes the “fill-and-revise” behavior: generating occluded content from pure noise while refining warped content from a partially noised state.
Experiment
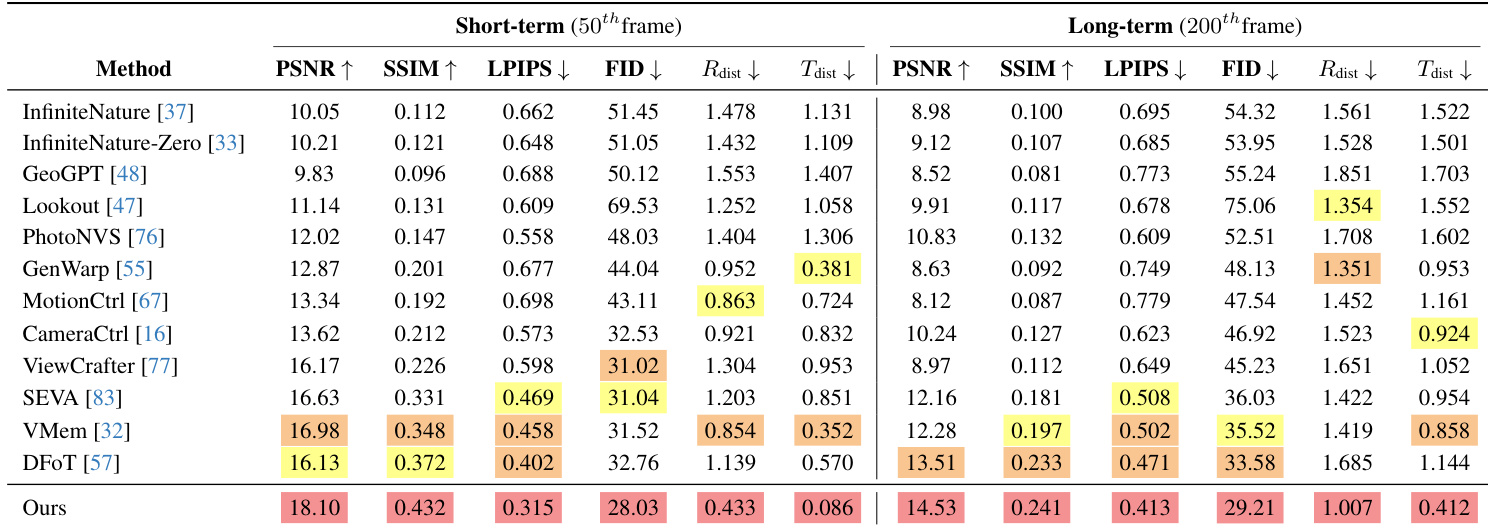
- On RealEstate10K, achieved state-of-the-art long-term synthesis (200th frame) with PSNR 17.13 and LPIPS 0.352, surpassing SEVA, VMem, and DFoT while maintaining the lowest pose errors (R_dist 0.697, T_dist 0.203), proving superior mitigation of camera drift.
- On DL3DV with complex trajectories, maintained leading performance across all metrics in long-term synthesis (PSNR 14.53, R_dist 1.007), outperforming DFoT (PSNR 13.51) and GenWarp (R_dist 1.351), demonstrating robustness in challenging scenes.
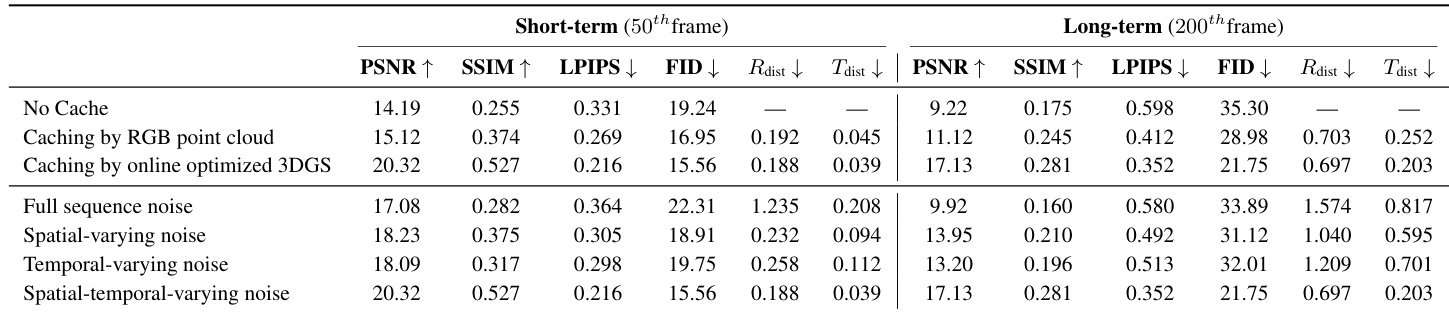
- Ablation confirmed 3DGS-based caching is critical for long-range fidelity (PSNR 17.13 vs 9.22 without cache) and spatial-temporal noise diffusion balances generation quality (PSNR 17.13) and camera accuracy (R_dist 0.697), outperforming spatial-only or temporal-only variants.
The authors evaluate ablation variants of their model on the RealEstate10K dataset, comparing caching strategies and noise diffusion designs for short-term (50th frame) and long-term (200th frame) novel view synthesis. Results show that using an online optimized 3DGS cache significantly outperforms RGB point cloud caching and no cache, especially in long-term generation, while the full spatial-temporal noise diffusion design achieves the best balance of visual quality and camera pose accuracy across both time horizons.
The authors evaluate their method on the RealEstate10K dataset, reporting superior performance across both short-term and long-term novel view synthesis metrics. Results show their approach achieves the highest PSNR and lowest LPIPS in both settings, while also maintaining the most accurate camera pose estimates with the smallest rotation and translation distances, particularly outperforming baselines in long-term stability.
The authors measure inference latency across pipeline components, showing that ST-Diff with 50 denoising steps dominates total time at 42.5 seconds, while 3D-related operations (TTT3R, 3DGS optimization, warping) collectively add only 8.5 seconds. Results confirm that geometric conditioning is computationally efficient compared to the generative backbone, which accounts for 78% of the total 54.5-second inference time per video chunk.

The authors evaluate their method on the RealEstate10K dataset, reporting superior performance across both short-term and long-term novel view synthesis metrics. Results show their approach achieves the highest PSNR and SSIM while maintaining the lowest LPIPS, FID, and camera pose errors (R_dist and T_dist), particularly excelling in long-term stability where most baselines degrade significantly. This demonstrates the effectiveness of their spatial-temporal noise diffusion strategy in preserving geometric consistency and mitigating cumulative camera drift.
