Command Palette
Search for a command to run...
QuCo-RAG: قياس عدم اليقين من مجموعة التدريب المسبق لتوليد التوليد المدعوم بالاسترجاع الديناميكي
QuCo-RAG: قياس عدم اليقين من مجموعة التدريب المسبق لتوليد التوليد المدعوم بالاسترجاع الديناميكي
Dehai Min Kailin Zhang Tongtong Wu Lu Cheng
الملخص
يحدد التوليد المدعوم بالاسترجاع الديناميكي (Dynamic Retrieval-Augmented Generation) بشكل تلقائي متى يجب استرجاع المعلومات أثناء التوليد، بهدف تقليل الظواهر الوهمية (hallucinations) في النماذج اللغوية الكبيرة (LLMs). ومع ذلك، تعتمد الطرق الحالية على إشارات داخلية للنموذج (مثل الـ logits، والانشطارية الانتروبية)، وهي في جوهرها غير موثوقة، لأن النماذج اللغوية الكبيرة غالبًا ما تكون غير مُعدَّلة بدقة، وتُظهر مستوى عالٍ من الثقة في النتائج الخاطئة. نقترح نموذج QuCo-RAG، الذي يحول الاعتماد من الثقة الذاتية إلى إحصائيات موضوعية محسوبة من بيانات التدريب المسبق. يُقيِّم منهجنا عدم اليقين عبر مرحلتين: (1) قبل التوليد، نحدد الكيانات ذات التكرار المنخفض، والتي تشير إلى فجوات المعرفة في الذيل الطويل؛ (2) أثناء التوليد، نتحقق من تكرار ظهور الكيانات معًا في مجموعة بيانات التدريب المسبق، حيث يشير عدم التكرار (صفر تكرار) غالبًا إلى خطر حدوث وهم. تعتمد كلتا المرحلتين على تقنية Infini-gram التي تتيح استعلامات بتأخير أقل من ميلي ثانية على بيانات تبلغ 4 تريليونات من الرموز، وتُفعّل عملية الاسترجاع عند ارتفاع مستوى عدم اليقين. أظهرت التجارب على مجموعات بيانات أسئلة متعددة الخطوات (multi-hop QA) أن QuCo-RAG يحقق مكاسب في الدقة المعرفية (EM) تتراوح بين 5 إلى 12 نقطة مقارنةً بالأساليب المتطورة الحالية باستخدام نماذج OLMo-2، كما يُظهر أداءً فعّالًا عند نقله إلى نماذج لا تُكشف عنها بيانات تدريبها المسبقة (مثل Llama، Qwen، GPT)، مُحسِّنًا الدقة المعرفية بنسبة تصل إلى 14 نقطة. كما تؤكد النتائج المتعلقة بالتعميم عبر المجالات، وخاصة في مجال أسئلة الطب الحيوي، متانة النموذج المقترح. هذه النتائج تُثبت أن التحقق القائم على المجموعة اللغوية (corpus-grounded verification) يُشكّل منهجًا منهجيًا وواقعيًا وغير مرتبط بنموذج معين، لتطبيق RAG الديناميكي. تم إتاحة الكود المصدر للنظام عبر الرابط التالي: https://github.com/ZhishanQ/QuCo-RAG.
One-sentence Summary
Researchers from the University of Illinois at Chicago, New York University, and Monash University propose QuCo-RAG, a dynamic RAG framework that replaces unreliable model-internal confidence signals with objective pre-training corpus statistics via Infini-gram for millisecond entity verification, achieving 5–14 point exact match gains across OLMo-2, Llama, and biomedical QA benchmarks by identifying low-frequency knowledge gaps and validating entity co-occurrence.
Key Contributions
- Existing dynamic RAG methods rely on unreliable model-internal signals like logits or entropy to trigger retrieval, which fails because large language models are ill-calibrated and often confidently generate incorrect outputs.
- QuCo-RAG replaces subjective confidence metrics with objective pre-training corpus statistics, using a two-stage approach: identifying low-frequency entities before generation and verifying entity co-occurrence during generation via millisecond-latency queries over 4 trillion tokens with Infini-gram.
- Evaluated on multi-hop QA benchmarks, QuCo-RAG achieves 5–12 point exact match gains over state-of-the-art baselines with OLMo-2 models and transfers to models with undisclosed pre-training data (Llama, Qwen, GPT), improving exact match by up to 14 points while demonstrating robustness in biomedical QA.
Introduction
Dynamic Retrieval-Augmented Generation (RAG) systems aim to reduce hallucinations in large language models (LLMs) by adaptively retrieving relevant knowledge during text generation. However, existing methods critically depend on model-internal signals like token probabilities or entropy to decide when retrieval is needed. These signals are fundamentally unreliable because LLMs are often ill-calibrated, exhibiting high confidence in incorrect outputs, which undermines hallucination detection.
The authors leverage pre-training corpus statistics instead of subjective model confidence to quantify uncertainty objectively. Their QuCo-RAG framework operates in two stages: first, it identifies low-frequency entities during pre-generation to flag long-tail knowledge gaps; second, it verifies real-time entity co-occurrence in the pre-training data during generation, where absent co-occurrence signals high hallucination risk. Both stages use Infini-gram for millisecond-scale queries over trillions of tokens to trigger retrieval. This corpus-grounded approach achieves 5–14 point exact match gains across multi-hop and biomedical QA benchmarks, works robustly across diverse LLMs including those with undisclosed pre-training data (Llama, Qwen, GPT), and establishes a model-agnostic paradigm for reliable uncertainty-aware generation.
Dataset
The authors use two primary data components in their study:
- OLMo-2 pre-training corpus: Serves as the main data source, comprising approximately 4 trillion tokens from diverse, unspecified origins. This transparent corpus enables precise entity frequency and co-occurrence analysis. It is publicly available alongside training code and recipes, supporting reproducibility.
- Triplet extractor training data: A curated set of sentence-triplet pairs where:
- Each input is a declarative sentence; outputs are knowledge triplets in (head entity, relation, tail entity) format if factual content exists.
- Tail entities prioritize named entities (persons, locations, organizations, dates) over generic descriptors for verifiability.
- Non-factual statements (e.g., reasoning conclusions starting with "Thus") yield empty outputs.
- Questions produce partial triplets (as answers are unknown), while non-factual content returns no triplets.
For model evaluation, the authors:
- Use the OLMo-2 corpus directly to train and validate their method on OLMo-2-Instruct variants (7B, 13B, 32B).
- Treat the OLMo-2 corpus as a proxy for models with undisclosed data (Llama-3-8B-Instruct, Qwen2.5-32B-Instruct, GPT-4.1, GPT-5-chat), leveraging known web-scale corpus overlaps.
- Apply no explicit cropping; instead, metadata is constructed via triplet extraction rules to filter and structure factual knowledge for retrieval.
- Process all data through the triplet extractor to isolate verifiable facts, ensuring only entity-rich, co-occurrence-validated knowledge informs retrieval.
Method
The authors leverage a corpus-grounded dynamic retrieval framework that decouples uncertainty quantification from internal model states and instead anchors it in pre-training corpus statistics. The system operates in two primary stages: pre-generation knowledge assessment and runtime claim verification, both governed by discrete binary triggers derived from lexical frequency and co-occurrence signals.
In the pre-generation phase, the system performs an initial uncertainty check before any token is generated. A lightweight entity extractor identifies key entities from the input question, and their frequencies are queried against the pre-training corpus via a high-throughput index engine. If the average entity frequency falls below a predefined threshold τentity, the system triggers retrieval using the original question as the query. The retrieved documents are then prepended to the context window to inform subsequent generation. This mechanism targets input uncertainty—cases where the question contains rare or long-tail entities that the model is unlikely to have encountered during pre-training.
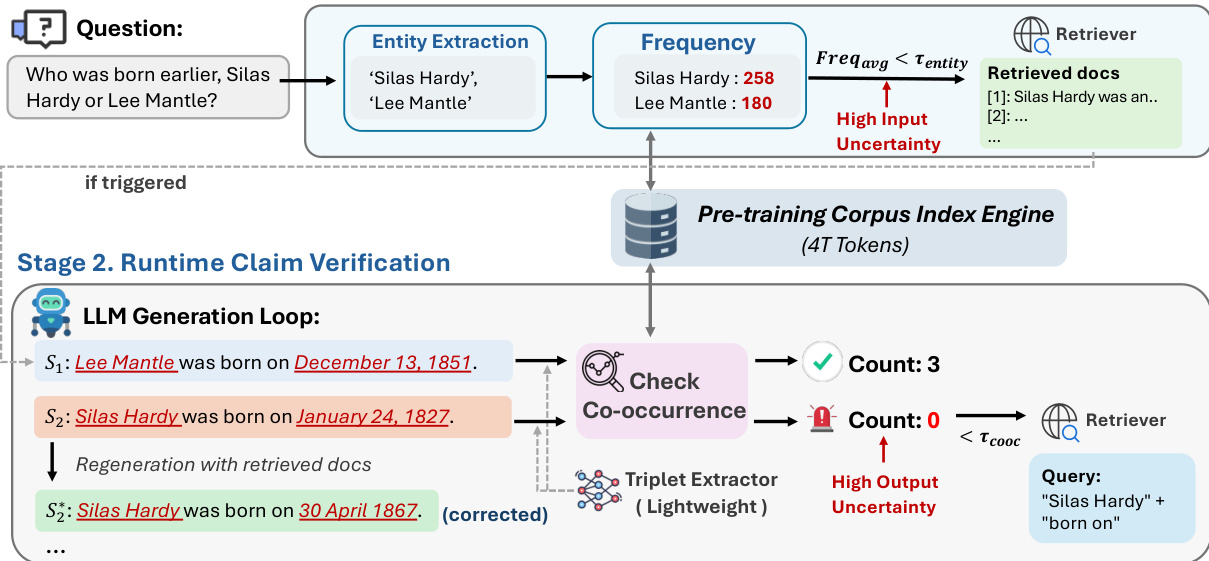
During generation, the system enters a runtime claim verification loop. After each generated sentence si, a lightweight triplet extractor parses the sentence into subject-relation-object triples (h,r,t). For each triple, the system computes the co-occurrence count of the head and tail entities within a fixed window in the pre-training corpus, defined as:
cooc(h,t;P)=∣{w∈P∣h∈w∧t∈w}∣This co-occurrence metric is preferred over full triplet matching due to the lexical variability of relational predicates. If any extracted triple exhibits a co-occurrence count below τcooc=1, the system flags the sentence as high-uncertainty and triggers retrieval. The query for retrieval is constructed by concatenating the head entity and relation (q=h⊕r), and the model regenerates the sentence using the newly retrieved context. This mechanism targets output uncertainty—claims that lack evidential grounding in the corpus and are thus likely hallucinations.
The entire pipeline is implemented with efficiency in mind. The authors employ Infini-gram, a suffix array-based indexing engine, to enable millisecond-latency corpus queries over trillion-token corpora. The triplet extractor is a distilled 0.5B parameter model fine-tuned on 40K in-context examples, ensuring low overhead without sacrificing extraction fidelity. The binary nature of the triggers—rooted in discrete corpus statistics rather than continuous confidence scores—eliminates the need for arbitrary threshold calibration and provides semantically grounded decision boundaries.
Experiment
- Evaluated on 2WikiMultihopQA and HotpotQA using OLMo-2 models (7B–32B), QuCo-RAG achieved 5–12 point Exact Match (EM) improvements over state-of-the-art baselines, e.g., +7.4 EM on 2WikiMultihopQA with OLMo-2-7B and +12.0 EM with OLMo-2-13B.
- Demonstrated cross-model transferability, yielding up to +14.1 EM on Qwen2.5-32B and +8.7 EM on GPT-5-chat for 2WikiMultihopQA using OLMo-2’s corpus as a proxy.
- Validated domain generalization on PubMedQA, achieving 66.4% accuracy with minimal overhead (0.93 retrievals/question), outperforming internal-signal methods that either over-retrieved or failed to improve.
- Maintained efficiency with only 1.70 average retrievals per question and lower token/LLM call usage than dynamic RAG baselines while maximizing EM scores.
QuCo-RAG achieves the highest accuracy (66.4%) on PubMedQA, outperforming the best baseline by 11.2 points while triggering only 0.93 retrievals per question and consuming 54.9 tokens on average. This demonstrates its ability to precisely detect hallucination risks through corpus statistics without domain-specific tuning, unlike internal-signal methods that either over-retrieve or fail to improve over no-retrieval baselines.
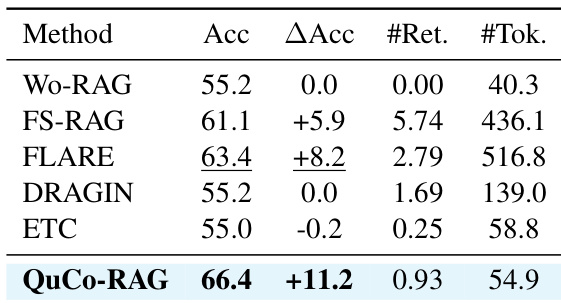
Results show QuCo-RAG consistently outperforms all baselines across entity frequency bins, with the largest gains on low-frequency entities where internal-signal methods fail to trigger effective retrieval. On the overall test set, QuCo-RAG achieves 32.7 EM, surpassing the best baseline by 9.2 points while maintaining moderate retrieval frequency. The method’s performance improves with higher entity frequency, reflecting its reliance on corpus co-occurrence statistics to reliably detect and correct hallucinations.
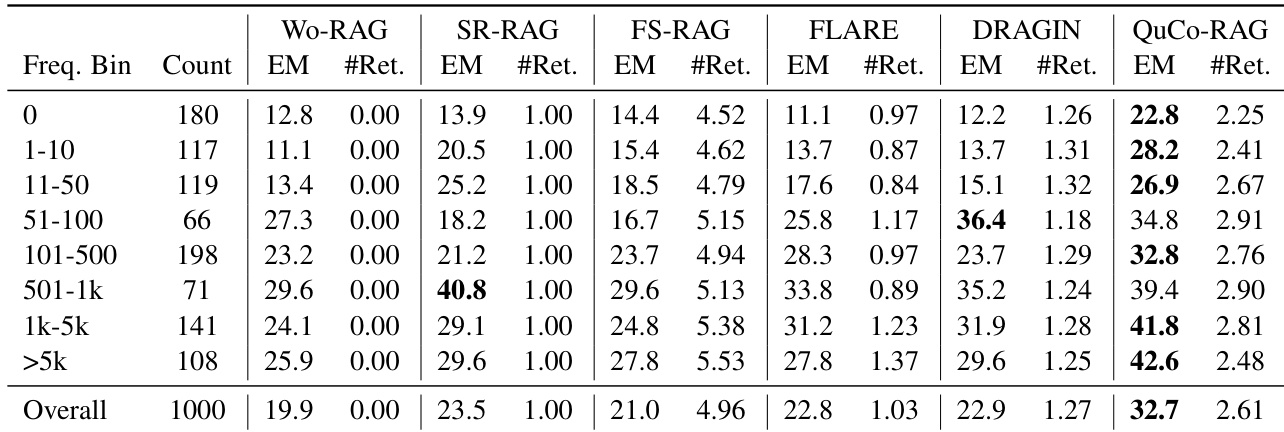
QuCo-RAG consistently outperforms all baseline methods across OLMo-2 model sizes and both multi-hop QA benchmarks, achieving gains of 5.3 to 12.0 EM points over the strongest baseline. The method’s corpus-based uncertainty quantification proves more reliable than internal-signal approaches, which show inconsistent performance and often fail to trigger retrieval on hallucinated content. Efficiency metrics confirm QuCo-RAG delivers top performance with moderate token usage and retrieval frequency.
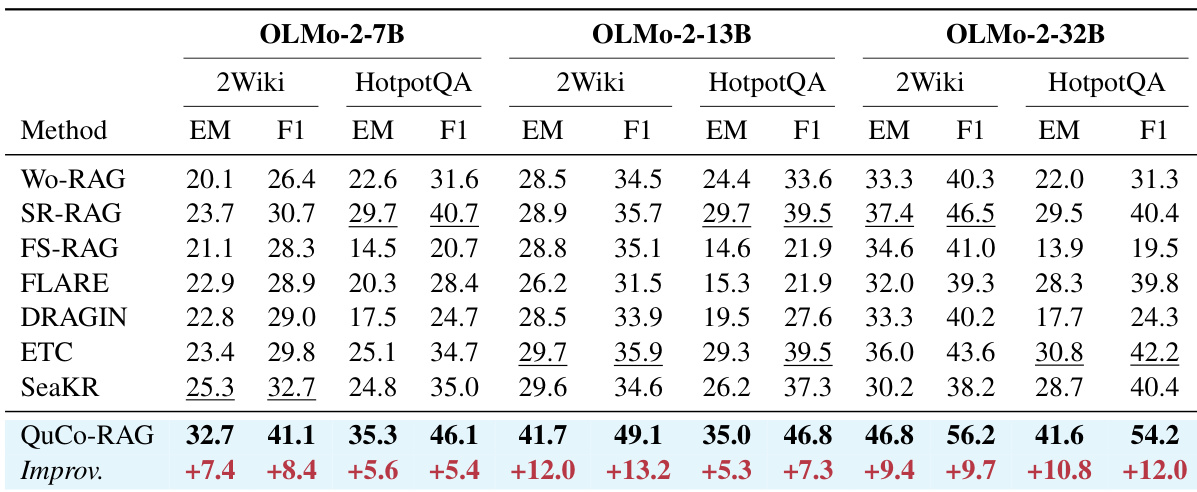
The authors use an ablation study to evaluate QuCo-RAG’s two-stage detection mechanism on 2WikiMultihopQA with OLMo-2-7B. Removing the runtime claim verification stage causes a larger performance drop (5.1 EM) than removing the pre-generation knowledge assessment (2.5 EM), indicating that co-occurrence verification is the more critical component. Even with only the initial check, QuCo-RAG outperforms SR-RAG by 3.9 EM while triggering fewer retrievals.
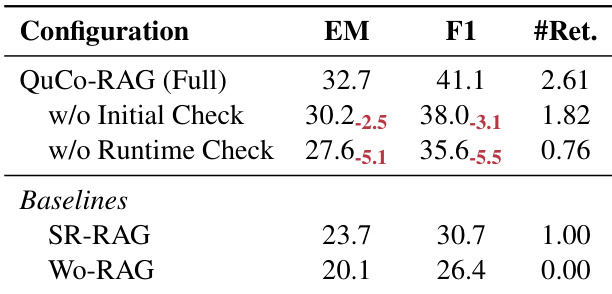
QuCo-RAG consistently outperforms all baseline methods across OLMo-2 model sizes on both 2WikiMultihopQA and HotpotQA, achieving higher Exact Match scores while maintaining moderate token usage and retrieval frequency. The method triggers fewer retrievals than dynamic baselines like FS-RAG and SeaKR, yet delivers superior accuracy, demonstrating efficient, corpus-grounded uncertainty detection. Efficiency metrics show QuCo-RAG uses fewer LLM calls and tokens than most dynamic RAG approaches, particularly at larger scales, without sacrificing performance.