Command Palette
Search for a command to run...
SAM الصوتي: التجزئة بأي شيء في الصوت
SAM الصوتي: التجزئة بأي شيء في الصوت
الملخص
إن فصل المصادر الصوتية العامة يُعدّ قدرة محورية لأنظمة الذكاء الاصطناعي متعددة الوسائط التي تستطيع إدراك الصوت والتفكير فيه. وعلى الرغم من التقدم الكبير الذي أُحرز في السنوات الأخيرة، فإن النماذج الحالية للفصل إما محددة المجال، مصممة لفئات ثابتة مثل الكلام أو الموسيقى، أو محدودة في التحكم، حيث تدعم فقط وسيلة توجيه واحدة مثل النص. في هذا العمل، نقدّم SAM Audio، نموذجًا أساسيًا للفصل الصوتي العام، يوحّد التوجيه النصي والمرئي وتمييز الفترات الزمنية ضمن إطار واحد. تم بناء SAM Audio على بنية مُحول التدفق (diffusion transformer)، وتم تدريبه باستخدام تقنية مطابقة التدفق (flow matching) على بيانات صوتية ضخمة تشمل الكلام، والموسيقى، والأصوات العامة، ويمكنه فصل المصادر المستهدفة بشكل مرن بناءً على وصف لغوي، أو أقنعة بصرية، أو فترات زمنية. يحقق النموذج أداءً متقدمًا على مستوى الحد الأقصى في مجموعة متنوعة من المعايير، بما في ذلك فصل الأصوات العامة، والكلام، والموسيقى، وأدوات موسيقية، سواء في الصوتيات الواقعية (in-the-wild) أو الصوتيات المهنية، متفوقًا بشكل كبير على الأنظمة السابقة العامة والمتخصصة. علاوةً على ذلك، نقدّم معيارًا جديدًا للفصل في البيئة الواقعية، يحتوي على توجيهات متعددة الوسائط مُعلّقة من قبل البشر، بالإضافة إلى نموذج تقييم غير مبني على مرجع (reference-free) يُظهر ارتباطًا قويًا مع التقييم البشري.
One-sentence Summary
Meta Superintelligence Labs researchers et al. propose SAM AUDIO, a foundation model for general audio separation that uniquely unifies text, visual, and temporal span prompting within a single diffusion transformer framework trained with flow matching on diverse audio data. Unlike domain-specific predecessors limited to single modalities, it achieves state-of-the-art performance across sound, speech, and music benchmarks while introducing a new real-world evaluation framework with reference-free metrics strongly correlating with human judgment.
Key Contributions
- Current text-prompted audio separation methods struggle to disambiguate target sounds in complex scenes like overlapping speech or subtle sound effects, as text descriptions alone lack temporal precision and specialized domain performance remains inferior to task-specific systems.
- The authors introduce span prompting, a novel temporal conditioning mechanism that enables precise sound event separation by specifying target time intervals directly within the mixture, eliminating the need for external reference audio or enrollment utterances.
- This approach addresses a key limitation in existing speaker extraction systems that require clean reference samples, providing flexible temporal control while maintaining content-preserving separation without altering intrinsic audio attributes like reverb.
Introduction
Audio separation is critical for applications like speech recognition and hearing aids, where isolating target sounds from mixtures enables clearer audio processing. Prior work faces key limitations: most models are constrained to fixed ontologies (e.g., supporting only 4–5 instrument stems in music separation), while text-prompted approaches struggle to disambiguate subtle sounds without reference audio and often train on unrealistic synthetic mixtures. The authors address these gaps by introducing SAM Audio, which leverages a pseudo-labeling data engine to generate realistic training samples from unlabeled audio using text prompts and rigorous multi-stage filtering. They further propose a reference-free perceptual evaluation model that better aligns with human judgments, overcoming the poor correlation of traditional metrics like SDR with real-world audio quality.
Dataset
- The authors construct SAM AUDIO using two primary data sources: a large-scale (~1M hours) medium-quality audio-video corpus and smaller high-quality audio datasets spanning speech, music, and general sound effects.
- Key subsets include:
- Fully-real music: 10,610 compositions (536 hours) with instrument stems; triplets formed by mixing instruments within compositions, rescaling stems via ±5 dB SNR offsets.
- Fully-real speech: 21,910 hours of conversational audio; triplets created from dual-speaker mixtures, with residual rescaled via ±15 dB SNR offsets.
- Synthetic mixtures: Clean music/speech mixed with noise (±15 dB SNR) from general sound pools; general sound effects combined across "in-the-wild" and professional recordings.
- Video-prompted data: Natural videos filtered via ImageBind scores (> threshold) to ensure audio-visual coherence; visual masks generated using SAM 2.
- Span-prompted data: Target sounds from HQ SFX (isolated events), with spans detected via VAD (silence threshold: -40 dBFS, min duration: 250 ms).
- For training, the authors use mixtures of real and synthetic data across all subsets, forming tuples (xmix,xtgt,xres,c) where c denotes text/video/span prompts. Fully-real data provides direct supervision, while synthetic data expands domain coverage.
- Critical processing steps include SNR-based rescaling for robustness, ImageBind filtering to exclude non-diegetic sounds in video data, and PLM-Audio for generating text prompts from sound captions. Span prompts are derived from binary VAD masks converted into time intervals.
Method
The authors leverage a unified generative framework built on a Diffusion Transformer (DiT) to perform multimodal audio source separation. The core architecture, as shown in the figure below, accepts an audio mixture and conditions the separation process on any combination of text, visual, or temporal span prompts. The model jointly generates both the target stem and a residual stem, capturing all remaining audio content, in a single forward pass.
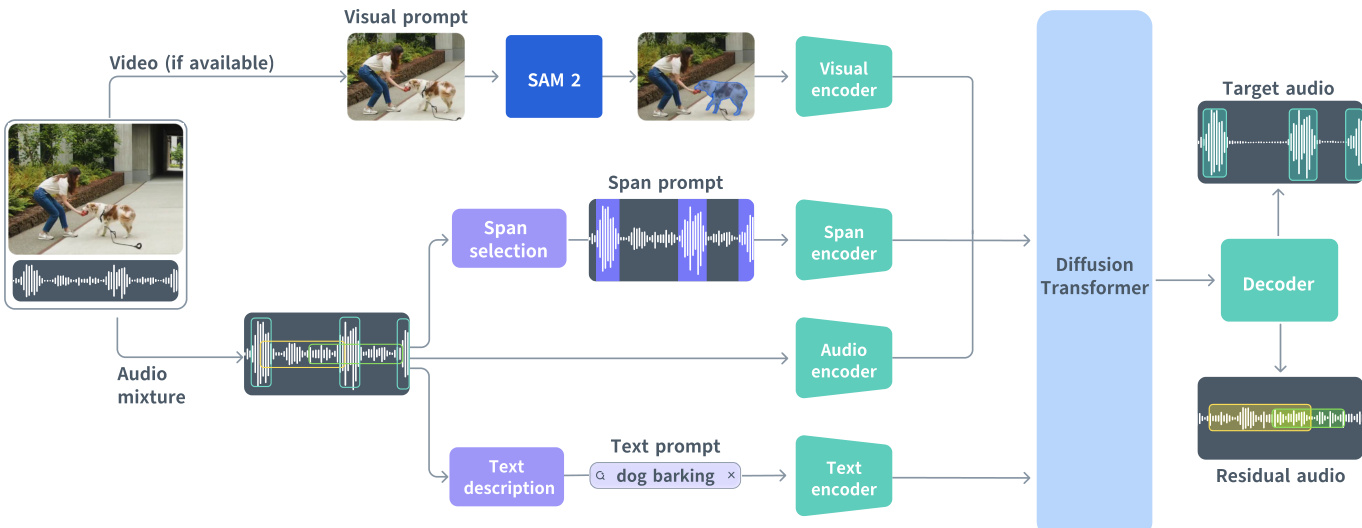
At the heart of the model is a flow-matching objective operating in the latent space of a DAC-VAE. The audio mixture is first encoded into a compact latent sequence xmix∈RT×C at 25 Hz, where C=128. The model then learns to transport a Gaussian prior x0∼N(0,I) to the joint target-residual representation x=[xtgt,xres]∈RT×2C over a continuous time variable t∈[0,1]. The DiT backbone predicts the instantaneous velocity field u(xt,c,t;θ), which is integrated to produce the final output. Each transformer block is modulated by the flow time t via scale-and-shift operations, with parameters shared across blocks to reduce model size while preserving performance.
The three prompt modalities are encoded and integrated differently. Text prompts, typically short noun-verb phrases (e.g., “dog barking”), are encoded using a frozen T5-base encoder into a global sequence of token features ctxt∈RNtxt×768, which are injected into the DiT via cross-attention layers. Visual prompts, derived from user interactions with SAM 2 on video frames, are processed by a Perception Encoder (PE) to extract frame-level features, which are resampled to match the audio frame rate and concatenated channel-wise with the audio latents. Span prompts, defined as sets of time intervals S∈Rk×2, are converted into a frame-synchronous binary token sequence indicating active or silent frames, embedded via a learnable table, and concatenated with the audio features to provide explicit temporal priors.
To handle missing modalities during training, dummy conditions are used: an empty string for text, all-zero vectors for video, and null tokens for spans. The model is further robustified by randomly dropping each prompt type with configurable probabilities during training. The training objective combines the flow-matching loss LFM with an auxiliary alignment loss Laux, which projects intermediate DiT representations into the embedding space of an external audio event detection (AED) model and minimizes the cosine distance to the ground-truth target embedding. The total loss is L=LFM+λLaux.
For long-form audio, the authors adopt a multi-diffusion strategy with overlapping windows. At each flow step, the ODE is solved independently for each window, and predictions are merged using normalized soft masks to ensure temporal coherence and avoid boundary artifacts. During inference, span prediction is enabled by default for text-only prompts, using a helper model PEA-Frame to estimate frame-level activity and generate approximate span sequences that are then combined with the original text prompt for conditioning.
Experiment
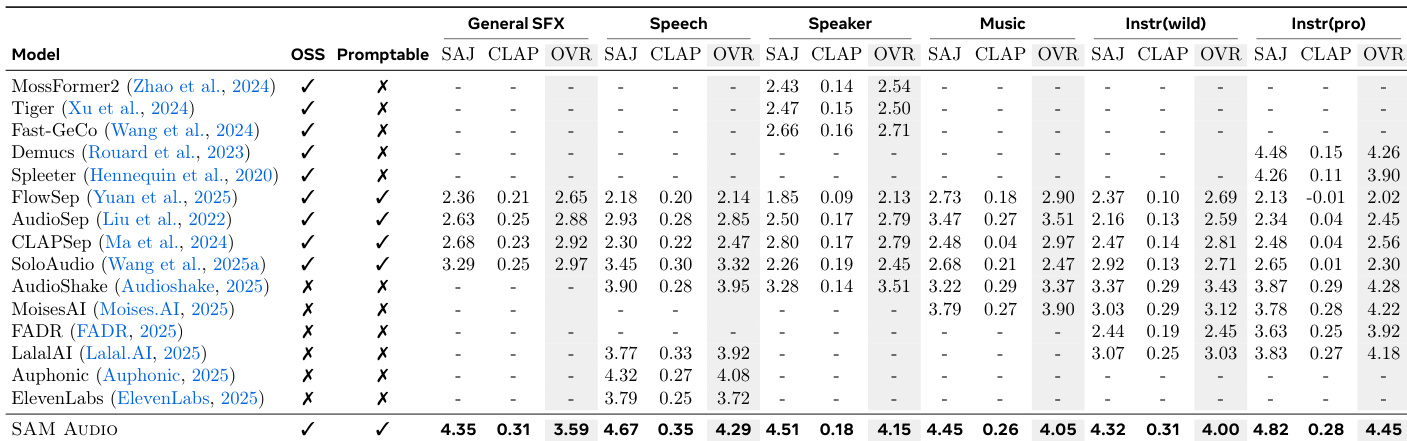
- Text-prompted separation: Achieved 4.45 OVR on MUSDB surpassing AudioShake (4.28); 36% net win rate over SoloAudio in general sound events.
- Visual-prompted separation: Outperformed DAVIS by 5-48% net win rate across tasks, with 25% improvement in speaker separation quality.
- Span-prompted separation: Combined text and span inputs increased net win rate by 12.9-39.0% over text-only conditioning.
- Music removal: Surpassed MoisesAI and AudioShake in residual audio quality for target sound suppression.
- SAJ evaluation model: Attained 0.883 Pearson correlation with human ratings for speech separation, outperforming CLAP and SDR Estimator.
- Model scaling: 3B parameter variant showed 23% net win rate gain over smaller models in instrument separation tasks.
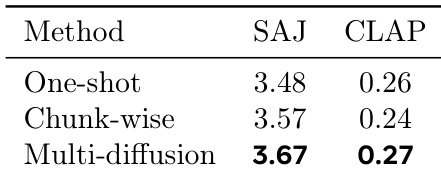
The authors evaluate three long-form separation strategies using SAJ and CLAP metrics, finding that multi-diffusion achieves the highest scores in both, indicating superior perceptual quality and semantic alignment. Results show multi-diffusion outperforms one-shot and chunk-wise methods, which suffer from degradation and discontinuities respectively.
Human ratings show that separation quality declines as task difficulty increases, with overall scores dropping from 3.716 at level 1 to 2.894 at level 4. Recall and faithfulness also degrade progressively, while precision shows the steepest decline, falling from 3.984 to 3.024 across the same levels.
The authors evaluate SAM Audio against multiple baselines across text-prompted separation tasks using objective metrics (SAJ, CLAP) and subjective overall scores (OVR). SAM Audio achieves the highest OVR scores across all categories, outperforming both general-purpose and specialized models, with particularly strong gains in speaker and professional instrument separation. Results confirm that unified training enables SAM Audio to generalize effectively and set new state-of-the-art performance.
SAM AUDIO achieves a higher overall subjective score (4.05) than both AudioShake (3.75) and MoisesAI (4.00) in text-prompted music removal tasks, indicating superior perceptual quality in suppressing target sounds while preserving residual audio.

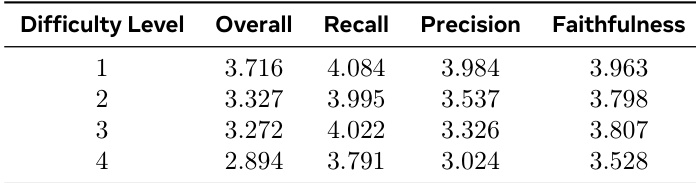
The authors evaluate SAM AUDIO using objective metrics across text and visual prompting, showing that fine-tuning with pseudo-labeled data (PL) generally improves performance. For text prompting, PL boosts SAJ scores in most tasks and enhances AES-PC scores for music and professional instrument separation, while CLAP scores remain stable. Under visual prompting, PL improves ImageBind alignment for general SFX and instrument separation, and reduces AES-PC values, indicating cleaner outputs.