Command Palette
Search for a command to run...
تنبؤ التضمين التالي يُحدث مُتعلّمين بصرية قويين
تنبؤ التضمين التالي يُحدث مُتعلّمين بصرية قويين
Sihan Xu Ziqiao Ma Wenhao Chai Xuweiyi Chen Weiyang Jin Joyce Chai Saining Xie Stella X. Yu
الملخص
مستوحاة من النجاح الذي حققته التدريب المسبق التوليدي في اللغة الطبيعية، نتساءل ما إذا كانت نفس المبادئ يمكن أن تؤدي إلى تعلم بصري ذاتي-مُدرَّب قوي. بدلًا من تدريب النماذج لإنتاج ميزات للاستخدام في المهام اللاحقة، نُدرّبها على إنتاج تمثيلات (إمبدينغز) للقيام بمهام تنبؤية مباشرة. يُستكشف في هذه الدراسة تحولٌ من تعلم التمثيلات إلى تعلم النماذج. وبشكل خاص، تتعلم النماذج توقع تمثيلات البُقع المستقبلية بناءً على البُقع السابقة، باستخدام تقنيات التمويه السببي (causal masking) وتقنية تجميد التدرج (stop gradient)، وهي ما نسميه بالانحدار التوليدي التنبؤي للإمبدينغ التالي (Next-Embedding Predictive Autoregression - NEPA). نُظهر أن نموذجًا بسيطًا من نوع Transformer، تم تدريبه مسبقًا على ImageNet-1k باستخدام التوقع التالي للإمبدينغ كهدف تعليمي وحيد، يكون فعّالًا جدًا — دون الحاجة إلى إعادة بناء البكسلات، أو استخدام رموز منفصلة، أو خسارة تقابلية، أو رؤوس مخصصة للمهام. يحافظ هذا النموذج على بساطة البنية المعمارية وقابلية التوسع، دون الحاجة إلى تعقيدات تصميم إضافية. تحقق NEPA نتائج قوية عبر مجموعة متنوعة من المهام، حيث تصل دقة التصنيف الأولية (top-1 accuracy) إلى 83.8% و85.3% على ImageNet-1K باستخدام نماذج ViT-B وViT-L على التوالي بعد التحسين الدقيق، كما تُظهر قدرة فعّالة على التحويل إلى مهام التصنيف الدلالي (semantic segmentation) على مجموعة ADE20K. نعتقد أن التدريب المسبق التوليدي من خلال التمثيلات يُقدّم بديلاً بسيطًا وقابلًا للتوسع، وربما عامًا بحقول المُدخلات (modality-agnostic)، للتعلم الذاتي البصري.
One-sentence Summary
Researchers from University of Michigan, New York University, and others propose NEPA, a generative pretraining framework that shifts from representation learning to direct predictive modeling by autoregressively predicting future patch embeddings using causal masking and stop gradients. This approach eliminates pixel reconstruction, discrete tokens, and contrastive losses, achieving 85.3% ImageNet-1K accuracy with ViT-L and effective transfer to semantic segmentation on ADE20K.
Key Contributions
- Current visual self-supervised learning approaches typically separate representation learning from task execution, requiring additional components like contrastive losses, pixel reconstruction, or task-specific heads despite advances in generative pretraining for language.
- The authors introduce Next-Embedding Predictive Autoregression (NEPA), a method that trains Transformers to directly predict future patch embeddings from past ones using causal masking and stop gradients as the sole pretraining objective, eliminating the need for discrete tokens, decoders, or auxiliary losses.
- NEPA achieves 83.8% and 85.3% top-1 accuracy on ImageNet-1K after fine-tuning with ViT-B and ViT-L backbones respectively, and demonstrates effective transfer to semantic segmentation on ADE20K, using only ImageNet-1k pretraining without pixel-level reconstruction.
Introduction
The authors explore whether generative pretraining principles from language modeling can create strong self-supervised visual learners, addressing the gap where vision models lag behind language in leveraging autoregressive prediction. Prior visual self-supervised methods face trade-offs: contrastive approaches require large batches or memory banks, pixel reconstruction struggles with scalability and weak semantics, and even representation-prediction frameworks like JEPA remain representation-centric, needing separate downstream heads instead of directly using prediction for tasks. The authors introduce Next-Embedding Predictive Autoregression (NEPA), which trains a simple Transformer to predict future patch embeddings from past ones using causal masking and stop gradients, operating solely in the embedding space without pixel reconstruction, discrete tokenizers, or auxiliary components. This approach achieves competitive ImageNet-1K accuracy (83.8% with ViT-B) and effective transfer to segmentation while offering architectural simplicity and potential modality-agnostic applicability.
Dataset
The authors use two primary datasets in their experiments:
- ImageNet-1k (ILSVRC): Accessed via Hugging Face
datasets; serves as the core dataset for ImageNet classification experiments. - ADE20K: Processed using standard pipelines from
mmsegmentationfor segmentation tasks.
Key details:
- No subset sizes, filtering rules, or composition specifics are provided for either dataset in the implementation section.
- ImageNet-1k is explicitly sourced through Hugging Face, while ADE20K adheres to established
mmsegmentationpreprocessing.
Data usage and processing:
- The training split and mixture ratios are not detailed in the provided text.
- Data augmentation employs
timmutilities, specificallyMixupandcreate_transform, for all ImageNet experiments. - No cropping strategies or custom metadata construction are described; ADE20K follows default
mmsegmentationrecipes.
The paper focuses on implementation infrastructure (e.g., Hugging Face transformers, timm), with dataset handling relying on these libraries' native pipelines.
Method
The authors leverage a minimalist autoregressive framework for visual pretraining, termed Next-Embedding Predictive Autoregression (NEPA), which mirrors the causal prediction paradigm of language models but operates entirely in continuous embedding space. The core idea is to train a model to predict the next patch embedding given all preceding ones, without relying on pixel reconstruction, discrete tokenization, or contrastive mechanisms.
The process begins by decomposing an input image x into T non-overlapping patches, each mapped to a continuous embedding via a shared encoder f, yielding a sequence z={z1,z2,…,zT}. An autoregressive predictor hθ is then trained to model the conditional distribution of the next embedding:
zt+1=hθ(z<t).This formulation avoids the need for a separate decoder or momentum encoder, reducing architectural complexity while preserving the causal structure of prediction.
To stabilize training and prevent collapse, the authors adopt a similarity-based loss inspired by SimSiam. The predicted embedding zt+1 is compared to the target zt+1, which is detached from the gradient graph. Both vectors are L2-normalized, and the loss is computed as the negative cosine similarity:
D(z,z)=−T−11t=1∑T−1(∥zt+1∥2zt+1⋅∥zt+1∥2zt+1),with the final loss defined as L=D(stopgrad(z),z). This objective encourages semantic alignment without requiring explicit reconstruction.
Refer to the framework diagram, which illustrates the autoregressive prediction mechanism: given a sequence of embedded patches, the model predicts the next embedding based on all prior context, with the target patch highlighted for clarity.
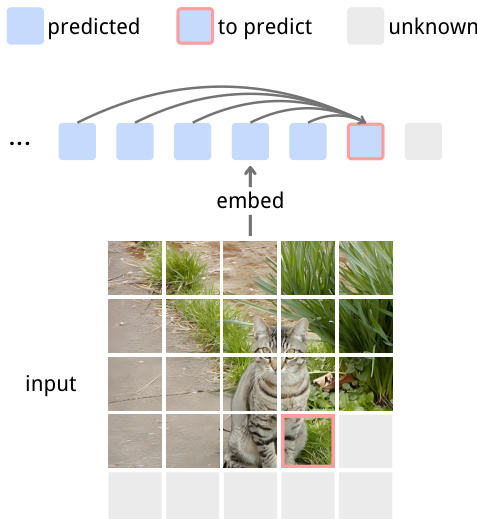
The model architecture is built upon a standard Vision Transformer backbone with causal attention masking, enabling direct prediction of future embeddings from past ones. Images are tokenized via a Conv2d patch embedder, with learnable positional embeddings added before feeding into the transformer. The authors incorporate modern stabilization techniques to improve training dynamics and scalability, including RoPE for relative positional encoding, LayerScale for residual branch stabilization, SwiGLU as the activation function in feed-forward layers, and QK-Norm to mitigate attention instability. These components are applied uniformly across all layers, as shown in the architectural diagram.
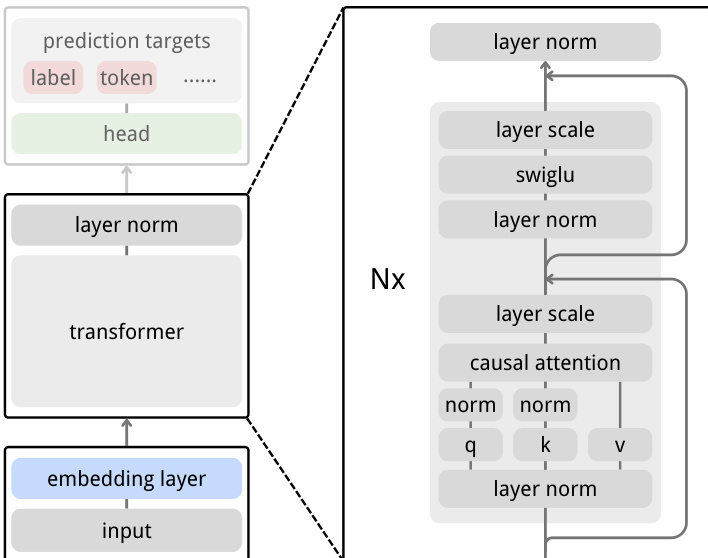
In contrast to JEPA, which employs asymmetric encoders and a dedicated scoring head, NEPA simplifies the design to a single embedding layer and an autoregressive transformer predictor. This architectural streamlining retains the latent prediction goal while eliminating auxiliary branches and heads, as depicted in the comparative diagram.

Experiment
- Ablated core algorithm components: Causal masking achieved 76.8% top-1 accuracy on ImageNet-1K after 50k pretraining steps, surpassing bidirectional attention (73.6%); stop-gradient prevented representation collapse; autoregressive shifting was essential for convergence.
- Evaluated architectural components: RoPE significantly boosted top-1 accuracy; LayerScale stabilized pretraining but required patch embedding freezing during fine-tuning to mitigate slight accuracy degradation; QK-Norm enabled stable training with SwiGLU.
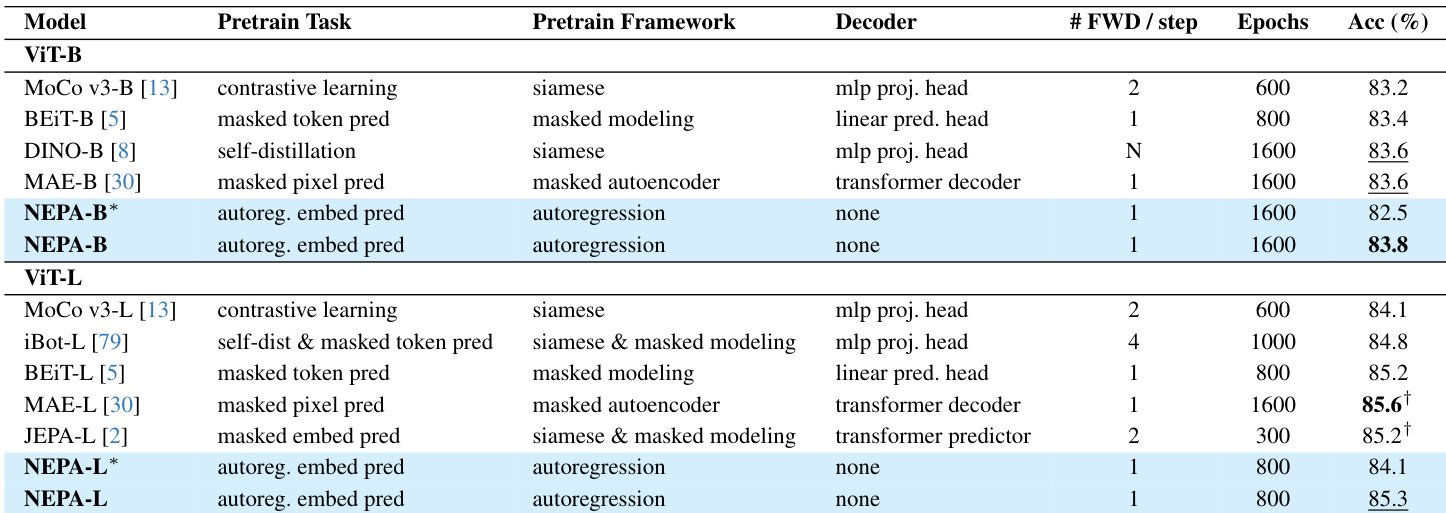
- Achieved 83.8% top-1 accuracy on ImageNet-1K classification with Base model and 85.3% with Large model, competitive with MAE and BEiT without task-specific heads or reconstruction targets.
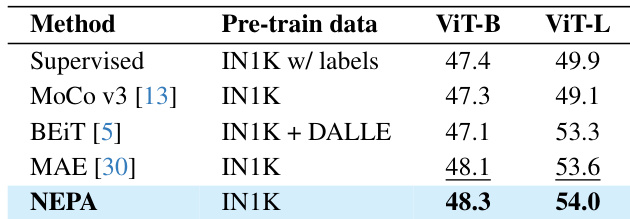
- Attained 48.3% mIoU on ADE20K semantic segmentation for Base model and 54.0% for Large model using UPerNet head, demonstrating effective transfer to dense prediction tasks from embedding-level pretraining.
- Attention analysis revealed long-range, object-centric patterns where queries attended to semantically related regions; embedding similarity maps showed high correlation within object parts, confirming semantic organization without explicit supervision.
The authors use an autoregressive next-embedding prediction framework without any decoder or auxiliary loss, achieving 83.8% top-1 accuracy on ImageNet-1K for the Base model and 85.3% for the Large model. Results show that NEPA matches or exceeds prior methods like MAE and BEiT despite using only a single forward pass and no reconstruction target. The model’s performance improves with architectural enhancements such as RoPE and QK-Norm, and it transfers effectively to downstream tasks without task-specific heads.
The authors evaluate the impact of layer-wise learning rate decay schedules during fine-tuning, finding that linearly increasing the decay from 0.35 to 1.00 improves top-1 accuracy from 83.0% to 83.8% compared to using a fixed decay of 0.65. This adaptive schedule reduces overfitting by gradually unfreezing deeper layers, allowing more stable convergence.

The authors evaluate the effect of random input embedding masking on pretraining performance, finding that increasing the masking ratio degrades top-1 accuracy after 100k steps: 0% masking yields 78.2%, 40% yields 76.4%, and 60% yields 75.7%. This indicates that, unlike in pixel-level masked modeling, random masking at the embedding level disrupts the autoregressive prediction signal and is not beneficial for their framework.

The authors evaluate NEPA on semantic segmentation using ADE20K with a UPerNet decoder, reporting mIoU scores of 48.3 for ViT-B and 54.0 for ViT-L after pretraining on ImageNet-1K. Results show NEPA outperforms supervised and contrastive baselines like MoCo v3 and BEiT, and matches or exceeds MAE despite using no pixel reconstruction or auxiliary losses. The strong performance confirms that next-embedding prediction alone enables effective transfer to dense prediction tasks.
The authors evaluate the impact of adding LayerScale, RoPE, and QK-Norm to a MAE baseline, finding that these components yield no measurable improvement in top-1 accuracy under this setup. Results indicate that MAE’s masked reconstruction objective is less sensitive to these architectural enhancements, which are more effective in autoregressive frameworks like NEPA.
