Command Palette
Search for a command to run...
OPENTOUCH: جلب اللمس الكامل لليد إلى التفاعل في العالم الحقيقي
OPENTOUCH: جلب اللمس الكامل لليد إلى التفاعل في العالم الحقيقي
الملخص
اليد البشرية تمثل وسيلة التفاعل الأساسية مع العالم المادي، ومع ذلك فإن الإدراك ذاتي الرؤية نادرًا ما يدرك متى أو أين أو بقوة كم يُحدث الاتصال. إن أجهزة الاستشعار اللمسية القابلة للارتداء القوية نادرة جدًا، ولا توجد حتى الآن مجموعات بيانات متاحة في البيئة الطبيعية (in-the-wild) تُزامن بين مقاطع الفيديو من منظور الشخص الأول وبيانات اللمس الكاملة لليد. ولسد الفجوة بين الإدراك البصري والتفاعل المادي، نقدّم "OpenTouch"، أول مجموعة بيانات لمسية شاملة لليد من منظور الشخص الأول في البيئة الطبيعية، تتضمن 5.1 ساعات من البيانات المزامنة بين الفيديو واللمس والوضعية، و2900 لقطة مُختارة بدقة مع تعليقات نصية تفصيلية. وباستخدام OpenTouch، نقدّم معايير استرجاع وتصنيف تُختبر بها كيفية تأسيس اللمس للإدراك والسلوك. ونُظهر أن الإشارات اللمسية توفر مؤشرًا مكثفًا وقويًا لفهم القبضة، وتعزز التزامن بين الوسائط المختلفة، ويمكن استرجاعها بشكل موثوق من استعلامات فيديو في البيئة الطبيعية. وبإطلاق هذه المجموعة المُعلّقة من البيانات البصرية-اللمسية-الوضعية، ومقاييس الأداء، نهدف إلى تعزيز الإدراك ذاتي الرؤية متعدد الوسائط، والتعلم الجسدي، وتشغيل الروبوتات الغنية بالاتصال المادي.
One-sentence Summary
Researchers from MIT, Harvard, Duke et al. introduce OPENTouch, the first in-the-wild dataset with synchronized egocentric video, force-aware full-hand tactile sensing, and hand-pose trajectories. Unlike prior lab-based datasets, it captures natural contact forces indistinguishable from vision alone, providing 5.1 hours of interaction data and benchmarks to advance multimodal perception and contact-rich robotic manipulation through tactile-grounded retrieval and classification.
Key Contributions
- OPENTouch addresses the critical lack of in-the-wild egocentric datasets aligning first-person video with full-hand tactile contact and pose, introducing the first such resource with 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips featuring detailed text annotations.
- The work establishes novel cross-sensory retrieval and tactile pattern classification benchmarks, specifically hand action recognition and grip type recognition tasks, to rigorously evaluate how tactile signals disambiguate interactions and strengthen cross-modal alignment for grasp understanding.
- A custom thin, low-cost, open-source tactile glove using FPCB technology enables this dataset, providing uniform 169-sensor coverage across the palmar hand surface through automated electrode routing on piezoresistive film for stable, high-resolution pressure mapping in everyday environments.
Introduction
The authors address the challenge of integrating tactile sensing with vision and pose data for robotic manipulation, where touch provides critical disambiguation for actions and grasps that visual data alone cannot resolve. Existing tactile encoding approaches focus narrowly on either piezoresistive sensor signals via lightweight CNNs or tactile images via pretrained ResNets, lacking standardized multimodal benchmarks to evaluate how touch specifically enhances action and grasp understanding. Their contribution introduces two novel tactile pattern classification tasks—hand action recognition and grip type recognition—that jointly leverage egocentric video, tactile signals, and hand pose, establishing clear metrics and data splits to quantify touch's role in disambiguating interactions for applications like robot policy learning.
Dataset
The authors use OpenTouch, the first in-the-wild egocentric dataset capturing synchronized full-hand tactile signals, egocentric video, and hand-pose trajectories. Key details:
-
Composition and sources:
- 5.1 total hours of recordings from 14 everyday environments (e.g., workshops, kitchens), featuring over 8,000 objects across 14 categories.
- Sources include Meta Aria glasses (1408×1408 RGB video at 30 Hz), Rokoko Smartgloves (hand pose via IMU/EMF sensors at 30 Hz), and a custom FPC-based tactile glove (force-aware full-hand touch).
- Includes 2,900 human-reviewed clips (≈3 hours) with dense annotations, plus head motion, eye tracking, and audio.
-
Subset details:
- Annotated clips (2,900): Filtered for contact-rich interactions. Labeled via GPT-5 using three pressure-sampled frames per clip (approach, peak force, release), verified by humans (90% accuracy). Labels cover object name/category, environment, action, grasp type (29 from GRASP taxonomy), and natural-language descriptions.
- Raw recordings (5.1 hours): Unscripted interactions; only the dominant hand is instrumented, with left-hand data generalized via mirroring.
-
Data usage in the paper:
- Training focuses on cross-sensory retrieval (e.g., video→tactile) and tactile grasp classification benchmarks.
- Modalities are mixed in tri-modal combinations (video, pose, tactile), with ablations testing temporal window sizes (e.g., 2-second windows) and tactile discretization.
- The 2,900 annotated clips form the core benchmark; raw data supports tactile retrieval from in-the-wild video (e.g., Ego4D).
-
Processing details:
- Synchronization: Hardware-aligned at 30 Hz with <2 ms latency via ESP-NOW wireless transmission and zero-potential readout circuits.
- Tactile maps are aggregated per grasp type to validate spatial pressure patterns.
- Metadata is constructed using LLM-generated annotations from pressure-dynamic frame sampling, avoiding full-video processing.
- No spatial cropping; temporal sampling targets critical interaction phases based on force dynamics.
Method
The authors leverage a multimodal sensing and encoding framework to capture and align egocentric visual, tactile, and hand-pose data for fine-grained human-object interaction analysis. The system begins with a capturing setup that integrates Meta Aria glasses for egocentric video, Rokoko Smartgloves for hand pose tracking, and a custom FPC-based tactile sensor embedded in a glove for full-hand pressure mapping. This hardware configuration enables synchronized acquisition of three complementary modalities, each processed through dedicated encoders to produce aligned embeddings in a shared latent space.
Refer to the framework diagram for an overview of the data pipeline. The visual encoder employs a frozen DINOv3 ViT-B/16 backbone to extract per-frame semantic features, which are temporally aggregated via mean pooling and projected into the shared embedding space. The tactile encoder treats the 16×16 pressure map sequence as a single-channel video stream, applying a three-layer CNN with 5×5 kernels and 2×2 max-pooling to extract spatial features, followed by a bidirectional GRU to model temporal dynamics. The final tactile representation is formed by concatenating forward and backward hidden states, then projected linearly. The pose encoder processes 21 3D hand landmarks per frame, applying geometric normalization to ensure translation and scale invariance, followed by a four-layer MLP and adaptive temporal average pooling to produce a compact pose embedding.
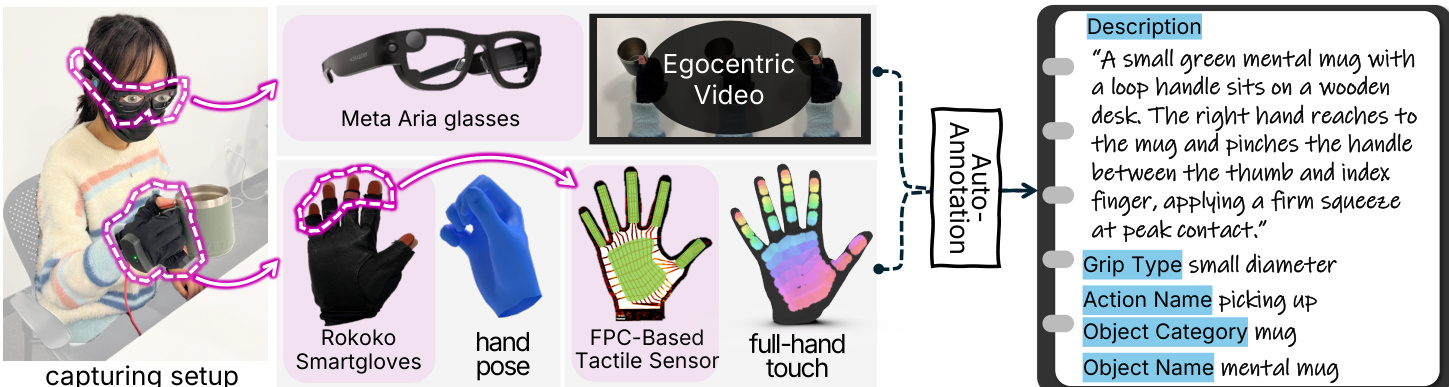
For cross-modal alignment, the authors implement both linear and deep retrieval methods. In the deep approach, embeddings from each modality are L2-normalized and projected into a 64-dimensional space. A symmetric InfoNCE loss is applied to maximize agreement between matching modality pairs (v↔t) and (t↔p), with temperature τ=0.07. For multimodal queries such as (v+p↔t), embeddings are fused via a linear head ϕ(⋅) before applying the same contrastive objective. The model is trained for 300 epochs using Adam with a cosine-annealed learning rate starting at 1×10−4 and batch size 256.
For downstream classification tasks—specifically action recognition and grasp type prediction—the authors attach lightweight linear heads atop the fused embeddings. Each classifier processes sequences of 10 frames, producing a single fused embedding passed through a fully connected layer and softmax. Training uses cross-entropy loss with Adam at 1×10−4 learning rate and batch size 64. The entire pipeline is designed to enable scalable, fine-grained annotation of hand-object interactions by combining dense tactile feedback with visual and kinematic context.
Experiment
- Cross-sensory retrieval experiments validate shared representation learning across vision, tactile, and pose modalities. On bi-modal tasks, the contrastive model achieved 7.15% Recall@1 for Video→Tactile and Tactile→Pose, surpassing linear baselines (CCA/PLSCA at ≤0.57% Recall@1) and demonstrating effective alignment of dynamic interaction cues.
- Multimodal fusion consistently improved retrieval: Video+Pose→Tactile reached 26.86% mAP, and Tactile+Vision→Pose achieved 26.86% mAP, confirming complementary information across modalities reduces ambiguity.
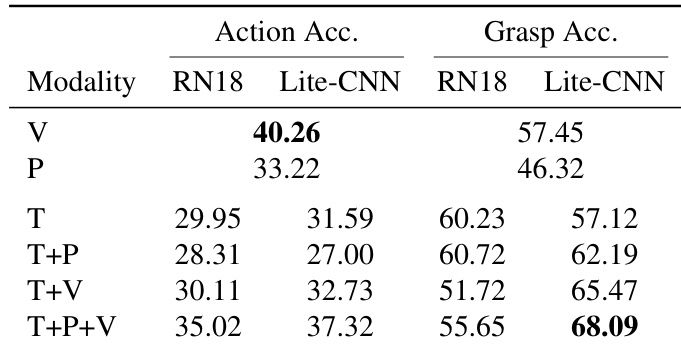
- Tactile pattern classification showed tactile inputs alone achieved 60.23% grasp accuracy, while Vision+Tactile fusion yielded optimal grasp (57.45%) and action recognition (40.26%) performance, highlighting modality-specific strengths.
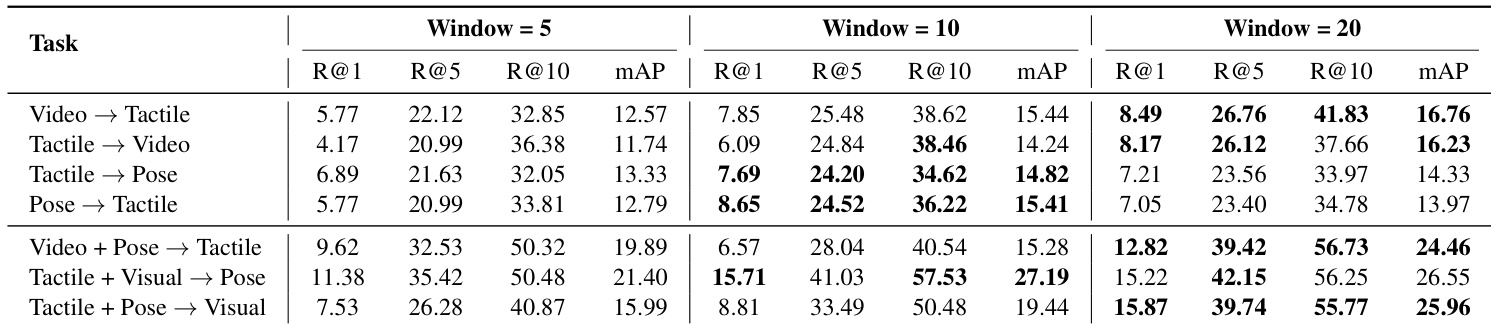
- Ablations revealed 20-frame temporal windows maximized retrieval (e.g., Video→Tactile Recall@1 rose from 5.77% to 8.49%), lightweight tactile encoders outperformed ResNet-18 by 10.49% mAP, and raw/5–7-level discretized tactile inputs provided optimal noise-robust representations.
- Zero-shot generalization to Ego4D demonstrated qualitative success in retrieving semantically consistent tactile signatures from video queries, validating cross-dataset applicability.
The authors evaluate cross-sensory retrieval performance across varying temporal window sizes and find that longer windows consistently improve results, with Window=20 yielding the highest Recall@1 and mAP across most tasks. Performance gains are especially pronounced in multimodal settings like Video+Pose→Tactile, where mAP increases from 19.89% at Window=5 to 24.46% at Window=20, indicating that modeling longer temporal dynamics enhances cross-modal alignment. The results confirm that temporal context is critical for capturing the evolving nature of tactile and visual interaction signals.
The authors evaluate action and grasp classification using different sensory modalities and encoders, finding that tactile signals alone are most informative for grasp type prediction, while combining vision, pose, and tactile cues yields the highest overall grasp accuracy. Vision alone performs reasonably well for both tasks, and adding tactile to vision consistently improves performance, especially when using the lightweight Lite-CNN encoder. The full tri-modal combination (T+P+V) with Lite-CNN achieves the best grasp accuracy at 68.09%.
The authors use a contrastive learning framework to align video, pose, and tactile modalities in a shared embedding space, enabling cross-modal retrieval. Results show that their method significantly outperforms linear baselines like CCA and PLSCA across all multimodal retrieval tasks, with Recall@1 and mAP scores improving by large margins—for example, achieving 14.08% R@1 and 26.86% mAP for video+pose→tactile retrieval. The consistent gains across all fusion directions indicate that combining modalities provides complementary information that reduces ambiguity and enhances cross-modal alignment.

The authors evaluate tactile signal discretization strategies across bi- and tri-modal retrieval tasks, comparing logarithmic, linear, and raw continuous representations. Results show that raw continuous tactile inputs consistently achieve the highest mAP across most settings, while mid-range discretization (5–7 levels) offers competitive performance, suggesting discretization can act as a useful regularizer without significantly degrading alignment. The performance trends confirm that tactile signals benefit from preserving their native continuous structure rather than being forced into coarser or transformed representations.
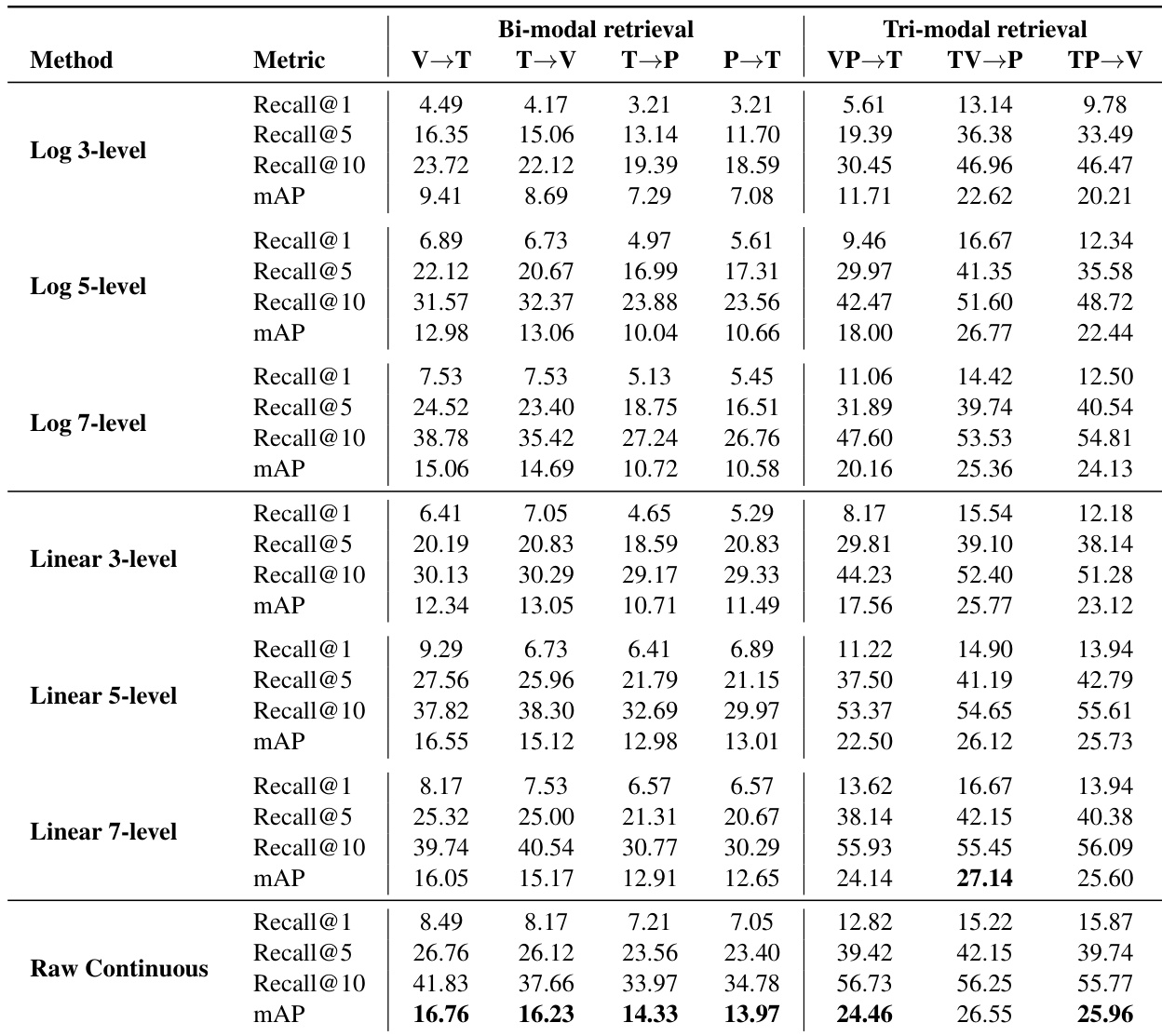
The authors use a contrastive learning framework to align video, tactile, and pose modalities in a shared embedding space, significantly outperforming linear baselines like CCA and PLSCA across all cross-modal retrieval tasks. Results show consistent gains in Recall@1, Recall@5, Recall@10, and mAP, with the largest improvements observed in tactile-to-pose and pose-to-tactile directions, indicating the model effectively captures the geometric coupling between hand motion and contact patterns. Multimodal inputs further enhance performance, demonstrating that video, pose, and tactile cues provide complementary information for robust cross-sensory alignment.
