Command Palette
Search for a command to run...
تقرير فني عن KlingAvatar 2.0
تقرير فني عن KlingAvatar 2.0
الملخص
لقد حققت نماذج توليد مقاطع الفيديو الافتراضية تقدماً ملحوظاً في السنوات الأخيرة. ومع ذلك، تُظهر الدراسات السابقة كفاءة محدودة في توليد مقاطع فيديو عالية الدقة وطويلة المدة، حيث تعاني من تدهور زمني (temporal drifting)، وانخفاض في الجودة، وضعف في اتباع التعليمات (prompt following) مع زيادة طول الفيديو. لمعالجة هذه التحديات، نقترح "KlingAvatar 2.0"، وهي إطار عمل تسلسلي فضائي-زمني (spatio-temporal cascade) يقوم بزيادة الدقة المكانية (spatial resolution) وطول الفيديو الزمني (temporal dimension) بشكل متزامن. يبدأ الإطار بتحديث إطارات الفيديو الأساسية (keyframes) ذات الدقة المنخفضة التي تلتقط المعاني الشاملة والحركة، ثم يقوم بتحسين هذه الإطارات إلى مقاطع فرعية عالية الدقة ومتماسكة زمنياً باستخدام استراتيجية الإطار الأول والإطار الأخير (first-last frame strategy)، مع الحفاظ على انتقالات زمنية سلسة في مقاطع الفيديو الطويلة. ولتعزيز دمج التوجيه عبر الوسائط (cross-modal instruction fusion) والتوافق في مقاطع الفيديو الطويلة، نقدم "مُدير التفكير المشترك" (Co-Reasoning Director) المكوّن من ثلاثة خبراء نموذج لغة كبير (LLM) مخصصين لكل وسيلة (modality). يقوم هؤلاء الخبراء بتقييم أولويات الوسائط واستخلاص النية الكامنة للمستخدم، وتحويل المدخلات إلى سيناريوهات تفصيلية من خلال حوار متعدد الدورات. كما يُضيف "مُدير السلبيات" (Negative Director) تحسيناً إضافياً على التعليمات السلبية لتحسين توافق التوجيهات. بناءً على هذه المكونات، نوسع الإطار ليدعم التحكم متعدد الشخصيات المخصص لكل هوية (ID-specific multi-character control). أظهرت التجارب الواسعة أن نموذجنا يعالج بفعالية التحديات المتعلقة بتوليد مقاطع فيديو طويلة المدة عالية الدقة بكفاءة، مع الحفاظ على التوافق المتعدد الوسائط، ويتميز بوضوح بصري محسّن، وتصوير واقعي للشفاه والأسنّة مع مزامنة شفاه دقيقة، وحفظ قوي للهوية، واتباع متماسك للتعليمات متعددة الوسائط.
One-sentence Summary
Kuaishou Technology's Kling Team proposes KlingAvatar 2.0, a spatio-temporal cascade framework generating long-duration high-resolution avatar videos by refining low-resolution blueprint keyframes via first-last frame conditioning to eliminate temporal drifting. Its Co-Reasoning Director employs multimodal LLM experts for precise cross-modal instruction alignment, enabling identity-preserving multi-character synthesis with accurate lip synchronization for applications in education, entertainment, and personalized services.
Key Contributions
- Current speech-driven avatar generation systems struggle with long-duration high-resolution videos, exhibiting temporal drifting, quality degradation, and weak prompt adherence as video length increases despite advances in general video diffusion models.
- KlingAvatar 2.0 introduces a spatio-temporal cascade framework that first generates low-resolution blueprint keyframes capturing global motion and semantics, then refines them into high-resolution sub-clips using a first-last frame strategy to ensure temporal coherence and detail preservation in extended videos.
- The Co-Reasoning Director employs three modality-specific LLM experts that collaboratively infer user intent through multi-turn dialogue, converting inputs into hierarchical storylines while refining negative prompts to enhance multimodal instruction alignment and long-form video fidelity.
Introduction
Video generation has advanced through diffusion models and DiT architectures using 3D VAEs for spatio-temporal compression, enabling high-fidelity synthesis but remaining limited to text or image prompts without audio conditioning. Prior avatar systems either rely on intermediate motion representations like landmarks or lack long-term coherence and expressive control for speech-driven digital humans. The authors address this gap by introducing KlingAvatar 2.0, which leverages multimodal large language model reasoning for hierarchical storyline planning and a spatio-temporal cascade pipeline to generate coherent, long-form audio-driven avatar videos with fine-grained expression and environmental interaction.
Method
The authors leverage a spatio-temporal cascade framework to generate long-duration, high-resolution avatar videos with precise lip synchronization and multimodal instruction alignment. The pipeline begins with a Co-Reasoning Director that processes input modalities—reference image, audio, and text—through a multi-turn dialogue among three modality-specific LLM experts. These experts jointly infer user intent, resolve semantic conflicts, and output structured global and local storylines, including positive and negative prompts that guide downstream generation. As shown in the framework diagram, the Director’s output feeds into a hierarchical diffusion cascade: first, a low-resolution Video DiT generates blueprint keyframes capturing global motion and layout; these are then upscaled by a high-resolution Video DiT to enrich spatial detail while preserving identity and composition. Subsequently, a low-resolution diffusion model expands the high-resolution keyframes into audio-synchronized sub-clips using a first-last frame conditioning strategy, augmented with blueprint context to refine motion and expression. An audio-aware interpolation module synthesizes intermediate frames to ensure temporal smoothness and lip-audio alignment. Finally, a high-resolution Video DiT performs super-resolution on the sub-clips, yielding temporally coherent, high-fidelity video segments.
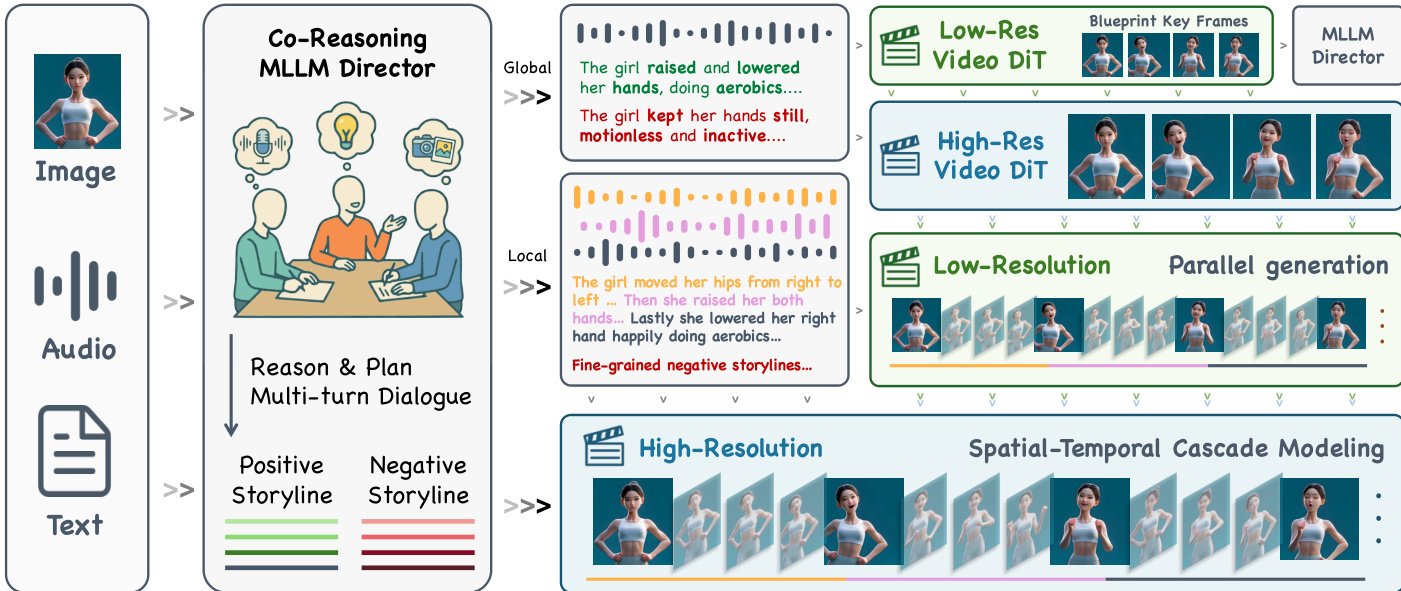
To support multi-character scenes with identity-specific audio control, the authors introduce a mask-prediction head attached to deep layers of the Human Video DiT. These deep features exhibit spatially coherent regions corresponding to individual characters, enabling precise audio injection. During inference, reference identity crops are encoded and cross-attended with video latent tokens to regress per-frame character masks, which gate the injection of character-specific audio streams into corresponding spatial regions. For training, the DiT backbone remains frozen while only the mask-prediction modules are optimized. To scale data curation, an automated annotation pipeline is deployed: YOLO detects characters in the first frame, DWPose estimates keypoints, and SAM2 segments and tracks each person across frames using bounding boxes and keypoints as prompts. The resulting masks are validated against per-frame detection and pose estimates to ensure annotation quality. As shown in the figure, this architecture enables fine-grained control over multiple characters while maintaining spatial and temporal consistency.

Experiment
- Accelerated video generation via trajectory-preserving distillation with custom time schedulers validated improved inference efficiency and generative performance, surpassing distribution matching approaches in stability and flexibility.
- Human preference evaluation on 300 diverse test cases (Chinese/English speech, singing) demonstrated superior (G+S)/(B+S) scores against HeyGen, Kling-Avatar, and OmniHuman-1.5, particularly excelling in motion expressiveness and text relevance.
- Generated videos achieved more natural hair dynamics, precise camera motion alignment (e.g., correctly folding hands per prompt), and emotionally coherent expressions, while per-shot negative prompts enhanced temporal stability versus baselines' generic artifact control.
Results show KlingAvatar 2.0 outperforms all three baselines across overall preference and most subcategories, with particularly strong gains in motion expressiveness and text relevance. The model achieves the highest scores against Kling-Avatar in motion expressiveness (2.47) and text relevance (3.73), indicating superior alignment with multimodal instructions and richer dynamic expression. Visual quality and motion quality also consistently favor KlingAvatar 2.0, though face-lip synchronization scores are closer to baselines.
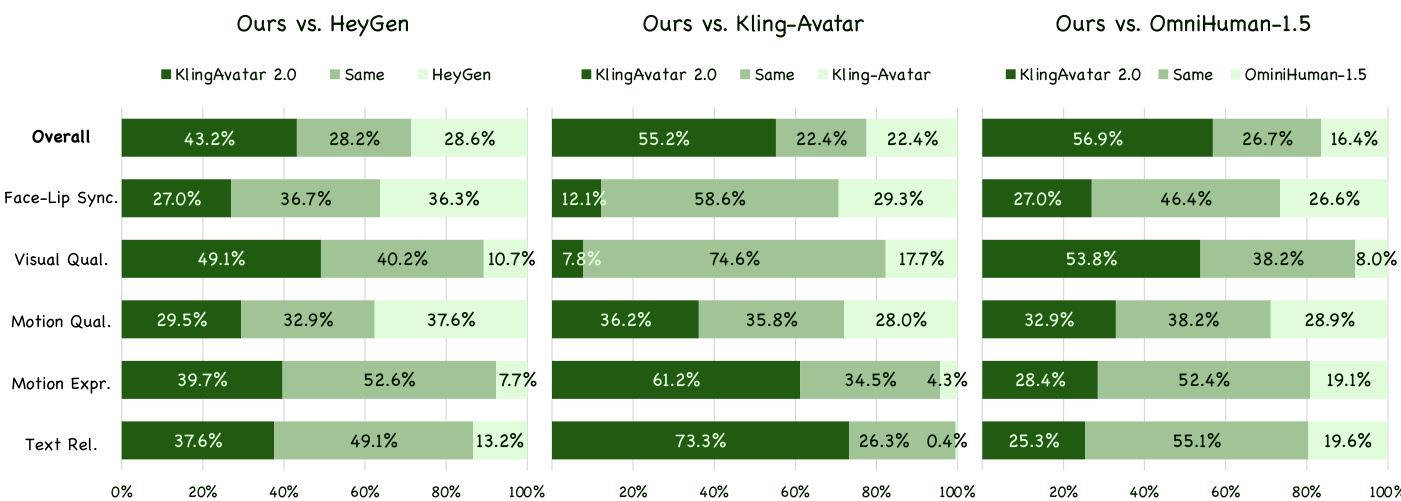
Results show KlingAvatar 2.0 outperforms all three baselines across overall preference and most subcategories, with particularly strong gains in motion expressiveness and text relevance. The model achieves the highest scores against Kling-Avatar in motion expressiveness (2.47) and text relevance (3.73), indicating superior alignment with multimodal instructions and richer dynamic expression. Visual quality and motion quality also consistently favor KlingAvatar 2.0, though face-lip synchronization scores are closer to baselines.
