Command Palette
Search for a command to run...
وكيل رمز كونفوشيوس: هياكل وكيل قابلة للتوسع لأساسات الشفرة في العالم الحقيقي
وكيل رمز كونفوشيوس: هياكل وكيل قابلة للتوسع لأساسات الشفرة في العالم الحقيقي
الملخص
تتطلب المهام الواقعية في هندسة البرمجيات وكالات برمجية قادرة على العمل داخل مخازن ضخمة من الكود، والحفاظ على جلسات طويلة الأمد، وتنسيق مجموعات معقدة من الأدوات بشكل موثوق عند وقت الاختبار. تقدم الأبحاث الحالية وكالات برمجية شفافة، لكنها تواجه صعوبات عند التوسع لدعم مهام أثقل تتماشى مع البيئات الإنتاجية، في حين أن الأنظمة الإنتاجية تحقق أداءً عمليًا قويًا، لكنها تقدم إمكانية توسيع محدودة، وشفافية محدودة، وتحكم محدود. نقدم وكالة الكود كونفوشيوس (CCA)، وهي وكالة هندسة برمجيات قادرة على العمل في مخازن كود ضخمة. تُبنى CCA على منصة SDK الخاصة بكونفوشيوس، وهي منصة لتطوير الوكالات تُنظَر إليها من خلال ثلاث زوايا مكملة: تجربة الوكالة (AX)، وتجربة المستخدم (UX)، وتجربة المطوّر (DX). تدمج المنصة منسقًا موحدًا مع ذاكرة عمل هرمية لتمكين التفكير في سياقات طويلة، ونظامًا مستمرًا لتدوين الملاحظات يدعم التعلم المستمر عبر الجلسات، ونظامًا قابلاً للتوسيع من الأدوات لضمان استخدام موثوق للأدوات. بالإضافة إلى ذلك، نقدّم وكالة فائقة (Meta-agent) تُ automate عملية تركيب وتقدير وتحسين تكوينات الوكالة من خلال دورة بناء-اختبار-تحسين، مما يمكّن من التكيف السريع مع المهام والبيئات وأكواد الأدوات الجديدة. وباستخدام هذه الآليات، تُظهر CCA أداءً قويًا في المهام الواقعية لهندسة البرمجيات. ففي اختبار SWE-Bench-Pro، حققت CCA معدل حل @1 بلغ 54.3%، متفوقةً على النماذج السابقة في الأبحاث، ومتقاربةً من النتائج التجارية، مع الحفاظ على نفس المخازن، وخلفيات النماذج، ووصول الأدوات.
One-sentence Summary
The authors from Meta and Harvard propose the Confucius Code Agent (CCA), a scalable software engineering agent built on the Confucius SDK, which integrates hierarchical working memory, adaptive context compression, persistent note-taking, and a meta-agent for automated configuration refinement; by explicitly separating Agent, User, and Developer Experience, CCA achieves state-of-the-art performance on SWE-Bench-Pro (54.3% Resolve@1) and demonstrates superior robustness in real-world debugging tasks, outperforming both research and commercial systems under identical conditions.
Key Contributions
-
Real-world software engineering demands coding agents capable of long-horizon, multi-file tasks in large codebases, yet existing systems either lack scalability (research-grade agents) or suffer from poor interpretability and extensibility (production-grade systems), creating a critical gap in agentic software engineering.
-
The Confucius Code Agent (CCA) addresses this through the Confucius SDK, which systematically separates Agent Experience (AX), User Experience (UX), and Developer Experience (DX), enabling scalable reasoning via hierarchical working memory, persistent note-taking for cross-session learning, and modular tool extensions with full observability.
-
On SWE-Bench-Pro, CCA achieves a Resolve@1 of 54.3%, outperforming prior research baselines and matching commercial systems under identical conditions, with ablation studies confirming the critical role of its meta-agent-driven configuration refinement and hierarchical memory mechanisms.
Introduction
The authors address the growing need for coding agents capable of handling large-scale, real-world software engineering tasks—such as navigating massive codebases, maintaining long-horizon workflows, and orchestrating complex toolchains—where existing systems fall short. Prior work faces a fundamental trade-off: research-grade agents offer transparency and interpretability but fail to scale to production workloads, while production systems deliver strong performance at the cost of limited extensibility, controllability, and reproducibility. The key challenges lie in sustaining long-context reasoning across dispersed code modules and enabling persistent, cross-session learning to avoid redundant effort. To overcome these, the authors introduce the Confucius Code Agent (CCA), built on the Confucius SDK, a platform structured around three distinct design axes: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK enables scalable agent behavior through a hierarchical working memory for efficient long-context reasoning, a persistent note-taking system that captures reusable insights and failure patterns, modular extensions for reliable tool integration, and a meta-agent that automates configuration synthesis and refinement via a build-test-improve loop. This principled scaffolding allows CCA to achieve a Resolve@1 of 54.3% on SWE-Bench-Pro—surpassing prior research baselines and matching commercial systems—demonstrating that effective agent design, not just model size, is critical for real-world impact.
Dataset

- The dataset is composed of real-world software engineering tasks drawn from GitHub issues and code repositories, specifically from the PyTorch and Open Library projects.
- For PyTorch-Bench, the authors collected 8 reproducible issues from the PyTorch GitHub repository between January and July 2025, selecting only those with clear reproduction scripts, detailed descriptions, and replication instructions.
- For the Open Library subset, the dataset includes project-specific and shared knowledge notes generated by an agent, organized into a hierarchical structure with directories for projects, shared utilities, and individual markdown files documenting edge cases and fixes.
- Each subset is processed to extract actionable insights: issues are filtered for reproducibility and technical clarity, while notes are structured with metadata including ID, title, description, and keywords for easy retrieval.
- The authors use the data in a training mixture where both PyTorch-Bench and Open Library tasks are combined, with balanced ratios to ensure diverse exposure to different types of software debugging challenges.
- A cropping strategy is applied by focusing only on relevant code files and test cases—such as the find_author() function and its associated test file—ensuring the agent operates on minimal, contextually sufficient input.
- Metadata is constructed for each note using standardized fields (id, title, description, keywords) to support semantic search and retrieval during agent execution.
Method
The Confucius SDK is designed around a three-axis framework that prioritizes Agent Experience (AX), User Experience (UX), and Developer Experience (DX) as interdependent and first-class design concerns. This holistic approach is reflected in the system's architecture, which separates the internal cognitive workspace of the agent from the external interfaces for users and developers. The core of the system is the Confucius Orchestrator, a minimal execution loop that manages the interaction between the large language model (LLM), the agent's memory, and external tools. The orchestrator operates in a bounded loop, invoking the LLM with a system prompt and the current memory state, parsing the model's output into structured actions, and routing these actions to the appropriate extensions for execution. This process continues until the agent signals completion or the maximum iteration limit is reached. Extensions, which are modular components that attach to the orchestrator, handle specific tasks such as parsing model outputs, executing tools, and shaping prompts. This separation allows for a clean division of responsibilities and enables the reuse of behaviors across different agents.

The framework's design philosophy is illustrated in the Confucius Core diagram, which shows the distinct channels for AX, UX, and DX. The agent's internal cognitive workspace (AX) is optimized for efficiency and minimal noise, receiving a distilled and structured version of the conversation history. In contrast, the user experience (UX) is designed for transparency and interpretability, providing rich, instrumented traces that allow users to observe and interact with the agent's behavior. The developer experience (DX) is supported by observability tools that provide insight into both the agent's reasoning (AX) and its external behavior (UX), enabling reproducibility, debugging, and rapid iteration. This separation of concerns ensures that each axis can be optimized independently without compromising the others.

A key challenge in long-running agent tasks is managing the context window of the LLM, which can be overwhelmed by the accumulation of conversation history. The Confucius SDK addresses this with an adaptive context compression mechanism. When the effective prompt length approaches configurable thresholds, a dedicated planner agent, the Code Architect, is invoked to analyze the conversation history and construct a structured summary. This summary, which explicitly preserves key information categories such as task goals, decisions made, open TODOs, and critical error traces, replaces the original large spans of history. The system maintains a rolling window of recent interactions in their original form, ensuring that the agent can sustain multi-step reasoning over long trajectories without exceeding context limits. This approach provides a more robust and semantically aware alternative to fixed-window truncation or simple retrieval methods.

The Confucius Code Agent (CCA) is a specific instantiation of the Confucius SDK, built using a meta-agent that automates the agent development process. The meta-agent operates within a build-test-improve loop, where it synthesizes agent configurations, wires together orchestrator components and extensions, evaluates candidate agents on representative tasks, and iteratively refines prompts and tool-use policies based on observed failures. This automated process allows for the rapid development of agents that are tailored to specific use cases and environments. The CCA is composed of the orchestrator, memory, and extensions, with the memory system including a hierarchical note-taking agent that turns interaction traces into structured persistent knowledge. This knowledge is stored as Markdown files in a file-system-like tree, enabling agents to retrieve and reuse information across sessions, including failure cases and known fixes. The extension system, which includes components like the Bash tool and file edit tool, provides a modular and extensible way to integrate new capabilities into the agent. The overall architecture of the CCA, as shown in the diagram, demonstrates how the Confucius SDK's components work together to create a robust and adaptable coding agent.
Experiment
- On SWE-Bench-Pro, CCA achieves 52.7% Resolve@1 with Claude 4.5 Sonnet and 54.3% with Claude 4.5 Opus, surpassing Live-SWE-Agent (45.8%) and Anthropic’s proprietary scaffold (52.0%), demonstrating that improved agentic scaffolding alone drives performance gains.
- Ablation studies show that learned tool-use via the Meta-agent contributes significantly to performance, with Resolve@1 dropping substantially when disabled, even with advanced context management intact.
- Hierarchical context management improves Resolve@1 by +6.6 points (42.0 to 48.6) on Claude 4 Sonnet, enabling deeper reasoning and reducing prompt length by over 40% without losing key information.
- CCA maintains stable performance across multi-file edit scenarios, with only moderate degradation on tasks modifying more files, indicating robustness in complex refactoring.
- Long-term memory via note-taking reduces token cost by 11k and iteration turns by 3, while improving Resolve@1 from 53% to 54.4% on repeated SWE-Bench-Pro tasks, showing effective cross-session learning.
- On SWE-Bench-Verified, CCA achieves 74.6% Resolve Rate with Claude 4 Sonnet, outperforming OpenHands and a mini-SWE-Agent variant using Claude 4.5 Sonnet, underscoring the impact of scaffolding over backbone model strength.
- Thinking budget scaling shows diminishing returns beyond 16k tokens on SWE-Bench-Verified, with no precise control over internal reasoning length due to model-level abstraction.
- Case studies on real PyTorch issues reveal CCA’s minimal, principled fixes align with eventual PyTorch team solutions, while CC’s multi-agent approach leads to over-engineered, context-fragmented solutions despite higher complexity.
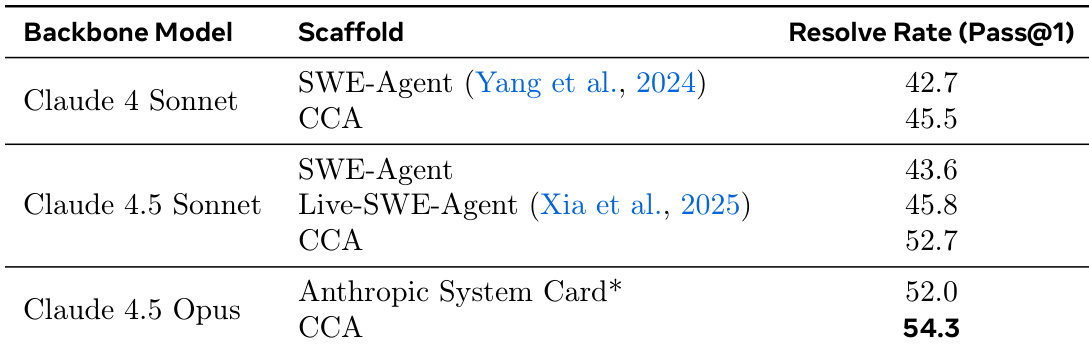
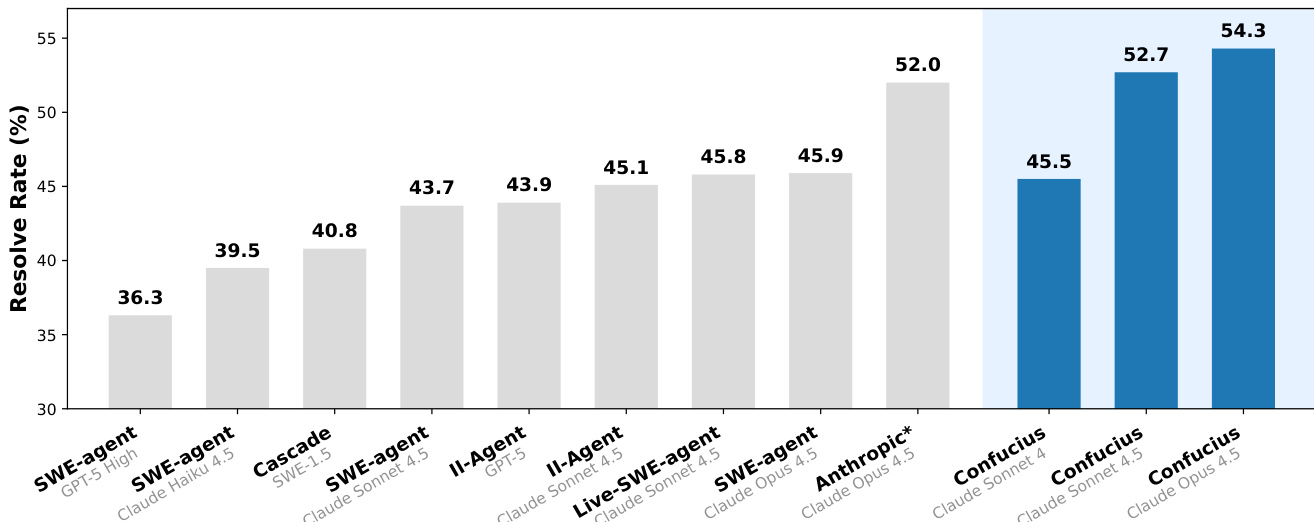
The authors use CCA, a novel agent scaffold, to achieve higher performance on SWE-Bench-Pro compared to existing baselines and proprietary systems. Results show that CCA consistently surpasses SWE-Agent and Live-SWE-Agent across different backbone models, reaching a Resolve Rate of 54.3% with Claude 4.5 Opus, outperforming the results reported by Anthropic's proprietary system.
The authors use Table 5 to compare CCA against open-source scaffolds on the SWE-Bench-Verified benchmark, showing that CCA achieves a Resolve Rate of 74.6% with Claude 4 Sonnet, outperforming the strongest open-source system, OpenHands, under identical backbone conditions. This result demonstrates that enhanced agentic scaffolding can close or surpass the performance gap introduced by differences in backbone model capability.

The authors use the SWE-Bench-Pro benchmark to compare CCA against various agent scaffolds and backbone models, showing that CCA consistently outperforms the SWE-Agent baseline across different models. With Claude 4.5 Opus, CCA achieves a Resolve@1 rate of 54.3%, surpassing both the best research-grade coding agent and the proprietary system from Anthropic, demonstrating that improvements stem from enhanced scaffolding rather than model or evaluation differences.
The authors analyze CCA's performance on SWE-Bench-Pro as a function of the number of files modified, grouping tasks into edited-file buckets. Results show that CCA maintains stable performance across different edit volumes, with the highest resolve rate of 57.8% for tasks modifying 1–2 files and a moderate decline to 44.4% for tasks modifying 10 or more files.

Results show that CCA's performance improves significantly with advanced context management and tool use. For Claude 4.5 Sonnet, enabling both advanced context management and advanced tool use increases the Resolve Rate from 44.0% to 51.6%, demonstrating the combined impact of these features.
