Command Palette
Search for a command to run...
PaddleOCR-VL: تعزيز تحليل المستندات متعددة اللغات من خلال نموذج رؤية-لغة فائق الصغر بحجم 0.9B
PaddleOCR-VL: تعزيز تحليل المستندات متعددة اللغات من خلال نموذج رؤية-لغة فائق الصغر بحجم 0.9B
الملخص
في هذا التقرير، نقترح نموذج PaddleOCR-VL، وهو نموذج متفوق في الأداء وفعال من حيث الموارد، مُصمم خصيصًا لتحليل المستندات. يُعد المكون الأساسي لهذا النموذج هو PaddleOCR-VL-0.9B، وهو نموذج بصري لغوي (VLM) مدمج وقوي، يدمج مشفرًا بصريًا ديناميكيًا من نوع NaViT مع نموذج لغوي ERNIE-4.5-0.3B، مما يمكّن من التعرف الدقيق على العناصر. ويتميز هذا النموذج المبتكر بدعمه الفعّال لـ 109 لغات، وتميّزه في التعرف على العناصر المعقدة (مثل النصوص، الجداول، الصيغ، والرسوم البيانية)، مع الحفاظ على استهلاك موارد منخفض جدًا. من خلال تقييمات شاملة على معايير عامة شائعة الاستخدام، بالإضافة إلى معايير داخلية، يحقق PaddleOCR-VL أداءً متفوقًا في تحليل المستندات على مستوى الصفحة، وفي التعرف على العناصر على مستوى العنصر. ويتفوّق بشكل ملحوظ على الحلول الحالية، ويُظهر تنافسية قوية أمام أفضل النماذج البصرية اللغوية (VLM)، مع توفير سرعة استنتاج عالية. تجعل هذه المزايا النموذج مناسبًا جدًا للتطبيق العملي في السياقات الواقعية. يمكن الوصول إلى الكود من خلال الرابط: https://github.com/PaddlePaddle/PaddleOCR
One-sentence Summary
The authors from Baidu propose PaddleOCR-VL, a resource-efficient vision-language model integrating a NaViT-style dynamic resolution encoder with ERNIE-4.5-0.3B, enabling SOTA performance in multi-language document parsing with accurate recognition of complex elements like tables and formulas, outperforming existing solutions while supporting fast inference for real-world deployment.
Key Contributions
-
PaddleOCR-VL introduces a compact yet powerful vision-language model, PaddleOCR-VL-0.9B, which combines a NaViT-style dynamic resolution visual encoder with the lightweight ERNIE-4.5-0.3B language model to enable efficient and accurate recognition of complex document elements such as text, tables, formulas, and charts, while supporting 109 languages and maintaining low resource consumption.
-
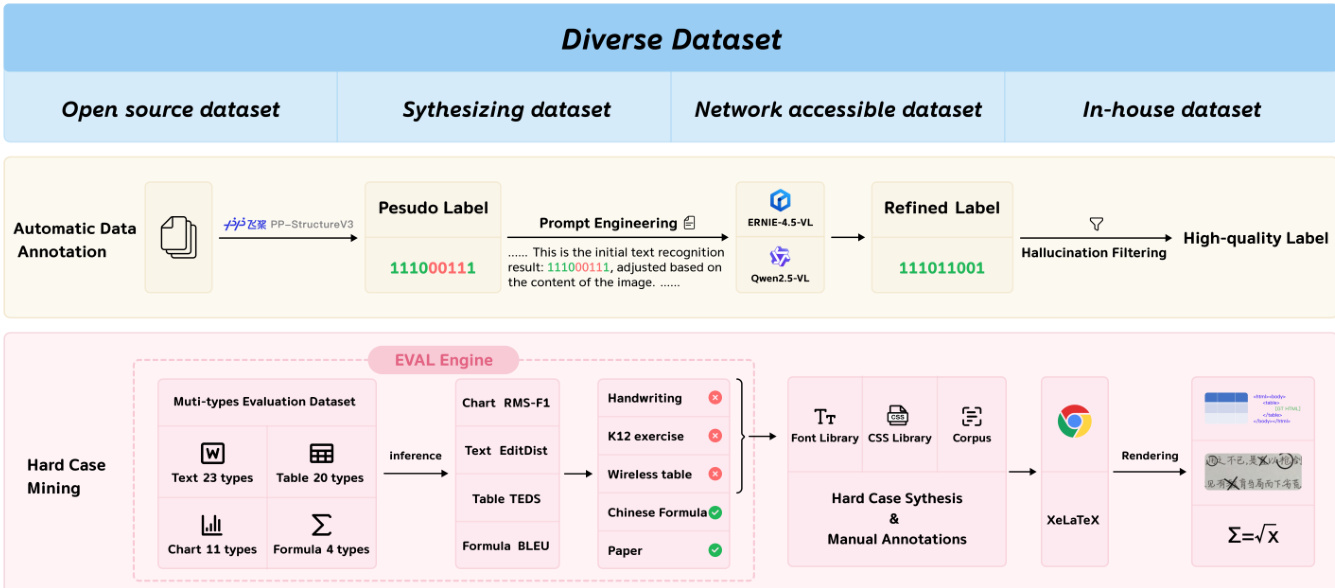
The framework employs a systematic data construction pipeline that leverages automated annotation via prompt engineering, data cleaning to eliminate hallucinations, and targeted hard case mining based on an evaluation engine, enabling the creation of high-quality training data at scale for robust multimodal document parsing.
-
PaddleOCR-VL achieves state-of-the-art performance on public benchmarks including OmniDocBench v1.0 and v1.5, as well as in-house evaluations, significantly outperforming existing pipeline-based and end-to-end methods in both page-level and element-level recognition, while delivering faster inference speeds and higher throughput across diverse hardware configurations.
Introduction
Document parsing is critical for extracting structured, semantically meaningful information from increasingly complex and multilingual documents, enabling applications in knowledge management, intelligent archiving, and supporting large language models via Retrieval-Augmented Generation (RAG). Prior approaches face key limitations: pipeline methods suffer from error propagation and integration complexity, while end-to-end vision-language models often incur high computational costs, struggle with reading order accuracy, and are prone to hallucinations on long or intricate layouts. To address these challenges, the authors introduce PaddleOCR-VL, a 0.9B ultra-compact vision-language model designed for high-performance, resource-efficient document parsing. The model combines a dynamic high-resolution visual encoder with a lightweight language backbone, enabling fast inference and strong recognition across text, tables, formulas, and charts. It leverages a novel data construction pipeline—using automated annotation via prompt engineering, data cleaning, and targeted hard case mining—to build a high-quality dataset of over 30 million samples. This approach supports robust training and enables SOTA performance on multiple benchmarks, while maintaining efficiency across diverse hardware. The system achieves state-of-the-art results in multilingual document parsing across 109 languages, including complex scripts, and is optimized for real-world deployment in production environments.
Dataset
- The dataset is built from four primary sources: open-source datasets, synthesized data, publicly accessible web data, and in-house collections, ensuring broad coverage across document types, languages, and visual styles.
- Text data comprises 20 million high-quality image-text pairs, curated from sources like CASIA-HWDB, UniMER-1M, and MathWriting, with extensive language support (109 languages) and coverage of printed, handwritten, scanned, and artistic text across academic papers, newspapers, IDs, tickets, and ancient books.
- Table data includes over 5 million image-table pairs, constructed via automatic annotation using PP-StructureV3 and ERNIE-4.5-VL, potential annotation mining from arXiv HTML sources, and high-quality synthesis using a tool that generates 10,000 samples per hour with customizable configurations for diverse table types and styles.
- Formula data exceeds 1 million samples, covering simple and complex printed, screen-captured, and handwritten formulas in both Chinese and English. It is built through source code rendering from arXiv, automatic annotation with ERNIE-4.5-VL-28B-A3B, LaTeX-based filtering, targeted synthesis of long-tail cases (e.g., vertical calculations, strikethroughs), and integration of public datasets like UniMER-1M and MathWriting.
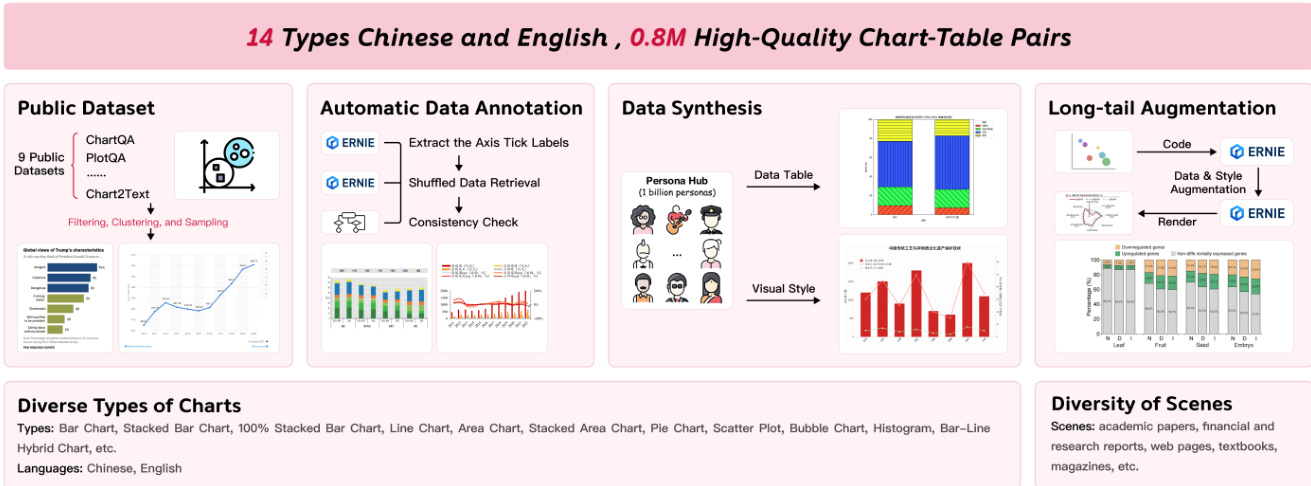
- Chart data consists of over 0.8 million bilingual (Chinese/English) image-chart pairs, derived from public datasets (ChartQA, PlotQA, Chart2Text, etc.), cleaned via a rigorous filtering pipeline, annotated using a two-stage LLM-based method, and augmented through a three-stage synthesis pipeline leveraging LLM personas and rendering tools (matplotlib, seaborn) to generate diverse visual styles.
- Hard case mining identifies model weaknesses using manually annotated evaluation sets across 23 text, 20 table, 4 formula, and 11 chart categories, followed by synthetic generation of challenging examples using font libraries, CSS, and rendering tools like XeLaTeX.
- All data undergoes multi-stage processing: automatic annotation with PP-StructureV3 and multimodal LLMs (ERNIE-4.5-VL, Qwen2.5VL), hallucination filtering, and rule-based validation (n-gram, HTML, rendering success).
- The final training data is used in a two-stage mixture strategy, with balanced ratios across text, tables, formulas, and charts, enabling the model to learn comprehensive document parsing capabilities across diverse layouts and domains.
- Metadata is constructed through hierarchical labeling (text lines, blocks, pages), structured output formats (OTSL for tables), and consistent alignment between visual content and semantic annotations.
- Cropping is applied during formula and table extraction, where regions of interest are isolated based on layout analysis before annotation or synthesis.
Method
The authors leverage a two-stage framework for document parsing, as illustrated in the overall system diagram. This architecture decouples layout analysis from fine-grained content recognition, enabling efficient and accurate processing of complex documents. The first stage, PP-DocLayoutV2, performs layout analysis by localizing and classifying semantic regions and predicting their reading order. The second stage, PaddleOCR-VL-0.9B, utilizes these layout predictions to perform detailed recognition of diverse content types, including text, tables, formulas, and charts. A lightweight post-processing module then aggregates the outputs from both stages to generate structured Markdown and JSON formats.
The layout analysis stage employs a dedicated lightweight model, PP-DocLayoutV2, to avoid the high latency and memory consumption associated with end-to-end vision-language models. This model consists of two sequentially connected networks. The first is an RT-DETR-based object detection model responsible for localizing and classifying layout elements. The detected bounding boxes and class labels are then passed to a subsequent pointer network, which predicts the reading order of the elements. This pointer network is a lightweight transformer with six layers, designed to model the relative order between detected elements. The architecture of this layout analysis model is detailed in the accompanying figure.
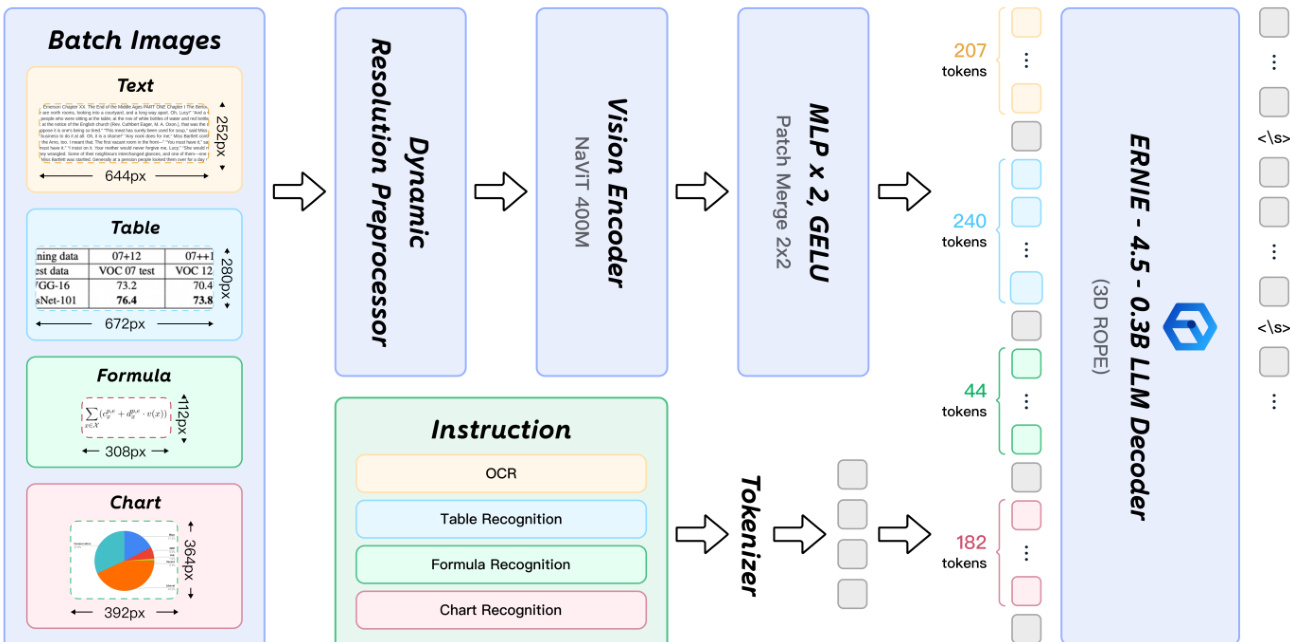
The element-level recognition stage is powered by PaddleOCR-VL-0.9B, a vision-language model inspired by the LLaVA architecture. This model integrates a pre-trained vision encoder with a dynamic resolution preprocessor, a randomly initialized 2-layer MLP projector, and a pre-trained large language model. The vision encoder is a NaViT-style model initialized from Keye-VL's vision model, which supports native-resolution inputs, allowing the model to handle images of arbitrary resolution without distortion. The projector efficiently bridges the visual features from the encoder to the language model's embedding space. The language model used is ERNIE-4.5-0.3B, a compact model chosen for its strong inference efficiency. The model's architecture is shown in the following diagram.
The training process for the two modules is distinct. For PP-DocLayoutV2, a two-stage strategy is employed. The RT-DETR model is first trained for layout detection and classification on a self-constructed dataset. Subsequently, its parameters are frozen, and the pointer network is trained independently for reading order prediction using a constant learning rate and the AdamW optimizer. For PaddleOCR-VL-0.9B, a post-adaptation strategy is used. The vision and language models are initialized with pre-trained weights. The training is divided into two stages: Stage 1 involves pre-training alignment on 29 million image-text pairs to establish a coherent understanding between visual inputs and their textual representations. Stage 2 consists of instruction fine-tuning on a curated dataset of 2.7 million samples, focusing on four specific tasks: OCR, Table Recognition, Formula Recognition, and Chart Recognition. This fine-tuning process adapts the model's general multimodal understanding to specific downstream recognition tasks.
Experiment
- Evaluated on OmniDocBench v1.5, olmOCR-Bench, and OmniDocBench v1.0 for page-level document parsing; achieved SOTA overall score of 92.86 on OmniDocBench v1.5, outperforming MinerU2.5-1.2B (90.67), with leading results in text (edit distance 0.035), formula (CDM 91.22), table (TEDS 90.89 and TEDS-S 94.76), and reading order (0.043).
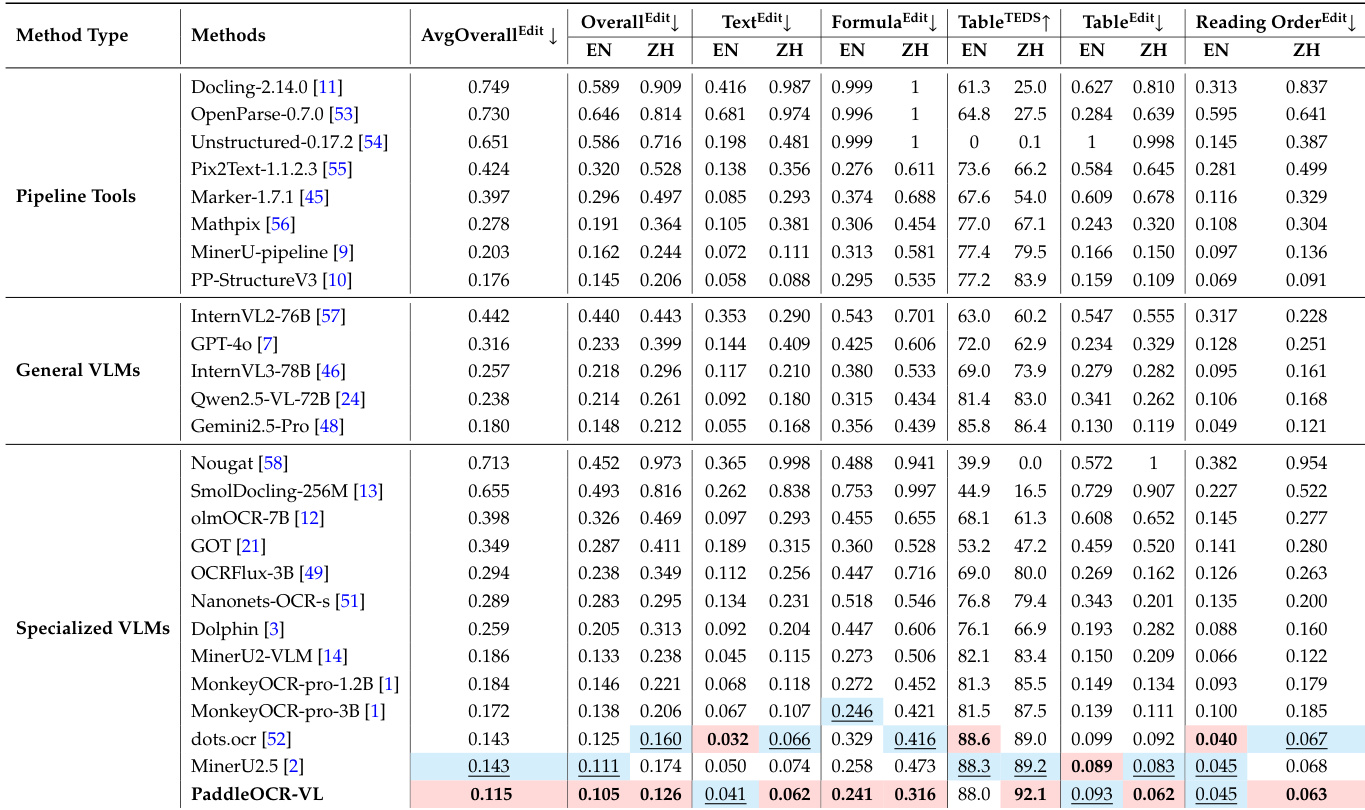
- On OmniDocBench v1.0, achieved average overall edit distance of 0.115, with SOTA performance in Chinese text (0.062) and English text (0.041), and top scores in Chinese table (92.14) and reading order (0.063).
- On olmOCR-Bench, attained highest overall score of 80.0 ± 1.0, leading in ArXiv (85.7), Headers and Footers (97.0), and ranking second in Multi-column (79.9) and Long Tiny Text (85.7).
- Element-level evaluation: on OmniDocBench-OCR-block, achieved lowest edit distances across diverse document types (e.g., PPT2PDF: 0.049, Academic Literature: 0.021); on In-house-OCR, set SOTA across 109 languages and 14 text types, including handwritten and artistic fonts; on Ocean-OCR-Handwritten, led in both English (edit distance 0.118) and Chinese (0.034) recognition.
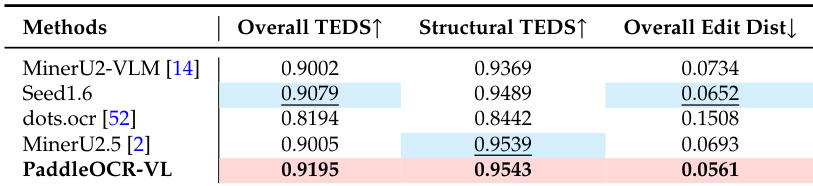
- On OmniDocBench-Table-block, achieved top TEDS of 0.9195 and lowest edit distance of 0.0561; on In-house-Table, scored highest in Overall TEDS (0.8699) and Structural TEDS (0.9066).
- On OmniDocBench-Formula-block, achieved SOTA CDM score of 0.9453; on In-house-Formula, reached 0.9882 CDM, demonstrating superior formula recognition in complex scenarios.
- On in-house-Chart benchmark, outperformed expert OCR VLMs and 72B-level models with high RMS-F1, showing strong chart parsing capability across 11 types in both English and Chinese.
- Inference evaluation: achieved 53.1% higher page throughput and 50.9% higher token throughput than MinerU2.5 on a single A100 GPU using FastDeploy, demonstrating state-of-the-art efficiency and scalability across hardware configurations.
Results show that PaddleOCR-VL achieves the highest overall TEDS and structural TEDS scores, along with the lowest overall edit distance, outperforming all compared models in table recognition on the OmniDocBench-Table-block benchmark.
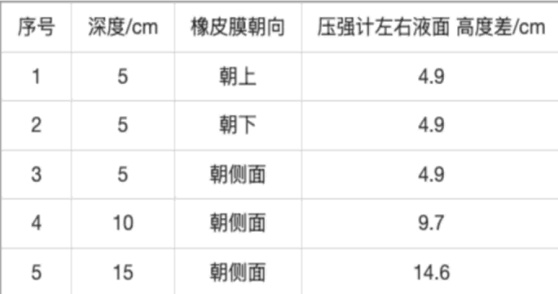
The authors use a table to present experimental results on pressure measurements under different conditions, including varying depths and rubber membrane orientations. Results show that the height difference in the manometer increases with depth, and the orientation of the rubber membrane affects the measured pressure, with the highest difference observed at a depth of 15 cm and the membrane facing sideways.
The authors use the OmniDocBench v1.5 benchmark to evaluate document parsing performance, with the table showing that PaddleOCR-VL achieves the highest overall edit distance score of 0.115, outperforming all other methods across key metrics including text, formula, and table recognition. Results show that PaddleOCR-VL leads in most categories, particularly in Chinese text and table recognition, while also demonstrating strong multilingual and complex layout handling capabilities.
The authors use the In-house-OCR benchmark to evaluate text recognition performance across multiple languages, reporting edit distances for various scripts. Results show that PaddleOCR-VL achieves the lowest edit distances in all evaluated languages, including Arabic (0.122), Korean (0.052), Tamil (0.043), Greek (0.135), Thai (0.081), Telugu (0.114), Devanagari (0.097), Cyrillic (0.109), Latin (0.013), and Japanese (0.096), demonstrating superior multilingual recognition capability.

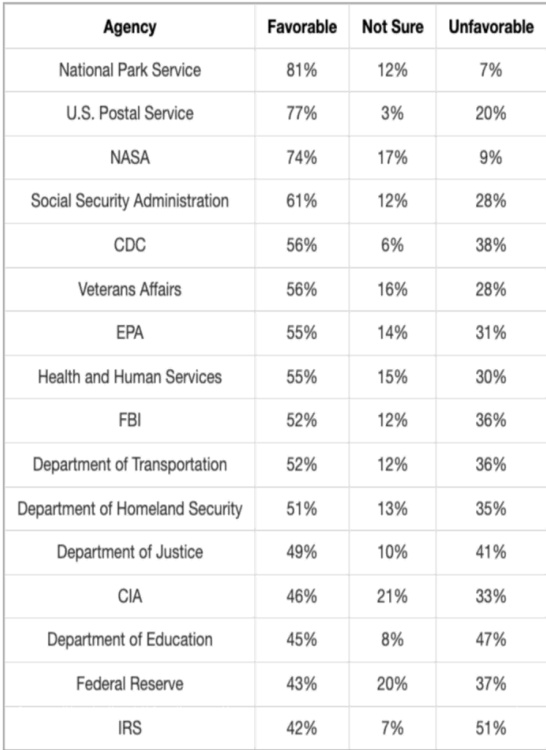
The authors use the table to present public opinion survey results on various U.S. government agencies, showing the percentage of respondents who hold favorable, not sure, or unfavorable views. Results show that the National Park Service has the highest favorability at 81%, while the IRS has the lowest at 42%, with a clear trend of declining favorability across agencies from top to bottom.