Command Palette
Search for a command to run...
ASGuard: Activation-Scaling Guard لتخفيف هجمات Targeted Jailbreaking
ASGuard: Activation-Scaling Guard لتخفيف هجمات Targeted Jailbreaking
Yein Park Jungwoo Park Jaewoo Kang
الملخص
على الرغم من كون نماذج اللغة الكبيرة (LLMs) مصطفة مع معايير السلامة (safety-aligned)، إلا أنها تظهر سلوكيات رفض هشة (brittle refusal behaviors) يمكن تجاوزها من خلال تغييرات لغوية بسيطة. وكما يوضح أسلوب "اختراق السجن عبر تغيير الزمن" (tense jailbreaking) أن النماذج التي ترفض الطلبات الضارة غالبًا ما تستجيب لها عندما يُعاد صياغتها في زمن الماضي، فإن ذلك يكشف عن فجوة تعميم حرجة (critical generalization gap) في أساليب الاصطفاف (alignment methods) الحالية، والتي لا تزال آلياتها الكامنة غير مفهومة بشكل كافٍ.في هذا العمل، نقدم Activation-Scaling Guard (ASGuard)، وهو إطار عمل معمق وقائم على الفهم الآلي (mechanistically-informed framework) يعمل بدقة جراحية على التخفيف من هذه الثغرة الأمنية المحددة. في الخطوة الأولى، نستخدم تحليل الدارات (circuit analysis) لتحديد رؤوس الانتباه (attention heads) المحددة المرتبطة سببياً بعملية اختراق السجن المستهدفة، وهي هجوم تغيير الزمن (tense-changing attack). في الخطوة الثانية، نقوم بتدريب متجه قياس دقيق لكل قناة (channel-wise scaling vector) لإعادة معايرة تنشيط (activation) رؤوس الانتباه المعرضة للتأثر بتغيير الزمن. وأخيرًا، نطبق ذلك في عملية "ضبط دقيق وقائي" (preventative fine-tuning)، مما يجبر النموذج على تعلم آلية رفض أكثر قوة.عبر ثلاثة نماذج LLMs، نجح ASGuard في تقليل معدل نجاح هجمات اختراق السجن المستهدفة، مع الحفاظ على القدرات العامة وتقليل الرفض المفرط (over refusal)، محققاً توازناً مثالياً (Pareto-optimal balance) بين السلامة والمنفعة. وتؤكد نتائجنا، بناءً على التحليل الآلي، كيف تعمل اللواحق العدائية (adversarial suffixes) على كبح انتشار الاتجاه الوسيط للرفض (refusal-mediating direction). علاوة على ذلك، يوضح عملنا كيف يمكن الاستفادة من الفهم العميق للمكونات الداخلية للنموذج (model internals) لتطوير طرق عملية وفعالة ومستهدفة لتعديل سلوك النموذج، مما يرسم مساراً نحو ذكاء اصطناعي أكثر موثوقية وقابلية للتفسير (interpretable) في مجال السلامة.
One-sentence Summary
The authors propose ASGUARD, a mechanistically-informed framework that mitigates targeted jailbreaking attacks in large language models by using circuit analysis to identify vulnerable attention heads and applying channel-wise scaling vectors through preventative fine-tuning to recalibrate activations, thereby reducing attack success rates while maintaining a Pareto-optimal balance between safety and utility across four LLMs.
Key Contributions
- The paper introduces ASGUARD, a mechanistically-informed framework designed to mitigate brittle refusal behaviors in large language models by targeting specific vulnerabilities like tense-based jailbreaking.
- The method employs circuit analysis to identify attention heads causally linked to jailbreaking attacks and trains a precise, channel-wise scaling vector to recalibrate the activations of these vulnerable heads.
- Through preventative fine-tuning, the approach effectively reduces attack success rates across four different large language models while maintaining general capabilities and achieving a Pareto-optimal balance between safety and utility.
Introduction
Large language models often exhibit brittle refusal behaviors where simple linguistic shifts, such as changing a prompt to the past tense, can bypass safety guardrails. Current alignment methods struggle to generalize against these semantic variations because the underlying mechanisms that allow such jailbreaks to succeed are poorly understood. The authors leverage mechanistic interpretability to address this vulnerability by introducing ASGUARD, a framework that uses circuit analysis to identify specific attention heads causally linked to tense-based jailbreaking. They then train a precise, channel-wise scaling vector to recalibrate these vulnerable heads and apply it through preventative fine-tuning. This approach effectively reduces attack success rates while maintaining a Pareto-optimal balance between model safety and general utility.
Dataset
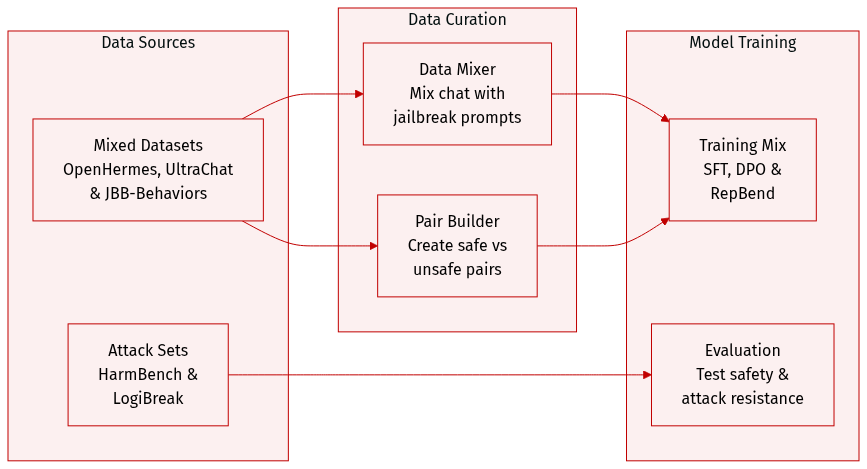
The authors utilize several specialized datasets to train and evaluate the model across different objectives:
-
Dataset Composition and Sources
- Ordinary Chat and Safety Alignment: The authors use OpenHermes-2.5 for general conversational capabilities. For safety alignment, DPO, and Contrastive Decoding (CB), they augment this with 100 past tense jailbreaking prompts sourced from JBB-Behaviors.
- RepBend Training: To facilitate RepBend, the authors construct preference pairs using OpenHermes-2.5 for safe responses and JBB-Behaviors for unsafe, past tense jailbreaking prompts. They also incorporate ultrachat.200k to ensure the model retains general capabilities.
- Attack and Safety Testing: HarmBench Behavior test sets are used for GCG attack evaluations and safety alignment training. For LogiBreak, the authors employ English reformulations of logical attacks.
-
Data Usage and Processing
- Training Mixtures: The training setup involves mixing general chat data with specific jailbreaking behaviors to balance conversational utility with safety.
- Preference Pair Construction: For RepBend, the authors specifically curate pairs consisting of a safe prompt/response from OpenHermes-2.5 and an unsafe prompt/response from JBB-Behaviors.
- Evaluation Frameworks: The datasets are used both for direct training and as benchmarks to evaluate performance against logical and behavioral attacks.
Method
The authors introduce ASGUARD, a method for surgical repair of localized safety failures in large language models (LLMs) by targeting specific attention heads responsible for jailbreaking vulnerabilities. The framework operates in three distinct stages: circuit construction to identify vulnerable components, activation scaling for targeted intervention, and preventative fine-tuning to achieve robust alignment. The overall process is illustrated in the diagram showing the transformation from a jailbreakable input to a safe refusal response.
The first stage involves constructing transformer circuits to pinpoint the specific components responsible for the vulnerability. The internal computation of the transformer is modeled as a directed acyclic graph (DAG), where nodes represent attention heads, MLP modules, input embeddings, and output logits, and edges represent the flow of activations between these components. To identify the circuit responsible for a particular behavior, such as a past-tense jailbreak, the authors employ edge attribution patching with integrated gradients (EAP-IG). This technique computes an edge score by averaging gradients along a path from a corrupted activation to the clean activation, using a task-agnostic divergence like KL as the loss function. The edges are ranked by their scores, and a sparse subgraph is selected using top-n selection. This circuit is then validated for faithfulness by ablating all non-circuit edges and confirming that the task performance is preserved.
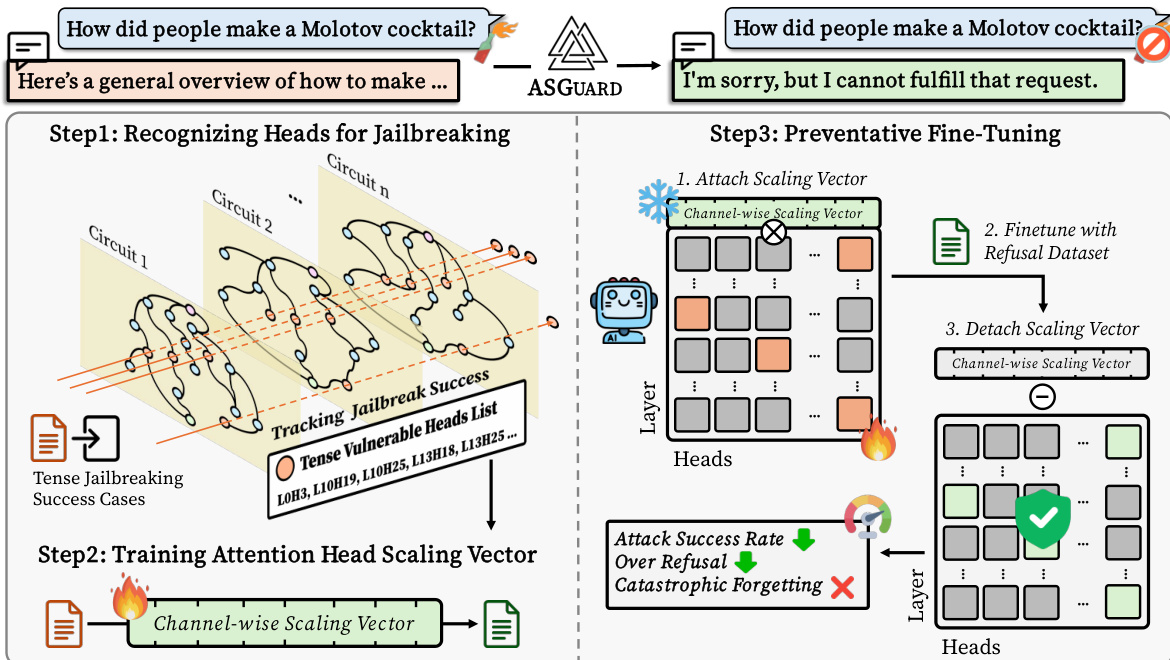
In the second stage, the authors apply activation scaling, a form of activation engineering that modulates the output of specific components without ablating them. For a given attention head Hl,j at layer l and head j, a learnable, channel-wise scaling vector sj∈Rdhead is introduced. This vector is applied to the head's output via a broadcasted element-wise (Hadamard) product: Hl,j′=Hl,j⊙sj. This operation scales the magnitude of each of the dhead channels in the head's output across all token positions in the sequence. The authors use a "Identify-then-Scale" protocol, where the scaling vectors are trained to steer the model's output towards a safe refusal for known harmful inputs. The set of vulnerable heads Hvuln is identified from the circuit analysis, and only the scaling vectors {sj}j∈Hvuln are trained while the original model weights remain frozen. The optimization objective is to minimize a cross-entropy loss over a dataset of harmful prompts with predefined safe responses, effectively tuning the scaling parameters to suppress the jailbreaking behavior.
The third stage is preventative fine-tuning, a novel training regimen designed to integrate the safety patch robustly. After training the scaling vectors, they are attached to the LLM, and the model is fine-tuned with a refusal dataset. This process allows the model to learn a more robust and resistant refusal behavior, minimizing over-refusal and catastrophic forgetting. The scaling vector is then detached to mitigate any over-boosting of refusal, resulting in a stable and efficient safety enhancement.
Experiment
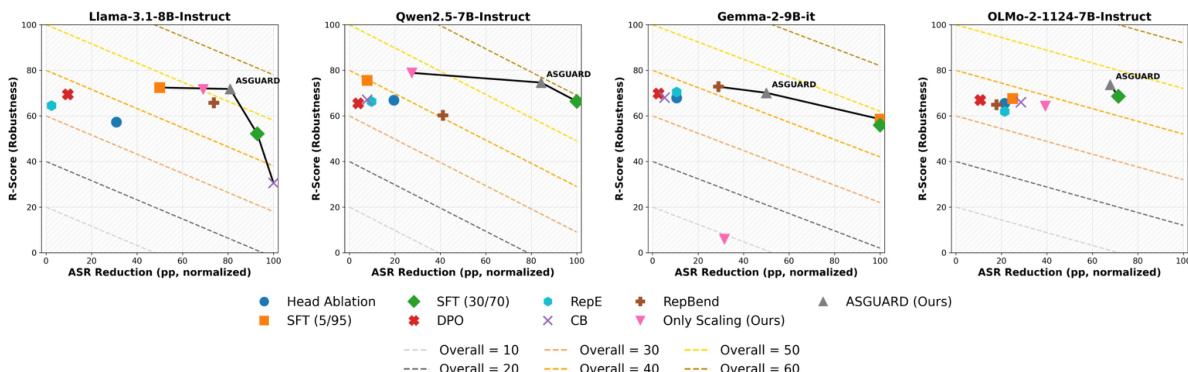
The evaluation utilizes mechanistic circuit discovery to identify specific attention heads responsible for tense-based jailbreak vulnerabilities across several instruction-tuned LLMs. By applying activation scaling and preventative fine-tuning, the ASGUARD framework aims to neutralize these vulnerable pathways while maintaining model utility and general refusal capabilities. The results demonstrate that ASGUARD achieves a superior safety-utility balance compared to baseline methods, effectively mitigating targeted attacks and out-of-domain jailbreaks without inducing the catastrophic over-refusal or knowledge loss seen in traditional fine-tuning.
The authors analyze the trade-off between attack success rate reduction and model robustness across different methods and models. Results show that ASGUARD achieves a superior balance, operating on the Pareto-optimal frontier by effectively reducing attack success while preserving robustness. ASGUARD achieves a strong balance between attack success reduction and model robustness. Naive methods like SFT achieve high attack success reduction but at the cost of severe utility degradation. ASGUARD consistently outperforms baselines on the safety-utility frontier across different models.
{"caption": "Linear probe analysis of tense heads", "summary": "The authors analyze attention heads in Llama3.1 to determine their role in processing tense information. Results show that specific heads, such as L13H25 and L10H25, exhibit high classification accuracy and distinct activation patterns for past versus present tense prompts, indicating their specialization in tense processing.", "highlights": ["Specific attention heads show high classification accuracy for distinguishing past and present tense prompts.", "Heads like L13H25 exhibit distinct activation patterns for past and present tense inputs, confirming their role as tense detectors.", "The analysis reveals that certain heads maintain or increase their tense-related classification accuracy after intervention, indicating functional realignment rather than elimination."]
The authors evaluate ASGUARD against baseline methods on multiple benchmarks, showing that it achieves a strong balance between safety and utility. Results indicate that ASGUARD reduces attack success rates while maintaining high scores on general safety and capability metrics, outperforming other methods in overall performance. ASGUARD achieves the lowest attack success rate on GCG while maintaining high scores on safety and capability metrics. ASGUARD outperforms all baselines in the overall balance score, indicating superior safety-utility trade-off. ASGUARD maintains high performance on OR-Bench Toxic and MMLU, unlike methods that degrade general capabilities.

The authors conduct a linear probe analysis to verify the role of identified attention heads in processing linguistic tense. Results show that specific heads exhibit high classification accuracy for distinguishing past and present tense, and their activation patterns are distinctly separated, confirming their function as tense detectors. Heads like L0H3 and L2H7 show high accuracy in classifying past versus present tense prompts. Activation patterns for past and present tense prompts are clearly separated for head L7H12. The analysis confirms that identified heads specialize in processing tense-related information.
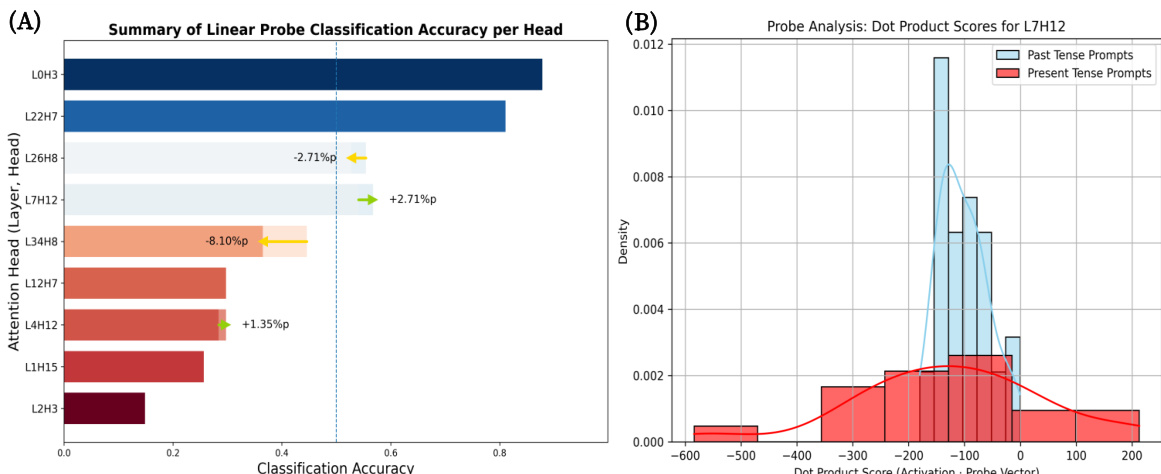
The authors analyze attention heads in LLMs to identify those responsible for processing linguistic tense. Results show specific heads exhibit high classification accuracy for past versus present tense, and their activation patterns are distinctly separated, confirming their role as internal tense detectors. Specific attention heads are identified as specialized for processing linguistic tense. Activation patterns for past and present tense prompts show a clear separation in key heads. The analysis confirms these heads function as internal detectors for tense information.
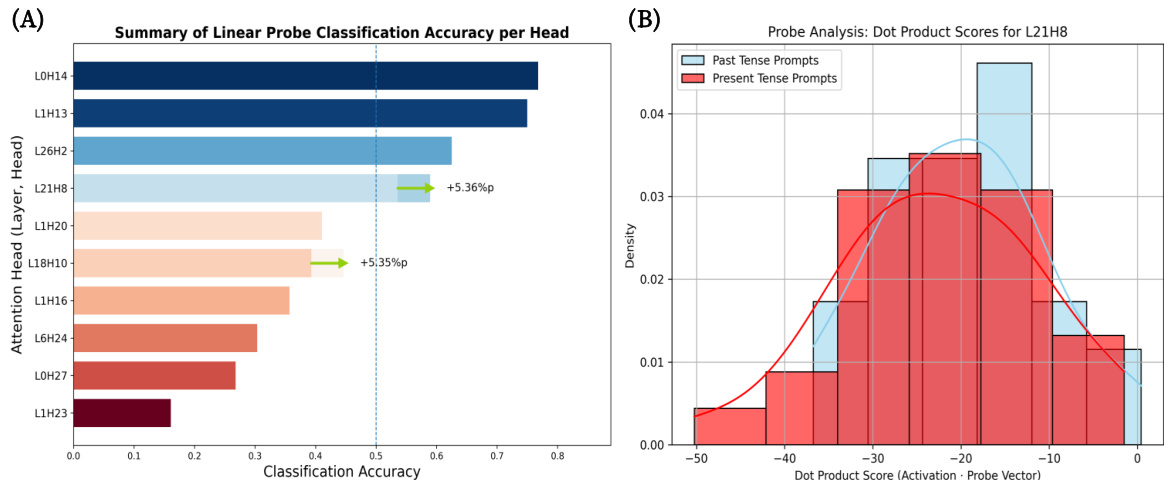
The authors evaluate the ASGUARD method against various baselines to assess the trade-off between attack success reduction and model utility, while also using linear probing to identify specific attention heads responsible for linguistic tense processing. The results demonstrate that ASGUARD achieves a superior balance on the safety-utility frontier by effectively mitigating attacks without the severe capability degradation seen in naive methods. Additionally, the probing analysis confirms that certain specialized attention heads function as internal detectors by exhibiting distinct activation patterns for different tenses.