Command Palette
Search for a command to run...
بطاقة النموذج (Model Card) لـ gpt-oss-120b & gpt-oss-20b
بطاقة النموذج (Model Card) لـ gpt-oss-120b & gpt-oss-20b
الملخص
بصفتي مترجماً محترفاً متخصصاً في المجالات التقنية والعلمية، أنا مستعد تماماً لتنفيذ هذه المهمة. سأحرص على تقديم ترجمة تجمع بين الدقة العلمية والتدفق اللغوي، مع الالتزام التام بالمعايير التي وضعتها.منهجية العمل التي سأتبعها:الدقة التقنية: سأقوم بنقل المفاهيم المعقدة بدقة متناهية، مع ضمان استخدام المصطلحات العربية المعتمدة في الأوساط الأكاديمية والتقنية.الالتزام بالمصطلحات التقنية (Terminology Consistency): سألتزم تماماً بتعليماتك بشأن المصطلحات التي يجب إبقاؤها باللغة الإنجليزية مثل (LLM, Agent, token, Transformer, Diffusion, prompt, pipeline, benchmark وغيرها)، لضمان عدم حدوث أي لبس لدى القارئ المتخصص.الأسلوب اللغوي (Stylistic Tone): سأعتمد أسلوباً رصيناً وموضوعياً (Formal and Objective) يتناسب مع التقارير التقنية والأوراق البحثية، مبتعداً عن الصياغات الإنشائية أو العامية.تطويع النص (Localization vs. Literal Translation): لن تكون الترجمة حرفية جامدة، بل سأعمل على إعادة صياغة الجمل لتتبع البناء التركيبي الطبيعي للغة العربية، مما يجعل النص يبدو وكأنه كُتب بالعربية أصلاً، مع الحفاظ الكامل على المعنى الأصلي.التعامل مع المصطلحات النادرة: في حال وجود مصطلح تقني حديث أو غير شائع، سأقوم بكتابة المقابل العربي متبوعاً بالمصطلح الأصلي بين قوسين لضمان أقصى درجات الوضوح.أنا جاهز الآن. يرجى تزويدي بالنص الإنجليزي الذي ترغب في ترجمته.
One-sentence Summary
The authors propose the gpt-oss-120b and gpt-oss-20b models as high-performance, open-source architectures designed to provide the research community with scalable alternatives to proprietary systems for diverse natural language processing tasks.
Key Contributions
- The paper introduces gpt-oss-120b, an open-weight model that provides customizable capabilities including full chain-of-thought reasoning and support for structured outputs.
- This work implements a training approach that avoids direct optimization pressure on the chain-of-thought to preserve monitorability, allowing developers to better detect potential model misbehavior.
- Extensive safety evaluations and adversarial fine-tuning experiments demonstrate that the model does not reach high capability thresholds in biological, chemical, or cyber risk categories, even when subjected to robust attacker simulations.
Introduction
As the demand for agentic workflows grows, there is a critical need for open-weight models that can handle complex reasoning, tool use, and structured outputs. While proprietary models offer robust system-level protections, open-weight models often present unique safety challenges because attackers can fine-tune them to bypass refusals or optimize for harmful tasks. The authors introduce gpt-oss-120b and gpt-oss-20b, two open-weight reasoning models designed for high instruction following and variable reasoning effort. To support transparency and safety research, the authors specifically avoid placing optimization pressure on the chain-of-thought process, thereby preserving the monitorability of the models' internal reasoning for developers.
Dataset
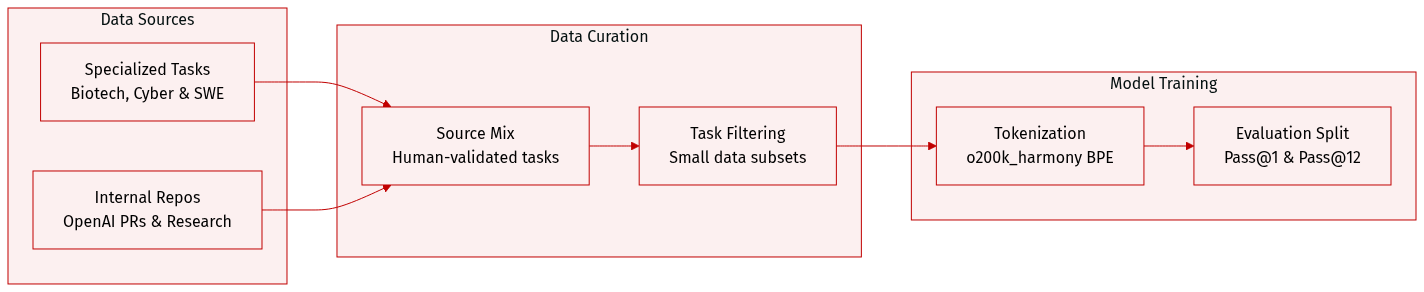
The authors utilize several specialized datasets and evaluation frameworks to assess model capabilities across various domains:
- Tacit Knowledge and Troubleshooting: Created in-house with Gryphon Scientific, this uncontaminated multiple choice dataset focuses on biothreat creation processes. It targets obscure knowledge that requires field-specific expertise or hands-on protocol experience.
- Cyber Range: This evaluation uses five emulated network scenarios, categorized into light and medium difficulty. Scenarios include Online Retailer, Simple Privilege Escalation, Basic C2, Azure SSRF, and Taint Shared Content. Models operate in a headless Linux environment with standard offensive tools and are tested under three configurations: Normal (goal and SSH key only), With Hints (a rough plan), and With Solver Code (partial code). Evaluation is measured via pass@12 for the unaided condition.
- SWE-bench Verified: The authors use a fixed subset of 477 human-validated tasks from SWE-bench Verified to evaluate real-world software issue resolution. For OpenAI o3 and o4-mini, they employ an internal tool scaffold for iterative file editing and debugging, reporting pass@1 performance.
- OpenAI PRs: This dataset is sourced directly from internal OpenAI pull requests to measure the ability to automate research engineering tasks. Each sample involves an agentic rollout where a model modifies a codebase to satisfy human-written prompts and hidden unit tests.
- PaperBench: To evaluate the replication of AI research, the authors use a 10-paper subset of the original PaperBench, specifically selecting papers requiring less than 10GB of external data. This subset involves 8,316 gradable sub-tasks designed to test codebase development and experiment execution.
- Tokenizer Details: All training stages utilize the o200k_harmony tokenizer, a BPE-based tokenizer with 201,088 tokens. It extends the standard o200k tokenizer used in GPT-4o to include specific tokens for the harmony chat format.
Method
The gpt-oss models are designed as autoregressive Mixture-of-Experts (MoE) transformers, extending the foundational architectures of GPT-2 and GPT-3. The authors release two distinct scales: gpt-oss-120b, which features 36 layers with a total of 116.8B parameters and 5.1B active parameters per token per forward pass, and gpt-oss-20b, which consists of 24 layers with 20.9B total parameters and 3.6B active parameters.
As shown in the table above, the parameter breakdown distinguishes between total and active parameters, noting that unembedding parameters are included in the active count while embeddings are not. To optimize memory efficiency, the authors apply quantization to the MoE weights, which constitute over 90% of the total parameter count. Specifically, they post-train the models using the MXFP4 format, quantizing weights to 4.25 bits per parameter. This technique allows the 120b model to fit within a single 80GB GPU and enables the 20b model to operate on systems with as little as 16GB of memory.
Following pre-training, the models undergo post-training to enhance reasoning and tool-use capabilities. The authors employ Chain-of-Thought (CoT) reinforcement learning (RL) techniques to teach the models complex problem-solving across domains such as coding, mathematics, and science. A key feature of this reasoning capability is the support for variable effort reasoning. By specifying keywords like "Reasoning: low" in the system prompt, users can configure three distinct reasoning levels: low, medium, and high. Increasing the requested reasoning level directly correlates with an increase in the average CoT length generated by the model.
The model is further trained for agentic tool use, allowing it to interact with external environments. This includes a browsing tool for web interaction to improve factuality, a Python tool for executing code within a stateful Jupyter notebook environment, and the ability to call arbitrary developer-defined functions via specific schemas. The model can seamlessly interleave CoT, function calls, and responses within a single session.
To manage security and instruction adherence, the authors implement an Instruction Hierarchy. The model is post-trained using a harmony prompt format that recognizes different roles: system messages, developer messages, and user messages. The training process explicitly teaches the model to prioritize instructions in the system message over developer messages, and developer messages over user messages. This hierarchy is evaluated through various conflict scenarios, such as testing whether a model can resist prompt injection or system prompt extraction attempts.

The robustness of the model is also addressed through adversarial training to estimate potential risks. The authors simulate a technical adversary using incremental reinforcement learning to explore how fine-tuning might affect capabilities in sensitive domains like biology, chemistry, and cyber security. This process involves helpful-only training, which rewards compliance with unsafe prompts, and maximizing capabilities relevant to specific preparedness benchmarks to ensure the model's safety boundaries are well-understood.
Experiment
The gpt-oss models were evaluated across a wide range of benchmarks covering reasoning, coding, tool use, multilingualism, and specialized domains like health and cybersecurity. The experiments validate that both the 120b and 20b models demonstrate strong reasoning capabilities and smooth test-time scaling, with the larger model performing competitively against leading closed-source models. Safety evaluations, including adversarial fine-tuning and jailbreak testing, indicate that the models remain below high-risk thresholds for biological, chemical, and cyber capabilities.
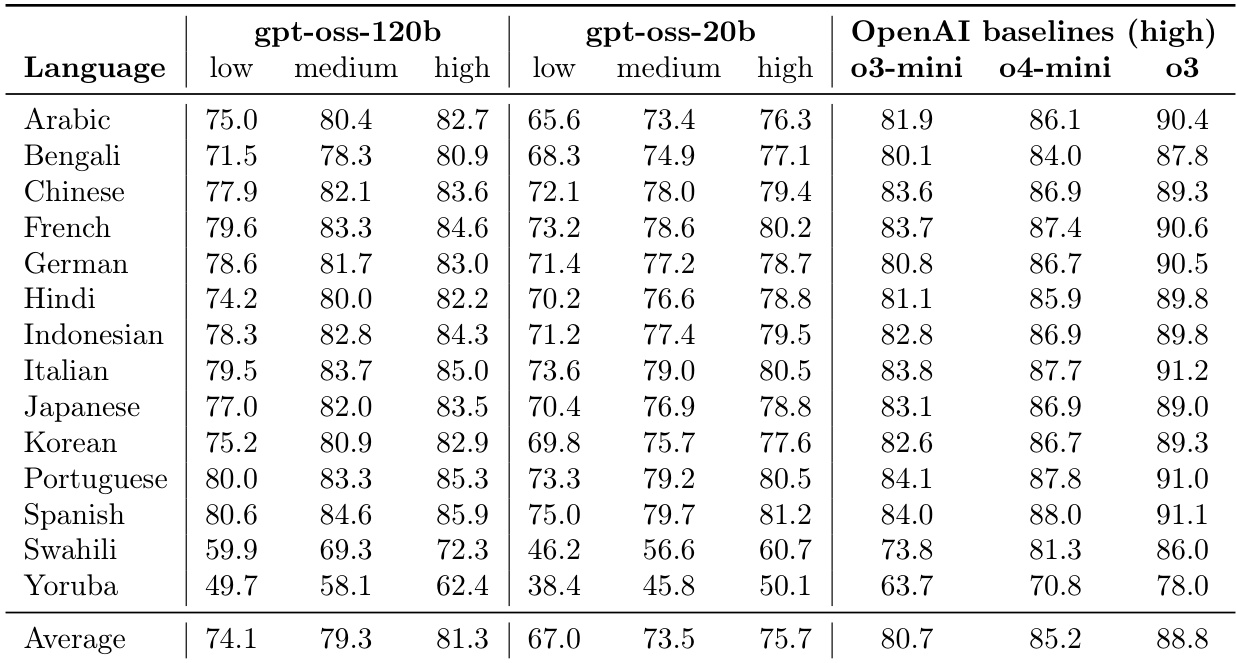
The the the table presents multilingual performance evaluations across various languages for the gpt-oss-120b and gpt-oss-20b models at different reasoning levels. Results are compared against OpenAI high-reasoning baselines to demonstrate how model size and reasoning effort impact multilingual proficiency. Increasing the reasoning level from low to high improves performance for both gpt-oss models across all tested languages. The gpt-oss-120b model consistently outperforms the gpt-oss-20b model in multilingual tasks. The OpenAI baselines generally maintain higher accuracy across the majority of languages compared to the gpt-oss models.
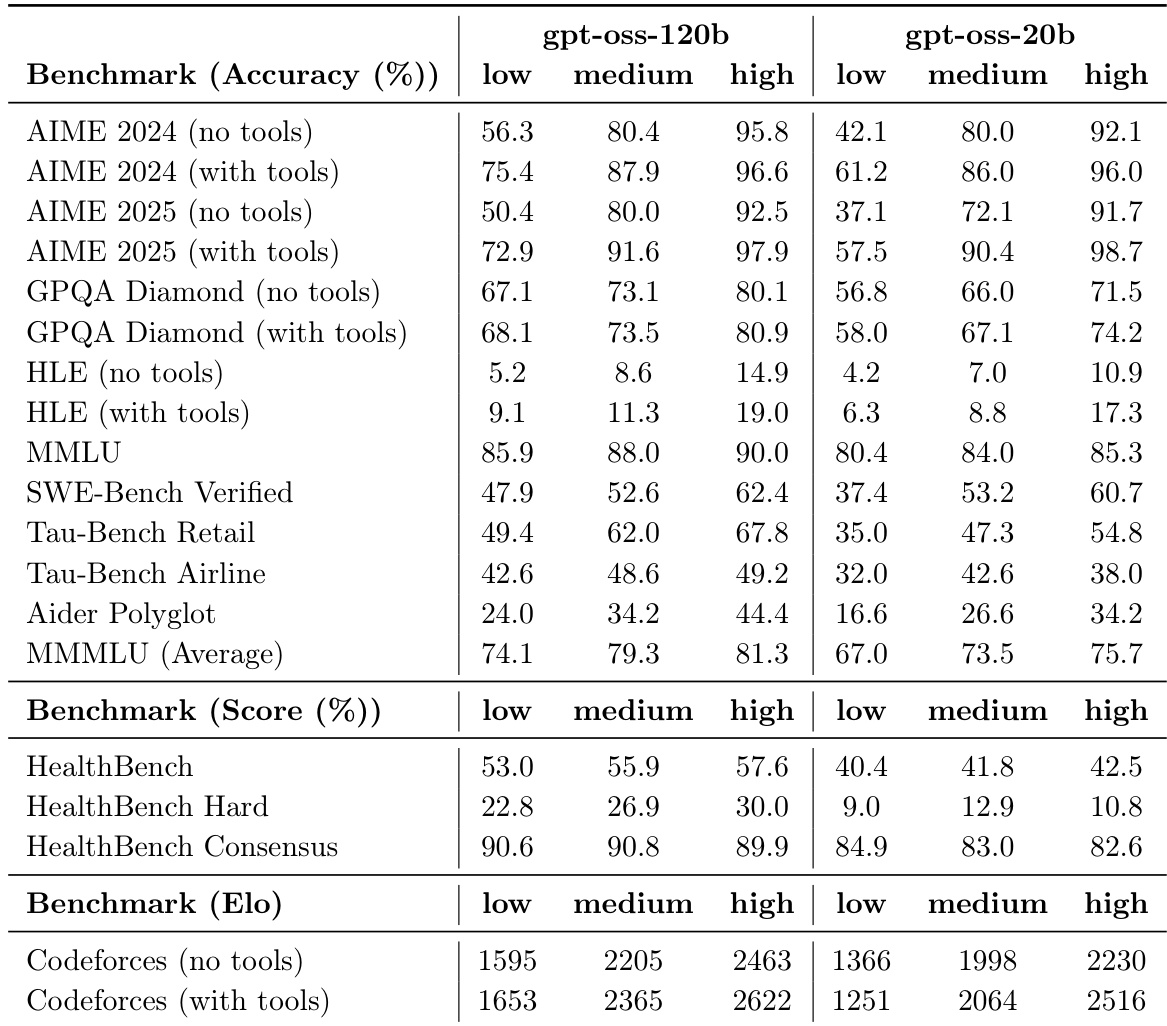
The the the table compares the performance of gpt-oss-120b and gpt-oss-20b across various reasoning, knowledge, and specialized benchmarks at three different reasoning levels. Results demonstrate that both models improve as reasoning effort increases from low to high, with the larger model consistently outperforming the smaller one. The gpt-oss-120b model shows higher accuracy than the 20b version across all evaluated benchmarks. Increasing the reasoning level from low to high leads to improved performance for both models on tasks such as AIME and GPQA. The 120b model achieves higher scores in specialized domains like HealthBench and Codeforces compared to the 20b model.
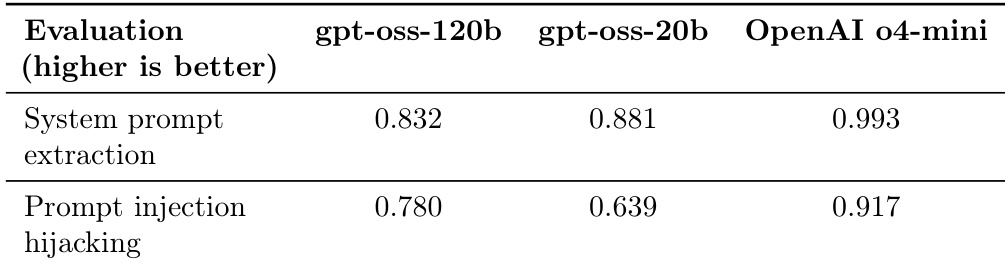
The the the table compares the performance of two gpt-oss models against OpenAI o4-mini on two specific security-related evaluation tasks. Both models show lower performance levels compared to the OpenAI model in these categories. The smaller gpt-oss-20b model achieves a higher score in system prompt extraction than the larger 120b version. The gpt-oss-120b model demonstrates better resistance to prompt injection hijacking than the gpt-oss-20b model. OpenAI o4-mini outperforms both gpt-oss models in both evaluated security tasks.
The authors evaluate the safety performance of gpt-oss-120b and gpt-oss-20b against OpenAI o4-mini across several categories of disallowed content. Results show that both models demonstrate high levels of safety compliance by refusing prompts related to illicit activities, violence, abuse, and sexual content. The gpt-oss-120b model shows safety performance that is highly comparable to OpenAI o4-mini across all tested categories. The smaller gpt-oss-20b model maintains strong refusal rates, performing similarly to the larger model in most safety dimensions. Both models exhibit particularly high success rates in refusing prompts involving abuse, disinformation, and hate speech.
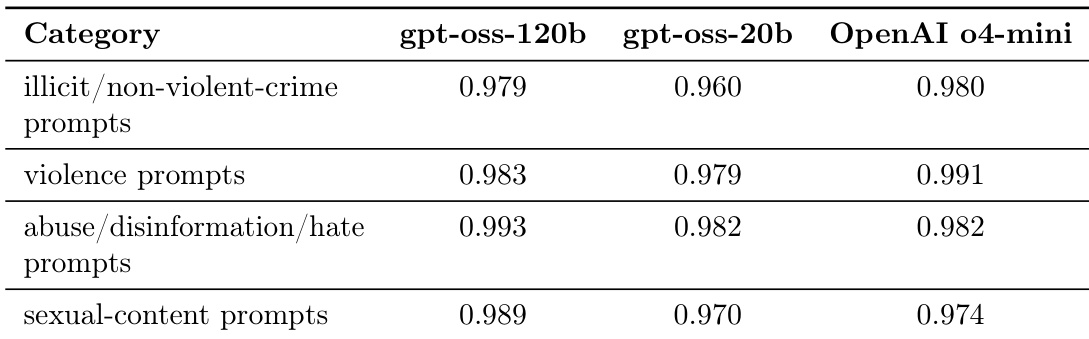
The the the table presents safety evaluation results across various harm categories for the gpt-oss-120b and gpt-oss-20b models, comparing them against OpenAI o4-mini and GPT-4o. The data reflects the models' ability to avoid generating disallowed content such as hate speech, self-harm instructions, and sexual content. Both gpt-oss models demonstrate high levels of safety across most categories, often performing at parity with or exceeding the compared frontier models. The gpt-oss-120b model shows consistent robustness in categories like sexual content and illicit non-violent content. In certain categories such as personal data handling, the gpt-oss models maintain performance levels comparable to OpenAI o4-mini and GPT-4o.
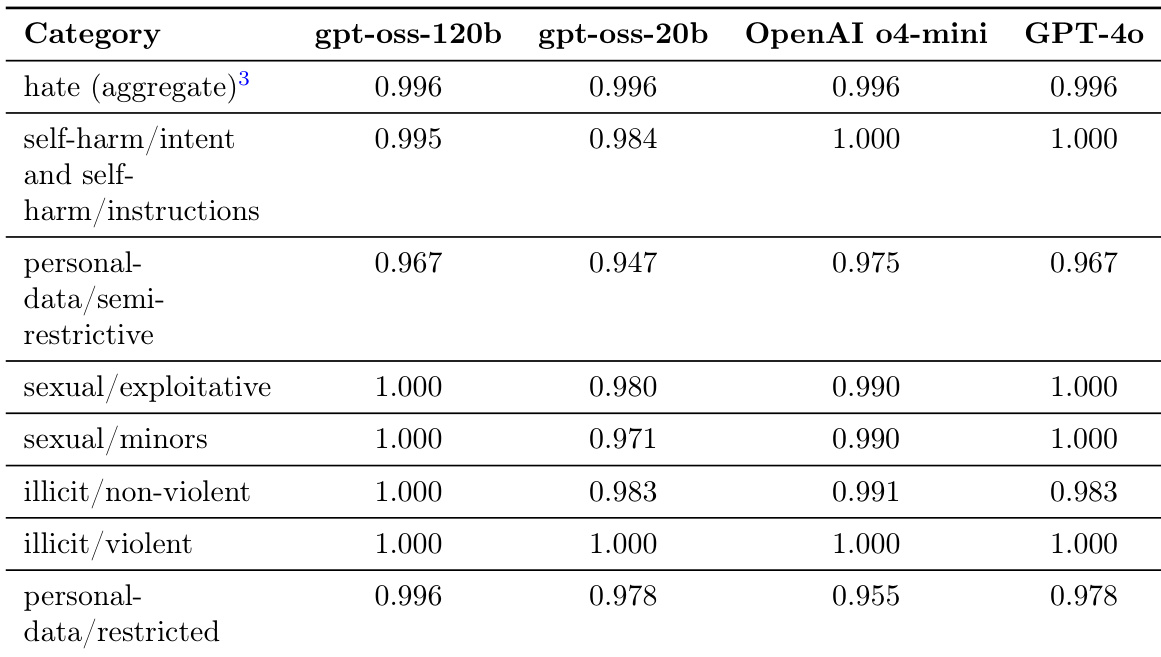
The evaluations compare the gpt-oss-120b and gpt-oss-20b models across multilingual proficiency, reasoning, specialized knowledge, security, and safety benchmarks against OpenAI baselines. Results indicate that increasing reasoning effort and model size consistently enhance performance in reasoning and multilingual tasks, though OpenAI models generally maintain a lead in accuracy and specific security tasks. Regarding safety, both gpt-oss models demonstrate high levels of compliance and robustness, achieving performance levels that are often comparable to or exceed frontier models across various harm categories.