Command Palette
Search for a command to run...
Granite-speech: نماذج LLMs مفتوحة المصدر مدركة للكلام مع قدرات قوية في مجال ASR للغة الإنجليزية
Granite-speech: نماذج LLMs مفتوحة المصدر مدركة للكلام مع قدرات قوية في مجال ASR للغة الإنجليزية
الملخص
تعد نماذج Granite-speech LLMs نماذج لغوية صوتية مدمجة وفعالة، صُممت خصيصاً لمهام التعرف التلقائي على الكلام (ASR) والترجمة الآلية للكلام (AST) باللغة الإنجليزية. تم تدريب هذه النماذج من خلال مواءمة الأنماط (modality aligning) للإصدارين اللذين يحتويان على 2B و 8B من المعلمات (parameters) لنموذج granite-3.3-instruct مع الصوت، وذلك باستخدام مجموعات بيانات مفتوحة المصدر متاحة للعامة، تحتوي على مدخلات صوتية وأهداف نصية تتكون إما من تفريغات بشرية (human transcripts) لمهام ASR، أو ترجمات مولدة آلياً لمهام AST.تظهر نتائج الـ benchmarking الشاملة أن هذه النماذج تتفوق في مهام ASR باللغة الإنجليزية —وهي محور تركيزنا الأساسي— على عدة نماذج منافسة تم تدريبها على كميات ضخمة من البيانات المملوكة (proprietary data) تفوق حجم بياناتنا بعدة مراتب، كما أنها تضاهي المنافسين في مهام AST من الإنجليزية إلى لغات أخرى (English-to-X) تشمل اللغات الأوروبية الرئيسية، واليابانية، والصينية.تتكون المكونات المخصصة للصوت مما يلي:1. مُشفر صوتي من نوع conformer يستخدم تقنية block attention والتدريب الذاتي (self-conditioning)، وقد تم تدريبه باستخدام التصنيف الزمني الاتصالي (connectionist temporal classification).2. محول نمط صوتي (speech modality adapter) يعتمد على تقنية windowed query-transformer، ويُستخدم لإجراء خفض العينات الزمني (temporal downsampling) للتضمينات الصوتية (acoustic embeddings) ومطابقتها مع فضاء التضمين النصي الخاص بـ LLM.3. محولات LoRA لإجراء ضبط دقيق (fine-tune) إضافي لنموذج LLM النصي.يعمل نموذج Granite-speech-3.3 في وضعين: في "الوضع الصوتي" (speech mode)، يقوم بتنفيذ مهام ASR و AST من خلال تفعيل الـ encoder، والـ projector، ومحولات LoRA؛ أما في "الوضع النصي" (text mode)، فإنه يستدعي نموذج granite-3.3-instruct الأساسي مباشرة (بدون LoRA)، مما يحافظ جوهرياً على جميع قدرات LLM النصية ومعايير السلامة الخاصة به.كلا النموذجين متاحان مجاناً عبر HuggingFace، ويمكن استخدامهما للأغراض البحثية والتجارية بموجب رخصة Apache 2.0 المرنة.
One-sentence Summary
By integrating a Conformer acoustic encoder with block attention and self-conditioning, a windowed query-transformer speech modality adapter, and LoRA fine-tuning, the Granite-speech series of compact, speech-aware LLMs achieves efficient English ASR and automatic speech translation that outperforms several larger proprietary models while preserving the original text-based capabilities of the Granite-3.3-instruct variants.
Key Contributions
- The paper introduces Granite-speech, a family of compact speech-aware large language models in 2B and 8B parameter variants designed for English automatic speech recognition (ASR) and automatic speech translation (AST).
- The architecture utilizes a specific speech-modality alignment strategy consisting of a Conformer acoustic encoder with block attention, a windowed query-transformer speech modality adapter for temporal downsampling, and LoRA adapters to fine-tune the underlying Granite-3.3-instruct model.
- Experimental results demonstrate that these models outperform several competitors trained on significantly larger proprietary datasets in English ASR and maintain competitive performance in English-to-X translation for major European languages, Japanese, and Chinese.
Introduction
Modern spoken language models generally fall into two categories: early fusion models that integrate audio and text tokens directly, and speech-aware LLMs that use an acoustic encoder to map audio to a text-based LLM. While early fusion models offer high modality fluency, they often suffer from reduced instruction-following capabilities and increased safety risks due to limited text-based alignment. The authors leverage a speech-aware architecture to develop Granite-speech, a series of compact 2B and 8B parameter models designed for English automatic speech recognition and automatic speech translation. By using a conformer acoustic encoder and a windowed query-transformer adapter to align audio with the Granite-3.3-instruct backbone, the authors preserve the original text model's safety guardrails and reasoning capabilities while achieving competitive performance on English ASR tasks.
Dataset
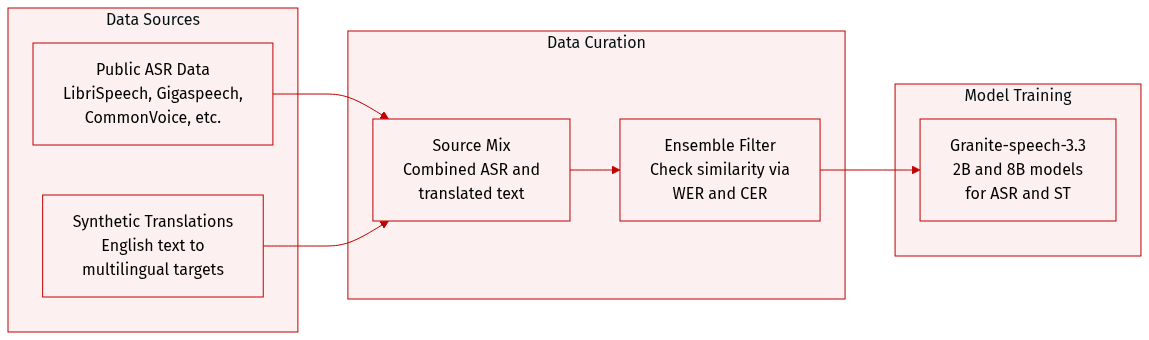
-
Dataset Composition and Sources: The authors train their models on a combination of major publicly available English Automatic Speech Recognition (ASR) datasets and synthetic speech translation data. The ASR corpora include Multilingual LibriSpeech, Gigaspeech, CommonVoice 17.0, LibriSpeech, Voxpopuli, AMI, YODAS, SPGI Speech, Switchboard, CallHome, Fisher, Voicemail, and TED LIUM.
-
Synthetic Speech Translation Data: To support speech translation tasks, the authors generated synthetic data by translating English transcriptions from CommonVoice 17 into several languages, including French, Spanish, German, Italian, Portuguese, Japanese, and Chinese.
-
Data Processing and Filtering: The authors used an ensemble filtering strategy to ensure high quality in the synthetic translations. They employed Phi-4 as the primary translation model and MADLAD-3B/10B as the secondary model to calculate similarity between translation outputs. After testing various metrics, they selected Word Error Rate (WER) and Character Error Rate (CER) as the most effective thresholds for filtering. Specifically, they applied a WER threshold of 0.3 for English to German translations and a CER threshold of 0.4 for English to Japanese translations. This process retained less than half of the original CommonVoice data but ensured higher translation reliability.
-
Model Usage: The processed datasets are used to train the Granite-speech-3.3 models (both 2B and 8B parameter versions). The mixture of ASR and synthetic translation data allows the models to perform both speech recognition and speech translation tasks, with the 8B model demonstrating superior translation performance compared to the 2B variant.
Method
The Granite speech system is designed as a speech-aware large language model (LLM) capable of performing both automatic speech recognition (ASR) and automatic speech translation (AST). The architecture integrates several key components to bridge the gap between continuous acoustic signals and discrete text tokens.
The overall framework consists of an acoustic encoder, a speech modality adapter, and a Granite text LLM. The acoustic encoder converts the raw speech signal into high-level representations. These representations are then processed by the speech modality adapter, which serves as a temporal downsampler and maps the acoustic embeddings into a latent space interpretable by the text LLM. To adapt the LLM to the specific characteristics of these acoustic embeddings, the authors employ LoRA (Low-Rank Adaptation) adapters applied to the query and value projection matrices within the attention blocks of the LLM layers.
Refer to the framework diagram:

The speech modality adapter utilizes a two-layer window-level Q-former projector. This design is inspired by the SALMONN architecture and aims to convert variable-length acoustic sequences into a fixed number of trainable queries that attend to the acoustic embeddings. Given an acoustic embedding sequence X=x1…xT of length T and N trainable queries Q=q1…qN, the adapter processes the input in blocks of size K (where K≥N and KmodN=0). The transformation is defined as:
y(i−1)∗N+1⋯yi∗N=Q−former(Q,x(i−1)∗K+1…xi∗K),i=1…⌈T/K⌉This mechanism effectively performs temporal downsampling by a factor of K/N. In the optimal configuration identified by the authors, a block size of K=15 frames and N=3 queries reduces the original 100 Hz logmel frame rate to a 10 Hz rate for the LLM.
To handle different tasks, the authors implement a task-specific prompt construction method using the Granite chat formatting syntax. The input sequence includes a system prompt, a user query, and a model response. For ASR and AST tasks, the user query contains a special ⟨audio⟩ token. During the forward pass, this token is replaced by the projected embeddings from the Q-former. For AST, the model supports both direct translation and a chain-of-thought (CoT) approach, where the model is prompted to first transcribe the speech and then translate it, using explicit tags to separate the steps.
The training process involves jointly optimizing the Q-former and the LoRA adapters while keeping the acoustic encoder frozen. The objective is the next-token prediction cross-entropy loss. To address potential data imbalances across different corpora, the authors utilize a balanced sampler. The sampling probability for a corpus i is controlled by a factor α∈[0,1], calculated as:
∑j=1LNjαNiαBy setting α=0.6, the authors are able to flatten the natural data distribution, ensuring that smaller corpora are adequately represented during the fine-tuning phase.
Experiment
The researchers evaluated the encoder architecture by comparing different tokenization methods and model scales to optimize performance for joint LLM training. Their findings indicate that character-level tokenization is most effective for subsequent integration with large language models. Additionally, safety assessments demonstrate that the speech interface successfully maintains the refusal behaviors of the underlying text model, preventing the execution of harmful instructions even when presented with complex or noisy audio inputs.
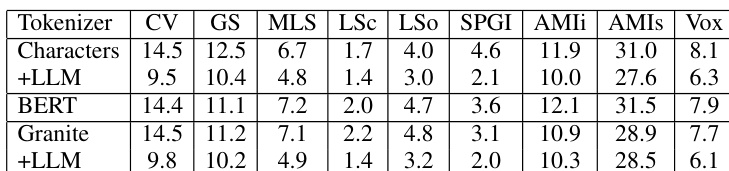
The authors evaluate how different output tokenization methods affect the performance of CTC speech encoders both during greedy decoding and after joint LLM training. Results show that character-based tokenization leads to improved performance when integrated with a large language model compared to BERT or Granite tokenization. Character tokenization combined with LLM training achieves better performance across various datasets than other tokenization methods. Joint LLM training reduces error rates for all tested tokenization types compared to greedy decoding alone. The performance gains from LLM integration are consistent across multiple different audio corpora.
The authors compare the performance of different Granite Large Language Models across several datasets. The results indicate that the model size and version influence recognition accuracy across various audio corpora. The smallest model version shows slightly higher error rates in several categories compared to the larger versions Performance trends remain relatively consistent across the different model iterations for most datasets The AMIs dataset consistently shows higher error rates than the other tested corpora

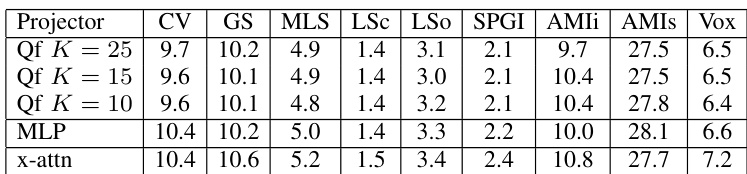
The authors evaluate different projector architectures across several datasets to assess their performance. The results show that varying the number of projection heads or using an MLP yields similar error rates across most corpora. The performance remains relatively stable across different configurations of the QF projector. The x-attn projector tends to result in higher error rates compared to the other evaluated architectures. MLP and QF projectors show comparable performance trends across the majority of the tested datasets.
The authors compare the automatic speech recognition performance of two different encoder architectures across various datasets. Results show that increasing the number of layers generally leads to improved recognition accuracy across most tested corpora. The 16 layer encoder achieves lower error rates than the 10 layer encoder in several categories Performance improvements from increasing layers are observed in most of the evaluated datasets Both encoder configurations show varying levels of error rates depending on the specific corpus used

The authors evaluate the impact of tokenization methods, LLM model scales, projector architectures, and encoder depths on speech recognition performance across various datasets. The findings indicate that character-based tokenization combined with joint LLM training yields superior results, while larger model sizes and deeper encoder architectures consistently improve accuracy. Additionally, the study demonstrates that MLP and QF projectors offer stable performance across different configurations, whereas the x-attn architecture tends to result in higher error rates.