Command Palette
Search for a command to run...
AM-Thinking-v1: دفع حدود الاستدلال بحجم 32B
AM-Thinking-v1: دفع حدود الاستدلال بحجم 32B
الملخص
نقدّم نموذج AM-Thinking-v1، وهو نموذج لغوي كثيف بحجم 32B، يُمثّل تقدّمًا في حدود التفكير المنطقي، ويعكس روح التعاون المفتوح المصدر. ويتفوّق النموذج على DeepSeek-R1، ويتقاسَم التفوّق مع النماذج الرائدة من نوع خليط الخبراء (MoE) مثل Qwen3-235B-A22B وSeed1.5-Thinking، حيث حقق نتائج متميّزة بلغت 85.3 في AIME 2024، و74.4 في AIME 2025، و70.3 في LiveCodeBench، ما يُظهر قدرات رائدة في الرياضيات والبرمجة بين النماذج المفتوحة المصدر ذات الحجم المماثل. تم بناء AM-Thinking-v1 بالكامل على أساس النموذج المفتوح المصدر Qwen2.5-32B، باستخدام استعلامات متاحة للعامة، واعتمد على عملية ما بعد التدريب المُحكَمة التي تدمج بين التدريب المُوجّه والتعلم بالتعزيز، مما يُتيح له قدرات استنتاجية استثنائية. تُظهر هذه الدراسة أن المجتمع المفتوح المصدر قادر على تحقيق أداء عالٍ على مستوى 32B، وهو حجم عملي يُعدّ "نقطة ذهبية" للاستخدام والضبط الدقيق. وبفضل التوازن بين الأداء الرفيع والقابلية للتطبيق في العالم الحقيقي، نأمل أن يُشجّع AM-Thinking-v1 على مزيد من الجهود التعاونية لاستغلال النماذج المتوسطة الحجم، ودفع حدود التفكير المنطقي، مع الحفاظ على إمكانية الوصول كأساس لعملية الابتكار. وقد أطلقنا النموذج مفتوح المصدر على منصة Hugging Face.
One-sentence Summary
The authors, affiliated with a-m-team, present AM-Thinking-v1, a 32B dense language model that achieves state-of-the-art reasoning performance on mathematical and coding benchmarks by leveraging a refined post-training pipeline on open-source data, outperforming DeepSeek-R1 and rivaling large MoE models while maintaining practical deployability and open accessibility.
Key Contributions
-
AM-Thinking-v1 is a 32B dense language model built from the open-source Qwen2.5-32B base and publicly available training data, demonstrating state-of-the-art reasoning performance on math and code benchmarks without relying on large Mixture-of-Experts (MoE) architectures or proprietary data.
-
The model achieves 85.3 on AIME 2024, 74.4 on AIME 2025, and 70.3 on LiveCodeBench by employing a carefully designed post-training pipeline that combines supervised fine-tuning with a two-stage reinforcement learning process, including difficulty-aware query selection and progressive data filtering.
-
Through rigorous data preprocessing—such as deduplication, removal of low-quality or multimodal queries, and ground-truth verification—the model effectively enhances reasoning capability, outperforming larger MoE models like DeepSeek-R1 and approaching the performance of Qwen3-235B-A22B and Seed1.5-Thinking.
Introduction
The authors leverage the publicly available Qwen2.5-32B base model to develop AM-Thinking-v1, a dense language model optimized for advanced reasoning tasks such as math problem solving and code generation. This work is significant because it demonstrates that high-performance reasoning—previously dominated by massive Mixture-of-Experts (MoE) models—can be achieved in a 32B-scale dense architecture, offering better deployability and lower infrastructure demands than large MoE systems. Prior approaches either relied on proprietary data, extremely large models, or complex deployment pipelines, limiting accessibility and practicality. The key contribution lies in a meticulously designed post-training pipeline that uses only open-source data, incorporating strict preprocessing, ground-truth verification for mathematical queries, and a two-stage training process combining Supervised Fine-Tuning and Reinforcement Learning with difficulty-aware query selection. This enables AM-Thinking-v1 to outperform much larger MoE models on benchmarks like AIME2024, AIME2025, and LiveCodeBench, proving that careful data curation and training design can close the reasoning gap without sacrificing model efficiency.
Dataset
- The dataset comprises approximately 2.84 million samples drawn from publicly available open-source sources across five core domains: mathematical reasoning, code generation, scientific reasoning, instruction following, and general chat.
- Mathematical reasoning data is sourced from datasets including OpenR1-Math-220k, Big-Math-RL-Verified, NuminaMath, MetaMathQA, 2023_amc_data, DeepMath-103K, and AIME, with each query including a verifiable ground truth.
- Code generation data comes from PRIME, DeepCoder, KodCode, liveincode_generation, codeforces_cots, verifiableCoding, opencoder, OpenThoughts-114k-Code_decontaminated, and AceCode-87K, all featuring verifiable test cases.
- Scientific reasoning includes multiple-choice questions from task_mmmlu, chemistryQA, Llama-Nemotron-Post-Training-Dataset-v1, LOGIC-701, ncert, and logicLM, each paired with reliable ground truths.
- Instruction follow data is drawn from Llama-Nemotron-Post-Training-Dataset and tulu-3-sft-mixture.
- General chat data spans evol, InfinityInstruct, open_orca, tulu-3-sft-mixture, natural_reasoning, flan, ultra_chat, and OpenHermes-2.5, covering open-ended, multi-turn, and single-turn interactions.
- All data undergoes deduplication and filtering: queries with URLs or image references are removed to prevent hallucination and ensure compatibility with a text-only model.
- Mathematical queries with unclear descriptions are filtered using an LLM, and ground truths are validated by comparing responses from DeepSeek-R1 with the original answers using math_verify. Discrepancies trigger re-evaluation using o4-mini, and incorrect ground truths are revised if o4-mini’s answer aligns with the most frequent DeepSeek-R1 response.
- Mathematical proof problems and multi-subquestion queries are excluded; multiple-choice math questions are rewritten as fill-in-the-blank to retain utility.
- Code queries are processed in a secure, distributed cloud sandbox supporting Python and C++. Code blocks are delimited using standard Markdown syntax (e.g.,
python,cpp). Test cases are either method call (converted to assertions) or standard input/output (handled via stdin/stdout). A query receives a reward of 1 only if all test cases pass. - To prevent data leakage, training queries are filtered to exclude exact and semantically similar matches from the evaluation set.
- During supervised fine-tuning, the model is trained on Qwen2.5-32B with a learning rate of 8e-5, a global batch size of 64, and 2 epochs using cosine warmup (5% of steps). Sequence length is capped at 32k tokens with sequence packing.
- For low-resource categories like instruction follow, data is upsampled by repetition. Challenging queries are augmented with multiple synthetic responses to improve training diversity and robustness.
- In multi-turn dialogues, only the final response—containing the full reasoning chain—is used as the training target, with loss computed solely on this output to emphasize reasoning quality.
Method
The authors leverage a two-stage reinforcement learning (RL) pipeline to enhance the reasoning capabilities of AM-Thinking-v1, a 32B dense language model built upon the Qwen2.5-32B base. The overall training framework is constructed using the verl open-source RL framework, which integrates vLLM, FSDP, and Megatron-LM to enable scalable training across 1000+ GPUs. The RL process is designed to ensure stable and effective policy updates while maintaining computational efficiency.
The training pipeline begins with a pre-filtering step to select queries of appropriate difficulty. Math and code queries are filtered based on their pass rates from the supervised fine-tuning (SFT) model, retaining only those with pass rates strictly between 0 and 1. This ensures that the training data remains challenging enough to drive learning without introducing instability from overly easy or intractable examples. The filtered datasets consist of 32k math and 22k code queries.
The RL pipeline consists of two distinct stages. In Stage 1, the model is trained on the filtered math and code queries using Group Relative Policy Optimization (GRPO), a lightweight variant of Proximal Policy Optimization (PPO). The training configuration includes several key design choices: no KL constraint is applied, allowing for more substantial policy updates; responses exceeding a length threshold during rollout are assigned zero advantage to prevent overlong outputs from influencing parameter updates; and strict on-policy training is enforced, where each batch of 256 queries generates 16 rollouts, and the policy updates only once per exploration stage. The maximum response length is capped at 24K tokens, and a relatively high learning rate of 4×10−6 is used to accelerate convergence.
When performance plateaus in Stage 1, the pipeline transitions to Stage 2. In this stage, all math and code queries that the model answered correctly with 100% accuracy in Stage 1 are removed from the training set. The dataset is then augmented with 15k general chat and 5k instruction-following data to improve the model's broader generalization capabilities. The maximum response length is increased to 32K tokens, and the learning rate is reduced to 1×10−6 to stabilize training during the later phase.
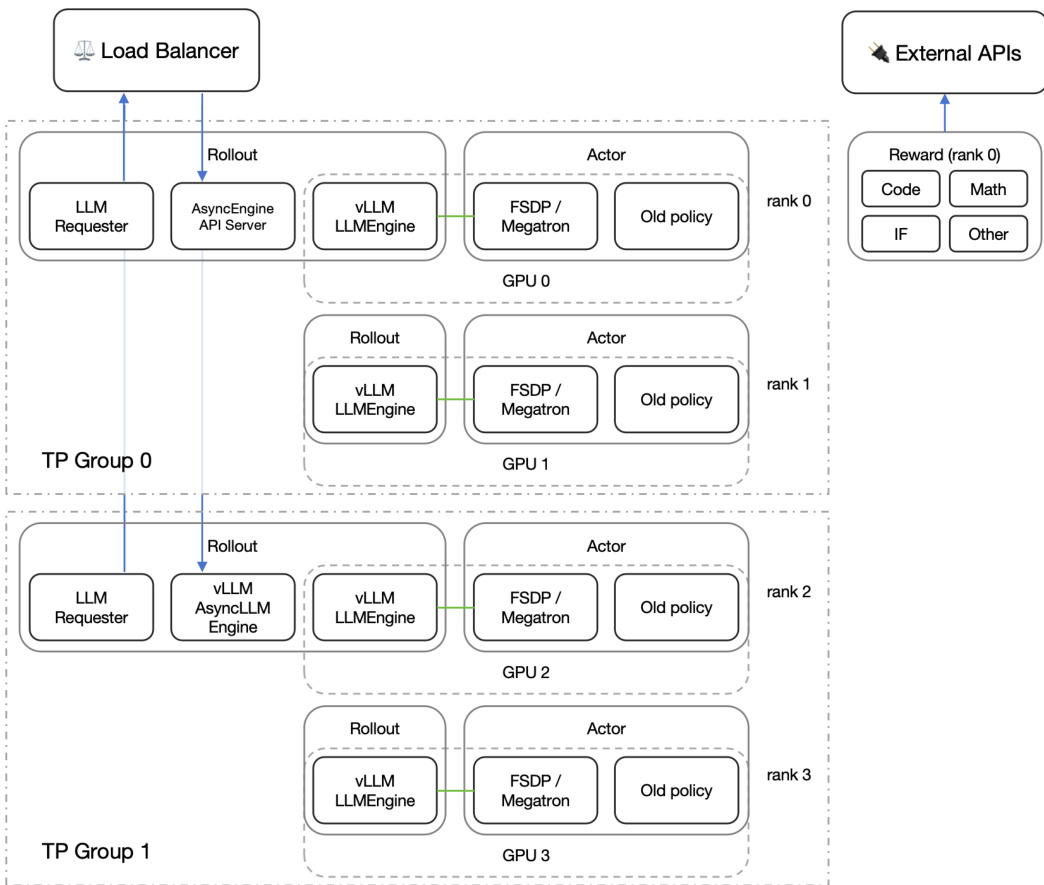
As shown in the figure below, the RL framework is organized into two tensor parallel (TP) groups, each containing multiple GPUs. Within each group, the system employs a load balancer to distribute incoming requests. The LLM Requester and AsyncEngine API Server manage the flow of queries, with the vLLM LLMEngine handling inference and the Actor component executing policy updates. The Actor uses FSDP/Megatron for distributed training and maintains an old policy for comparison during GRPO updates. The framework also supports external APIs for reward computation, where resource-intensive operations such as LLM-as-a-judge and code sandboxing are offloaded. Reward computation is categorized by source type, including Code, Math, Instruction Following (IF), and Other, with the reward for each source being computed independently. This modular design enables efficient and scalable RL training across a large cluster.
Experiment
- Synthetic response filtering validates quality through perplexity, n-gram repetition, and structure checks; verified via pass rate for ground-truth queries and LLM-based reward scoring for others.
- Verifiable queries (math, code, instruction-following) use rule-based verification: math answers validated via normalized comparison (math_verify), instruction-following assessed via IFEval with strict mode, yielding binary rewards.
- Non-verifiable queries use a reward model scoring helpfulness, correctness, and coherence; final score is their average.
- Rollout speed optimization employs detached rollout with streaming load balancing, reducing long-tail latency and improving GPU utilization by dynamically distributing generation across instances.
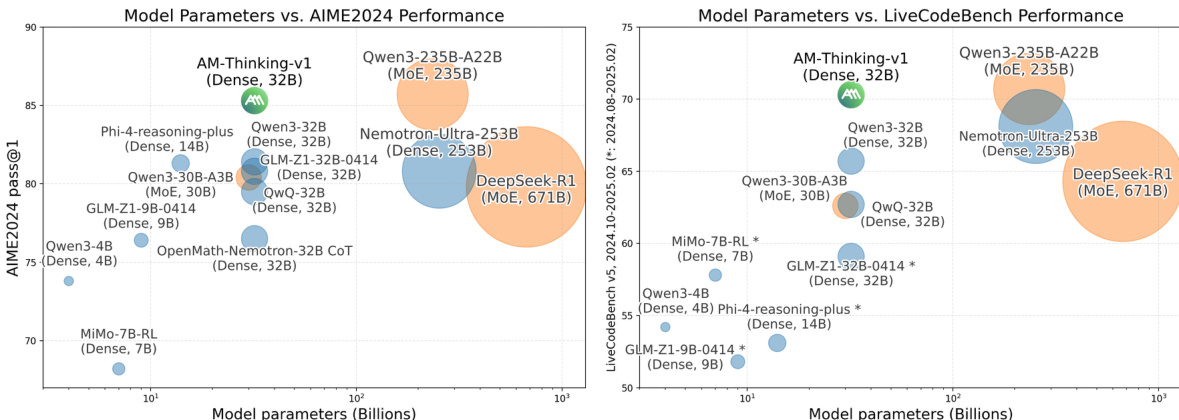
- On AIME2024, AM-Thinking-v1 achieves 85.3 pass@1, surpassing DeepSeek-R1 (80.0) and Qwen3-32B (78.7), and matching larger models like Qwen3-235B-A22B (85.3).
- On AIME2025, it scores 74.4, outperforming DeepSeek-R1 (70.0) and Qwen3-32B (69.3).
- On LiveCodeBench, AM-Thinking-v1 achieves 70.3 pass@1, significantly exceeding DeepSeek-R1 (64.3), Qwen3-32B (65.7), and Nemo-Ultra-256B (68.1).
- On Arena-Hard, it scores 92.5, competitive with OpenAI-o1 (92.1) and o3-mini (89.0), though below Qwen3-235B-A22B (95.6).
- SFT training shows a pattern shift: higher learning rate (8×10⁻⁵) and batch size (2M tokens) enable convergence; generation length decreases and stop ratio increases over time, indicating improved reasoning structure alignment.
The authors use a consistent evaluation setup across multiple reasoning benchmarks to compare AM-Thinking-v1 with several leading models. Results show that AM-Thinking-v1 achieves strong performance on mathematical and coding tasks, outperforming or closely matching larger models such as DeepSeek-R1 and Qwen3-32B, while also demonstrating competitive results on the general chat benchmark Arena-Hard.
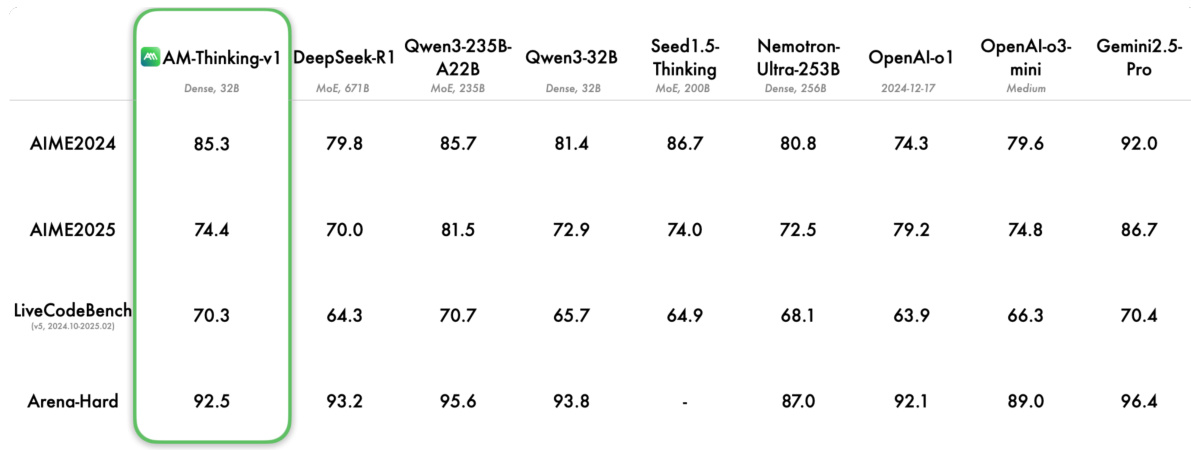
The authors evaluate AM-Thinking-v1 on multiple reasoning benchmarks and compare it with several leading large-scale models. On mathematical tasks, AM-Thinking-v1 achieves scores of 85.3 and 74.4 on AIME2024 and AIME2025, respectively, outperforming or closely matching larger models such as DeepSeek-R1 and Qwen3-235B-A22B. On the LiveCodeBench benchmark, AM-Thinking-v1 attains a score of 70.3, substantially surpassing DeepSeek-R1 (64.3), Qwen3-32B (65.7), and Nemotron-Ultra-253B (68.1), demonstrating strong capabilities in code understanding and generation. On the general chat benchmark Arena-Hard, AM-Thinking-v1 obtains a score of 92.5, which is competitive with several proprietary models such as OpenAI-o1 (92.1) and o3-mini (89.0). However, its performance still lags behind Qwen3-235B-A22B (95.6), indicating that there remains room for improvement in general conversational capabilities.

The authors use the provided charts to compare the performance of AM-Thinking-v1 against various models on AIME2024 and LiveCodeBench benchmarks, plotting model size against benchmark scores. Results show that AM-Thinking-v1 achieves strong performance on both tasks, outperforming several larger models and demonstrating competitive efficiency relative to its parameter count.