Command Palette
Search for a command to run...
تقرير تقني عن Kimi-Audio
تقرير تقني عن Kimi-Audio
الملخص
نقدّم نموذج Kimi-Audio، وهو نموذج أساسي مفتوح المصدر للصوت، يتميّز بالتفوّق في فهم الصوت، وإنشاؤه، والمحادثة الصوتية. ونُفصّل في ممارسات بناء Kimi-Audio، بما في ذلك معمارية النموذج، وتجهيز البيانات، ووصفة التدريب، ونشر الاستدلال، وتقييم الأداء. وبشكل خاص، نستخدم مُحلّل صوتي بتردد 12.5 هيرتز، ونُصمم معمارية مبتكرة تعتمد على نموذج لغوي كبير (LLM) مع مدخلات مكوّنة من خصائص مستمرة وناتج مكوّن من رموز منفصلة، ونطوّر مُفكّكًا تدفقيًا مُقسّمًا على حُزم (chunk-wise streaming detokenizer) مبنيًا على مطابقة التدفّق (flow matching). ونُجهّز مجموعة بيانات لمرحلة التدريب المسبق تضم أكثر من 13 مليون ساعة من البيانات الصوتية، تغطي طيفًا واسعًا من الأنواع، بما في ذلك الكلام، والصوتيات، والموسيقى، ونُنشئ خط أنابيب لبناء بيانات ما بعد التدريب عالية الجودة ومتنوعة. يُبدأ Kimi-Audio من نموذج لغوي مُدرّب مسبقًا، ثم يُدرّب باستمرار على بيانات صوتية ونصية من خلال عدة مهام مُصمّمة بعناية، ويُعدّل دقيقًا لدعم مجموعة متنوعة من المهام المرتبطة بالصوت. وتشير التقييمات الواسعة إلى أن Kimi-Audio يحقّق أداءً متفوّقًا على مستوى الحد الأقصى (state-of-the-art) في مجموعة من معايير الصوت، بما في ذلك التعرف على الكلام، وفهم الصوت، والإجابة على الأسئلة الصوتية، والمحادثة الصوتية. ونُطلق الكود البرمجي، ونقاط التحقق من النموذج، بالإضافة إلى أدوات التقييم عبر الرابط: https://github.com/MoonshotAI/Kimi-Audio.
One-sentence Summary
The authors propose Kimi-Audio, an open-source audio foundation model developed by Moonshot AI and collaborators, which integrates a 12.5Hz audio tokenizer and a novel LLM-based architecture with continuous features and discrete outputs, enabling state-of-the-art performance in audio understanding, generation, and conversation through continual pre-training and flow-matching-based streaming detokenization, with applications in speech recognition, audio QA, and multimodal dialogue.
Key Contributions
-
Kimi-Audio is an open-source audio foundation model designed to unify diverse audio tasks—such as speech recognition, audio understanding, and speech conversation—by leveraging a novel LLM-based architecture that processes continuous acoustic features and discrete semantic tokens, with a 12.5Hz audio tokenizer to align audio and text sequence lengths for efficient multimodal modeling.
-
The model is trained on a massive pre-training dataset exceeding 13 million hours of diverse audio (speech, music, environmental sounds) and a carefully curated pipeline for high-quality, task-specific fine-tuning data, enabling robust performance across multiple domains without reliance on proprietary data sources.
-
Extensive evaluation demonstrates Kimi-Audio achieves state-of-the-art results on key benchmarks including speech recognition, audio question answering, and speech conversation, with an open-sourced evaluation toolkit ensuring fair and reproducible comparisons across audio LLMs.
Introduction
Audio processing has traditionally been handled by task-specific models, limiting scalability and generalization. With the rise of large language models (LLMs), there is growing momentum toward unifying audio understanding and generation under a single framework, leveraging the sequential nature of audio and its strong alignment with text. However, prior work falls short in several key areas: models are often narrow in scope—focused on either understanding or generation—lack robust pre-training on raw audio, and frequently withhold code or checkpoints, hindering reproducibility and community advancement.
The authors introduce Kimi-Audio, an open-source, universal audio foundation model that unifies speech recognition, audio understanding, audio generation, and speech conversation in one architecture. They address prior limitations by designing a hybrid input representation that combines discrete semantic tokens with continuous acoustic vectors at a 12.5Hz compression rate, enabling efficient and rich audio modeling. The model is initialized from a pre-trained text LLM and trained on 13 million hours of diverse audio data using a multi-stage pre-training strategy—covering text-only, audio-only, audio-to-text mapping, and audio-text interleaving tasks—followed by instruction-based fine-tuning. This approach enables strong performance across multiple domains while maintaining high language intelligence.
Critically, the authors release both the model and an open evaluation toolkit to ensure fair benchmarking, addressing inconsistencies in metrics and protocols that have plagued prior comparisons. Their work marks a significant step toward general-purpose audio intelligence, with a focus on accessibility, scalability, and autonomy.
Dataset
-
The pre-training dataset consists of unimodal (text-only, audio-only) and multimodal (audio-text) data, with audio-only data totaling approximately 13 million hours of raw audio from diverse real-world sources such as audiobooks, podcasts, and interviews. This includes rich acoustic content like music, environmental sounds, human vocalizations, and multilingual speech.
-
The raw audio lacks transcriptions, language labels, speaker annotations, and segmentation, and often contains artifacts like background noise, reverberation, and speaker overlap.
-
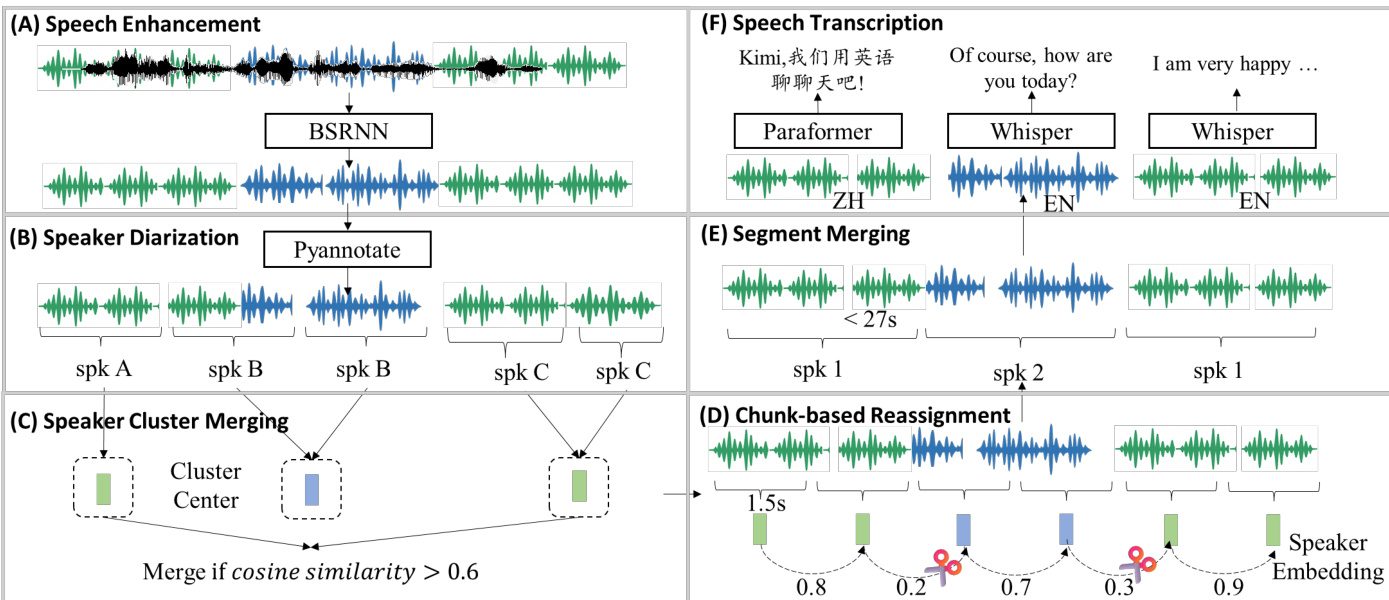
The authors develop an end-to-end audio data processing pipeline to generate high-quality multimodal annotations, focusing on long-form audio with consistent context—unlike prior methods that emphasize short segments.
-
The pipeline includes:
- Speech Enhancement: A Band-Split RNN (BSRNN)-based model applied at 48kHz to reduce noise and reverberation; original or enhanced audio is used in a 1:1 ratio during pre-training to preserve environmental and musical content.
- Diarization-Driven Segmentation: Using PyAnnotate for initial speaker segmentation, followed by three post-processing steps:
- Speaker Cluster Merging: Clusters with cosine similarity > 0.6 are merged to reduce speaker fragmentation.
- Chunk-based Reassignment: 1.5-second chunks are reassigned to speaker clusters based on similarity thresholds (<0.5 indicates a speaker change).
- Segment Merging: Adjacent same-speaker segments are merged if total length exceeds 27 seconds or silence gap exceeds 2 seconds.
- Speech Transcription:
- Language detection via Whisper-large-v3; only English and Mandarin segments are retained.
- English: Whisper-large-v3 provides transcriptions and punctuation.
- Mandarin: Paraformer-Zh generates transcriptions with character-level timestamps; punctuation is added based on inter-character gaps (comma for 0.5–1.0s, period for >1.0s).
-
The pipeline runs on a cluster of 30 cloud instances (128 vCores, 1 TB RAM, 8 NVIDIA L20 GPUs each), totaling 3,840 vCores, 30 TB RAM, and 240 GPUs, achieving ~200,000 hours of audio processed per day.
-
For audio understanding tasks (ASR, AQA, AAC, SER, SEC, ASC), the model is fine-tuned on open-source datasets (Table 1) and supplemented with 55,000 hours of in-house ASR data and 5,200 hours of in-house audio data for AAC/AQA.
-
For speech conversation capabilities, the authors build a large-scale multi-turn dataset:
- User queries are generated by LLMs and converted to speech using the Kimi-TTS system with diverse timbres (125K+ timbres).
- Assistant responses are synthesized using a single voice actor (Kimi-Audio speaker) with pre-recorded emotional and stylistic variations across 20+ styles and 5 intensity levels per style.
- Kimi-TTS enables zero-shot TTS with 3-second prompts, preserving timbre, emotion, and style, trained on 1M hours of synthetic data and refined via reinforcement learning.
- Kimi-VC performs voice conversion to transfer diverse in-the-wild speech into the Kimi-Audio speaker’s timbre while preserving style, emotion, and accent, fine-tuned using the voice actor’s recordings.
-
For audio-to-text chat, open-source text datasets (Table 2) are used, with user queries converted to speech. Text is preprocessed by:
- Filtering out complex content (math, code, tables, multilingual text, or long inputs).
- Rewriting for colloquialism and clarity.
- Converting single-turn complex instructions into multi-turn, concise interactions.
Method
The Kimi-Audio model is structured as a unified framework for audio understanding, generation, and conversation, integrating three primary components: an audio tokenizer, an audio LLM, and an audio detokenizer. The overall architecture is designed to process multimodal inputs and generate both text and audio outputs within a single model. As shown in the framework diagram, the system begins with an audio tokenizer that processes raw audio input to produce discrete semantic tokens and continuous acoustic features. These representations are then fed into the audio LLM, which employs a shared transformer architecture for cross-modal processing. The shared layers, initialized from a pre-trained text LLM, extract joint representations from both text and audio inputs, which are subsequently routed to specialized parallel heads: a text head for generating text tokens and an audio head for predicting discrete audio semantic tokens. The predicted audio tokens are passed to the audio detokenizer, which reconstructs coherent audio waveforms. This modular design enables seamless handling of diverse audio-language tasks, including speech recognition, audio understanding, and speech conversation, within a unified model framework.
The audio tokenizer employs a hybrid strategy to represent audio signals, combining discrete semantic tokens with continuous acoustic features. It leverages a supervised speech tokenizer derived from an automatic speech recognition (ASR) model, which uses vector quantization within a Whisper encoder architecture to convert continuous speech representations into discrete tokens at a 12.5Hz frame rate. Complementing this, a continuous feature representation is extracted from a pre-trained Whisper model, which operates at a 50Hz frame rate. To align the temporal resolution, an adaptor is introduced to downsample the Whisper features to 12.5Hz, and these downsampled features are concatenated with the embeddings of the discrete semantic tokens. This combined representation serves as the input to the audio LLM, enabling the model to benefit from both the semantic grounding of discrete tokens and the rich acoustic details of continuous features.
The audio LLM is designed to generate both text and audio outputs by processing the multimodal inputs from the tokenizer. It features a shared transformer architecture where the initial layers are shared across both modalities, allowing the model to learn cross-modal representations. After the shared layers, the architecture diverges into two parallel heads: a text head that autoregressively predicts text tokens, and an audio head that predicts discrete audio semantic tokens. The shared transformer layers and the text head are initialized from a pre-trained text LLM, ensuring strong language capabilities, while the audio head is initialized randomly. This initialization strategy allows the model to retain robust text understanding and generation while learning to process and generate audio information effectively.
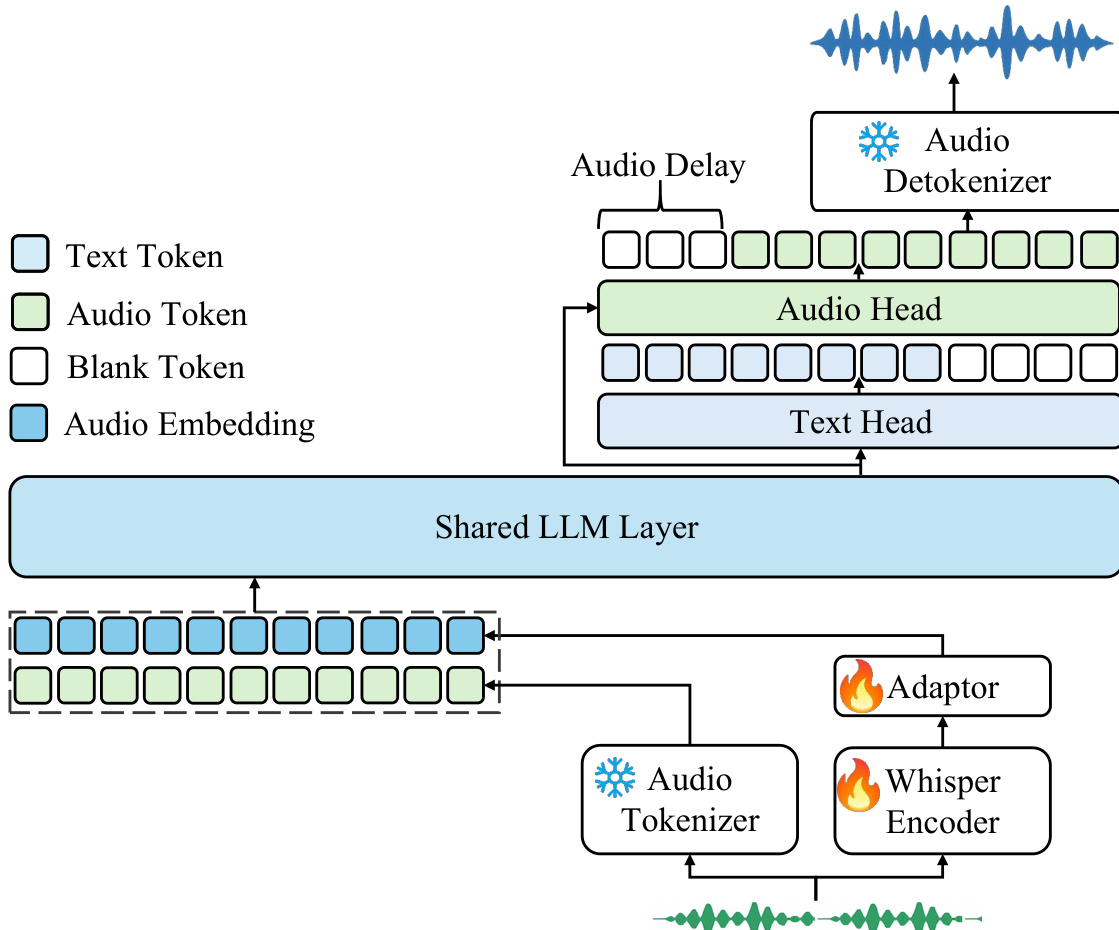
The audio detokenizer converts the discrete semantic tokens predicted by the audio LLM into coherent audio waveforms. It consists of two main components: a flow-matching module that transforms 12.5Hz semantic tokens into 50Hz mel-spectrograms, and a vocoder that generates waveforms from the mel-spectrograms. To reduce latency, a chunk-wise streaming detokenizer is implemented, which processes audio in chunks (e.g., 1 second per chunk). This approach uses a chunk-wise causal mask during training and inference, where each chunk is processed with the context of all previous chunks. To address intermittent issues at chunk boundaries, a look-ahead mechanism is introduced, which incorporates future semantic tokens from the next chunk into the current chunk's processing. This mechanism is training-free and only delays the generation of the first chunk by a few tokens, ensuring high-quality audio synthesis.
The pre-training of Kimi-Audio involves several tasks designed to learn knowledge from both audio and text domains and align them in the model's latent space. These tasks include unimodal pre-training for audio and text, audio-text mapping pre-training, and audio-text interleaving pre-training. For unimodal pre-training, next-token prediction is applied to text tokens and discrete semantic audio tokens separately. For audio-text mapping, ASR and TTS tasks are formulated to learn the alignment between audio and text. For interleaving pre-training, three tasks are designed: audio to semantic token interleaving, audio to text interleaving, and audio to semantic token + text interleaving. The model is initialized from the Qwen2.5 7B model and extended with semantic audio tokens and special tokens. Pre-training is conducted using 585B audio tokens and 585B text tokens with a specific task weight, and the continuous acoustic feature extractor is initially frozen and later fine-tuned.
The training of the audio detokenizer is conducted in three stages. First, both the flow-matching model and the vocoder are pre-trained on a large amount of audio data to learn diverse timbre, prosody, and quality. Second, a chunk-wise fine-tuning strategy with dynamic chunk sizes is applied on the same pre-training data. Finally, the model is fine-tuned on high-quality single-speaker recording data to enhance the quality of the generated audio.
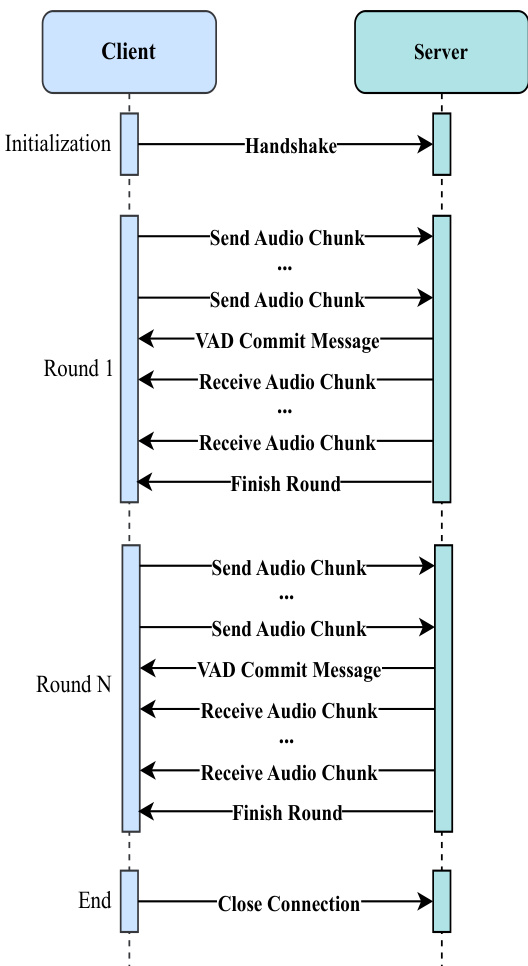
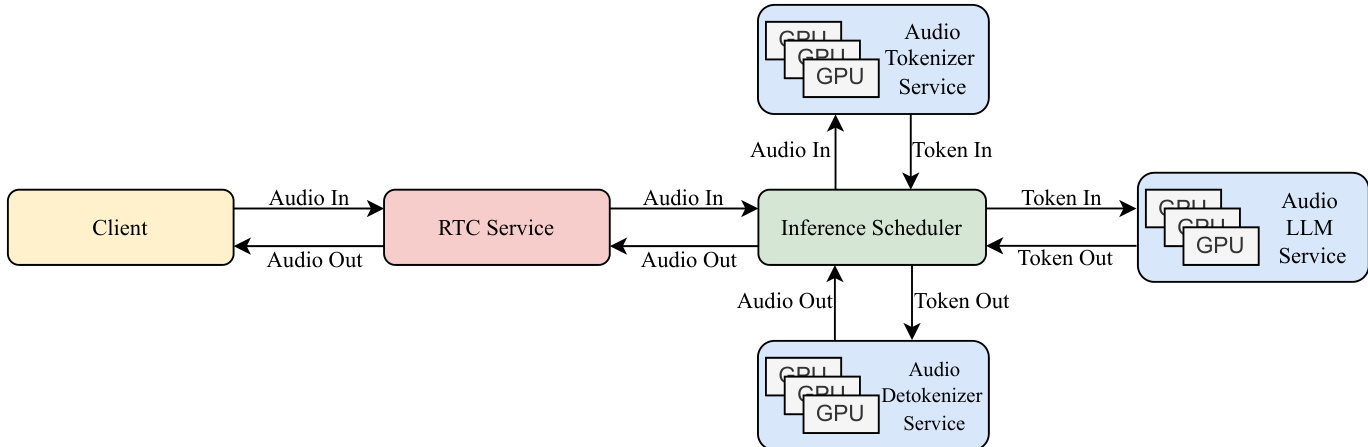
Inference and deployment of Kimi-Audio are designed for real-time speech-to-speech conversation. The workflow involves the client sending audio chunks to the server, which processes the input using the audio tokenizer, audio LLM, and audio detokenizer. The server returns audio chunks to the client, which plays them back to the user. The production deployment architecture is modular, with services for the audio tokenizer, audio LLM, and audio detokenizer, each equipped with load balancers and multiple inference instances to handle requests in parallel. The Inference Scheduler manages the conversation flow, maintaining conversation history and coordinating the processing of each interaction round.
Experiment
- Conducted supervised fine-tuning (SFT) on audio understanding, speech conversation, and audio-to-text chat data to enhance instruction following and audio processing capabilities.
- Fine-tuned Kimi-Audio for 2–4 epochs using AdamW optimizer with cosine decay learning rate (1e-5 to 1e-6) and 10% warmup tokens.
- Developed an open-source evaluation toolkit addressing reproducibility issues in audio foundation models, featuring standardized WER calculation and GPT-4o-mini-based intelligent judging for semantic evaluation.
- Achieved state-of-the-art results on ASR: 1.28 WER (LibriSpeech test-clean), 0.60 WER (AISHELL-1), and 2.56 WER (AISHELL-2 ios), outperforming Qwen2-Audio-base and Qwen2.5-Omni.
- Excelled in audio understanding: 73.27 on MMAU sound category, 60.66 on speech category, 59.13 on MELD emotion recognition, and top scores on non-speech sound and acoustic scene classification tasks.
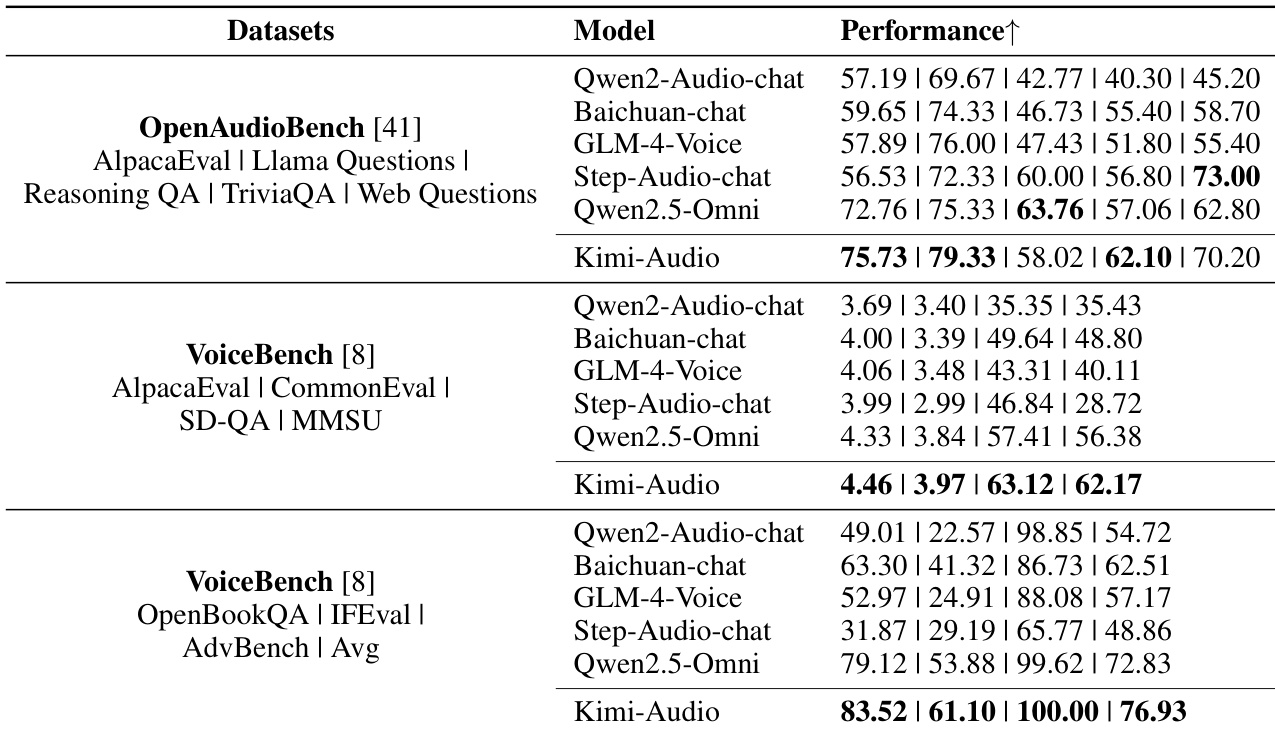
- Achieved SOTA performance on audio-to-text chat: led on OpenAudioBench (AlpacaEval, Llama Questions, TriviaQA) and outperformed all baselines on VoiceBench (e.g., 4.46 AlpacaEval, 100.00 Advbench).
- Demonstrated strong end-to-end speech conversation abilities: achieved 3.90 average human rating (1–5 scale), highest in emotion control and empathy, second-highest overall after GPT-4o (4.06).
The authors use a structured approach to define pre-training tasks for Kimi-Audio, categorizing them into audio/text unimodal, audio-text mapping, and audio-text interleaving tasks with distinct formulations and weights. This design emphasizes the importance of audio-to-text and text-to-audio alignment while incorporating interleaved audio-text interactions to enhance multimodal understanding.
The authors use the table to evaluate Kimi-Audio's performance on audio understanding tasks across multiple benchmarks, including MMAU, ClothoAQA, VocalSound, Nonspeech7k, MELD, TUT2017, and CochlScene. Results show that Kimi-Audio achieves the highest scores on most benchmarks, demonstrating superior performance in understanding music, sound events, and speech compared to other models.

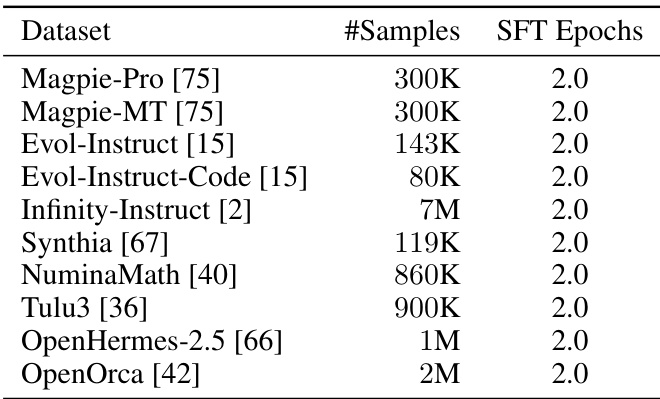
The authors use a consistent fine-tuning strategy across multiple SFT datasets, training Kimi-Audio for 2.0 epochs on each dataset with the same hyperparameters. This uniform approach ensures a fair comparison of model performance across different data sources during supervised fine-tuning.
The authors use the OpenAudioBench and VoiceBench datasets to evaluate Kimi-Audio's performance in audio-to-text chat tasks, comparing it against several baseline models. Results show that Kimi-Audio achieves state-of-the-art performance on multiple sub-tasks, including AlpacaEval, Llama Questions, and TriviaQA, and outperforms all compared models on key metrics such as SD-QA, MMSU, and OpenBookQA.
The authors evaluate Kimi-Audio's speech conversation capabilities against several models using human ratings across dimensions such as emotion control, empathy, and style control. Results show that Kimi-Audio achieves the highest scores in speed control and emotion control, and it attains the highest overall average score of 3.90, outperforming all other models except GPT-4o.
