Command Palette
Search for a command to run...
DreamO: إطار موحد للتخصيص الصوتي
DreamO: إطار موحد للتخصيص الصوتي
الملخص
في الآونة الأخيرة، أظهرت الأبحاث الواسعة حول التخصيص الصوري (مثل الهوية، الموضوع، الأسلوب، الخلفية، إلخ) قدرات قوية على التخصيص في النماذج التوليدية الضخمة. ومع ذلك، فإن معظم النهج المُعتمدة مصممة لمهام محددة فقط، مما يحد من قدرتها على التعميم عند دمج أنواع مختلفة من الشروط. لا يزال تطوير إطار موحد لتخصيص الصور تحديًا مفتوحًا. في هذه الورقة، نقدم "DreamO"، وهو إطار لتخصيص الصور مصمم لدعم مجموعة واسعة من المهام، مع تسهيل التكامل السلس لعدة أنواع من الشروط. بشكل خاص، يستخدم DreamO إطارًا يعتمد على نموذج التحويل التدرجي (DiT) لمعالجة مدخلات من أنواع مختلفة بشكل موحد. أثناء التدريب، نقوم ببناء مجموعة بيانات تدريب ضخمة تتضمن مهام تخصيص متنوعة، ونُدخل قيدًا للترشيح المميز (feature routing constraint) لتمكين استرجاع دقيق للمعلومات ذات الصلة من الصور المرجعية. بالإضافة إلى ذلك، نصمم استراتيجية مكان مخصص (placeholder strategy) تربط أماكن مخصصة بشروط معينة في مواقع محددة، مما يتيح التحكم في موقع الشروط في النتائج المولدة. علاوة على ذلك، نستخدم استراتيجية تدريب متدرجة تتكون من ثلاث مراحل: مرحلة أولية تركز على مهام بسيطة باستخدام بيانات محدودة لبناء اتساق أساسي، ومرحلة تدريب شاملة لتعزيز قدرات التخصيص بشكل شامل، ومرحلة نهائية للتوافق النوعي لتصحيح الانحيازات النوعية الناتجة عن البيانات منخفضة الجودة. تُظهر التجارب الواسعة أن DreamO قادرة على أداء مهام تخصيص الصور المختلفة بجودة عالية، ودمج مرونة لعدة أنواع من الشروط التحكمية.
One-sentence Summary
The authors, from ByteDance's Intelligent Creation Team and Peking University, propose DreamO, a unified diffusion transformer-based framework that enables high-fidelity, multi-condition image customization by introducing a feature routing constraint and a placeholder strategy to disentangle and precisely control identity, style, subject, and try-on attributes, achieving seamless integration of diverse conditions with strong generalization and high-quality generation.
Key Contributions
-
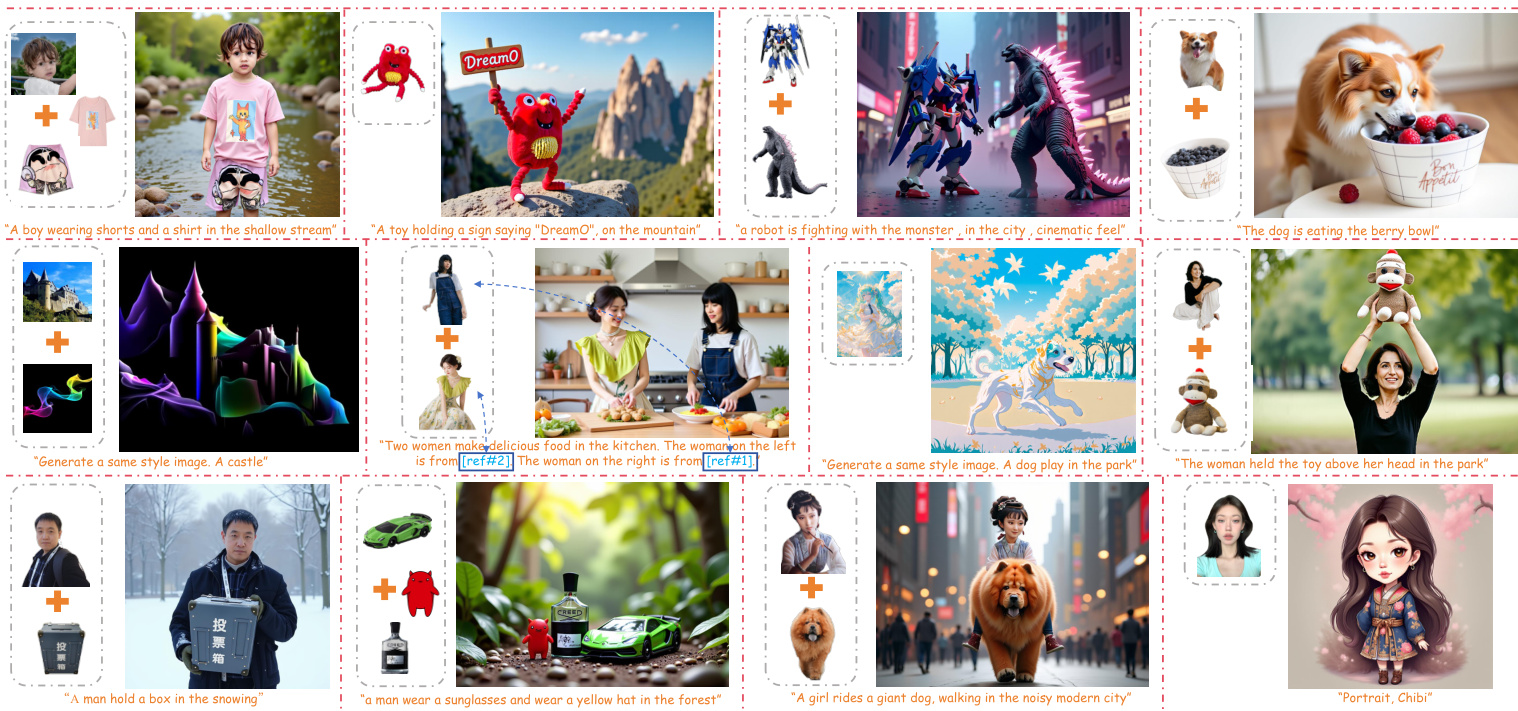
DreamO presents a unified framework for image customization that supports diverse tasks—such as identity preservation, style transfer, and virtual try-on—by leveraging a pre-trained diffusion transformer (DiT) with minimal additional training, enabling seamless integration of multiple condition types.
-
The method introduces a feature routing constraint during training to enhance content fidelity and disentangle different control conditions by exploiting internal representation correspondences, while a placeholder strategy allows precise spatial control over condition placement in generated images.
-
Through a progressive training strategy and large-scale multi-task data, DreamO achieves stable convergence and high-quality results across complex customization scenarios, outperforming existing task-specific and multi-condition approaches in both visual quality and flexibility.
Introduction
The authors leverage diffusion transformers (DiT) to address the growing need for flexible, high-quality image customization in applications like identity preservation, style transfer, and virtual try-on. Prior approaches either focus on single tasks with rigid condition interactions or rely on general-purpose models that lack specialized design for multi-condition control, leading to poor fidelity and limited integration. DreamO introduces a unified framework that processes diverse conditions—identity, style, subject, and layout—through a shared input sequence, using a feature routing constraint to ensure precise, disentangled control. It further employs a placeholder strategy for spatial placement and a progressive training regimen to stabilize learning across complex, multi-concept scenarios, enabling a single model to achieve high-fidelity, flexible customization with minimal training overhead.
Dataset
- The dataset is composed of multiple task-specific subsets collected and constructed to support generalized image customization across identity, subject, try-on, style, and routing tasks.
- Identity paired data: 150K photorealistic and 60K stylized identity pairs are generated using PuLID-FLUX and PuLID-SDXL, with mutual reference images or text prompts to guide style variation.
- Subject-driven data: 200K single-subject images from Subject200K are augmented with 100K character-related paired data retrieved via semantic search. For multi-subject tasks, two-column images are created by concatenating Subject200K samples, and the X2I-subject dataset is incorporated. A MovieGen-inspired pipeline enhances human-driven generation.
- Try-on data: 500K paired images are built from web-crawled model-clothing pairs and a two-step process involving high-quality model image collection, clothing segmentation, and pairing. All data undergo manual filtering for quality.
- Style-driven data: For text-guided style transfer, an internal SDXL-based model generates images with consistent style but varying content. For image-guided style transfer, paired style reference, content reference, and target images are created using Canny-guided Flux to derive content references.
- Routing mask extraction: LISA is used to generate object masks conditioned on text prompts; InternVL provides object descriptions in complex cases to support label generation for routing constraints.
- Data is processed with task-specific pipelines: scene detection and object tracking via Mask2Former, cross-clip instance matching using SigLip embeddings and clustering.
- During training, the data is combined into a mixture with task-specific ratios, enabling emergent cross-task capabilities such as joint identity and try-on customization, despite no explicit training on such combinations.
Method
The authors leverage the Diffusion Transformer (DiT) framework as the core denoising network, which processes image and text inputs in a unified manner by patchifying the 2D image latent into a sequence of 1D tokens. This approach is built upon the Flux-1.0-dev model, which serves as the base architecture for the proposed method. The framework supports flexible condition inputs, where multiple condition images are encoded into the same latent space using the Variational Autoencoder (VAE) component of Flux. These condition tokens are then concatenated with the text and image tokens along the sequence dimension and fed into the DiT model. To ensure proper alignment of positional information, a condition mapping layer is introduced at the input of Flux, where the position embeddings of condition tokens are aligned with those of the noisy latent using Rotary Position Embedding (RoPE). The authors extend this alignment by incorporating a trainable, index-wise condition embedding (CE) of size 10×c, which is directly added to the condition tokens. Additionally, Low-Rank Adaptation (LoRA) modules are integrated into the DiT architecture to enable efficient fine-tuning of the model parameters.
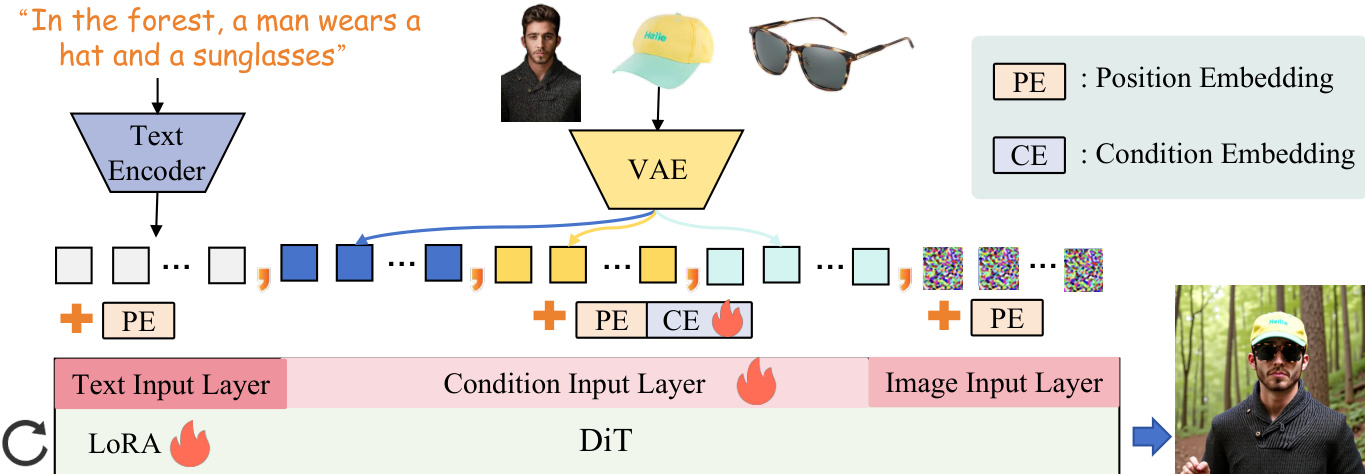
The method introduces a routing constraint mechanism to guide the attention of the model toward specific regions in the generated output. As shown in the figure below, cross-attention is established between the condition image tokens and the noisy image latent tokens within the DiT framework. The cross-attention map M is computed as M=dQcond,iKimgT, where Qcond,i represents the condition tokens of the i-th condition image and Kimg represents the tokens of the noisy image latent. To obtain a global response of the condition image across the generated output, the attention map is averaged along the condition token dimension, resulting in a response map M∈Rl. This response map is then used to compute a mean squared error (MSE) loss, Lroute, which optimizes the attention focus to align with the target subject mask. This constraint ensures that the model's attention is directed toward the relevant regions of the condition image, improving consistency and detail preservation in the generated output.
To further enhance the alignment between textual descriptions and condition inputs, the authors design a placeholder-to-image routing constraint. This mechanism establishes correspondences between textual placeholders and their corresponding condition images. During training, placeholders such as [ref#1] are appended to the text description, and the model learns to associate the text tokens of the placeholder with the condition image tokens. The routing constraint enforces that the similarity between the condition image Ci and its corresponding placeholder [ref#i] is maximized, while the similarity with other placeholders is minimized. This is achieved through a loss function Lholder that computes the MSE between the softmax of the attention scores and a binary matrix Bi, where the value is 1 only when the placeholder matches the condition image. This strategy ensures that the model correctly maps textual references to their respective visual inputs, improving the accuracy of multi-reference image generation.
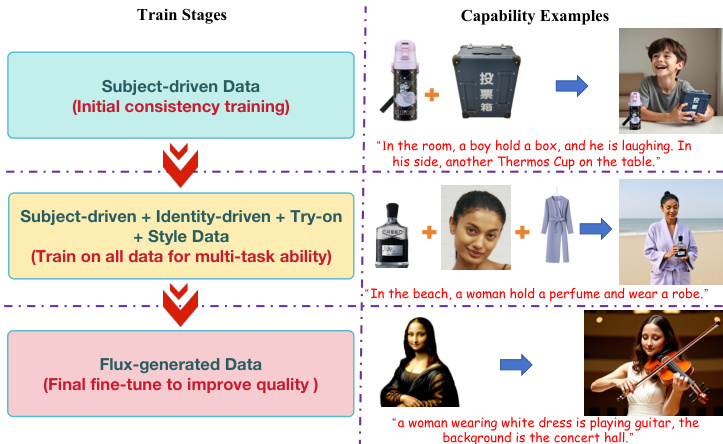
The overall training objective combines the diffusion loss, routing constraint loss, and placeholder routing loss into a single loss function: L=λdiff⋅Ldiff+λroute⋅Lroute+λholder⋅Lholder. The diffusion loss Ldiff is derived from the Flow Matching framework, where the model is trained to regress the target velocity given the noised latent, timestep, and condition. The routing and placeholder losses are designed to be computationally efficient, adding minimal overhead to the training process. The method also incorporates a probabilistic mechanism where normal text inputs are used with a 50% probability, allowing the model to handle both conditional and unconditional text inputs. The training pipeline proceeds in stages, starting with subject-driven data for initial consistency, followed by multi-task training on subject, identity, and style data, and concluding with fine-tuning on Flux-generated data to improve overall quality.
Experiment
- Progressive training strategy validates improved convergence and generation quality: initial warm-up on Subject200K enables fast learning of subject-driven generation, full-data tuning enhances multi-task performance, and image quality refinement realigns outputs with Flux's generative prior, significantly improving fidelity.
- On DreamBench and multi-subject benchmarks, DreamO achieves superior subject consistency (CLIP and Dino similarity) and text-following ability, outperforming methods like MS-Diffusion, OmniGen, and OminiControl.
- On Unsplash-50, DreamO achieves higher face similarity (ID cosine) and better text alignment (CLIP similarity) compared to PhotoMaker, InstantID, and PuLID.
- In virtual try-on, DreamO excels in both try-on accuracy (CLIP similarity to reference garment) and text-following ability, surpassing IMAGDressing which lacks text alignment.
- For style customization, DreamO achieves the highest style consistency (CSD similarity) and content consistency (CLIP similarity to prompt), outperforming StyleShot, StyleAlign, InstantStyle, DeaDiff, and CSGO.
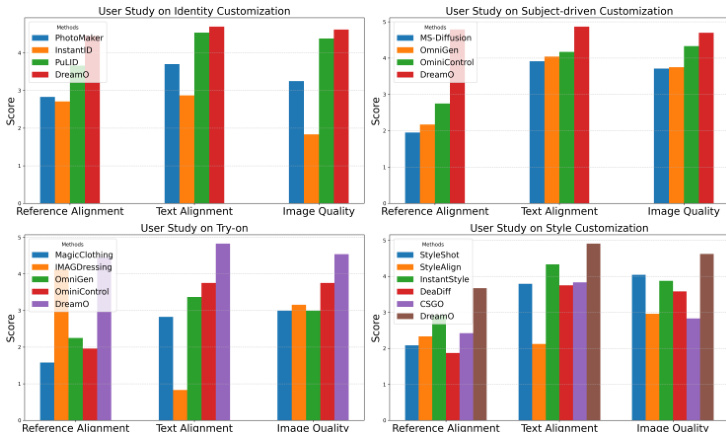
- User study confirms DreamO ranks highest in text alignment, reference alignment, and image quality across all tasks, with average scores above 4.0 out of 5.
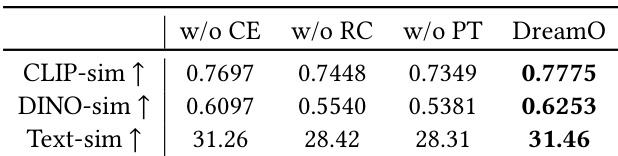
- Ablation studies verify that routing constraint and progressive training are critical: removing them degrades reference fidelity, causes condition coupling, and reduces consistency and text-following performance.
Results show that DreamO outperforms MS-Diffusion, OmniGen, and OminiControl in both single-subject and multi-subject customization tasks, achieving the highest CLIP-sim and DINO-sim scores for subject consistency and the highest text-sim for text-following ability. The model demonstrates superior performance in maintaining reference fidelity and text alignment across different conditions.

Results show that DreamO achieves the highest face similarity (0.607) and text similarity (0.2570) among the compared methods, outperforming PhotoMaker, InstantID, and PuLID in both identity customization metrics. The authors use these quantitative results to demonstrate DreamO's superior ability to preserve identity and follow text prompts in identity-driven generation tasks.

The authors conduct a user study to evaluate DreamO against several state-of-the-art methods across four customization tasks: identity, subject-driven, try-on, and style. Results show that DreamO achieves the highest scores in reference alignment, text alignment, and image quality across all tasks, indicating superior performance in aligning with user inputs and maintaining high-quality outputs.
Results show that DreamO outperforms ablated versions without condition embedding, routing constraint, or progressive training across all metrics. The full model achieves the highest CLIP-sim, DINO-sim, and text-sim values, demonstrating superior subject consistency and text-following ability.
Results show that DreamO achieves the highest Style-sim and Text-sim scores among all compared methods, indicating superior performance in style consistency and text alignment for style customization tasks. The model outperforms alternatives such as StyleAlign, StyleShot, InstantStyle, DEADiff, and CSGO in both metrics, demonstrating its effectiveness in maintaining reference style and following textual descriptions.
