Command Palette
Search for a command to run...
تقرير فني عن Kimi-VL
تقرير فني عن Kimi-VL
الملخص
نقدّم نموذج Kimi-VL، وهو نموذج مفتوح المصدر وفعال لذكاء اصطناعي متعدد الخصائص (Mixture-of-Experts) يُعنى بمعالجة الصور واللغة (VLM)، ويتميز بقدرات متقدمة في التفكير متعدد الوسائط، وفهم السياقات الطويلة، وقدرات قوية كـ"وكيل" (agent)، مع تفعيل فقط 2.8 مليار معلمة في معالج النص (Kimi-VL-A3B). يُظهر نموذج Kimi-VL أداءً متميزًا في مجالات صعبة ومتنوعة: كنموذج VLM عام، يتفوّق Kimi-VL في المهام متعددة الدورات (مثل OSWorld)، مُوازيًا النماذج الرائدة. علاوةً على ذلك، يُبدي قدرات ملحوظة في مهام متعددة وصعبة في مجالات الصور واللغة، تشمل فهم الصور والفيديوهات على مستوى الجامعات، وتحديد النصوص من الصور (OCR)، والتفكير الرياضي، وفهم الصور المتعددة. في تقييمات مقارنة، يُنافس بفعالية النماذج الفعّالة المتطورة مثل GPT-4o-mini وQwen2.5-VL-7B وGemma-3-12B-IT، ويتفوّق على GPT-4o في عدة مجالات حاسمة. كما يُقدّم Kimi-VL تقدّمًا ملحوظًا في معالجة السياقات الطويلة وفهمها بدقة. بفضل نافذة سياقية موسّعة تصل إلى 128K، يمكن لـKimi-VL معالجة مدخلات طويلة ومتنوعة، محقّقًا نتائج مبهرة بـ64.5 في LongVideoBench و35.1 في MMLongBench-Doc. كما يُمكّن مُشغّل الرؤية بذات الدقة الأصلية (MoonViT) من رؤية وفهم مدخلات بصرية فائقة الدقة، محقّقًا 83.2 في InfoVQA و34.5 في ScreenSpot-Pro، مع الحفاظ على تكاليف حسابية منخفضة في المهام الشائعة. بناءً على Kimi-VL، نقدّم نسخة متقدّمة تُعنى بالتفكير الطويل: Kimi-VL-Thinking-2506. تم تطوير هذا النموذج الجديد من خلال التدريب المُشرَف على سلسلة طويلة من التفكير (long chain-of-thought, CoT) وتعلم التقويم (reinforcement learning، RL)، ويُظهر قدرات قوية في التفكير على المدى الطويل (64.0 في MMMU، 46.3 في MMMU-Pro، 56.9 في MathVision، 80.1 في MathVista، 65.2 في VideoMMMU)، مع الحفاظ على قدرات عامة قوية. يمكن الوصول إلى الكود والنماذج بشكل عام عبر الرابط: https://github.com/MoonshotAI/Kimi-VL.
One-sentence Summary
The authors propose Kimi-VL, an efficient open-source Mixture-of-Experts vision-language model with a 2.8B-parameter activated decoder and native-resolution MoonViT encoder, enabling strong multimodal reasoning, long-context understanding (up to 128K), and high-resolution visual perception, outperforming models like GPT-4o in key domains while maintaining low computational cost; an advanced long-thinking variant, Kimi-VL-Thinking-2506, achieves state-of-the-art performance in long-horizon reasoning via chain-of-thought fine-tuning and reinforcement learning with only ~3B activated parameters.
Key Contributions
- Kimi-VL introduces an efficient open-source Mixture-of-Experts (MoE) vision-language model with only 2.8B activated parameters in its language decoder, enabling strong multimodal reasoning, long-context understanding up to 128K tokens, and advanced agent capabilities while maintaining low computational cost for common tasks.
- The model leverages a native-resolution vision encoder, MoonViT, to achieve state-of-the-art performance on high-resolution visual tasks such as InfoVQA (83.2) and ScreenSpot-Pro (34.5), outperforming several leading efficient VLMs on benchmarks like LongVideoBench (64.5) and MMLongBench-Doc (35.1).
- Kimi-VL-Thinking-2506, enhanced via long chain-of-thought supervised fine-tuning and reinforcement learning, achieves top-tier reasoning performance on complex benchmarks including 80.1 on MathVista and 65.2 on VideoMMMU, demonstrating that a model with only ~3B activated parameters can rival much larger models in long-horizon multimodal reasoning.
Introduction
The authors leverage a Mixture-of-Experts (MoE) architecture to build Kimi-VL, an open-source vision-language model that achieves strong multimodal reasoning, long-context understanding, and agent capabilities—key advancements for real-world AI assistants that must interpret complex visual and linguistic inputs. Prior open-source VLMs have lagged behind in efficiency and reasoning, often relying on dense models with limited context or no support for long chain-of-thought (CoT) reasoning. Kimi-VL overcomes these limitations with a 2.8B-parameter activated language decoder and a native-resolution MoonViT vision encoder, enabling high-fidelity perception and efficient processing of ultra-high-resolution images and long-form inputs (up to 128K tokens). The model excels across diverse benchmarks, including college-level reasoning, OCR, multi-image understanding, and long video analysis, outperforming larger models in several domains. The authors further introduce Kimi-VL-Thinking-2506, a long-thinking variant enhanced via CoT fine-tuning and reinforcement learning, which achieves state-of-the-art performance on complex reasoning tasks while maintaining low computational cost.
Dataset
- The dataset is composed of six primary multimodal data categories: caption, image-text interleaving, OCR, knowledge, video, and agent data, supplemented by a high-quality text-only corpus from Moonlight J. Liu et al. 2025a.
- Caption data includes open-source and in-house collections in English and Chinese, with strict limits on synthetic data to prevent hallucination; it undergoes filtering, deduplication, and resolution variation to ensure image-text alignment and vision tower robustness.
- Image-text interleaving data is sourced from open datasets and in-house materials like textbooks and webpages, with synthetic data used to enrich knowledge; a data reordering pipeline ensures correct image-text sequence preservation.
- OCR data spans single-page and multi-page documents, covering multilingual, dense, handwritten, and complex layouts (e.g., tables, diagrams, mermaid plots); extensive augmentation (rotation, distortion, noise) enhances robustness, and in-house data supports long-document understanding.
- Knowledge data is built from textbooks, research papers, and curated sources, processed via layout parsing and OCR; a standardized taxonomy ensures balanced coverage across domains, with an additional pipeline to extract pure textual content from infographics.
- Agent data is collected from virtual machine environments using heuristic methods, capturing screenshots and action logs across desktop, mobile, and web platforms; human-annotated multi-step trajectories with Chain-of-Thought reasoning are included to train planning and grounding capabilities.
- Video data comes from open and in-house sources, covering diverse durations, scenes, and tasks; long videos are processed with dense captioning pipelines, and synthetic caption proportions are limited to reduce hallucination risk.
- The text-only pre-training corpus (Moonlight) spans English, Chinese, code, math/reasoning, and knowledge domains, with domain-specific filtering and quality validation; sampling ratios are optimized via empirical evaluation to balance knowledge depth and generalization.
- During training, the authors use a data-driven mixture strategy: high-performing subsets are upsampled, while diverse document types are preserved at balanced ratios to maintain model generalization.
- For instruction tuning, a seed dataset is created via human annotation, then expanded using model-generated responses ranked and refined by annotators; reasoning tasks use rejection sampling with a reward model to filter low-quality chains of thought.
- Reasoning data is synthesized via a rejection sampling pipeline using a powerful long-CoT model (Kimi k1.5), with multi-step reasoning trajectories generated for math, science, and VQA tasks, and filtered using both model evaluation and rule-based rewards.
- The model is evaluated on a comprehensive suite of benchmarks: MM-MMU, MMBench, MMStar, MMVet, RealWorldQA, AI2D, MathVision, MathVista, BLINK, InfoVQA, OCRbench, VideoMMMU, MMVU, Video-MME, MLVU, LongVideoBench, EgoSchema, VSI-Bench, and TOMATO, covering perception, reasoning, OCR, video understanding, and long-context tasks.
- Agent evaluation uses ScreenSpot V2, ScreenSpot Pro, OSWorld, and WindowsAgentArena, assessing GUI grounding, task planning, and performance in real-world operating systems (Ubuntu, Windows, macOS) with interactive, application-level tasks.
Method
The Kimi-VL model architecture is composed of three primary components: a native-resolution vision encoder, an MLP projector, and a Mixture-of-Experts (MoE) language model. The vision encoder, named MoonViT, is designed to process images at their native resolutions without requiring complex sub-image splitting and splicing operations. This is achieved by employing a packing method where images are divided into patches, flattened, and concatenated into 1D sequences. This approach allows MoonViT to leverage the same core computation operators and optimization techniques as a language model, such as variable-length sequence attention supported by FlashAttention, thereby maintaining high training throughput for images of varying resolutions.

As shown in the figure below, MoonViT processes images of different resolutions, including small images, long videos, and fine-grained scenes, directly. The continuous image features extracted by MoonViT are then passed to an MLP projector. This projector consists of a two-layer MLP that first applies a pixel shuffle operation to compress the spatial dimensions of the image features, followed by a projection into the dimension of the language model's embeddings. The resulting features are then fed into the MoE language model for further processing.
The language model component of Kimi-VL is based on the Moonlight model, an MoE architecture with 2.8B activated parameters and 16B total parameters, similar in structure to DeepSeek-V3. The model is initialized from an intermediate checkpoint of Moonlight's pre-training stage, which has processed 5.2T tokens of pure text data and supports an 8192-token context length. This initialization is followed by joint pre-training on a combination of multimodal and text-only data, totaling 2.3T tokens.
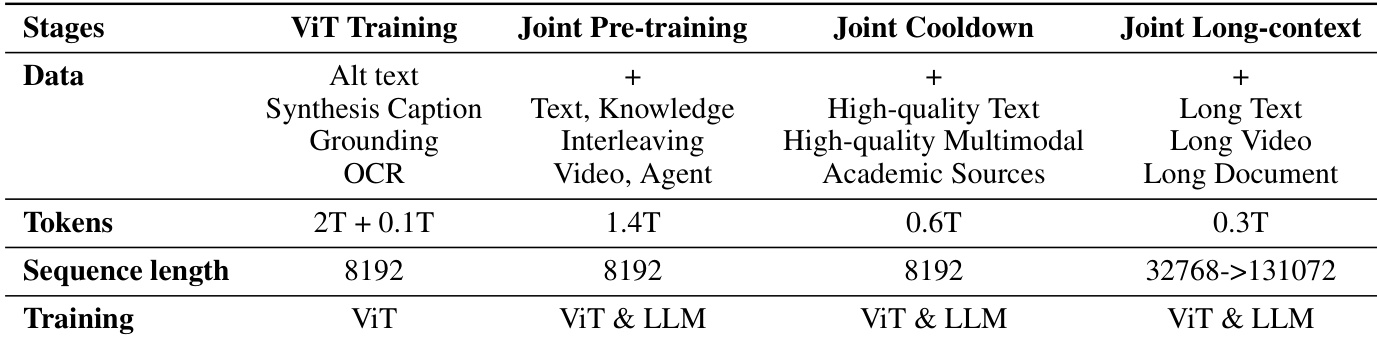
The pre-training process of Kimi-VL is structured into several stages, consuming a total of 4.4T tokens after the initial text-only pre-training of the language model. To preserve text capabilities, all stages that update the language model are conducted as joint training stages. The training begins with text pre-training on 5.2T tokens of pure text data, followed by joint pre-training on 1.4T tokens of multimodal data. This is followed by a joint cooldown phase on 0.6T tokens of high-quality text and multimodal data, and finally a joint long-context phase on 0.3T tokens of long text, long video, and long document data. Each stage resumes the learning rate scheduler from the previous stage to ensure a smooth transition.

Following pre-training, Kimi-VL undergoes a series of post-training stages. The first is joint supervised fine-tuning (SFT), where the model is fine-tuned with instruction-based data to enhance its ability to follow instructions and engage in dialogue. This stage uses a mixture of pure-text and vision-language SFT data, with supervision applied only to answers and special tokens. The model is trained at a sequence length of 32k tokens for one epoch, followed by another epoch at 128k tokens, with a learning rate schedule that decays and then re-warms up.
The second post-training stage is long-CoT supervised fine-tuning, which employs a small, high-quality warmup dataset of long-CoT reasoning paths for both text and image inputs. This dataset is designed to encapsulate key cognitive processes such as planning, evaluation, reflection, and exploration. A lightweight SFT on this dataset primes the model to internalize these multimodal reasoning strategies, leading to more detailed and logically coherent responses.
The final stage is reinforcement learning (RL), which further advances the model's reasoning abilities. The RL algorithm, a variant of online policy mirror descent, iteratively refines the policy model to improve problem-solving accuracy. The objective function is regularized by relative entropy to stabilize policy updates. Each training iteration samples a problem batch, and the model parameters are updated using the policy gradient. To enhance efficiency, a length-based reward penalizes excessively long responses, and curriculum and prioritized sampling strategies focus training on the most pedagogically valuable examples.
Experiment
- Pre-training stages: Kimi-VL undergoes four stages—ViT training (2T tokens), alignment (0.1T tokens), joint pre-training (1.4T tokens), and joint cooldown (data-augmented with synthetic content). The final long-context activation stage extends context length to 128K tokens with 25% long-data ratio, enabling robust long-form understanding.
- Needle-in-a-Haystack (NIAH) test: Achieves high recall accuracy on haystacks up to 128K tokens, validating strong long-context retrieval capability.
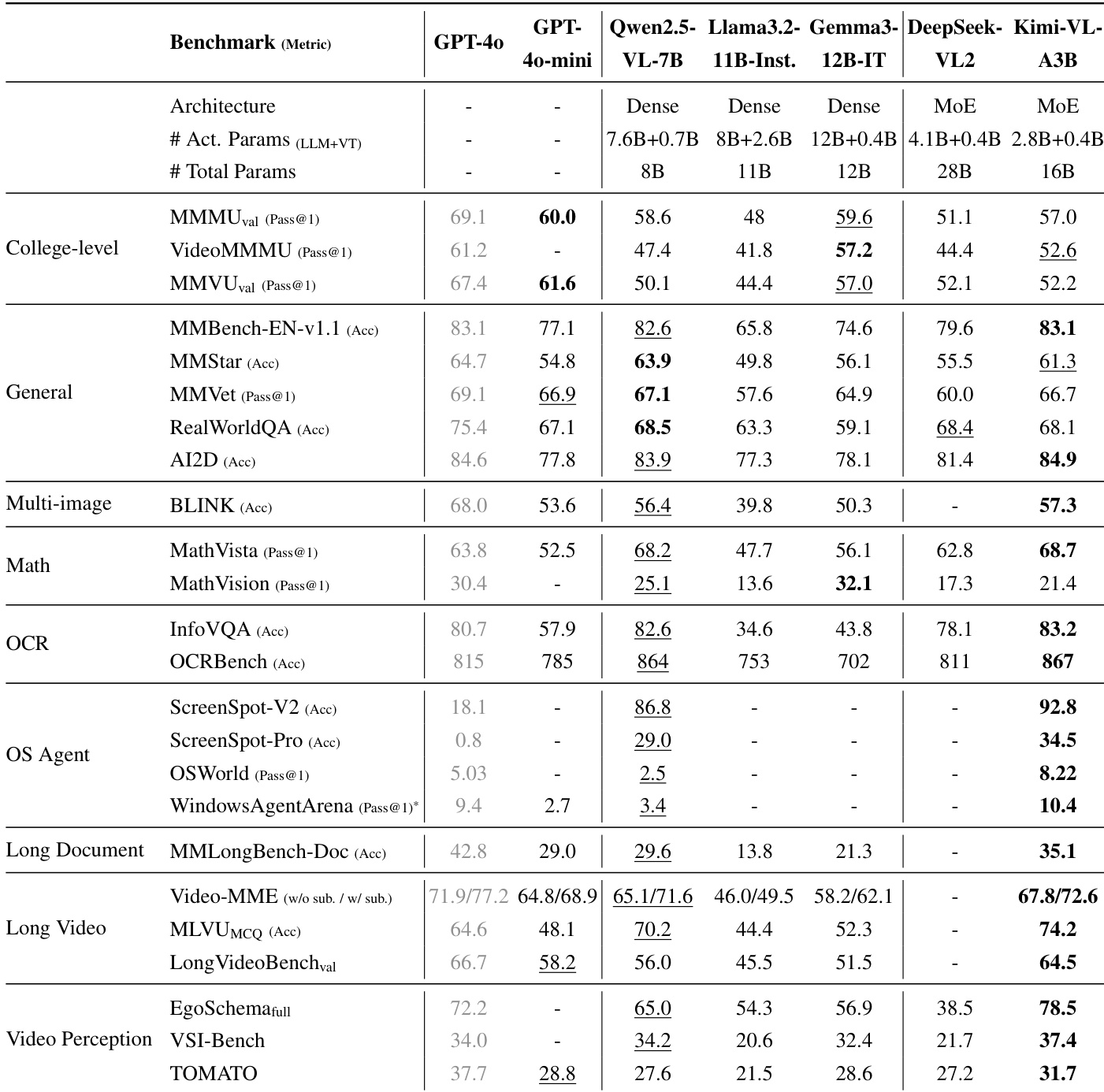
- On MMMU validation set: Achieves 57.0%, outperforming DeepSeek-VL2 (51.1%) and matching larger models like Qwen2.5-VL-7B (58.6%).
- On MathVista: Scores 68.7%, surpassing GPT-4o (63.8%) and Qwen2.5-VL-7B (68.2%), demonstrating strong visual mathematical reasoning.
- On OCRBench: Achieves 86.7%, outperforming GPT-4o-mini (78.5%) and DeepSeek-VL2 (81.1%), highlighting superior OCR and document understanding.
- On MMBench-EN-v1.1: Achieves 83.1%, outperforming all efficient VLMs and matching GPT-4o.
- On long-form content: Scores 35.1% on MMLongBench-Doc (outperforming GPT-4o-mini and Qwen2.5-VL-7B), 72.6% on Video-MME (w/ subtitles), and 74.2% on MLVU MCQ, showing strong long-document and video comprehension.
- On agent tasks: Achieves 8.22% on OSWorld and 10.4% on WindowsAgentArena, surpassing GPT-4o (5.03% and 9.4%).
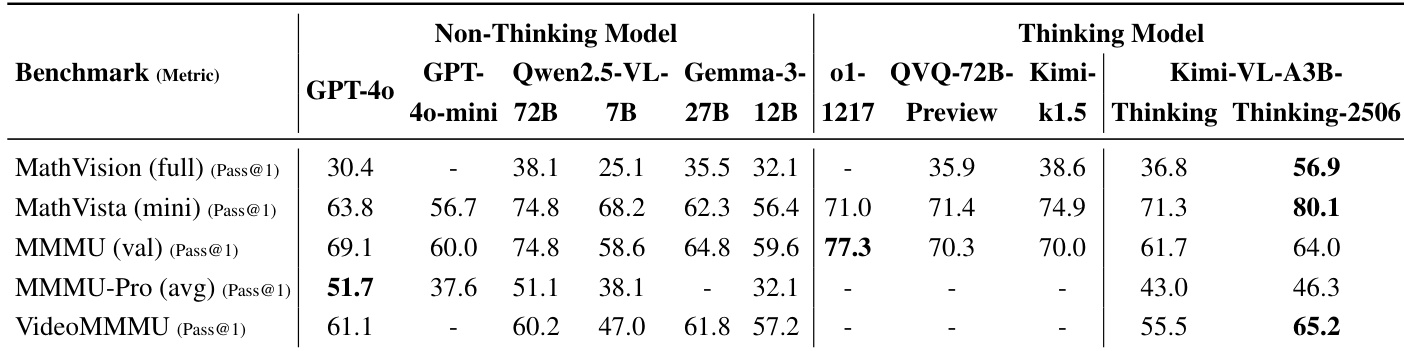
- Kimi-VL-Thinking: Improves by 2.6% on MathVista, 4.7% on MMMU, and 15.4% on MathVision; reaches 71.3% on MathVista and 61.7% on MMMU, outperforming GPT-4o and larger models with only 3B activated parameters.
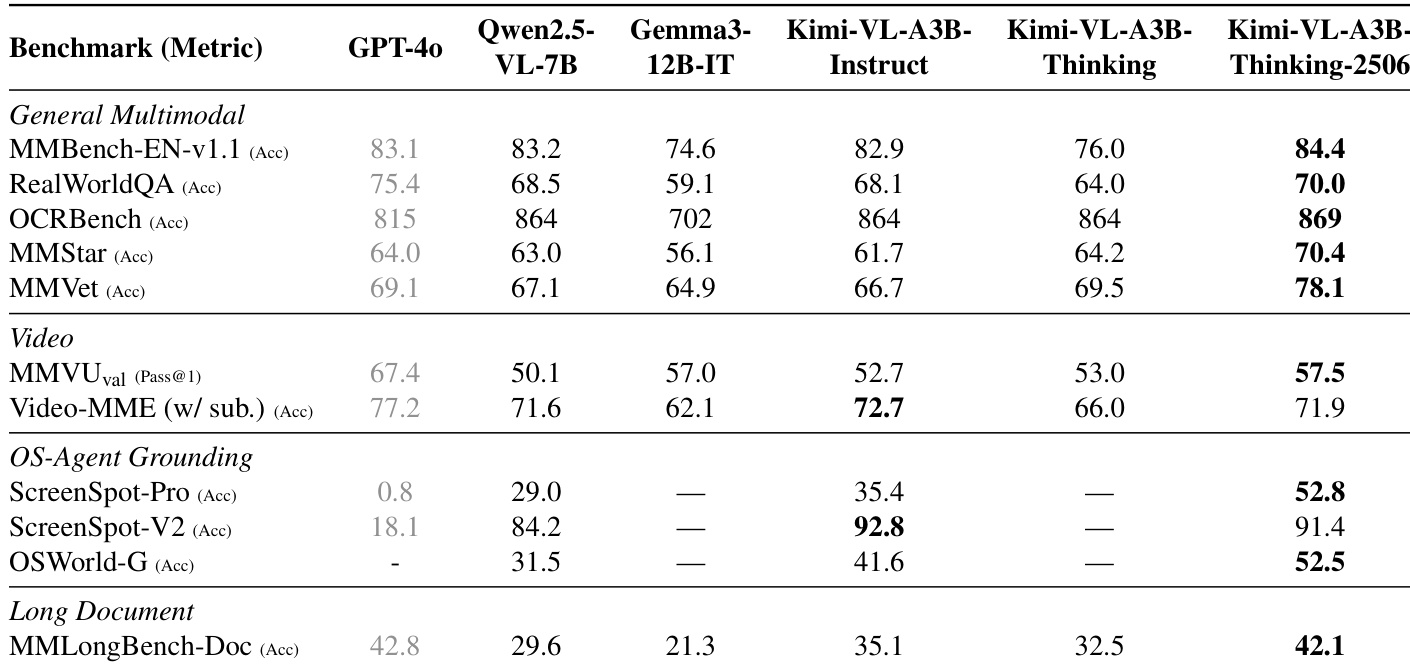
- Kimi-VL-A3B-Thinking-2506: Achieves 56.9% on MathVision (+20.1% over base thinking model), 80.1% on MathVista, 46.3% on MMMU-Pro, and 42.1% on MMLongBench-Doc; reduces average output tokens by 20%, improving efficiency while maintaining strong performance across vision, video, and long-context tasks.
The authors use Kimi-VL-A3B-Thinking-2506 to achieve state-of-the-art results on multiple multimodal benchmarks, outperforming larger models in several categories. The model demonstrates strong performance across general visual understanding, mathematical reasoning, and long-form content comprehension, while also improving efficiency by reducing output token length.
Results show that Kimi-VL-A3B-Thinking-2506 achieves the highest accuracy across most general multimodal and video benchmarks, outperforming other models including GPT-4o and Qwen2.5-VL-7B, while also demonstrating strong performance on OS-agent grounding and long-document tasks. The model maintains competitive results on general vision-language tasks and improves efficiency by reducing output token length compared to its predecessor.
Results show that Kimi-VL-A3B-Thinking-2506 achieves state-of-the-art performance on reasoning benchmarks, outperforming other models including GPT-4o and QVQ-72B, with significant improvements in accuracy and reduced token consumption compared to its predecessor. The model also maintains strong general multimodal understanding capabilities, demonstrating competitive results across various vision-language tasks.
Results show that Kimi-VL maintains high recall accuracy for both text and video haystacks up to 128K tokens, with performance remaining at 100.0% across all text haystack lengths and 91.7% for the longest video haystack. The model demonstrates robust long-context understanding, as evidenced by its ability to retrieve needles in haystacks of varying lengths, including the maximum 131,072-token sequence.

The authors use a four-stage pre-training process for Kimi-VL, starting with standalone ViT training on image-text pairs using a combination of SigLIP and caption generation losses, followed by joint pre-training, cooldown, and long-context activation stages that progressively integrate language and multimodal capabilities. Results show that the model achieves a sequence length of up to 131,072 tokens in the final long-context stage, with data composition shifting to include more long-form text, video, and document inputs to enable robust long-context understanding.