Command Palette
Search for a command to run...
كاميرا افتراضية مستقرة: توليد توليد منظور باستخدام نماذج التشتت
كاميرا افتراضية مستقرة: توليد توليد منظور باستخدام نماذج التشتت
Jensen Zhou Hang Gao Vikram Voleti Aaryaman Vasishta Chun-Han Yao Mark Boss Philip Torr Christian Rupprecht Varun Jampani
الملخص
نقدّم نموذج Seva (Stable Virtual Camera)، وهو نموذج توزيع عام قادر على إنشاء مناظر جديدة لمشهد معين، بالاعتماد على أي عدد من المناظر المدخلة والكاميرات المستهدفة. تعاني الطرق الحالية من صعوبة في إنتاج تغيرات كبيرة في الزاوية المرئية أو عينات سلسة زمنيًا، مع الاعتماد على تكوينات محددة للمهام. يتجاوز نهجنا هذه القيود من خلال تصميم نموذج بسيط، ووصفة تدريب محسّنة، واستراتيجية عينة مرنة تُعمّم عبر مهام توليد المناظر عند الاختبار. نتيجة لذلك، تُحافظ العينات الناتجة على اتساق عالٍ دون الحاجة إلى تقطيع إضافي يعتمد على تمثيل ثلاثي الأبعاد، مما يُبسط عملية توليد المناظر في البيئات الواقعية. علاوةً على ذلك، نُظهر أن طريقة عملنا قادرة على إنتاج مقاطع فيديو عالية الجودة تمتد حتى نصف دقيقة مع إغلاق دوري سلس. تُظهر الاختبارات الواسعة أن Seva يتفوّق على الطرق الحالية عبر مختلف المجموعات البيانات والبيئات. صفحة المشروع تحتوي على الكود والنماذج: https://stable-virtual-camera.github.io/.
One-sentence Summary
The authors, from Stability AI, University of Oxford, and UC Berkeley, propose SEVA, a generalist diffusion model that enables high-fidelity, temporally coherent view synthesis across diverse camera trajectories without 3D distillation, leveraging a simple yet flexible design that outperforms prior methods in consistency and scalability for real-world applications.
Key Contributions
-
STABLE VIRTUAL CAMERA (SEVA) addresses the challenge of generative novel view synthesis in uncontrolled environments by enabling high-quality image and video generation across diverse camera trajectories, supporting any number of input and target views without requiring rigid task configurations or explicit 3D representations.
-
The method introduces a two-pass procedural sampling strategy and a training recipe that jointly optimizes for large viewpoint changes and temporal smoothness, allowing seamless video generation of up to 30 seconds with precise camera control and loop closure, all without relying on NeRF distillation.
-
Extensive benchmarking across 10 datasets shows SEVA outperforms prior state-of-the-art methods, achieving +1.5 dB PSNR over CAT3D in its native setup and demonstrating strong generalization to real-world user captures with input views ranging from 1 to 32.
Introduction
The authors leverage diffusion models to address the challenges of generative novel view synthesis (NVS) in uncontrolled, real-world settings, where sparse input views and flexible camera control are common. Prior methods face two key limitations: they either struggle with large viewpoint changes or fail to produce temporally smooth video outputs, and many require NeRF distillation to enforce 3D consistency, complicating the pipeline. Additionally, existing models are often task-specific—either optimized for set-based view generation or trajectory-based video synthesis—limiting their flexibility. The authors introduce STABLE VIRTUAL CAMERA (SEVA), a unified diffusion-based NVS model that eliminates explicit 3D representations, enabling high-quality, temporally coherent view synthesis across arbitrary camera trajectories with any number of input and target views. Their approach combines a carefully designed training strategy that covers both small and large viewpoint changes, and a two-pass procedural sampling method that ensures smooth interpolation and long-trajectory stability. SEVA achieves state-of-the-art performance across diverse datasets and settings, demonstrating high-fidelity videos up to 30 seconds with seamless loop closure, all without NeRF distillation.
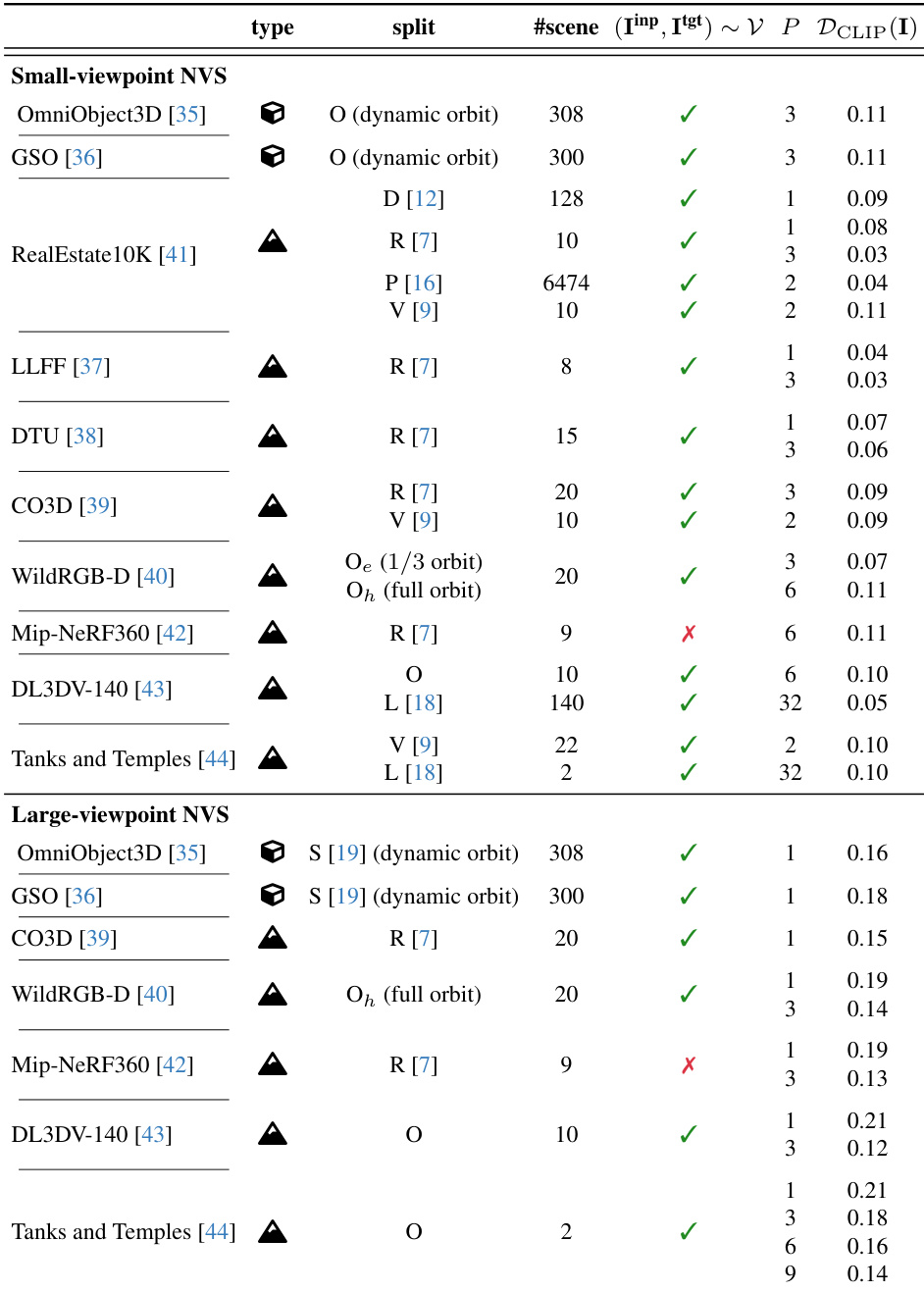
Dataset
- The benchmark dataset comprises 10 publicly available datasets spanning object-level, object-centric scene, and full scene categories, including OmniObject3D, GSO, LLFF, DTU, CO3D, WildRGBD, RealEstate10K, Mip-NeRF 360, DL3DV-140, and Tanks and Temples.
- The dataset is structured into multiple splits used in prior works—4DiM (D), ViewCrafter (V), pixelSplat (P), ReconFusion (R), SV3D (S), Long-LRM (L)—as well as a newly defined split (O) that uses all available scenes unless otherwise specified.
- For the O split, test scenes are selected as follows: TRAIN and TRUCK from Tanks and Temples; 10 specific scenes from DL3DV-140 identified by unique IDs; 20 scenes from WildRGBD, each with a specific object and scene identifier (e.g., BALL/SCENE_563); and full test sets for all other datasets.
- Input views (P) vary from sparse (P=1) to semi-dense (P=3), enabling evaluation across different input flexibility regimes.
- The benchmark distinguishes between small-viewpoint and large-viewpoint novel view synthesis (NVS) based on CLIP feature disparity between input and target views. Tasks with average CLIP distance ≤ 0.11 are classified as small-viewpoint (emphasizing interpolation smoothness), while those with > 0.11 are large-viewpoint (assessing generation capacity).
- For WildRGBD, two difficulty levels are defined: O_e (easy) uses one-third of the original sequence (~120° rotation), while O_h (hard) uses the full sequence (~360° rotation). In both cases, 21 frames are uniformly subsampled, P frames are randomly selected as inputs, and the rest serve as targets.
- For DL3DV-140 and Tanks and Temples, target frames are selected every 8th frame in the original sequence. Remaining frames are clustered using K-means (K=32) on a 6D vector combining camera translation and direction to ensure diverse input coverage.
- The authors use the data for training and evaluation across multiple splits, with model performance reported on both small- and large-viewpoint setups. For P=1, camera normalization unit length is swept to address scale ambiguity.
- All results are computed using the same input and target view configurations as prior works, with the exception of the O split, which uses custom scene and view selections.
- Metadata such as CLIP-based disparity and view selection logic are constructed to enable consistent and reproducible evaluation across different NVS tasks.
Method
The authors leverage a multi-view diffusion model architecture, denoted as pθ, to address novel view synthesis (NVS) tasks. This model is built upon the Stable Diffusion 2.1 (SD 2.1) framework, which consists of an auto-encoder (VAE) and a latent denoising U-Net. The core architecture is modified to handle multi-view inputs by inflating the 2D self-attention layers within the U-Net's low-resolution residual blocks into 3D self-attention, enabling the model to capture spatial and temporal dependencies across views. To further enhance model capacity, 1D self-attention is added along the view axis after each self-attention block via skip connections. The model is trained as a "M-in N-out" diffusion model, where the context window length T=M+N is fixed during training. The training process employs a two-stage curriculum: the first stage uses a context window of T=8 with a large batch size, while the second stage increases the context window to T=21 with a smaller batch size. This curriculum helps prevent divergence during training. The model is conditioned on multiple inputs: the VAE latents of the input views, their corresponding camera poses encoded as Plücker embeddings, and high-level semantic information from CLIP image embeddings. The camera poses are normalized relative to the first input camera and scaled to fit within a [−2,2]3 cube. The conditioning is applied via concatenation and adaptive layer normalization. The model is trained on squared images with a resolution of 576×576.
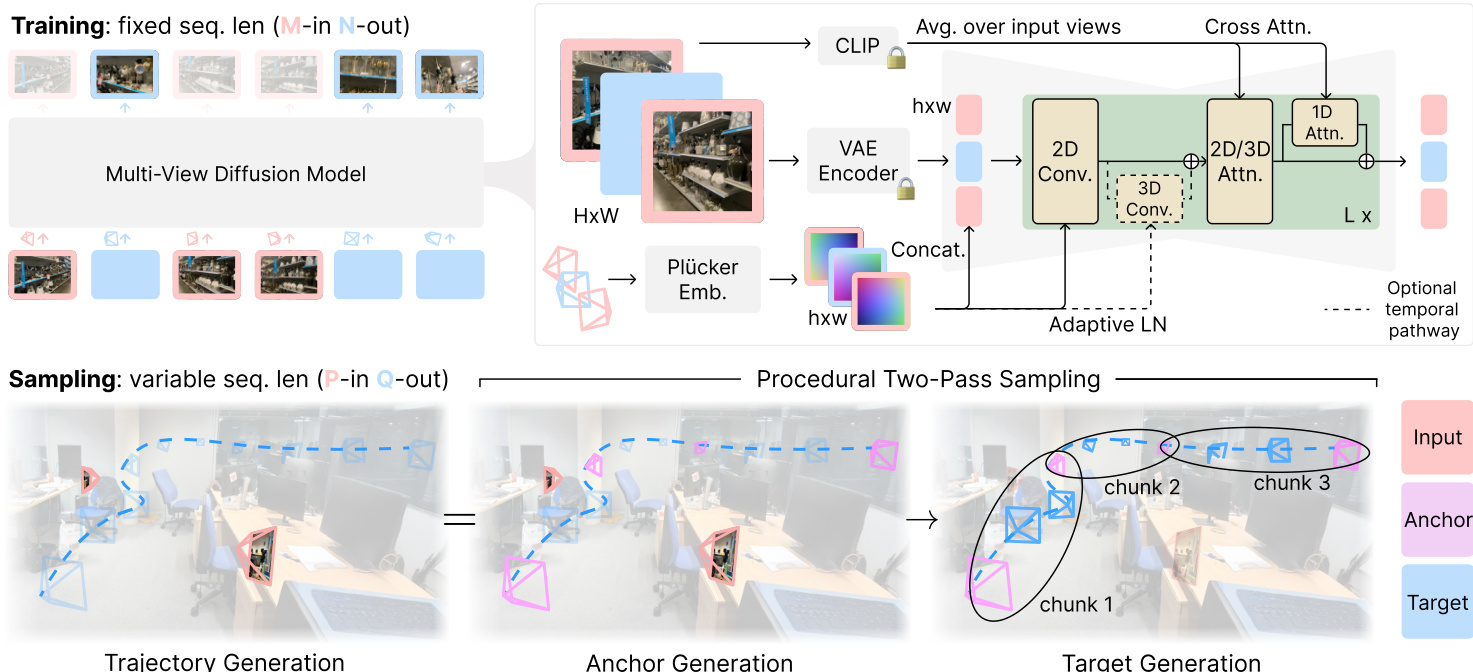
At test time, the model is used for a wide range of NVS tasks, which can be cast as a "P-in Q-out" problem where P and Q are variable. The authors propose a procedural two-pass sampling strategy to handle cases where P+Q>T. In the first pass, the model generates a set of anchor frames, Iacr, using all available input frames. In the second pass, the target frames are generated in chunks, using the previously generated anchors to maintain consistency. For set NVS, a nearest procedural sampling strategy is used, where target frames are grouped with their nearest anchor frames. For trajectory NVS, an interpolation procedural sampling strategy is employed, where a subset of target frames is generated as anchors, and the remaining frames are interpolated between them. This approach ensures temporal smoothness and 3D consistency across the generated views.
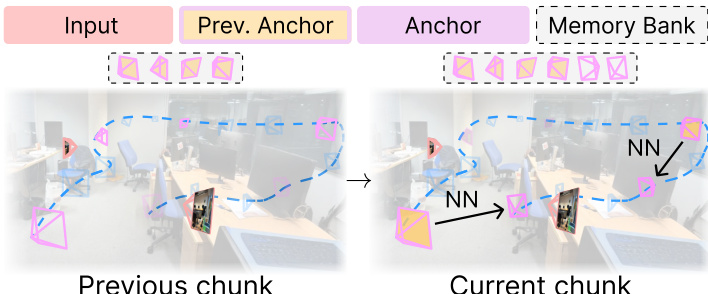
For scenarios where the number of target views Q is significantly larger than the context window T, a memory bank is introduced to maintain long-term 3D consistency. This memory bank stores previously generated anchor views and their corresponding camera poses. When generating new anchors, the model retrieves their spatially nearest neighbors from this memory bank, ensuring that the generated views are consistent with the global scene structure. This strategy is particularly effective for long trajectories and large-set NVS tasks, where maintaining consistency over a large number of frames is critical.
Experiment
- SEVA model validates strong performance across three key criteria: generation capacity, interpolation smoothness, and input flexibility, demonstrating generalization across diverse NVS tasks including set NVS, trajectory NVS, and long-trajectory NVS.
- On small-viewpoint set NVS, SEVA achieves state-of-the-art PSNR results, with +6.0 dB improvement on LLFF (P=3) and outperforming specialized models in semi-dense-view regimes (e.g., +1.7 dB on T&T with P=32); it also surpasses prior diffusion-based models by +4.2 dB on RE10K (P=2).
- On large-viewpoint set NVS, SEVA shows even greater advantages, improving by +0.6 dB PSNR over CAT3D on Mip360 (P=3), and maintaining strong performance on challenging scenes like DL3DV and T&T.
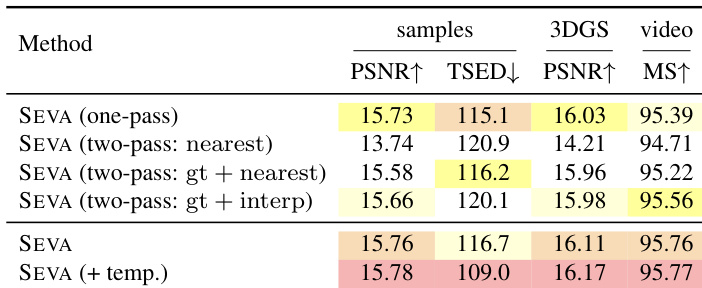
- In trajectory NVS, SEVA produces photorealistic, smooth transitions across complex camera paths, with quantitative gains in PSNR and superior temporal quality (MS↑) and 3D consistency (TSED↓, PSNR↑), especially when using interp procedural sampling and optional temporal pathway.
- For long-trajectory NVS, SEVA maintains 3D consistency over 1000+ frames using a spatial memory bank, significantly reducing artifacts compared to temporal neighbor lookup, demonstrating robustness in open-ended navigation.
- SEVA generalizes zero-shot to longer context windows and higher image resolutions, producing high-quality outputs across portrait and landscape orientations, with improved 3D consistency in semi-dense-view settings.
- The model exhibits strong zero-shot generalization to diverse input types, including single-view, sparse-view, and text-prompted images, with diverse and plausible hallucinations in unseen regions, validated through multiple random seeds.
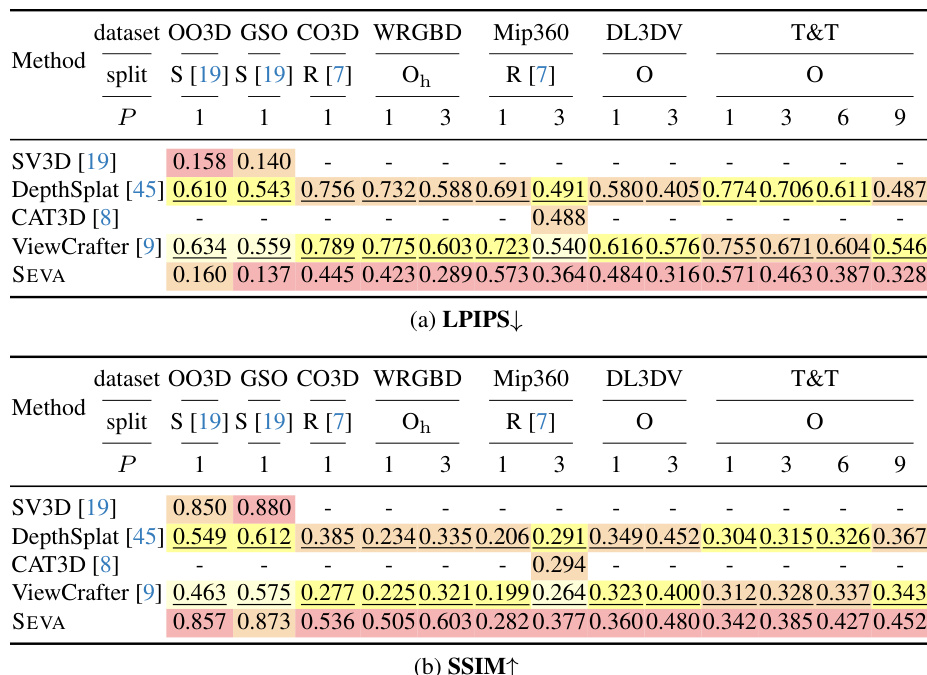
Results show that SEVA achieves state-of-the-art performance in small-viewpoint set NVS across multiple datasets, particularly excelling in the sparse-view regime with significant PSNR improvements. In large-viewpoint set NVS, SEVA demonstrates strong generation capacity, outperforming prior methods on challenging scenes like DL3DV and T&T, with notable gains in PSNR and perceptual quality.
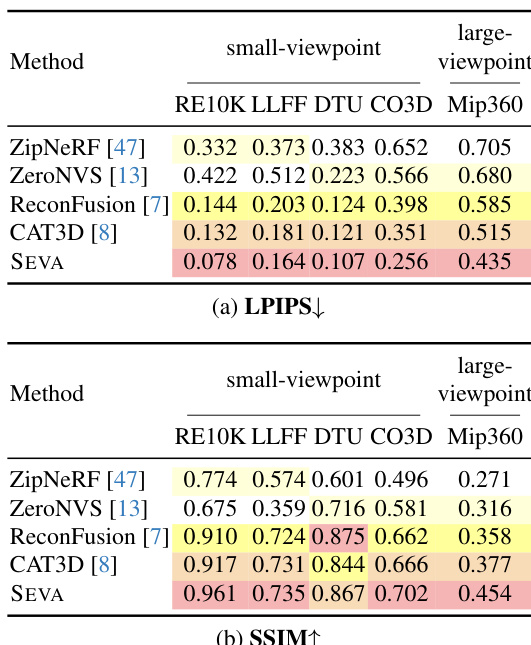
Results show that SEVA achieves state-of-the-art performance in most small-viewpoint set NVS splits, particularly excelling in the sparse-view regime with significant PSNR improvements over prior methods. The model also demonstrates strong generalization in the semi-dense-view regime, outperforming specialized models on certain datasets despite not being specifically designed for that setup.
Results show that SEVA's two-pass procedural sampling with interpolated procedural sampling achieves the best performance across all metrics, with the highest PSNR and MS scores. The integration of the temporal pathway further improves temporal quality, while the one-pass method shows lower performance due to increased flickering and reduced 3D consistency.
Results show that SEVA achieves state-of-the-art performance in most small-viewpoint set NVS settings, particularly excelling in the sparse-view regime with significant PSNR improvements over prior methods. The model also demonstrates strong generalization in large-viewpoint set NVS and trajectory NVS, producing photorealistic outputs with smooth transitions and high 3D consistency, even when handling complex camera movements and long trajectories.
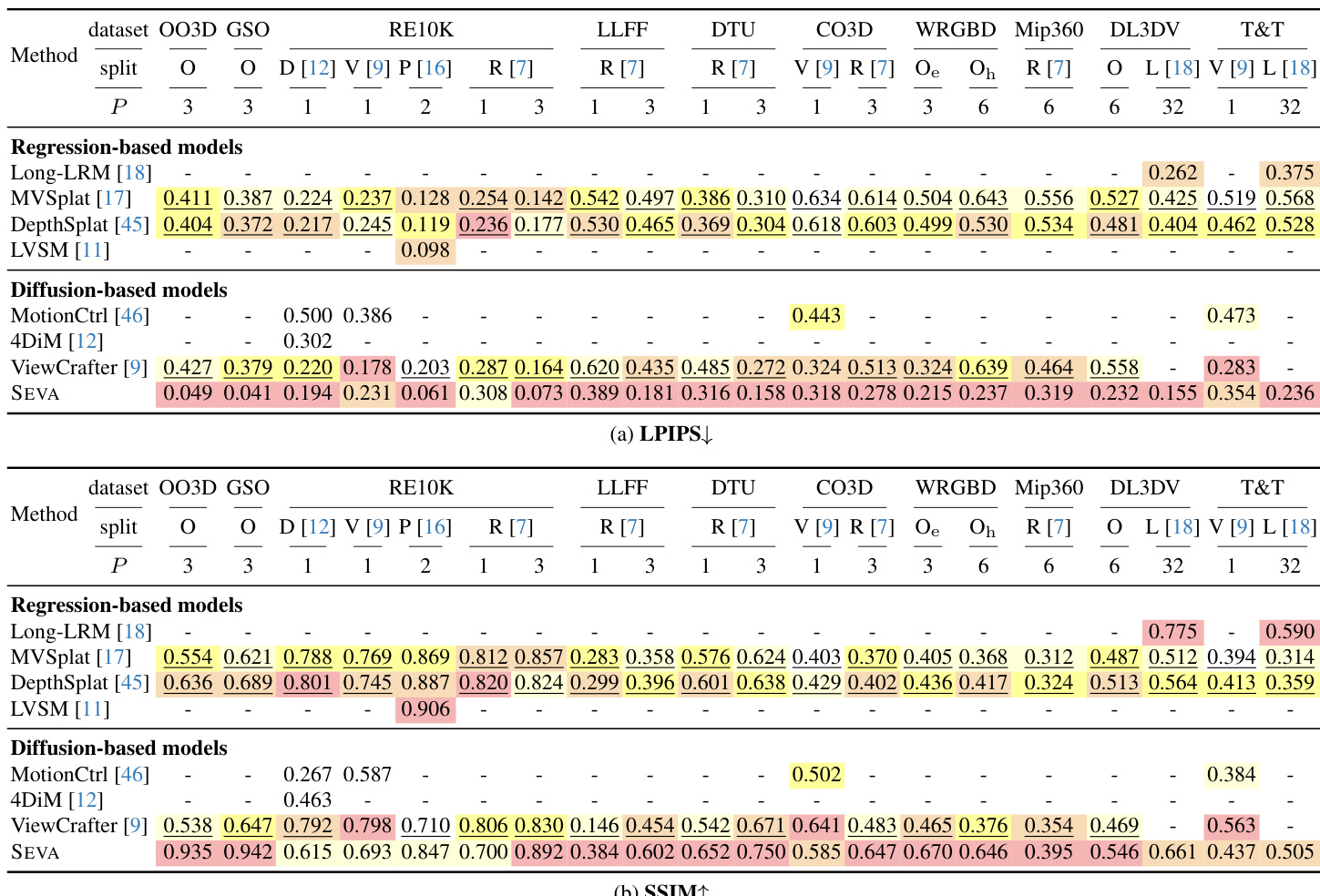
The authors use Table 2 to evaluate the performance of SEVA on small-viewpoint novel view synthesis (NVS) across various datasets and input regimes. Results show that SEVA achieves state-of-the-art PSNR on most splits, particularly excelling in the sparse-view regime (P ≤ 8) and performing favorably in the semi-dense-view regime (P = 32), despite not being specifically designed for this setup. The model's performance is notably strong on object datasets like OO3D and GSO, where it surpasses all other methods.