Command Palette
Search for a command to run...
VideoLLaMA 3: النماذج الأساسية متعددة الوسائط الرائدة لفهم الصور والفيديوهات
VideoLLaMA 3: النماذج الأساسية متعددة الوسائط الرائدة لفهم الصور والفيديوهات
الملخص
في هذه الورقة البحثية، نقترح نموذج VideoLLaMA3 الأساسي متعدد الوسائط الأكثر تطورًا لفهم الصور والفيديوهات. يعتمد تصميم VideoLLaMA3 الأساسي على فلسفة مركزية في الرؤية (vision-centric). وتشير عبارة "مركزية الرؤية" إلى جوانب متعددة: نموذج التدريب المركزي في الرؤية، وتصميم الإطار المركزي في الرؤية. والرؤية الأساسية في نموذج التدريب المركزي في الرؤية هي أن بيانات الصورة والنص عالية الجودة تُعدّ حاسمة لفهم كل من الصور والفيديوهات. بدلًا من إعداد مجموعات بيانات ضخمة من الفيديو والنص، نركّز على بناء مجموعات بيانات ضخمة وعالية الجودة للصورة والنص. يتضمن VideoLLaMA3 أربع مراحل تدريب: 1) تكييف مشفر الرؤية، والذي يمكّن مشفر الرؤية من قبول صور ذات أبعاد متغيرة كمدخلات؛ 2) محاذاة الرؤية واللغة، والذي يُعدّل بشكل مشترك مشفر الرؤية، والمحول (projector)، والنموذج اللغوي الكبير (LLM) باستخدام بيانات صورة-نص ضخمة تغطي أنواعًا متعددة (بما في ذلك الصور المكانية، والمستندات، والرسوم البيانية)، بالإضافة إلى بيانات نصية فقط؛ 3) التدريب الدقيق متعدد المهام، والذي يدمج بيانات التدريب الدقيق للصورة والنص (SFT) للمهام التطبيقية، ويستخدم بيانات الفيديو والنص لبناء أساس قوي لفهم الفيديو؛ 4) التدريب الدقيق المركزي في الفيديو، والذي يُحسّن بشكل إضافي قدرة النموذج على فهم الفيديو. أما في تصميم الإطار، فيتم تكييف مشفر الرؤية المُدرّب مسبقًا لتحويل الصور ذات الأحجام المختلفة إلى رموز رؤية (vision tokens) بعدد يتناسب مع حجم الصورة، بدلًا من عدد ثابت من الرموز. أما بالنسبة للمدخلات الفيديو، فيتم تقليل عدد رموز الرؤية وفقًا لدرجة تشابهها، مما يجعل تمثيل الفيديو أكثر دقة وانسيابية. وبفضل التصاميم المركزة في الرؤية، يحقق VideoLLaMA3 أداءً متميزًا في معايير تقييم فهم الصور والفيديوهات.
One-sentence Summary
The authors from DAMO Academy and Hupan Lab propose VideoLLaMA3, a vision-centric multimodal foundation model that achieves state-of-the-art performance in both image and video understanding by leveraging large-scale high-quality image-text data and a four-stage training paradigm. The model introduces Any-resolution Vision Tokenization and Differential Frame Pruning to enable flexible, high-fidelity visual representation and efficient video processing, significantly improving capabilities in document comprehension, mathematical reasoning, and long-form video analysis.
Key Contributions
- VideoLLaMA3 introduces a vision-centric training paradigm that prioritizes image understanding to enhance video comprehension, leveraging high-quality image-text data to improve the vision encoder's robustness before focusing on temporal modeling in video tasks.
- The model features two key vision-centric framework innovations: dynamic resolution input support via Rotary Position Embedding to handle variable aspect ratios and high-resolution images, and video token compression to reduce redundancy and improve computational efficiency.
- VideoLLaMA3 achieves state-of-the-art performance on diverse benchmarks, excelling in both image understanding (e.g., chart and math reasoning) and video tasks (e.g., long-form video, temporal grounding), outperforming prior models across multiple metrics.
Introduction
The authors leverage the success of image-centric multimodal large language models (MLLMs) to address the challenges of video understanding, where temporal dynamics and low-quality, sparse video-text datasets hinder progress. Prior work often struggles with inefficient token handling, rigid input representations, and limited generalization due to reliance on scarce, noisy video data. To overcome these limitations, the authors introduce VideoLLaMA3, a vision-centric MLLM that first strengthens image understanding through a four-stage training paradigm—vision encoder adaptation, vision-language alignment, multi-task fine-tuning, and video-centric fine-tuning—using high-quality image-text data. The model incorporates two key technical innovations: dynamic resolution input via Rotary Position Embedding to handle variable aspect ratios and high-resolution images, and video token compression to reduce redundancy and improve computational efficiency. These design choices enable VideoLLaMA3 to achieve state-of-the-art performance on both image and video benchmarks, including document comprehension, mathematical reasoning, long video understanding, and temporal grounding, while maintaining strong generalization across modalities.
Dataset
- The VL3-Syn7M dataset, used to train VideoLLaMA3, consists of 7 million image-caption pairs sourced from COYO-700M and processed through a multi-stage cleaning pipeline.
- Key filtering steps include: aspect ratio filtering to remove extreme image shapes, aesthetic score filtering using a dedicated model to discard low-quality visuals, text-image similarity scoring via BLIP2 and CLIP to retain describable content, and visual feature clustering using CLIP features and k-NN to ensure semantic diversity and balanced category coverage.
- After filtering, images undergo re-captioning: brief captions are generated with InternVL2-8B, and detailed captions with InternVL2-26B, producing two distinct subsets—VL3-Syn7M-short and VL3-Syn7M-detailed—used at different training stages.
- The dataset is integrated into a multi-stage training framework:
- In Vision Encoder Adaptation, VL3-Syn7M-short is combined with LLaVA-Pretrain-558K, Object365, and SA-1B to enhance scene understanding and fine-grained feature extraction.
- In Vision-Language Alignment, VL3-Syn7M is augmented with COCO-2017, ShareGPT4o, ShareGPT4V, DenseFusion, and LLaVA-Recap, with recaptioning applied to enhance caption quality.
- In Multi-task Fine-tuning, VL3-Syn7M supports general image, document, OCR, grounding, and multi-image tasks, with additional data from Pixmo, Cambrian-10M, and specialized datasets like Demon-Full and Contrastive-Caption.
- In Video-centric Fine-tuning, VL3-Syn7M contributes to general image understanding, while video-specific data from LLaVA-Video, ShareGPT-4o, and synthetic dense captions from Panda-70M (via Qwen2-VL-72B) are used to strengthen temporal and spatial reasoning.
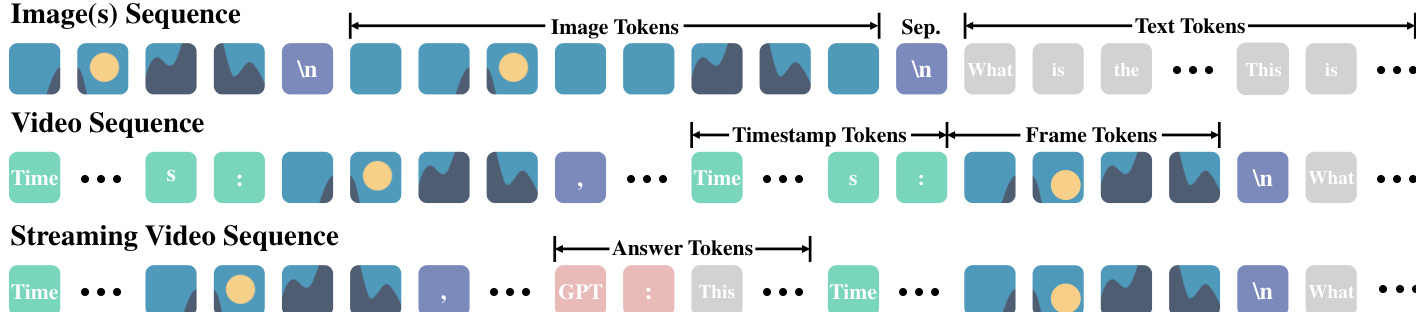
- Data is formatted as token sequences: images use “\n” to separate tokens, videos include “Time: xxs” timestamps before each frame and commas to separate frames, and streaming videos use interleaved frame, timestamp, and answer tokens (e.g., “GPT: xxx”) to simulate real-time interaction.
- For video training, long videos are segmented into two-minute clips based on dense caption intervals, and synthetic streaming conversations are constructed to support multi-turn understanding.
- Temporal grounding data is converted into text format (e.g., “1.0-2.0 s”) and combined with datasets like ActivityNet, YouCook2, and Charades-STA to train the model on precise event localization.
Method
The authors leverage a vision-centric approach to design VideoLLaMA3, a multimodal foundation model for image and video understanding. The core of the model architecture consists of a vision encoder, a video compressor, a projector, and a large language model (LLM). The vision encoder, initialized with the pre-trained SigLIP, extracts visual features, while the projector bridges the representation gap between the vision encoder and the LLM. The LLM used is based on the Qwen2.5 architecture. To handle inputs of varying resolutions, the model employs Any-resolution Vision Tokenization (AVT), which adapts the vision encoder to process images and videos of any size by dynamically generating a corresponding number of vision tokens. This is achieved by replacing the absolute position embeddings in the Vision Transformer (ViT) with 2D-RoPE, enabling the encoder to maintain spatial relationships across different resolutions. For video inputs, the model further reduces the number of tokens through a video compressor, which is designed to eliminate redundant information.
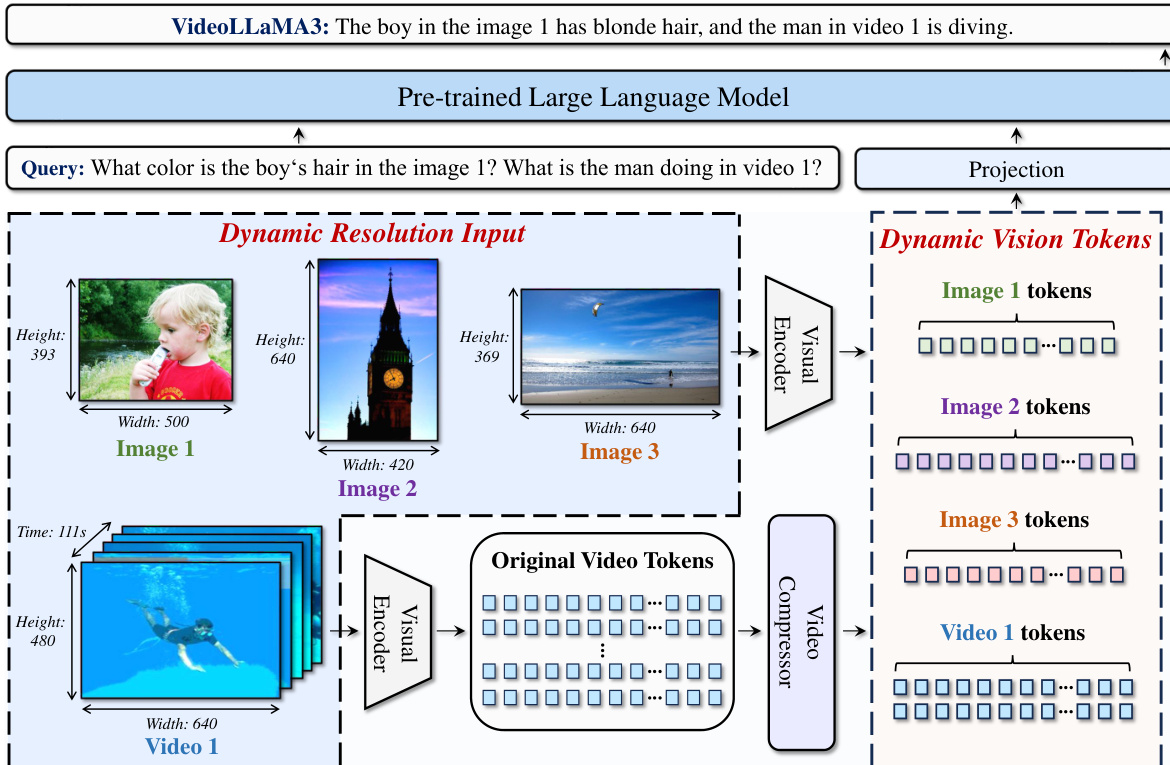
As shown in the figure below, the model's architecture supports dynamic resolution input, where images of different dimensions are processed into vision tokens of variable lengths. This flexibility is crucial for preserving fine-grained details in images. For videos, the model first applies a per-frame 2×2 spatial downsampling via bilinear interpolation to limit the context length. To further reduce redundancy, the Differential Frame Pruner (DiffFP) is employed. This component computes the 1-norm distance between temporally consecutive patches in the pixel space and prunes patches with distances below a threshold, effectively removing frames with minimal content change. This process results in a more compact and precise representation of the video input.
The training of VideoLLaMA3 is structured into four distinct stages. The first stage, Vision Encoder Adaptation, fine-tunes the vision encoder and projector on a large-scale image dataset, transforming the encoder into a dynamic-resolution processor. The second stage, Vision-Language Alignment, jointly fine-tunes the vision encoder, projector, and LLM using a diverse set of image-text and text-only data to integrate multimodal knowledge. The third stage, Multi-task Fine-tuning, performs instruction fine-tuning on a combination of image and video-based question-answering data, which enhances the model's ability to follow instructions and lays the foundation for video understanding. The final stage, Video-centric Fine-tuning, focuses on improving video understanding by training on video-text data, image-only data, and text-only data, with all model parameters unfrozen. This staged training process ensures that the model develops strong image understanding capabilities first, which are then leveraged to enhance its video understanding performance.
Experiment
- VideoLLaMA3-2B and VideoLLaMA3-7B are evaluated on image and video benchmarks to validate their multi-modal understanding capabilities.
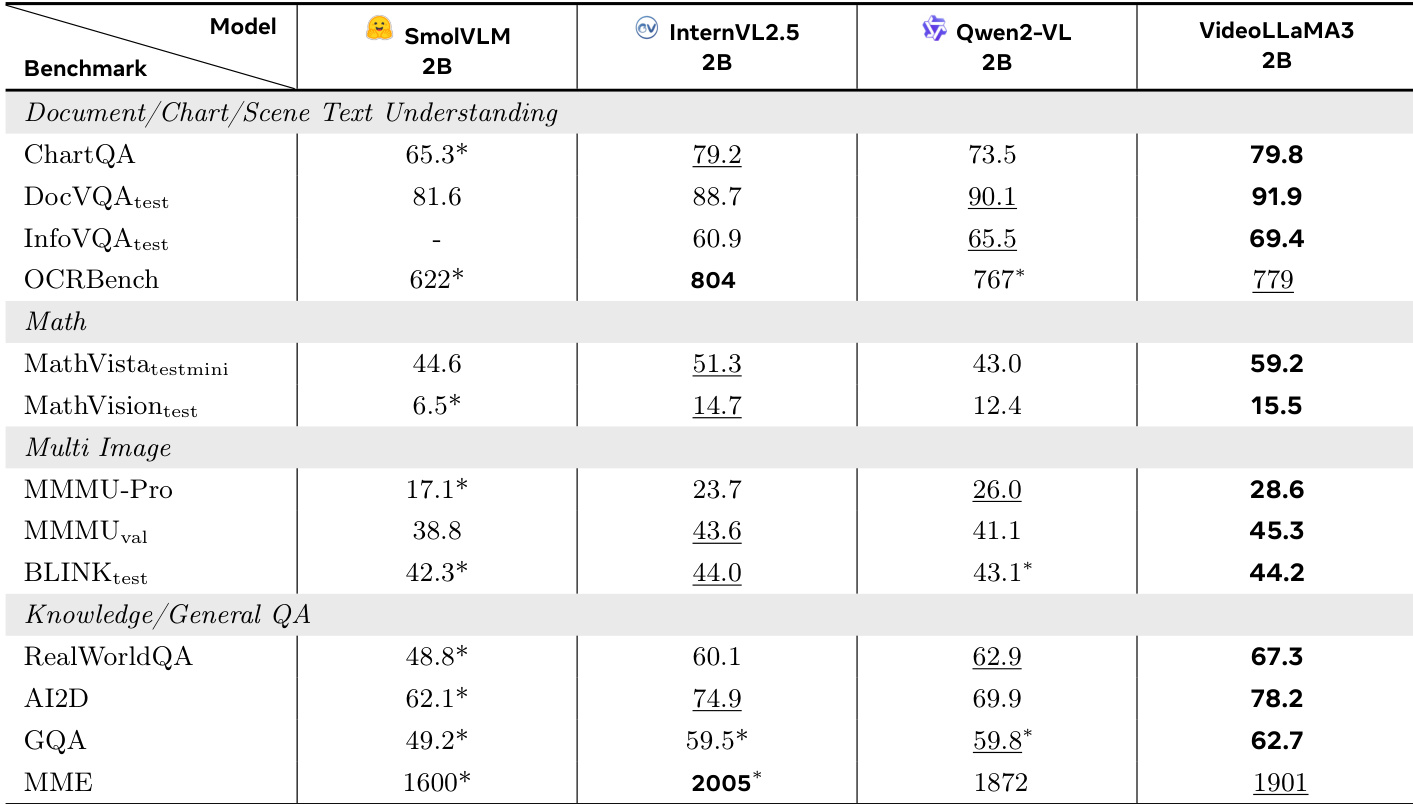
- On image benchmarks, VideoLLaMA3-2B achieves 69.4% on InfoVQA, surpassing the previous best by 3.9%, and 59.2% on MathVista, outperforming prior methods by 7.9%. It also scores 67.3% on RealWorldQA, exceeding the prior state-of-the-art by 4.4%.
- VideoLLaMA3-7B achieves 65.7% on MathVision, surpassing the previous best by 6.5%, and 67.3% on RealWorldQA, improving by 2.0% over prior models.
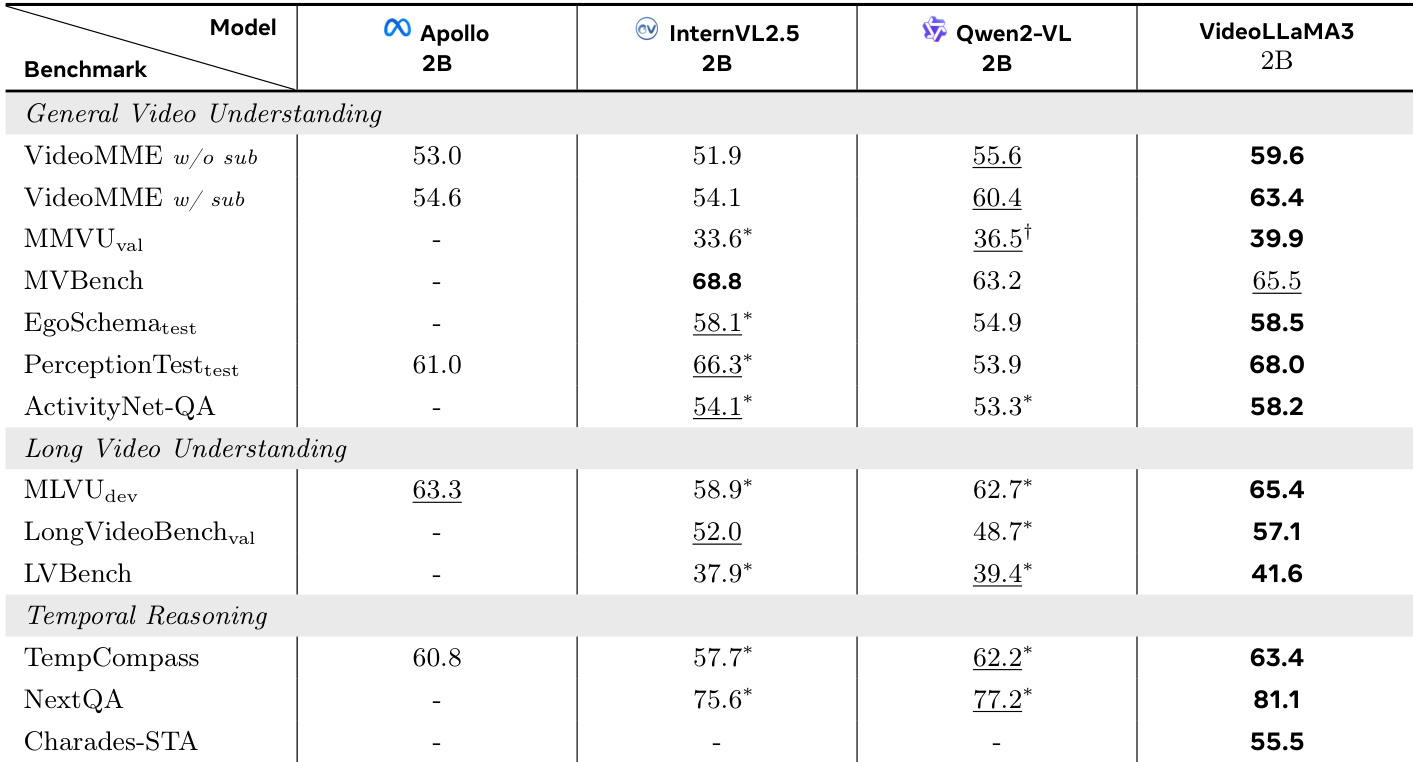
- On video benchmarks, VideoLLaMA3-2B achieves the highest scores on VideoMME w/o sub (59.6%), VideoMME w/ sub (63.4%), ActivityNet-QA (58.2%), PerceptionTest-test (68.0%), and MVBench (65.5%), and leads on all long-video benchmarks: MLVU-dev (65.4%), LongVideoBench-val (57.1%), and LVBench (40.4%).
- VideoLLaMA3-7B leads on 5 out of 7 general video understanding benchmarks and achieves top performance on MLVU-dev, with strong results on LongVideoBench-val and LVBench.
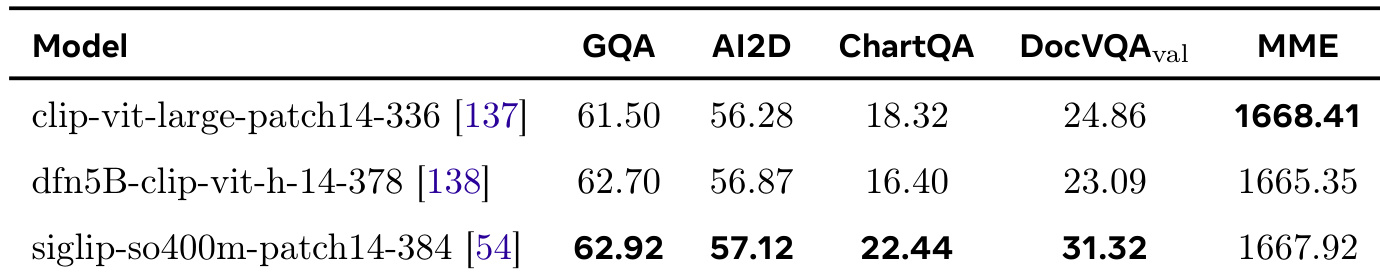
- Ablation studies confirm SigLIP as the optimal vision encoder, outperforming CLIP and DFN, especially in text-rich and fine-grained understanding tasks.
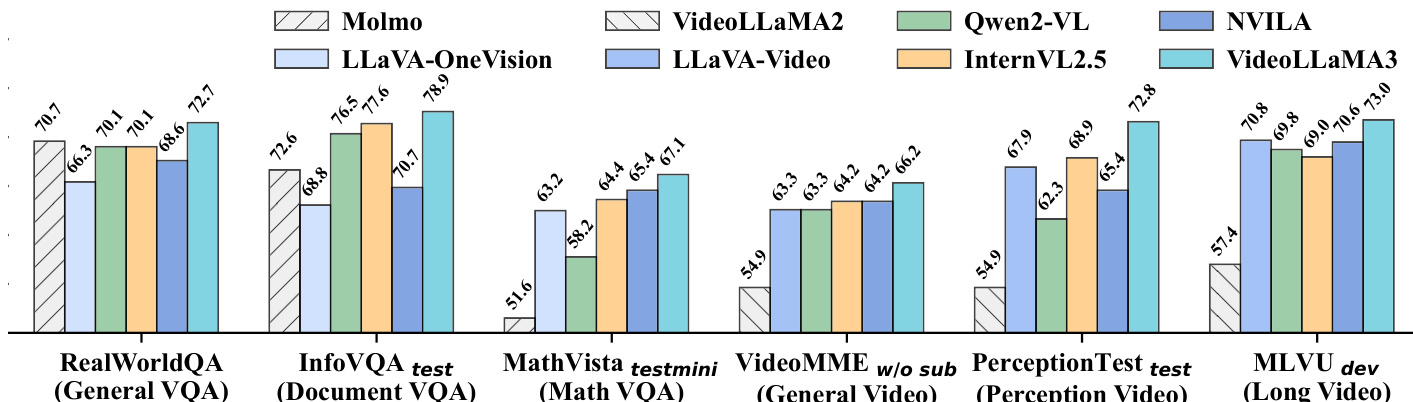
The authors use VideoLLaMA3-7B to evaluate its performance on video benchmarks, comparing it against several state-of-the-art models. Results show that VideoLLaMA3-7B achieves the highest scores on multiple tasks, including MLVU-dev (73.0%), LongVideoBench-val (59.8%), and NextQA (84.5%), demonstrating strong capabilities in long video understanding and temporal reasoning.
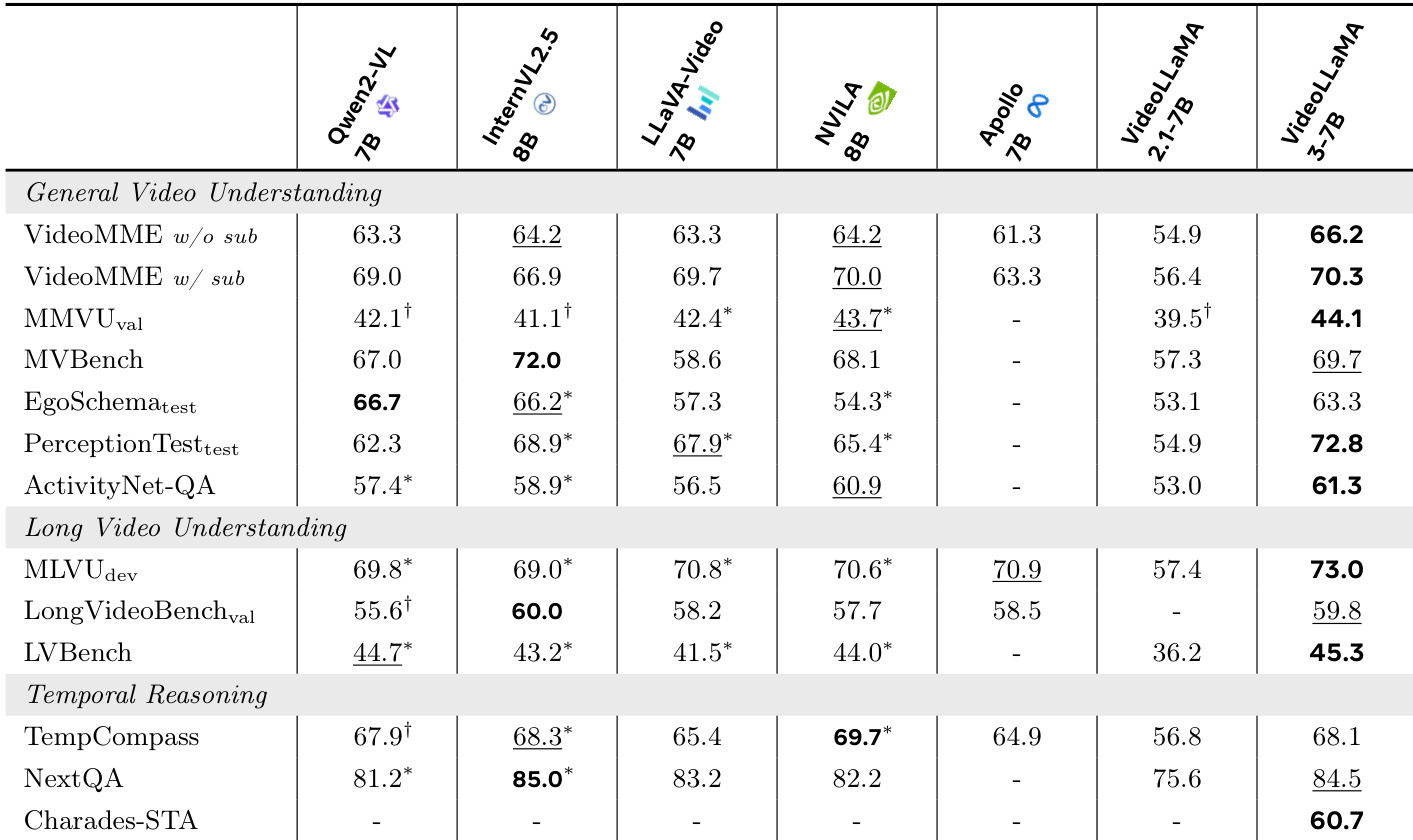
Results show that VideoLLaMA3 achieves the highest scores on most benchmarks compared to other models. It outperforms baselines such as Qwen2-VL, LLaVA-Video, and InternVL2.5 across general video understanding, long video comprehension, and temporal reasoning tasks, demonstrating strong performance in both short and long video analysis.
The authors conduct an ablation study comparing three vision encoders—CLIP, DFN, and SigLIP—on a subset of the dataset, evaluating their performance across multiple benchmarks. Results show that SigLIP outperforms the other two encoders, particularly in fine-grained text understanding tasks, leading the authors to select it as the base vision encoder for further development.
The authors use the table to compare the performance of VideoLLaMA3-2B against several baselines on video understanding benchmarks. Results show that VideoLLaMA3-2B achieves the highest scores on multiple tasks, including VideoMME w/o sub (59.6%), VideoMME w/ sub (63.4%), and PerceptionTest-test (68.0%). It also leads in long video understanding and temporal reasoning, scoring 65.4% on MLVU-dev and 81.1% on NextQA, demonstrating strong performance across diverse video comprehension tasks.
The authors use Table 5 to evaluate the 2B model variants on image benchmarks, focusing on document/chart/scene text understanding, mathematical reasoning, multi-image understanding, and general knowledge QA. Results show that VideoLLaMA3-2B achieves the highest scores on several key tasks, including DocVQA test (91.9), OCRBench (779), and RealWorldQA (67.3), outperforming all listed baselines. It also demonstrates strong performance in mathematical reasoning, scoring 59.2 on MathVista, which is significantly higher than the second-best model.