Command Palette
Search for a command to run...
Vchitect-2.0: محول متوازٍ لتوسيع نماذج التمايز الفيديو
Vchitect-2.0: محول متوازٍ لتوسيع نماذج التمايز الفيديو
الملخص
نقدّم Vchitect-2.0، وهي بنية ترانسفورمر متوازية مصممة لتوسيع نماذج التوزيع الفيديو لدعم إنشاء فيديو من نص على نطاق واسع. يحتوي النظام الكلي لـ Vchitect-2.0 على عدة تصميمات رئيسية. (1) من خلال إدخال كتلة توزيع متعددة الوسائط جديدة، نحقق تزامنًا متسقًا بين الوصف النصي والإطارات المرئية المُولَّدة، مع الحفاظ على الاتساق الزمني عبر التسلسلات. (2) لتجاوز القيود المتعلقة بالذاكرة والحساب، نقترح إطارًا تدريبيًا فعّالًا من حيث الاستخدام الذاكرة، يدمج التوازي الهجين وتقنيات أخرى لتقليل الاستهلاك الذاكرة، مما يمكّن من التدريب الفعّال على تسلسلات فيديو طويلة ضمن أنظمة موزعة. (3) بالإضافة إلى ذلك، يضمن خط أنابيب معالجة البيانات المُحسَّنة إنشاء Vchitect T2V DataVerse، وهي مجموعة بيانات تدريب بحجم مليون مدخل، ذات جودة عالية، من خلال عملية تأشير صارمة وتقييم جمالي. تُظهر الاختبارات الواسعة أن Vchitect-2.0 يتفوق على الطرق الحالية من حيث جودة الفيديو، وكفاءة التدريب، والقابلية للتوسع، مما يجعله أساسًا مناسبًا لإنشاء فيديوهات عالية الدقة.
One-sentence Summary
The authors, affiliated with Nanyang Technological University, Shanghai Artificial Intelligence Laboratory, and The Chinese University of Hong Kong, propose Vchitect-2.0, a parallel transformer architecture that enables scalable text-to-video generation by introducing a multimodal diffusion block for enhanced text-video alignment and temporal coherence, combined with a hybrid parallelism framework incorporating sequence and data parallelism with memory optimization techniques like recomputation and offloading, significantly improving training efficiency and scalability for long-duration, high-resolution videos, supported by a high-quality million-scale dataset curated through rigorous annotation and aesthetic evaluation.
Key Contributions
- Vchitect-2.0 introduces a novel multimodal diffusion block that ensures strong alignment between text prompts and generated video frames while preserving temporal coherence across long video sequences, addressing key challenges in text-to-video generation.
- The architecture employs a hybrid parallelism framework combining data and sequence parallelism with memory-saving techniques like recomputation and offloading, enabling efficient training of large-scale video diffusion models on distributed systems.
- The Vchitect T2V DataVerse, a million-scale high-quality dataset curated through rigorous annotation and aesthetic evaluation, supports diverse and complex text-to-video tasks, with extensive benchmarking showing superior performance in video quality, temporal consistency, and training efficiency.
Introduction
The authors leverage recent advances in diffusion models for text-to-video (T2V) generation, where the goal is to produce temporally coherent, high-fidelity videos from textual prompts. While prior work has extended text-to-image diffusion models with temporal modules like spatio-temporal attention or 3D convolutions, these approaches struggle with long video sequences due to temporal inconsistencies—such as flickering and motion discontinuities—and high computational demands. Limited availability of high-quality, well-annotated video datasets further restricts model generalization. To address these challenges, the authors introduce Vchitect-2.0, a parallel transformer architecture featuring a novel Multimodal Diffusion Block that ensures strong text-video alignment and temporal coherence. The system employs a hybrid parallelism framework combining data and sequence parallelism with memory optimization techniques like recomputation and offloading, enabling efficient training of long videos on distributed systems. Additionally, they introduce the Vchitect T2V DataVerse, a million-scale dataset curated through rigorous annotation and aesthetic evaluation to improve training quality and diversity. Extensive experiments show that Vchitect-2.0 achieves state-of-the-art performance in video quality, temporal consistency, and training efficiency, establishing a scalable foundation for future video generation research.
Dataset
-
The dataset for Vchitect-2.0 combines publicly available sources—WebVid10M, Panda70M, Vimeo25M, and InternVid—with 1 million internally sourced videos, all processed through a rigorous filtering and re-annotation pipeline to improve quality and control.
-
Public datasets contribute diverse video content across domains, while the in-house data includes high-resolution videos (up to 4K) with longer durations and more detailed annotations, enhancing both visual fidelity and semantic richness.
-
The data processing pipeline begins with shot segmentation using PySceneDetect with an AdaptiveDetector (threshold 21.0), followed by event stitching via ViCLIP feature comparison (similarity threshold 0.6) to merge clips from the same semantic event.
-
Static video filtering removes clips with more than 30% static frames by comparing grayscale pixel intensity differences between consecutive frames (threshold 0.9), ensuring only dynamic content is retained.
-
Aesthetic evaluation uses a pre-trained predictor on CLIP features to score video frames from 1 to 10; only clips with higher aesthetic scores are kept, significantly improving visual quality.
-
Dynamic estimation measures motion intensity using RAFT on downsampled 128x128 frames (2 iterations), helping identify and filter out videos with excessive camera shake or minimal motion.
-
Video captioning is performed using LLaVA-Next-Video and fine-tuned VideoChat models, each processing 16 frames with a prompt focused on subjects, actions, and background. Captions average 200 tokens and are recaptioned to improve detail and dynamic description.
-
Watermark detection uses an EfficientNet-based classifier trained on LAION to assess watermark presence in key frames; videos with high watermark probability are excluded.
-
Text localization employs EasyOCR with a detection score threshold of 0.4 and minimum text length of 4; frames with text area exceeding 2% of total area are flagged, and videos with more than one such frame are discarded.
-
The final dataset features longer average video durations compared to Vchitect, with recaptioned descriptions averaging 100 tokens and significantly improved aesthetic scores—nearly half of in-house videos score above 6, up from 16.89% in prior versions.
-
For training, the data is split into a mixture of subsets with adjusted ratios to balance domain coverage and quality, with the in-house data contributing higher-resolution, longer, and more detailed content to enhance model performance.
-
All video clips are processed to maintain narrative coherence, with metadata including aesthetic scores, dynamic degree, watermark flags, and text localization information embedded for downstream use in training and evaluation.
Method
The authors leverage a parallel transformer architecture designed to address the challenges of training large-scale video diffusion models. The core of the model is built upon the foundation of Stable Diffusion 3, incorporating unified multimodal diffusion blocks that are augmented with learnable context latents to enhance text-frame coherence. To extend this capability to text-to-video generation while maintaining both text-image and text-video coherence, the authors introduce a parallel multimodal diffusion block. This block retains the text-image generation capability while enabling generalized text-to-video synthesis. The architecture processes text and visual embeddings, which are interleaved in a checkerboard pattern for full-sequence cross-attention, anchored by the text embedding from the first frame. The input sequences, structured as [B, F, L, H, W], are transformed for spatial and temporal attention: spatial attention reshapes the input to [B×F, L, H, W], while temporal attention reshapes it to [B × L, F, H, W]. The outputs from the spatial, temporal, and full-sequence cross-attention branches are aggregated via element-wise addition to produce the final feature representation. 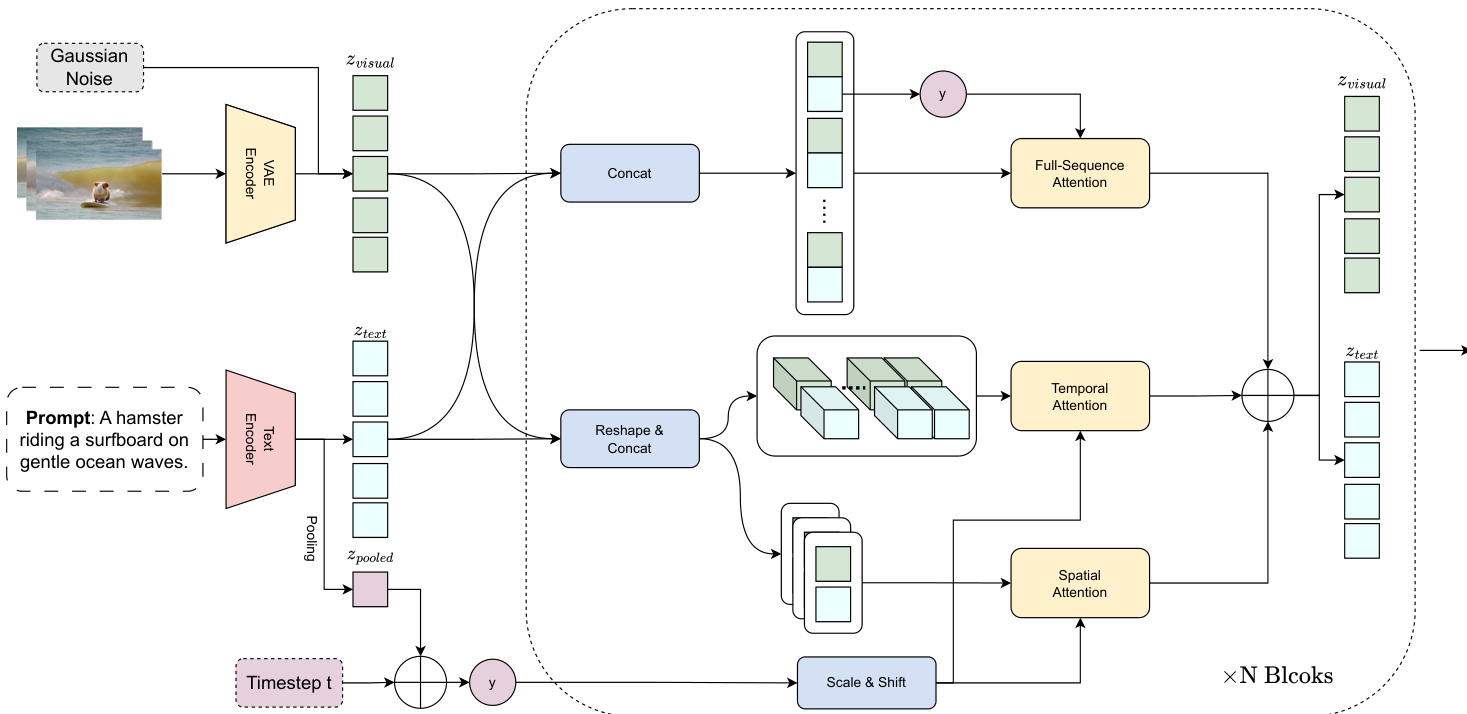
The training system employs a combination of memory-efficient strategies to handle the substantial memory footprint of forward activations in long-context video training. The authors analyze the limitations of existing frameworks and propose a training system that integrates various memory-saving techniques. A key decision is to limit sequence parallelism (SP) groups within a single training node, utilizing other memory-saving techniques, and applying data parallelism across nodes. This strategy avoids the inefficiencies and scalability issues associated with inter-node SP, particularly given the lower bandwidth between nodes compared to intra-node connections. The system combines intra-node SP with inter-node data parallelism, integrating activation offloading, recomputation, and Fully Sharded Data Parallelism (FSDP) to mitigate memory footprint while minimizing overhead. 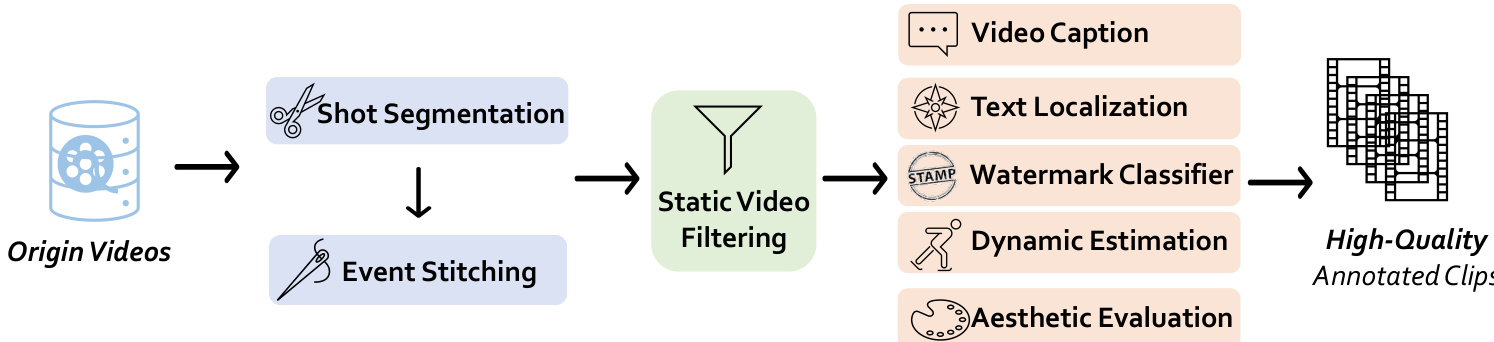
To further optimize memory usage, the authors implement a specialized intra-node SP workflow tailored to the 3D and multi-modal nature of their model. They choose to slice the spatial sequence in the Transformer backbone, as it is typically longer than the temporal sequence, minimizing the impact on computation kernel efficiency. For the spatial attention kernel, head parallelism is adopted, as intra-node SP does not face the limitation of the number of attention heads. Text tokens are sharded across all devices in an SP group, similar to visual tokens, ensuring load balance in the Transformer backbone and text encoders. The VAE inference stage, which is computationally intensive and memory-heavy, is parallelized by viewing the input video as a batch of frames and utilizing frame-wise data parallelism. The scattered batch of frames is sliced into smaller mini-batches for iterative encoding, and frame-wise DP parallelism is extended to latent patchification and position embedding calculation. An all-to-all resharding step is introduced before the transformer blocks to substitute for an all-gather after VAE encoding, improving parallelism and reducing communication. 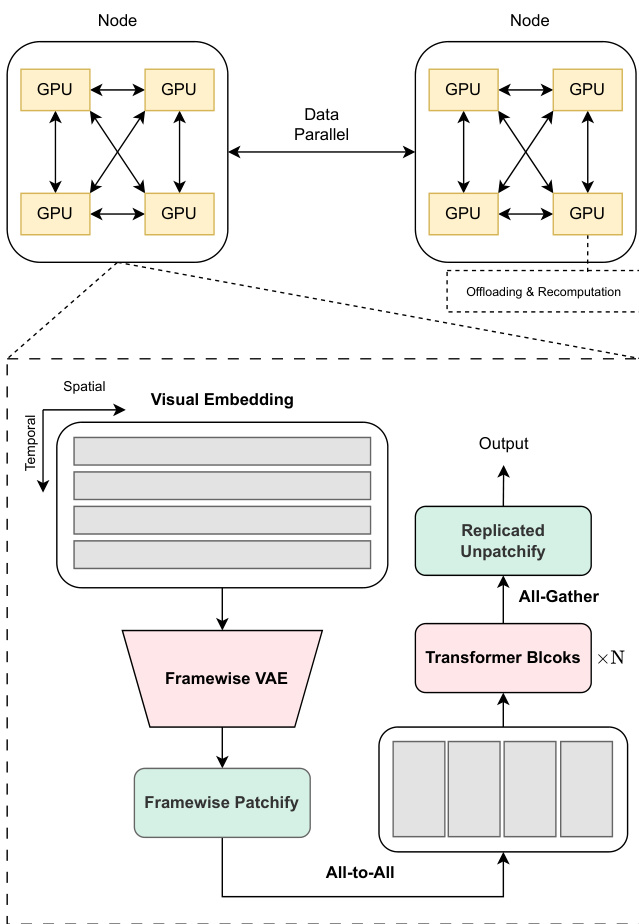
Experiment
- Conducted multi-stage training on WebVid-10M, Panda-70M, InternVid-18M-aes, Vimeo, and internal data to scale resolution and video length, enabling 720p, 5-second video generation with high temporal coherence and visual fidelity.
- Achieved competitive results on VBench: Vchitect-2.0-2B outperformed CogVideoX-2B by 1.35% in Overall Consistency, 0.65% in Aesthetic Quality, and 3.92% in Imaging Quality; the enhanced version (Vchitect-2.0-2B [E]) surpassed commercial model Kling by 0.39% in Total Score.
- Human evaluation showed a win ratio over 60% across video-text alignment, frame-wise quality, and temporal quality, indicating strong preference for Vchitect-2.0-2B over Mira, OpenSora-v1.2, CogVideoX-2B, and OpenSoraPlan-v1.1.
- Ablation studies confirmed the effectiveness of full-sequence cross-attention, improving Total Score, Overall Consistency, Aesthetic Quality, and Imaging Quality.
- Memory-efficient training strategies (recomputation, offload, SP workflow) enabled stable training at long sequence lengths (up to 1.16M tokens), with near-linear scalability and reduced iteration time compared to baseline and cross-node methods.
Results show that Vchitect-2.0-2B [E] achieves a Total Score of 82.24%, outperforming Kling and other models in most metrics, particularly excelling in Overall Consistency, Aesthetic Quality, and Imaging Quality. The enhanced version demonstrates competitive performance, with a Total Score exceeding Kling by 0.39%, highlighting the effectiveness of the proposed training strategy and post-processing with VEnhancer.

The authors evaluate memory-efficient training strategies for video generation models, comparing baseline, recomputation, offload, and combination methods across different input shapes. Results show that the combination strategy achieves the best balance of memory efficiency and iteration time, enabling stable training even for large input shapes where other methods fail due to out-of-memory errors or performance degradation.

The authors use automated evaluation metrics from VBench to assess the performance of Vchitect-2.0-2B, showing that it achieves a Total Score of 79.33%, outperforming the baseline and other models in Overall Consistency, Aesthetic Quality, and Imaging Quality. Results indicate that the model excels in generating visually coherent and high-quality videos, particularly in metrics related to visual fidelity and consistency, while still facing challenges in human-centric content and spatial understanding.

The authors conduct a human evaluation comparing Vchitect-2.0-2B against four other models across three metrics: video-text alignment, frame-wise quality, and temporal quality. Results show that Vchitect-2.0-2B achieves an average win ratio of 74.59% in video-text alignment, 71.62% in frame-wise quality, and 66.01% in temporal quality, demonstrating a clear preference for the proposed model across all evaluated aspects.
