Command Palette
Search for a command to run...
TOOLACE: التغلّب في نقاط استدعاء الدوال الخاصة بـ LLM
TOOLACE: التغلّب في نقاط استدعاء الدوال الخاصة بـ LLM
الملخص
يُعد استدعاء الدوال (Function calling) عاملاً محوريًا في توسيع حدود تطبيق نماذج اللغة الكبيرة (LLMs)، حيث تُعد البيانات التدريبية عالية الجودة والمتنوعة عاملاً حاسمًا في تمكين هذه القدرة. غير أن جمع وتعليق البيانات الحقيقية المتعلقة باستدعاء الدوال يمثل تحديًا كبيرًا، في حين أن البيانات الاصطناعية المولدة عبر خطوط الإنتاج (pipelines) الحالية غالبًا ما تفتقر إلى الشمولية والدقة. في هذه الورقة، نقدم ToolACE، وهو خط إنتاج آلي (agentic pipeline) مصمم لتوليد بيانات تعلم الأدوات (tool-learning) دقيقة ومعقدة ومتنوعة، ومُعد خصيصًا ليتوافق مع قدرات نماذج LLM. يعتمد ToolACE على عملية تركيب تطورية ذاتية (self-evolution synthesis) مبتكرة لفرز مجموعة شاملة من واجهات برمجة التطبيقات (APIs) تضم 26,507 واجهة متنوعة. كما يتم توليد الحوارات من خلال التفاعل بين عدة وكلاء (agents)، وذلك تحت إشراف مقياس لتعقيد المهمة (complexity evaluator). ولضمان دقة البيانات، قمنا بتطبيق نظام تحقق من طبقتين يجمع بين الفحوصات القائمة على القواعد (rule-based) وتلك المعتمدة على النماذج (model-based). وقد أظهرت نتائجنا أن النماذج المدربة على بياناتنا المولدة اصطناعيًا—وحتى تلك التي تحتوي على 8 مليارات معلمة (parameters) فقط—تُحقق أداءً في الطليعة (state-of-the-art) يضاهي أحدث نماذج GPT-4. ويتاح نموذجنا ومجموعة فرعية من البيانات للجمهور عبر الرابط: https://huggingface.co/Team-ACE.
One-sentence Summary
The authors present ToolACE, an automatic agentic pipeline that leverages a novel self-evolution synthesis process utilizing multi-agent interplay guided by a complexity evaluator and a dual-layer verification system to generate accurate, complex, and diverse tool-learning data from 26,507 diverse APIs, enabling models with only 8B parameters to achieve state-of-the-art function calling performance comparable to the latest GPT-4 models with the model and a data subset publicly available.
Key Contributions
- This work introduces ToolACE, an automated agentic pipeline designed to generate accurate and diverse tool-learning data through a novel self-evolution synthesis process. The system curates a comprehensive API pool of 26,507 diverse tools and utilizes multi-agent interactions to create complex dialogues.
- A self-guided complication strategy is developed to generate function-calling dialogs with appropriate complexity levels under the guidance of a large language model complexity evaluator. Data quality is maintained through a dual-layer verification system that integrates both rule-based and model-based checkers to ensure executability.
- Experimental results on the BFCL and APIBank benchmarks show that models trained on this synthesized data achieve state-of-the-art performance. Even an 8B parameter model trained with this method outperforms existing open-source LLMs and competes with the latest GPT-4 models.
Introduction
Equipping large language models with function calling capabilities is critical for deploying AI agents in complex real-world scenarios such as workflow automation and financial reporting. Yet, progress is limited by the scarcity of annotated real data and the poor coverage of existing synthetic datasets. The authors present ToolACE, an automated pipeline that generates accurate and diverse tool-learning data through a self-evolution synthesis process and multi-agent dialog generation. Their system includes a dual-layer verification framework to ensure quality, enabling smaller models to match the performance of larger proprietary systems.
Dataset
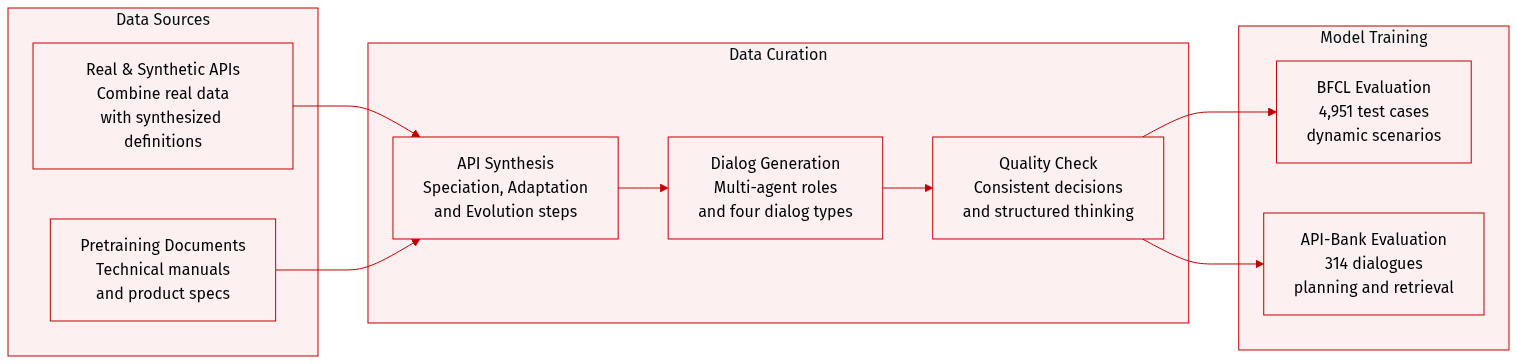
- Dataset Composition and Sources: The authors build a comprehensive API pool combining real API data with synthesized definitions. They extract domain information from pretraining data sources such as technical manuals, product specifications, and tutorials.
- Synthesis Methodology: A Tool Self-Evolution Synthesis module creates diverse APIs through three steps. Speciation constructs a hierarchical context tree from raw documents. Adaptation samples subtrees to ensure distinct functionalities across APIs. Evolution iteratively improves definitions using an example buffer and diversity indicators like parameter mutation.
- Dialog Generation: A multi-agent framework simulates user, assistant, and tool roles to produce function-calling dialogs. The system generates four dialog types including single calls, parallel calls, dependent calls, and non-tool-use interactions.
- Quality Assurance: To maintain data quality, the authors generate each assistant action multiple times and retain only responses with consistent decisions. A structured thinking process guides the assistant to make accurate tool-calling decisions.
- Evaluation Benchmarks: The model is evaluated using the Berkeley Function-Calling Benchmark which contains 4,951 test cases for dynamic scenarios. They also utilize API-Bank with 314 tool-use dialogues to assess planning and retrieval capabilities.
- Data Structure: The generated API documentation supports complex nested types including lists of lists or lists of dictionaries.
Method
The authors leverage a modular, agentic framework named ToolACE to generate high-quality, diverse, and complex function-calling data tailored to the capabilities of a given large language model (LLM). The overall architecture, as illustrated in the framework diagram, comprises three core components: Tool Self-evolution Synthesis (TSS), Self-Guided Dialog Generation (SDG), and Dual-Layer Validation (DLV). These components work in a coordinated manner to recursively synthesize APIs, generate contextually appropriate dialogs with adaptive complexity, and ensure data accuracy through automated and human-in-the-loop verification.
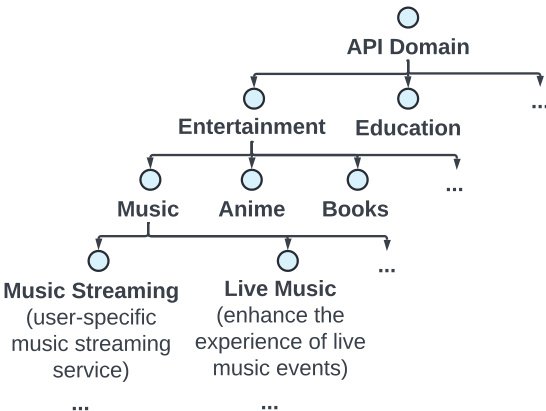
The first module, Tool Self-evolution Synthesis (TSS), is responsible for generating a rich and diverse set of APIs. It operates by recursively evolving a hierarchical API context tree, which is built from pretraining data and structured around an API domain. This tree, as shown in the figure below, organizes APIs into broad categories such as Entertainment and Education, further branching into specific subdomains like Music and Books. The synthesis process uses a self-evolve and update mechanism to iteratively generate new APIs based on existing examples and contextual information, ensuring a broad and representative coverage of tool functionalities.
The second module, Self-Guided Dialog Generation (SDG), synthesizes function-calling dialogs that are appropriately complex for the target LLM. This module is designed to address the mismatch between the model's capabilities and the generated data's difficulty. It consists of a multi-agent system where a user agent, an assistant agent, and a tool agent interact to create dialogs. The key innovation lies in the use of the LLM to be tuned, denoted as M, as a complexity evaluator. The evaluator measures the difficulty of a data sample (x,y) by computing the loss HM(x,y), defined as the negative log-likelihood of the target sequence y given the input x:
HmathcalM(x,y)=−frac1nysumi=1nylogp(ti∣x,t1,ldots,ti−1),,where x is the input query, y=[t1,ldots,tny] is the response, and p is the model's token prediction probability. A higher loss indicates greater complexity. This loss is positively correlated with the number of candidate APIs, the number of APIs utilized, and the dissimilarity between the user query and the API descriptions, as demonstrated in the figure below. The evaluator uses a small prior dataset to establish a suitable complexity range for the model, with the loss of correctly generated data serving as a lower bound and the loss of persistently difficult data serving as an upper bound. This information is then used as guidance for the multi-agent generator to produce data of optimal difficulty.
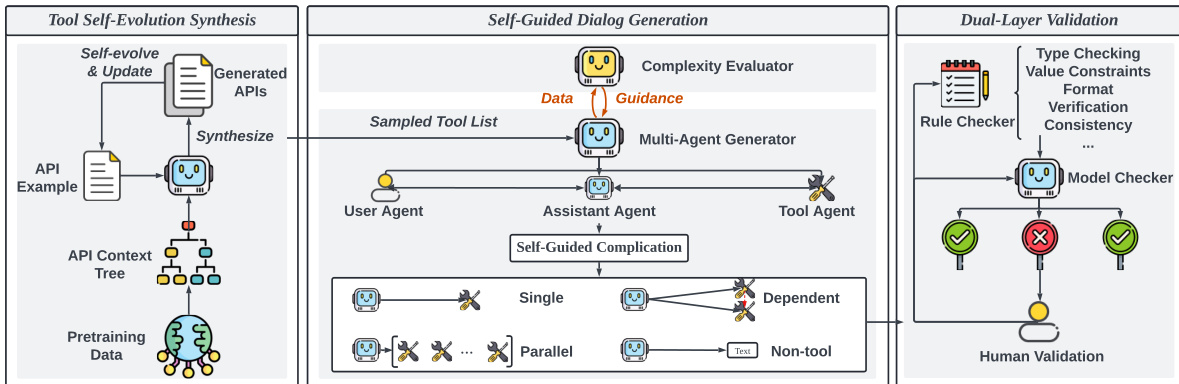
Following the generation of dialog data, the Dual-Layer Validation (DLV) module ensures the accuracy and reliability of the synthesized data. This system operates in two layers. The first is a rule verification layer, which employs a rule checker to enforce strict syntactic and structural compliance with the API definition. It validates four key aspects: API definition clarity, function calling executability (by checking API name, required parameters, and parameter formats using regular expressions), dialog correctness, and data sample consistency. The second layer is a model verification layer, which uses LLM-powered expert agents to evaluate content quality. This layer decomposes the verification task into sub-queries focused on hallucination detection, consistency validation, and tool response check. Each sub-task is handled by a dedicated agent, and the results are aggregated before being overseen by human experts for final validation. This dual-layer approach ensures that the training data is both syntactically correct and semantically meaningful.
Experiment
The study validates the ToolACE approach by fine-tuning LLaMA3.1-8B-Instruct and other backbones on synthesized data, comparing performance against state-of-the-art API-based and open-source models on BFCL and API-Bank benchmarks. Ablation studies reveal that dual-layer verification, medium data complexity, and high API diversity are critical for maximizing function calling accuracy and mitigating hallucinations. Results demonstrate that ToolACE significantly enhances functional calling capabilities across various model sizes and backbones without compromising general abilities, outperforming alternative training datasets and in-context learning methods.
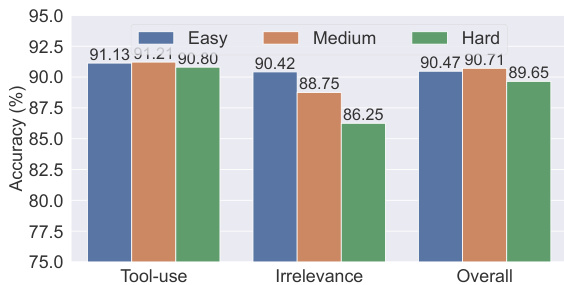
The chart compares model accuracy across different complexity levels for tool-use, irrelevance, and overall performance. Results show that medium complexity data yields the highest accuracy in tool-use and overall categories, while easy complexity performs best in irrelevance detection, indicating an optimal balance in data complexity for model training. Medium complexity data achieves the highest accuracy in tool-use and overall performance Easy complexity data shows the best performance in irrelevance detection Accuracy varies significantly across complexity levels, with medium complexity being optimal for most tasks
The the the table lists the hyperparameters used for training the LLMs with LoRA. These settings include a learning rate of 10^-4, a cosine learning rate scheduler, a batch size of 48, three epochs, and LoRA parameters with a rank of 16 and an alpha of 32. The training uses a cosine learning rate scheduler and a batch size of 48. LoRA is employed with a rank of 16 and an alpha of 32. The model is trained for three epochs with a learning rate of 10^-4.

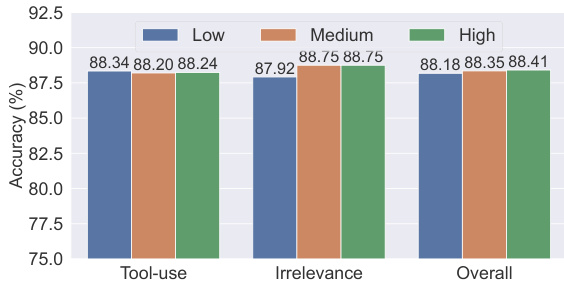
The authors compare the performance of various models on the BFCL benchmark, focusing on their ability to make correct function calls and retrieve relevant information. Results show that the ToolACE-8B model achieves high accuracy in both call and retrieval+call categories, outperforming most open-source models and demonstrating competitive performance against API-based models. ToolACE-8B achieves high accuracy in both call and retrieval+call categories, surpassing most open-source models. The model demonstrates competitive performance against API-based models, particularly in the call category. ToolACE-8B significantly outperforms other open-source models like xLAM-7b-fc-r and LLaMA-3.1-8B-Instruct in both categories.
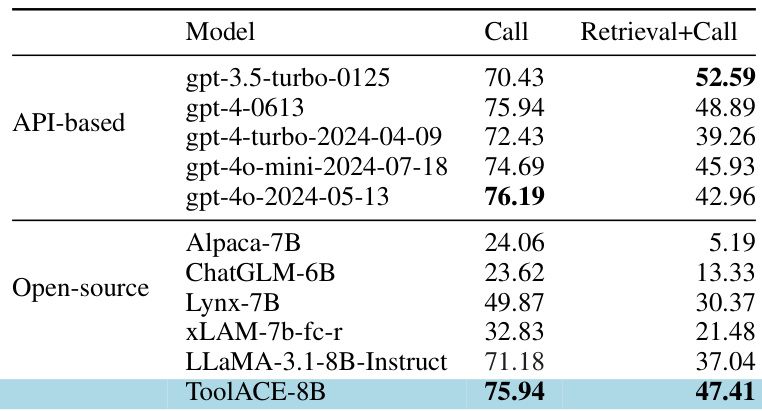
The chart shows the performance of models trained on data of varying complexity levels, with results presented for tool-use, irrelevance, and overall accuracy. Models trained on medium-complexity data achieve the highest accuracy across all categories, indicating that optimal complexity enhances functional calling performance. Models trained on medium-complexity data achieve the highest accuracy in all categories. Accuracy is lower for both low and high complexity data compared to medium complexity. The overall performance trend shows a slight improvement with increasing data complexity up to a medium level.
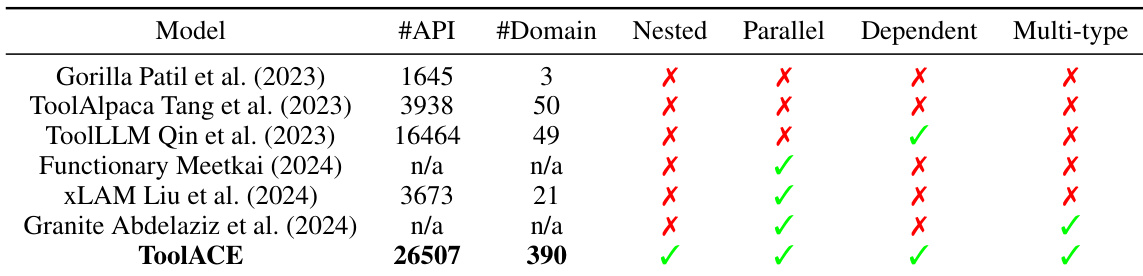
The the the table compares various datasets based on their API count, domain diversity, and inclusion of different data types such as nested, parallel, dependent, and multi-type samples. ToolACE stands out with the highest number of APIs and domains, and it includes all data types, indicating a comprehensive and diverse dataset. ToolACE has the highest number of APIs and domains compared to other datasets. ToolACE includes all data types, while others lack one or more types. The inclusion of diverse data types in ToolACE suggests a more comprehensive training dataset.
The evaluation utilizes LoRA training on a comprehensive dataset characterized by high API count and domain diversity to assess model capabilities on the BFCL benchmark. Results indicate that the ToolACE-8B model surpasses most open-source competitors in function calling and retrieval tasks while maintaining competitive performance against API-based models. Furthermore, experiments varying data complexity demonstrate that medium-complexity training data optimizes tool-use and overall accuracy, whereas easy complexity better supports irrelevance detection.