Command Palette
Search for a command to run...
الشبكات العصبية للترميز التنبؤي ذات الخروج المبكر للذكاء الاصطناعي على حافة الشبكة
الشبكات العصبية للترميز التنبؤي ذات الخروج المبكر للذكاء الاصطناعي على حافة الشبكة
Alaa Zniber Mounir Ghogho Ouassim Karrakchou Mehdi Zakroum
الملخص
يُحدث إنترنت الأشياء (IoT) تحولًا جذريًا في مجالات متعددة، حيث يتم دمج أجهزة الاستشعار بشكل متزايد في الأجهزة القابلة للارتداء، والمباني الذكية، والمعدات المتصلة. وعلى الرغم من أن التعلم العميق يتيح استخلاص رؤى قيمة من بيانات إنترنت الأشياء، فإن النماذج التقليدية تتطلب قدرات حاسوبية تفوق إمكانيات الأجهزة الطرفية محدودة الموارد. وعلاوة على ذلك، فإن مخاوف الخصوصية واحتياجات المعالجة في الوقت الفعلي تجعل الحوسبة المحلية ضرورة حتمية تفوق الحلول القائمة على السحابة. مستلهمين من كفاءة الطاقة في الدماغ البشري، نقترح شبكة ترميز تنبؤي ثنائية الاتجاه ضحلة مع آلية الخروج المبكر، والتي توقف العمليات الحسابية ديناميكيًا بمجرد تحقيق عائد أداء محدد. يؤدي هذا النهج إلى تقليل البصمة الذاكرة والتكاليف الحسابية مع الحفاظ على دقة عالية. وقد قمنا بالتحقق من صحة منهجيتنا باستخدام مجموعة بيانات CIFAR-10. وتُظهر نتائجنا أن نموذجنا يحقق أداءً يقارب أداء الشبكات العميقة، ومع ذلك يعتمد على عدد أقل بكثير من المعاملات (parameters) وتقليل في التعقيد الحسابي، مما يوضح الإمكانات الكبيرة للهندسات المستوحاة بيولوجيًا في مجال الذكاء الاصطناعي للطرفية (Edge AI) الفعّال.
One-sentence Summary
Researchers from the International University of Rabat, University Mohammed VI Polytechnic, and the University of Leeds propose EE-PCN, a shallow bidirectional predictive coding network with early exiting that dynamically halts computation to achieve deep-network accuracy with minimal memory and FLOPs for extreme edge AI.
Key Contributions
- The paper introduces a new derivation of predictive coding cycling rules for bidirectional networks that effectively implements both feedback and feedforward update mechanisms.
- A shallow predictive coding network is designed to achieve accuracy comparable to deeper models while significantly reducing the memory footprint for deployment on extreme-edge devices.
- The method incorporates a dynamic early-exiting mechanism and knowledge distillation across cycles to adaptively adjust the number of operations, thereby improving inference efficiency and the performance of early exits.
Introduction
The rise of IoT in sectors like health monitoring and smart cities demands real-time data processing on resource-constrained edge devices, yet conventional deep learning models are too computationally heavy and memory-intensive for these environments. While Predictive Coding Networks (PCNs) offer biologically inspired efficiency, prior implementations often double parameter counts compared to standard models and lack adaptive mechanisms, forcing them to perform unnecessary computations on simple inputs. To address these challenges, the authors propose a shallow bidirectional PCN that integrates an early exiting mechanism to dynamically halt inference once a performance threshold is met. This approach leverages knowledge distillation across cycles to maintain high accuracy while drastically reducing memory footprint and computational overhead, making it suitable for extreme edge deployment.
Dataset
- The authors use the CIFAR-10 dataset, which contains 60,000 32x32 RGB images evenly distributed across 10 classes to simulate low-resolution IoT applications like surveillance and smart farming.
- The dataset is split into a training set of 50,000 images and a test set of 10,000 images.
- Data augmentation is applied to the training set using random translation and horizontal flipping.
- The training data is processed into batches of 128 images for model learning.
Method
The authors propose a Predictive Coding Network (PCN) model enhanced with early exiting capabilities to optimize inference efficiency. The architecture consists of a shared backbone serving as a feature extractor, along with multiple downstream task classifiers. The backbone is designed as a bidirectional hierarchy of convolutional and deconvolutional layers.
As shown in the figure below:
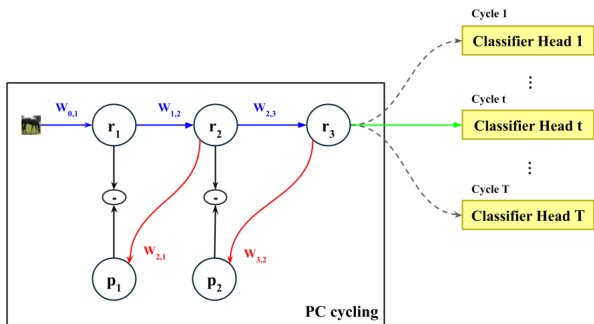
In this framework, blue arrows denote the forward convolutional pass, while red arrows indicate the feedback deconvolutions used to reduce local errors. During inference, the model performs a variable number of cycles, t≤T, over the backbone to iteratively minimize local prediction errors across all layers. Once the cycling process concludes, the final layer feature vector is passed to the classifier corresponding to the current cycle count t, indicated by the green arrow. The classification confidence is then compared against a predefined user threshold. If the confidence exceeds the threshold, the inference is terminated and a response is returned. Otherwise, another cycle is initiated, followed by another classification and threshold comparison.
The architecture employs T distinct classifiers rather than a single classifier shared across all cycles. This decision is driven by the evolving nature of feature representations throughout the iterative process. Since feature vectors undergo continuous refinement from one cycle to the next, a classifier trained on feature representations from a five-cycle model would be unable to accurately interpret the patterns extracted by a one-cycle model for the same input.
To derive the PC update rules, the authors apply gradient descent to minimize the local errors at each pass. Let rl(t) denote the feature representation at convolution layer l and cycle t. The representation at layer l=0 is fixed as the input image. For t=0, all feature representations are initialized through a standard feedforward pass: rl(0)=ϕ(Wl−1,lrl−1(0)),l=1,⋯,L where ϕ is a nonlinear activation function, assumed to be ReLU in the experiments.
The feedback pass update rule governs a process in which the higher-layer representation, rl+1(t), generates a top-down prediction of the lower-layer representation, rl(t), denoted by pl(t). This prediction is given by: pl(t)=ϕ[Wl+1,lrl+1(t)] The update is carried out by minimizing the local error, defined as ϵl(t)=21∣∣rl(t)−pl(t)∣∣22. The feedback update rule, computed at the midpoint t+1/2, is expressed as: rl(t+1/2)=(1−αl)rl(t)+αlϕ[Wl+1,lrl+1(t)] The representation of the last layer remains unaffected during the feedback pass by design.
The feed-forward pass update rule governs a process in which the lower-layer representation generates a bottom-up prediction, which is then used to update the upper-layer representation. The feed-forward prediction is given by: pl(t+1/2)=ϕ[Wl−1,lrl−1(t+1/2)] This results in the following feed-forward update rule: rl(t+1)=(1−βl)rl(t+1/2)+βlϕ[Wl−1,lrl−1(t+1/2)] Unlike prior formulations that rely solely on feedback convolution weight matrices, this formulation integrates both top-down and bottom-up predictions, leading to a more comprehensive update mechanism.
Regarding training, the classification task is formulated as a multi-objective optimization problem where T losses, denoted as Li, compete over the shared weights. The authors address this using scalarization, transforming the problem into a single-objective optimization through a weighted average. Furthermore, they incorporate Kullback-Leibler (KL) divergence, denoted as KD, between intermediate logits and the final-cycle logits to facilitate knowledge distillation. In this framework, the deepest network acts as the teacher, while the preceding shallow sub-networks serve as students. The total loss is expressed as: Ltot=ρ∑i=1TλiLi+(1−ρ)∑i=1T−1KD(y^i,y^T) where λi is a positive weighting factor for the loss function Li, y^i represents the logit vector from classifier i, and ρ is a balancing factor.
The model design leverages PC dynamics to develop shallow networks capable of running on extreme edge devices. The models are based on VGG-like architectures where all convolutions use a 3×3 kernel with a stride of 1 and are followed by a ReLU activation function. Whenever the number of channels changes, max-pooling is applied in the feed-forward direction or upsampling in the feedback direction with a 2×2 kernel. Finally, the early exit classifiers are implemented as simple linear layers to ensure minimal overhead.
Experiment
- Experiments validate that recursive processing with PC update rules in shallow models achieves competitive performance on extreme edge devices, outperforming edge-specific baselines and approaching VGG-11 accuracy with significantly fewer parameters.
- Results demonstrate that additional processing cycles enhance model expressivity, allowing shallow architectures to better learn complex patterns and distinguish difficult classes.
- Integrating an early exiting mechanism significantly reduces computational load and energy consumption, with high-confidence thresholds enabling the model to exit early for most inputs while maintaining accuracy.
- The proposed models meet strict memory constraints of frugal microcontrollers, and their recursive nature ensures lower FLOP counts than deep networks for a large portion of the dataset, facilitating extended battery life.
- Comparisons confirm that predictive coding rules combining top-down and bottom-up predictions outperform equivalent feed-forward CNNs.