Command Palette
Search for a command to run...
المشتق التربيعي: إطار موحد يربط بين نزول التدرج وطرق نيوتن من خلال تركيب الهيسيينات والتدرجات
المشتق التربيعي: إطار موحد يربط بين نزول التدرج وطرق نيوتن من خلال تركيب الهيسيينات والتدرجات
John Chiang
الملخص
تُعد تسريع تقارب طرق التحسين من الرتبة الثانية، ولا سيما الطرق من نوع نيوتن، تحديًا محوريًا في البحوث الخوارزمية. في هذه الورقة، نوسع الأعمال السابقة حول التدرج التربيعي (Quadratic Gradient - QG) ونُثبّتُ صرامةً قابليته للتطبيق على مسائل التحسين العددي المحدب العامة. نقدم صيغةً جديدةً من التدرج التربيعي تنحرف عن إطار نيوتن التقليدي القائم على مصفوفة هيسية ثابتة. نعرض منهجيةً جديدةً لبناء نسخة محدثة من التدرج التربيعي؛ وهذه النسخة الجديدة لا تستوفي شروط تقارب طريقة نيوتن ذات الهيسية الثابتة. ومع ذلك، تُظهر النتائج التجريبية أنها تتفوق أحيانًا على النسخة الأصلية من حيث معدل التقارب. ورغم أن هذا الاختلاف يخفف من بعض قيود التقارب الكلاسيكية، فإنه يحافظ على تقريب موجب التعريف لمصفوفة الهيسية، ويُظهر أداءً تجريبيًا مماثلاً، بل ومتفوقًا في بعض الحالات، من حيث معدلات التقارب. علاوةً على ذلك، نثبت أن كلاً من النسخة الأصلية من التدرج التربيعي (QG) والنسخة المقترحة يمكن تطبيقهما بفعالية على أراضٍ تحسينية غير محدبة. إن الدافع الرئيسي لعملنا هو محدودية معدلات التعلم القياسية التقليدية. نحن نجادل بأن المصفوفة القطرية يمكنها تسريع عناصر التدرج بمعدلات غير متجانسة بفعالية أكبر. وتُرسخُ نتائجنا التدرج التربيعي (QG) كإطار متنوع وقوي للتحسين الحديث. بالإضافة إلى ذلك، ندمج مُقدّر هاتشينسون (Hutchinson's Estimator) لتقدير القطر الرئيسي لمصفوفة الهيسية بكفاءة عبر حاصل ضربات الهيسية-المتجه (Hessian-vector products). والجدير بالذكر أننا نثبت أن الصيغة المقترحة من التدرج التربيعي فعالة للغاية في هندسات التعلم العميق (Deep Learning architectures)، مما يوفر بديلاً قويًا من الرتبة الثانية لمُحسّنات التكيف القياسية.
One-sentence Summary
John Chiang proposes a novel Quadratic Gradient variant that replaces fixed Hessian Newton frameworks with a diagonal matrix approach to accelerate convergence in Deep Learning. By integrating Hutchinson's Estimator for efficient Hessian diagonal approximation, this method outperforms traditional scalar learning rates in non-convex optimization landscapes.
Key Contributions
- The paper introduces a novel variant of the Quadratic Gradient that departs from the fixed Hessian Newton framework by maintaining a positive-definite Hessian proxy, which allows for effective application to non-convex optimization landscapes where traditional methods often fail.
- This work integrates Hutchinson's Estimator to efficiently approximate the Hessian diagonal via Hessian-vector products, reducing the computational complexity of second-order information from O(n2) to O(n) and enabling scalability for Deep Learning architectures.
- Experimental results demonstrate that the proposed Quadratic Gradient variants achieve comparable or superior convergence rates compared to original methods and standard adaptive optimizers, validating their utility as a robust second-order alternative for general convex and non-convex problems.
Introduction
Modern numerical optimization struggles to balance the scalability of first-order methods like SGD with the rapid convergence of second-order approaches like Newton's method, as the former fails on ill-conditioned curvatures while the latter incurs prohibitive computational costs and sensitivity to Hessian indefiniteness. Prior work on the Quadratic Gradient (QG) has shown promise in specific tasks like logistic regression but often relies on fixed Hessian approximations that limit general applicability and theoretical convergence guarantees. The authors leverage a novel QG variant that synthesizes curvature information into a diagonal matrix to replace scalar learning rates, enabling dimension-wise acceleration without satisfying the strict constraints of traditional fixed Hessian Newton methods. By integrating Hutchinson's Estimator for efficient Hessian diagonal approximation, they establish a unified framework that extends to general convex and non-convex landscapes, offering a robust second-order alternative to standard adaptive optimizers in Deep Learning.
Dataset
The provided text only lists the titles "mnist" and "credi" under the section "Large-Scale Datasets" without offering any descriptive content. Consequently, it is not possible to draft a dataset description covering composition, sources, filtering rules, training splits, or processing strategies based on this input. No further details regarding dataset size, metadata construction, or model usage are available in the source material.
Experiment
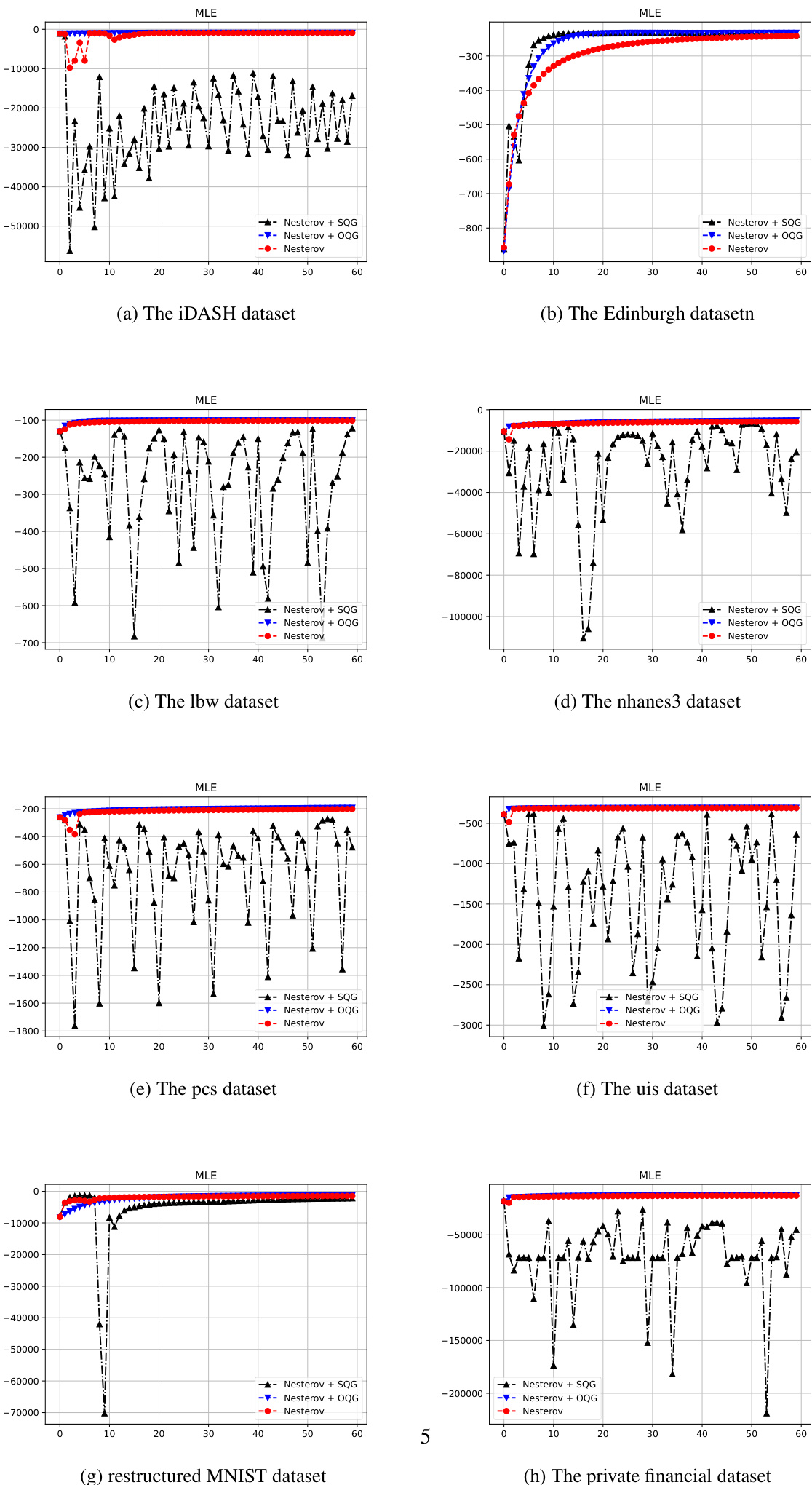
- Logistic regression experiments on multiple datasets validate that the Simplified Quadratic Gradient (SQG) framework maintains high computational efficiency and convergence speed comparable to the original method while offering a more streamlined architecture, though it requires conservative learning rate decay for NAG to ensure stability.
- Deep learning tests on ResNet-18 demonstrate that the new QG variant achieves faster convergence than Adam and exhibits superior stability in non-convex regions compared to AdaHessian, with computational overhead comparable to second-order methods.
- Benchmark evaluations on convex and non-convex functions confirm the algorithm's ability to handle dimensional scaling and navigate ill-conditioned valleys effectively.
- Saddle point analysis reveals that the QG variant overcomes the stagnation typical of first-order methods by utilizing spectral information to assign large adaptive steps along directions of minimal curvature, allowing the optimizer to escape saddle points efficiently.
- Overall, the framework successfully bridges first and second-order optimization by integrating Hessian approximations to accelerate convergence and robustly manage complex topological features in high-dimensional spaces.