الموارد الحاسوبية المستخدمة في هذا البرنامج التعليمي هي بطاقة A6000 واحدة.
Kimi-Audio-7B-Instruct هو نموذج أساسي مفتوح المصدر لمعالجة الصوت، أصدره فريق KimiTeam في 28 أبريل 2025. يستطيع هذا النموذج التعامل مع مهام معالجة صوتية متنوعة ضمن إطار عمل موحد. وتشمل الأبحاث ذات الصلة... تقرير فني لشركة كيمي أوديو تشمل الوظائف الرئيسية ما يلي:
قدرات الأغراض العامة: تتعامل مع مجموعة متنوعة من المهام مثل التعرف التلقائي على الكلام (ASR)، والإجابة على الأسئلة الصوتية (AQA)، والترجمة الصوتية التلقائية (AAC)، والتعرف على عاطفة الكلام (SER)، وتصنيف الأحداث/المشهد الصوتي (SEC/ASC)، والحوار الصوتي الشامل.
أداء رائد في الصناعة: يحقق مستويات SOTA في معايير الصوت المتعددة.
التدريب المسبق على نطاق واسع: التدريب المسبق على أكثر من 13 مليون ساعة من البيانات الصوتية المختلفة (الكلام والموسيقى والصوت) وبيانات النص لتمكين التفكير الصوتي القوي وفهم اللغة.
هندسة مبتكرة: باستخدام مدخلات الصوت الهجينة (متجه صوتي مستمر + علامات دلالية منفصلة) ونواة LLM مع قدرات المعالجة المتوازية، يمكن إنشاء علامات النص والصوت في وقت واحد.
الاستدلال الفعال: جهاز فك الإرسال المتدفق المقسم مع مطابقة التدفق لتوليد صوت منخفض الكمون.
المصدر المفتوح: إصدار نقاط تفتيش للكود والنموذج من أجل الضبط الدقيق للتدريب المسبق والتعليمات، وإصدار مجموعة أدوات تقييم شاملة لتعزيز البحث والتطوير المجتمعي.
2. خطوات التشغيل
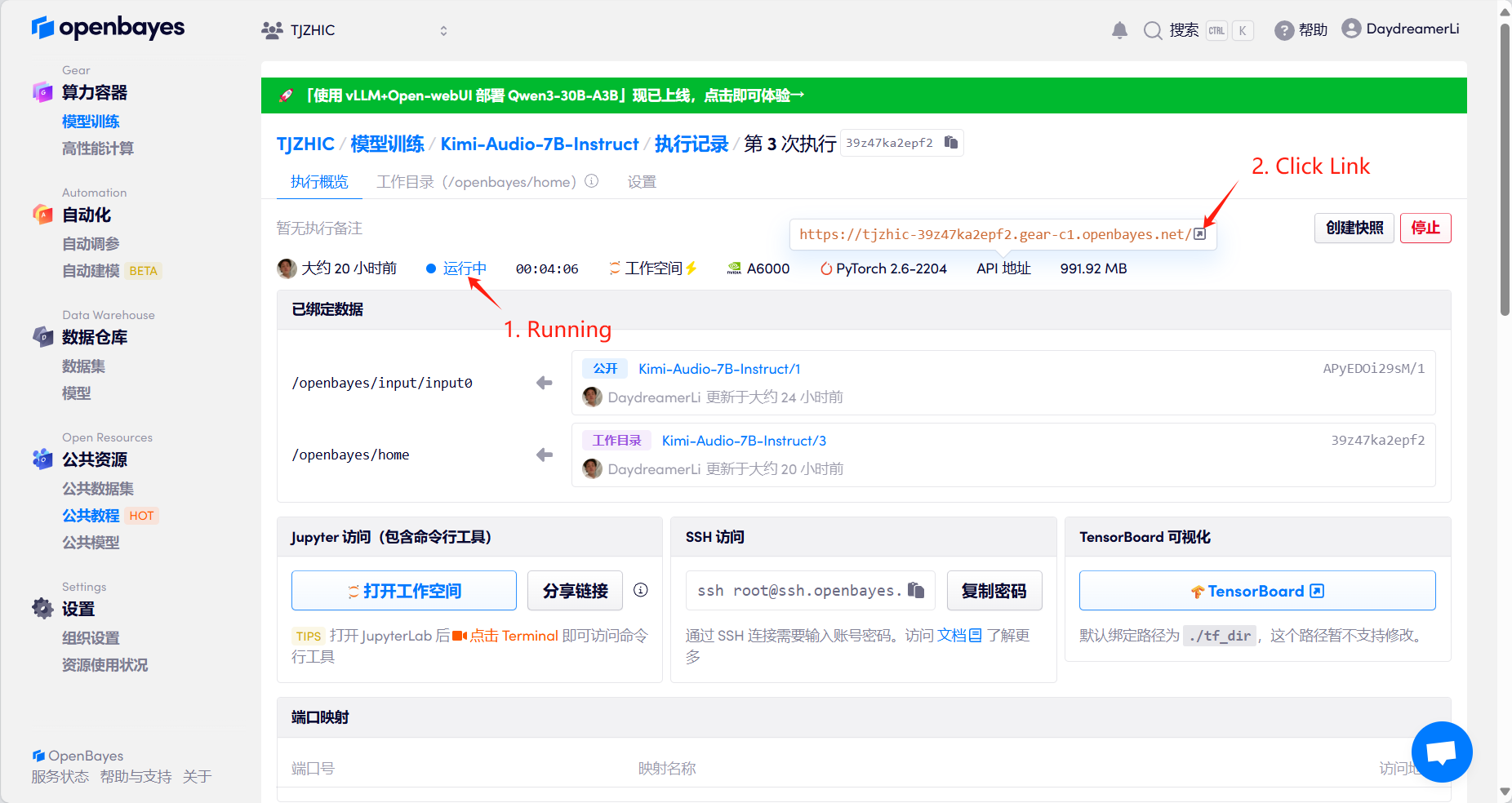
1. ابدأ تشغيل الحاوية
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 3-5 دقائق وتحديث الصفحة.
2. أمثلة الاستخدام
إرشادات الاستخدام
عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
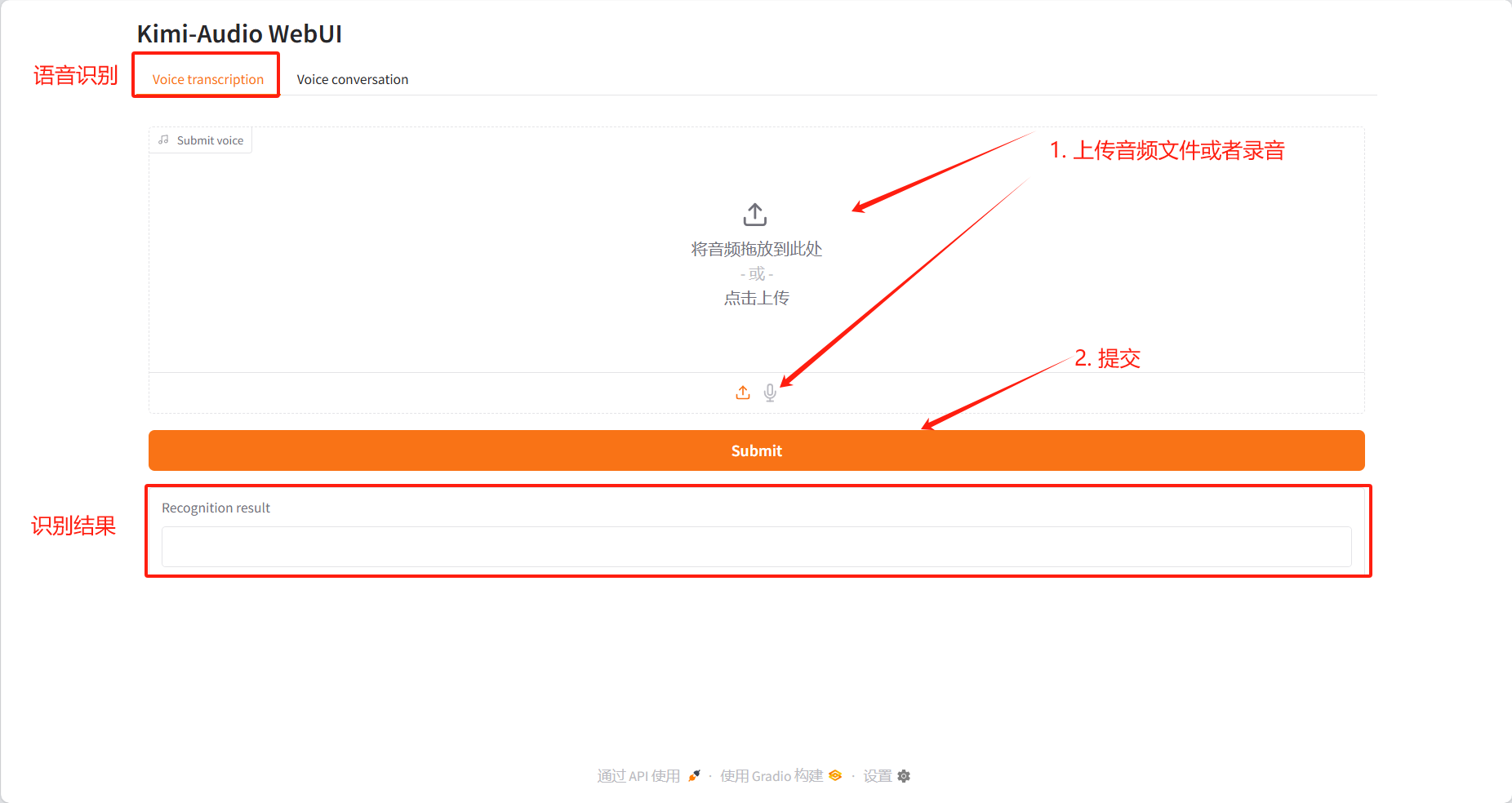
يوفر هذا البرنامج التعليمي اختبارين للوحدة: النسخ الصوتي والمحادثة الصوتية.
وظائف كل وحدة هي كما يلي:
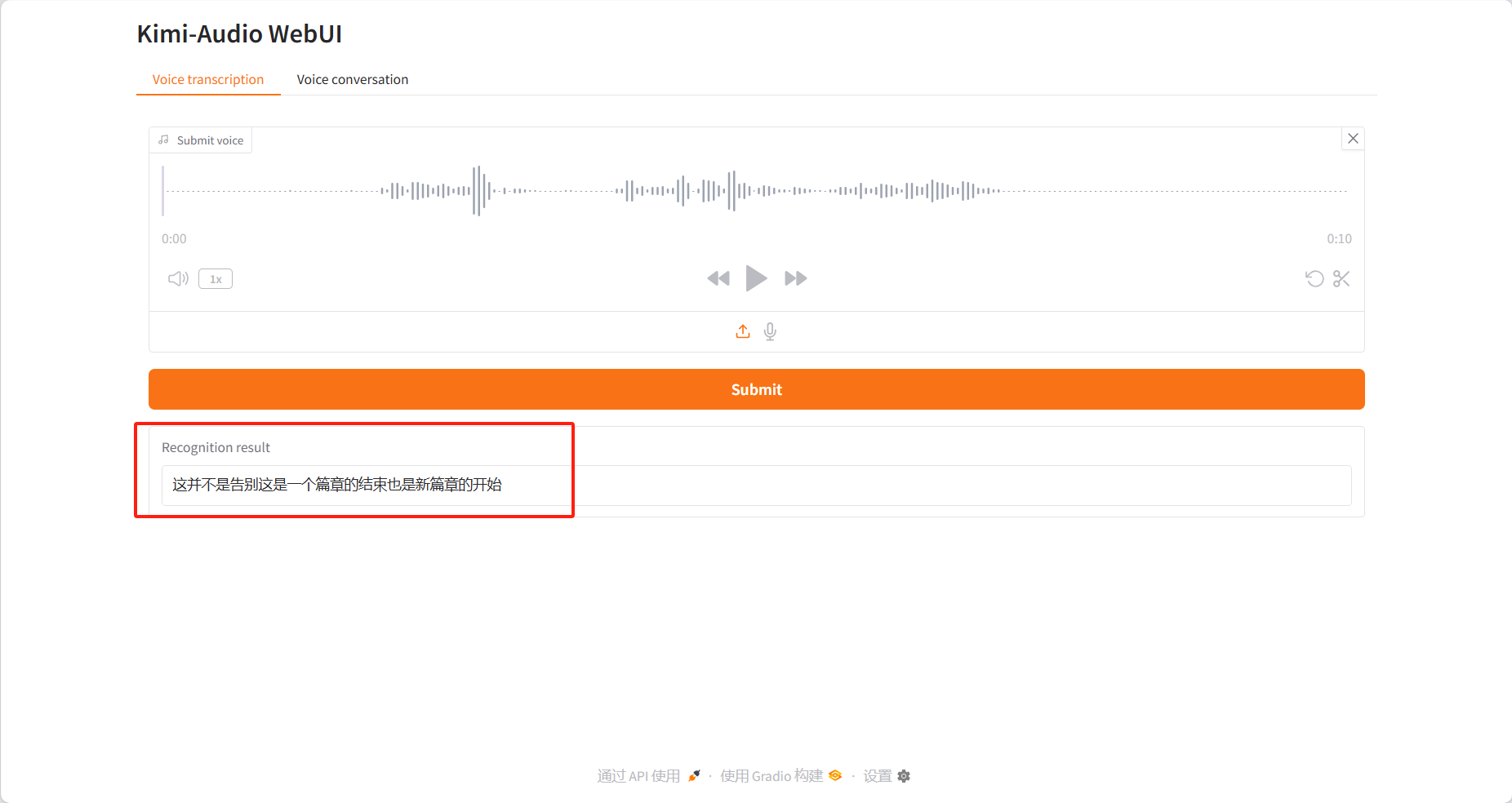
نسخ الصوت
نتائج التعريف
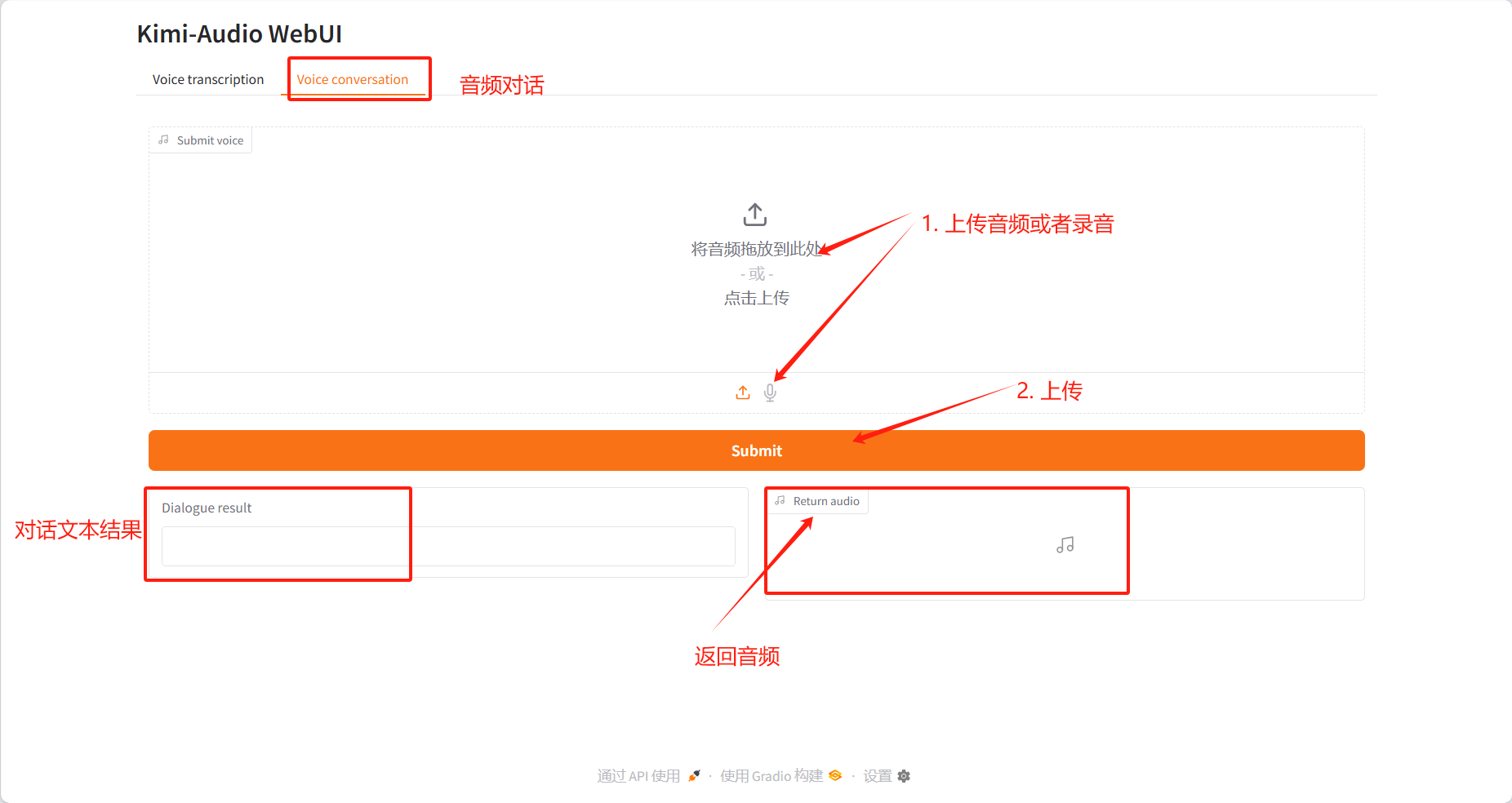
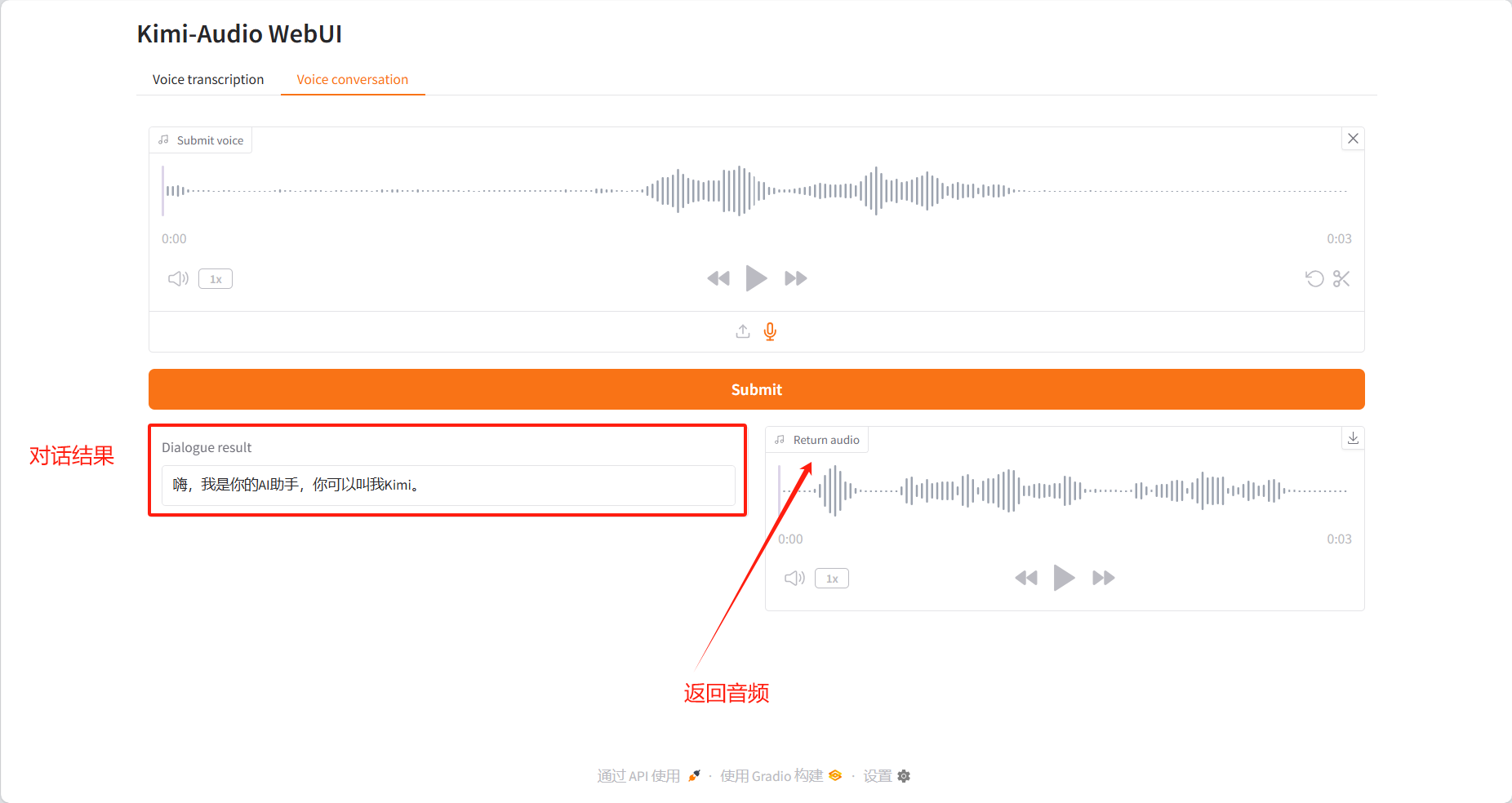
محادثة صوتية
نتائج الحوار
3. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓
معلومات الاستشهاد
شكرًا لمستخدم Github سوبر يانغ نشر هذا البرنامج التعليمي. معلومات الاستشهاد لهذا المشروع هي كما يلي:
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
تم المساهمة في هذا الدفتر من قبل مستخدمي المجتمع وهو مخصص لأغراض تعليمية وإعلامية فقط. إذا كان أي محتوى ينطوي على انتهاك لحقوق النشر، يرجى الاتصال بنا على [email protected] للمراجعة والإزالة الفورية.
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.
الموارد الحاسوبية المستخدمة في هذا البرنامج التعليمي هي بطاقة A6000 واحدة.
Kimi-Audio-7B-Instruct هو نموذج أساسي مفتوح المصدر لمعالجة الصوت، أصدره فريق KimiTeam في 28 أبريل 2025. يستطيع هذا النموذج التعامل مع مهام معالجة صوتية متنوعة ضمن إطار عمل موحد. وتشمل الأبحاث ذات الصلة... تقرير فني لشركة كيمي أوديو تشمل الوظائف الرئيسية ما يلي:
قدرات الأغراض العامة: تتعامل مع مجموعة متنوعة من المهام مثل التعرف التلقائي على الكلام (ASR)، والإجابة على الأسئلة الصوتية (AQA)، والترجمة الصوتية التلقائية (AAC)، والتعرف على عاطفة الكلام (SER)، وتصنيف الأحداث/المشهد الصوتي (SEC/ASC)، والحوار الصوتي الشامل.
أداء رائد في الصناعة: يحقق مستويات SOTA في معايير الصوت المتعددة.
التدريب المسبق على نطاق واسع: التدريب المسبق على أكثر من 13 مليون ساعة من البيانات الصوتية المختلفة (الكلام والموسيقى والصوت) وبيانات النص لتمكين التفكير الصوتي القوي وفهم اللغة.
هندسة مبتكرة: باستخدام مدخلات الصوت الهجينة (متجه صوتي مستمر + علامات دلالية منفصلة) ونواة LLM مع قدرات المعالجة المتوازية، يمكن إنشاء علامات النص والصوت في وقت واحد.
الاستدلال الفعال: جهاز فك الإرسال المتدفق المقسم مع مطابقة التدفق لتوليد صوت منخفض الكمون.
المصدر المفتوح: إصدار نقاط تفتيش للكود والنموذج من أجل الضبط الدقيق للتدريب المسبق والتعليمات، وإصدار مجموعة أدوات تقييم شاملة لتعزيز البحث والتطوير المجتمعي.
2. خطوات التشغيل
1. ابدأ تشغيل الحاوية
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 3-5 دقائق وتحديث الصفحة.
2. أمثلة الاستخدام
إرشادات الاستخدام
عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
يوفر هذا البرنامج التعليمي اختبارين للوحدة: النسخ الصوتي والمحادثة الصوتية.
وظائف كل وحدة هي كما يلي:
نسخ الصوت
نتائج التعريف
محادثة صوتية
نتائج الحوار
3. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓
معلومات الاستشهاد
شكرًا لمستخدم Github سوبر يانغ نشر هذا البرنامج التعليمي. معلومات الاستشهاد لهذا المشروع هي كما يلي:
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
تم المساهمة في هذا الدفتر من قبل مستخدمي المجتمع وهو مخصص لأغراض تعليمية وإعلامية فقط. إذا كان أي محتوى ينطوي على انتهاك لحقوق النشر، يرجى الاتصال بنا على [email protected] للمراجعة والإزالة الفورية.
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.