Command Palette
Search for a command to run...
نُشرت في مجلة الطبيعة! يشرح المؤلف الأول للورقة بالتفصيل طريقة التعلم بالعينة الصغيرة لنموذج لغة البروتين لحل مشكلة نقص البيانات التجريبية الرطبة

في الحلقة الثالثة من سلسلة "Meet AI4S"، يشرفنا دعوة تشو زيي، زميل ما بعد الدكتوراه في معهد العلوم الطبيعية بجامعة شنغهاي جياو تونغ والمركز الوطني شنغهاي للرياضيات التطبيقية،تركز مجموعته البحثية في جامعة شنغهاي جياو تونغ، وهي مجموعة هونغ ليانغ، على تصميم البروتين والأدوية بالذكاء الاصطناعي، والفيزياء الحيوية الجزيئية. وقد توصل فريق البحث إلى نتائج مثمرة. وقد نشروا حتى الآن 77 ورقة بحثية، نُشر العديد منها في مجلات Nature.
في جلسة المشاركة هذه، شارك الدكتور تشو زيي أحدث نتائج أبحاث الفريق تحت عنوان "طريقة التعلم بالعينة الصغيرة لنموذج لغة البروتين" واستكشف أفكارًا جديدة للتطور الموجه بمساعدة الذكاء الاصطناعي.
الخلفية البحثية لنموذج لغة البروتين (PLM)
البروتين وهندسة البروتين
البروتين هو الناقل الرئيسي للوظائف البيولوجية والمنفذ للأنشطة الحيوية. يتعرض حمض الأمونيا الأميني الطبيعي لتفاعل التكثيف بالجفاف لتشكيل تسلسل بقايا البروتين، والذي يتم طيه بعد ذلك في بنية ثالثية. إن تغيير ملف الأحماض الأمينية في البروتين قد يؤثر على بنيته ووظيفته.
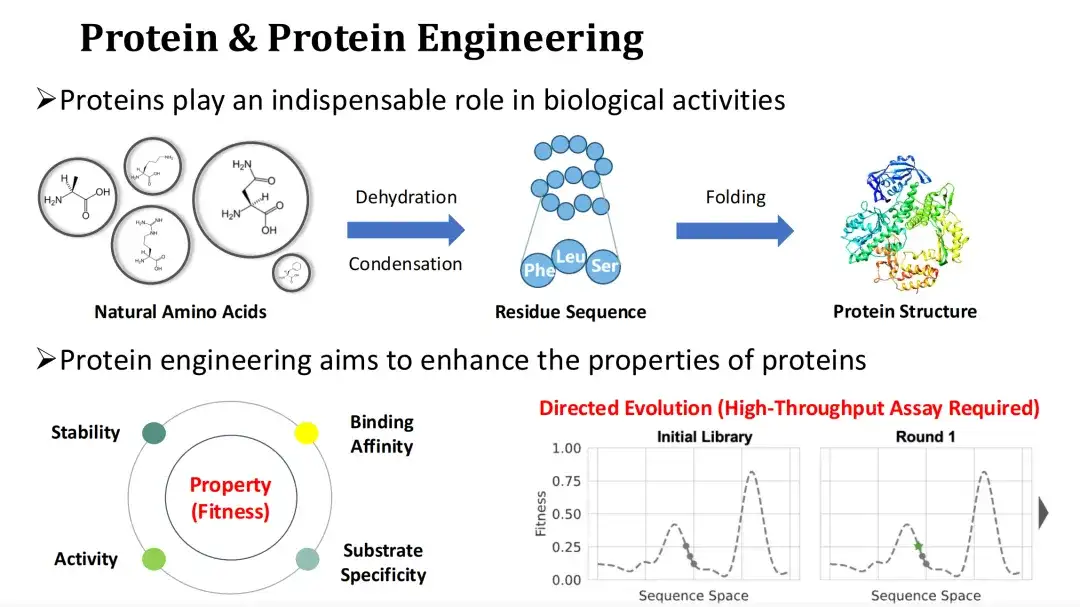
نظرًا لأن البروتينات الطبيعية غالبًا ما يصعب تلبية الاحتياجات الصناعية أو الطبية، فإن هندسة البروتين تأمل في تحسين الخصائص الوظيفية للبروتينات، مثل النشاط التحفيزي والاستقرار والقدرة على الارتباط وما إلى ذلك، عن طريق تحويرها.
نحن عادة نشير إلى قياس الخصائص الوظيفية للبروتين باللياقة البدنية. أصبح التطور الموجه الآن هو الأسلوب السائد في هندسة البروتين.وتعتمد هذه الطريقة على الطفرات العشوائية والتجارب عالية الإنتاجية للعثور على الطفرات ذات اللياقة البدنية العالية، ولكن تكاليف التجارب مرتفعة. وفي ضوء ذلك،الموضوع الذي سأشاركه اليوم هو كيفية استخدام أساليب الذكاء الاصطناعي للتنبؤ باللياقة البدنية وبالتالي تقليل التكاليف التجريبية.
هندسة إدارة دورة حياة المنتج
نحن نعلم أن نماذج اللغة التي يمثلها ChatGPT قوية جدًا وقادرة على فهم النصوص وتوليدها بجودة عالية. يتم تدريب نماذج اللغة هذه مسبقًا على كميات هائلة من النصوص وتكون قادرة على تعلم القوانين الإحصائية للنص وإتقان القواعد الأساسية ودلالات الكلمات في السياق. فهل من الممكن تدريب نماذج لغة البروتين بطريقة مماثلة على تسلسلات بروتينية ضخمة؟ الجواب هو نعم.

نموذج لغة البروتين PLM لديه ثلاث وظائف رئيسية. أولاً، يمكن لـ PLM نمذجة المعلومات التطورية المشتركة لتسلسلات البروتين وتعلم الترابطات والقيود التطورية بين البقايا.تمامًا مثل اللغة الطبيعية، يمكن لـ LM تعلم قواعد النص. يمكن لـ PLM استخدام هذه القدرة لتقدير الطفرات الضارة أو المفيدة، وبالتالي التنبؤ بملاءمة الطفرة.
ثانيًا، بالإضافة إلى التنبؤ باللياقة البدنية، يمكن لـ PLM أيضًا حساب التمثيل المتجه للبروتينات.يمكن استخدام هذه التمثيلات للتنبؤ بالبنية أو استخراج البروتين، وبعد الضبط الدقيق، يمكنها أيضًا إجراء تنبؤ بالوظيفة.
أخيرًا، يمكن لـ PLM تنفيذ عملية توليد بروتين مشروط مثل ChatGPT لتحقيق تصميم بروتين جديد.
إن هندسة PLM تشبه هندسة LM للغة الطبيعية، والتي تنقسم إلى نموذج الانحدار التلقائي والنموذج المقنع.يستخدم هيكل الشبكة لهذين النموذجين المحول، الذي يتكون من آلية الاهتمام الذاتي وطبقة متصلة بالكامل. الفرق الرئيسي يكمن في أهداف ما قبل التدريب.
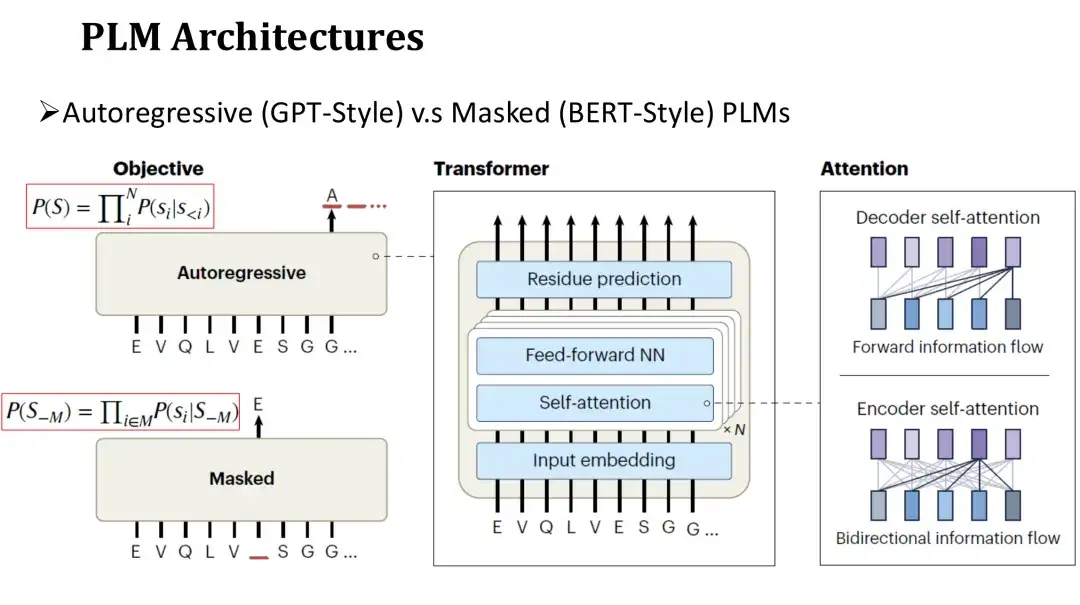
الهدف من التدريب المسبق للنموذج الانحداري التلقائي هو توليد الأحماض الأمينية التالية بالتسلسل من اليسار إلى اليمين.الهدف من نموذج الإخفاء هو استعادة الأحماض الأمينية المقنعة بشكل عشوائي، على غرار ملء الفراغات. نظرًا لأن النموذج الانحداري التلقائي لا يمكنه الاعتماد إلا على التسلسل الناتج على اليسار عند التنبؤ بكل حمض أميني، فإن انتباهه يكون أحادي الاتجاه.يمكن لنموذج القناع رؤية الأحماض الأمينية على جانبي الموضع المقنع أثناء التنبؤ.لذلك فإن اهتمامها ثنائي الاتجاه.
اتجاهان بحثيان ساخنان في إدارة دورة حياة المنتج
في الوقت الحاضر، تنقسم النقاط الساخنة لأبحاث إدارة دورة حياة المنتج بشكل رئيسي إلى اتجاهين. الأول هو PLM المعزز بالاسترجاع.أثناء التدريب أو التنبؤ، يأخذ هذا النوع من النماذج محاذاة التسلسل المتعددة (MSA) للبروتين الحالي كمدخل إضافي ويحسن أداء التنبؤ من خلال المعلومات المسترجعة. على سبيل المثال، MSA Transformer وTranception هما نموذجان نموذجيان لهذا النوع.
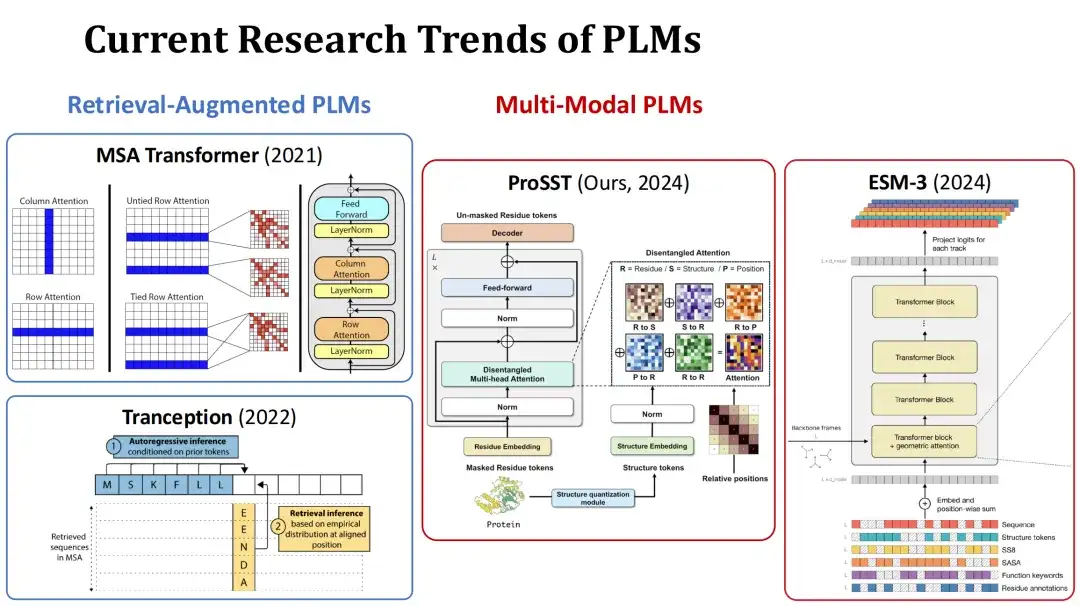
الثاني هو Multi-Modal PLM.بالإضافة إلى تسلسلات البروتين، يأخذ هذا النوع من النماذج أيضًا بنية البروتين أو معلومات أخرى كمدخلات إضافية لتعزيز قدرة النموذج على التمثيل. على سبيل المثال، يقوم نموذج ProSST الذي قدمته مجموعتنا هذا العام بقياس بنية البروتين في تسلسل رمزي هيكلي وإدخاله في نموذج Transformer مع تسلسل الأحماض الأمينية، مما يؤدي إلى دمج هذين النوعين من المعلومات من خلال آلية انتباه منفصلة. ومثال آخر على ذلك هو النموذج المعاصر ESM-3، الذي يأخذ في الاعتبار معلومات أكثر ثراءً، بما في ذلك نوع الأحماض الأمينية، والبنية الثلاثية الكاملة، ورمز البنية الثلاثية، والبنية الثانوية، ومساحة السطح التي يمكن الوصول إليها بالمذيب (SASA)، والوصف الوظيفي للبروتينات والبقايا، بإجمالي 7 مدخلات.
التنبؤ باللياقة البدنية الخاضعة للإشراف وغير الخاضعة للإشراف
بعد ذلك، سنناقش مشكلة التنبؤ باللياقة البدنية.نظرًا لأن PLM يمكنه نمذجة توزيع الاحتمالات لتسلسلات البروتين، فيمكن استخدامه مباشرة للتنبؤ بملاءمة الطفرات دون بيانات مُسمّاة. تُسمى هذه الطريقة بالتنبؤ بدون رقابة أو التنبؤ غير الخاضع للإشراف.

على وجه التحديد، يقوم PLM بتسجيل الطفرات عن طريق حساب نسبة الاحتمال اللوغاريتمي بين الطفرة والنوع البري. بالنسبة للنموذج الانحداري التلقائي، فإن احتمال التسلسل P هو حاصل ضرب احتمالات توليد كل حمض أميني. يمكن الحصول على درجة الطفرة عن طريق طرح logP من النوع البري من logP المتحور. من الناحية البديهية، فإن الأمر يتعلق بمقارنة احتمال حدوث الطفرة بالنسبة للنوع البري، ثم تقييم تأثير الطفرة. هذه طريقة تقييم تجريبية.
بالنسبة لنموذج الإخفاء، من المستحيل حساب احتمال التسلسل بأكمله بشكل مباشر، لكنه يستطيع أولاً إخفاء نقطة معينة ثم تقدير توزيع احتمالات الأحماض الأمينية في هذه النقطة. لذلك، بالنسبة لكل موضع طفرة، يمكن طرح logP للحمض الأميني من النوع البري من logP للحمض الأميني المتحور المتوقع بعد الإخفاء، ومن ثم يمكن إضافة الفرق في جميع المواضع للحصول على درجة الطفرة.
بالإضافة إلى ذلك، نظرًا لأن PLMs توفر تمثيلات متجهية لتسلسلات البروتين، فيمكن أيضًا ضبطها بدقة لتحقيق التنبؤ باللياقة البدنية الخاضعة للإشراف عندما تكون هناك بيانات تجريبية كافية.
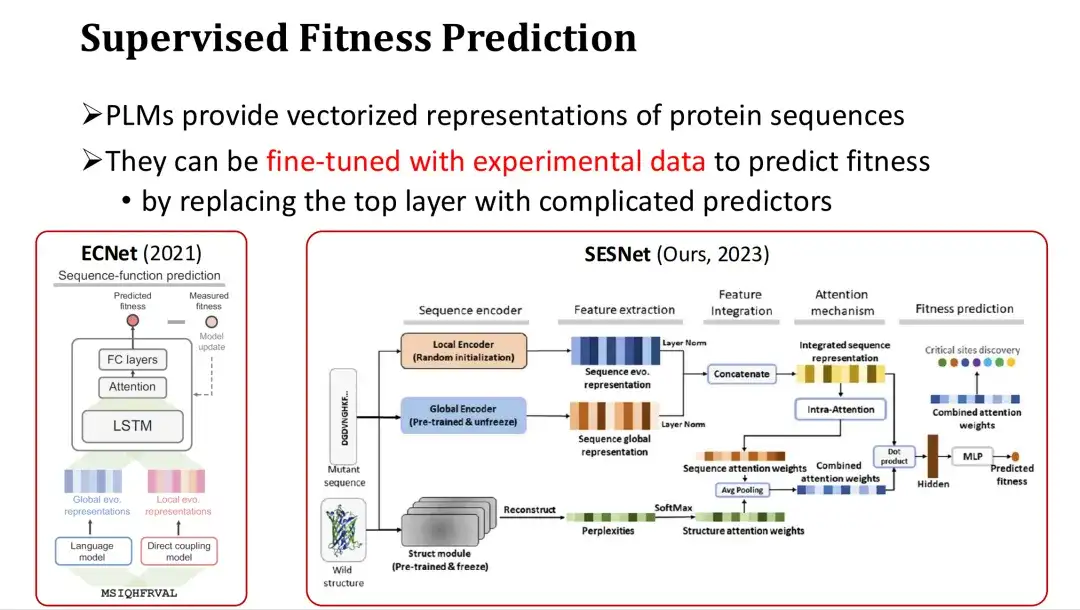
النهج المحدد هو إضافة طبقة إخراج للتنبؤ باللياقة البدنية (مثل آلية الانتباه أو الإدراك متعدد الطبقات MLP) بعد الطبقة الأخيرة من ميزات PLM، واستخدام Fitness Label للتدريب الكامل أو الجزئي. على سبيل المثال، تقوم ECNet بإضافة ميزات MSA استنادًا إلى ميزات النموذج الكبيرة، ودمجها من خلال LSTM، وإجراء تدريب تحت الإشراف. يجمع نموذج SESNet الذي طورته مجموعة البحث الخاصة بنا في العام الماضي بين ميزات التسلسل الخاصة بـ ESM-1b، والميزات الهيكلية لـ ESM-IF، وميزات MSA لأداء التنبؤ باللياقة البدنية الخاضعة للإشراف.
مقدمة إلى طريقة FSFP: طريقة تعلم نموذجية صغيرة لإدارة دورة حياة المنتج
أهمية التعلم باستخدام عينة صغيرة للتنبؤ باللياقة البدنية
قبل تقديم طريقة FSFP، من الضروري توضيح أهمية التعلم بالعينة الصغيرة في التنبؤ باللياقة البدنية. على الرغم من أن الأساليب غير الخاضعة للإشراف لا تتطلب بيانات مصنفة للتدريب، إلا أن دقة تسجيل الأهداف من الصفر أقل. بالإضافة إلى ذلك، نظرًا لأن النتائج المبنية على نسب الاحتمال اللوغاريتمي لا يمكنها أن تعكس إلا بعض القوانين الطبيعية للبروتينات، فمن الصعب أيضًا التنبؤ بشكل فعال بالخصائص غير الطبيعية للبروتينات.

من ناحية أخرى، على الرغم من دقة طرق التعلم الخاضعة للإشراف، إلا أنها تتطلب بيانات تجريبية واسعة النطاق للتدريب لتحسين الأداء بشكل كبير بسبب العدد الهائل من معلمات إدارة دورة حياة المنتج. يتضمن تقييم نماذج التعلم الخاضع للإشراف عمومًا تقسيم مجموعة البيانات عالية الإنتاجية الموجودة إلى 8:2، في حين أن مجموعة التدريب الخاصة بـ 80% قد تحتوي بالفعل على عشرات الآلاف من البيانات، وهو أمر مكلف للغاية للحصول عليه في الممارسة العملية.
لتناول هذه المشكلة، نقترح طريقة FSFP، وهي طريقة تعلم صغيرة النطاق لإدارة دورة حياة المنتج. يمكن أن تعمل هذه الطريقة على تحسين أداء التنبؤ باللياقة البدنية لـ PLM بشكل كبير باستخدام عدد صغير من عينات التدريب (العشرات). في الوقت نفسه، تعتبر طريقة FSFP مرنة للغاية ويمكن تطبيقها على أنظمة إدارة دورة حياة المنتج المختلفة.
طريقة FSFP: تصنيف التعلم من أجل اللياقة البدنية
اعتبرت جميع طرق التعلم الإشرافي السابقة التنبؤ باللياقة البدنية بمثابة مشكلة انحدار، أي تحسين النموذج عن طريق حساب خطأ التربيع المتوسط (MSE) بين مخرجات النموذج وعلامة اللياقة البدنية. ومع ذلك، في ظل ظروف العينة الصغيرة، يكون من السهل جدًا الإفراط في ملاءمة نموذج الانحدار وتنخفض خسارة التدريب بسرعة كبيرة. ولذلك، قمنا بتغيير تفكيرنا ولم نقم بالانحدار، بل قمنا بدلاً من ذلك بالتعلم التصنيفي، والذي يتطلب فقط الفرز الدقيق ولا يتطلب ملاءمة دقيقة للقيم العددية.
يتمتع هذا النهج بميزتين رئيسيتين. أولا، يلبي التسلسل نفسه الاحتياجات الأساسية للهندسة البروتينية، والتي تتطلب فقط قياس الفعالية النسبية للطفرات. ثانياً، مهمة الترتيب أسهل من التنبؤ بالقيم المطلقة.
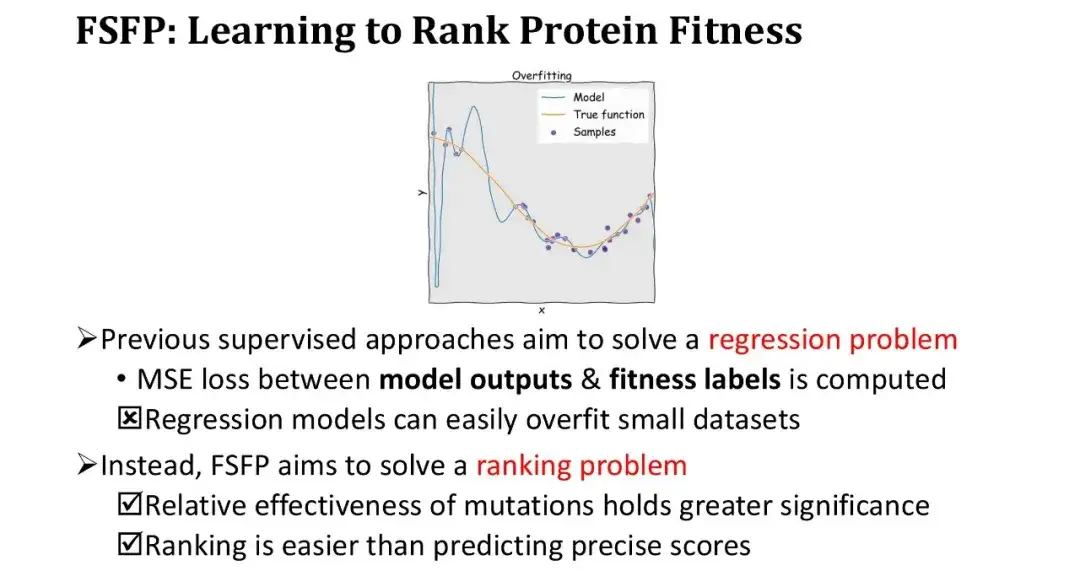
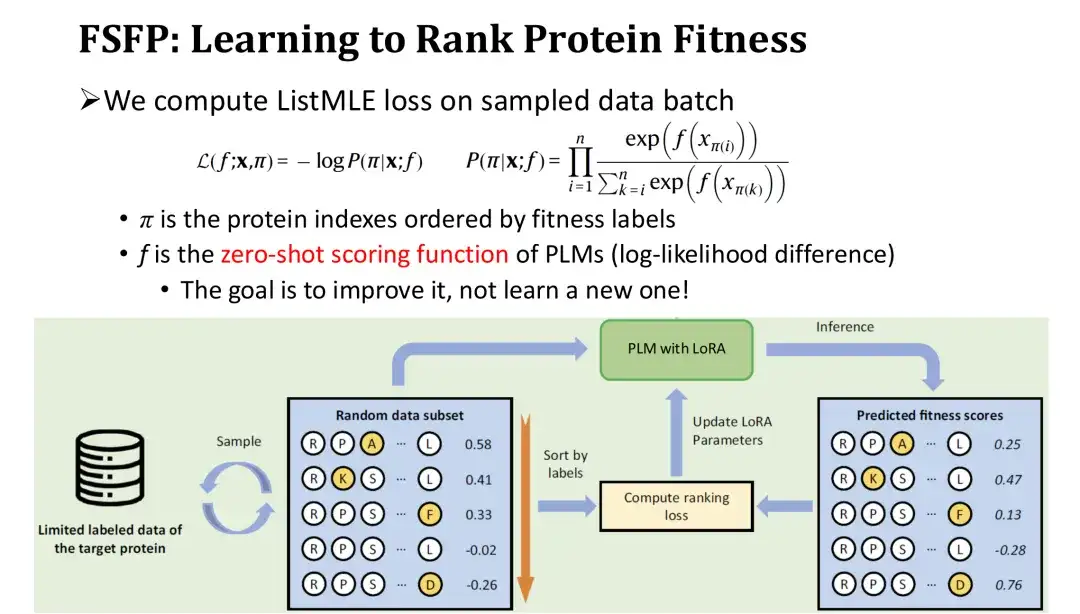
في تكرار التدريب، نقوم بفرز مجموعة العينات من الطفرات بالترتيب العكسي وفقًا لعلاماتها، ثم نحسب خسارة الترتيب - ListMLE استنادًا إلى قيم التنبؤ الخاصة بالنموذج لهذه الطفرات.كلما اقترب ترتيب القيم المتوقعة للنموذج من الترتيب الحقيقي، كلما كانت الخسارة أصغر. ومن بينها، نستخدم دالة التسجيل ذات اللقطة الصفرية استنادًا إلى نسبة الاحتمال اللوغاريتمي كدالة تسجيل f للنموذج للطفرة. الغرض من ذلك هو استخدام تسجيل النقاط من الصفر كنقطة بداية وتصحيحها تدريجيًا باستخدام بيانات التدريب لتحسين الأداء دون إعادة تهيئة الوحدة، وبالتالي تقليل صعوبة التدريب.
طريقة FSFP: ضبط دقيق لمعاملات إدارة دورة حياة المنتج (PLM) بكفاءة
نظرًا لأن عدد المعلمات في PLM عادةً ما يصل إلى مئات الملايين، فإن ضبط النموذج بالكامل باستخدام القليل جدًا من البيانات سيؤدي حتماً إلى الإفراط في التجهيز.ولذلك، قدمنا تقنية ثانية، LoRA، للحد من عدد المعلمات القابلة للتدريب في النموذج.
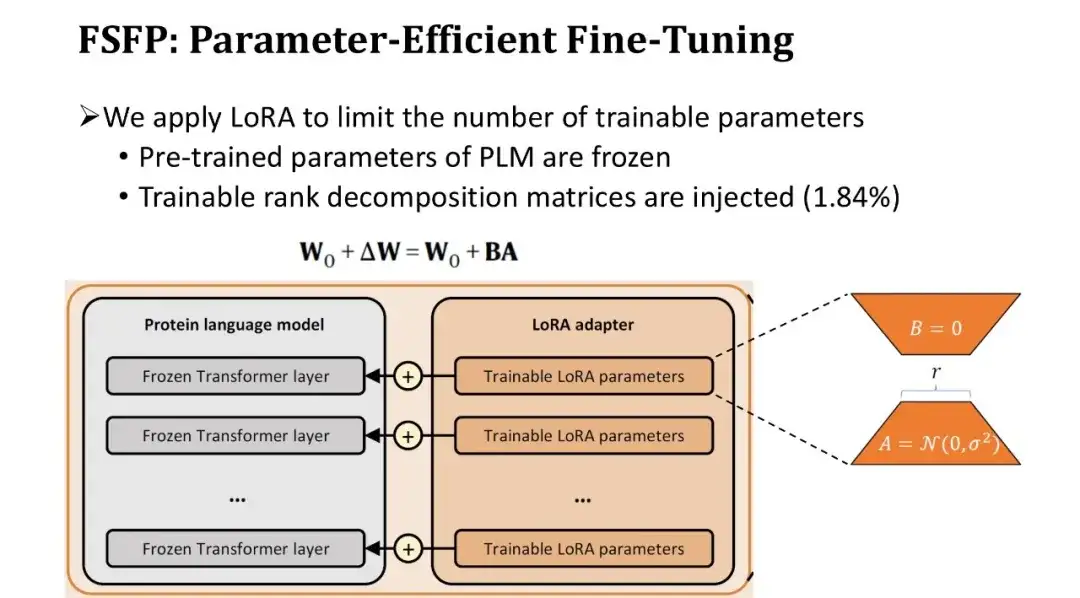
يقوم LoRA بإدراج زوج من مصفوفات تحليل الرتبة القابلة للتدريب في الطبقة المتصلة بالكامل لكل كتلة من Transformer، مع الحفاظ على المعلمات المدربة مسبقًا دون تغيير. نظرًا لأن مصفوفة تحلل الرتبة صغيرة جدًا، فمن الممكن تقليل عدد المعلمات القابلة للتدريب إلى 1.84% الأصلي. على الرغم من تقليل عدد المعلمات القابلة للتدريب، إلا أن قدرة التعلم للنموذج لا تزال مضمونة لأن كل طبقة من المحول يتم ضبطها بدقة.
طريقة FSFP: تطبيق التعلم الفوقي على التنبؤ باللياقة البدنية
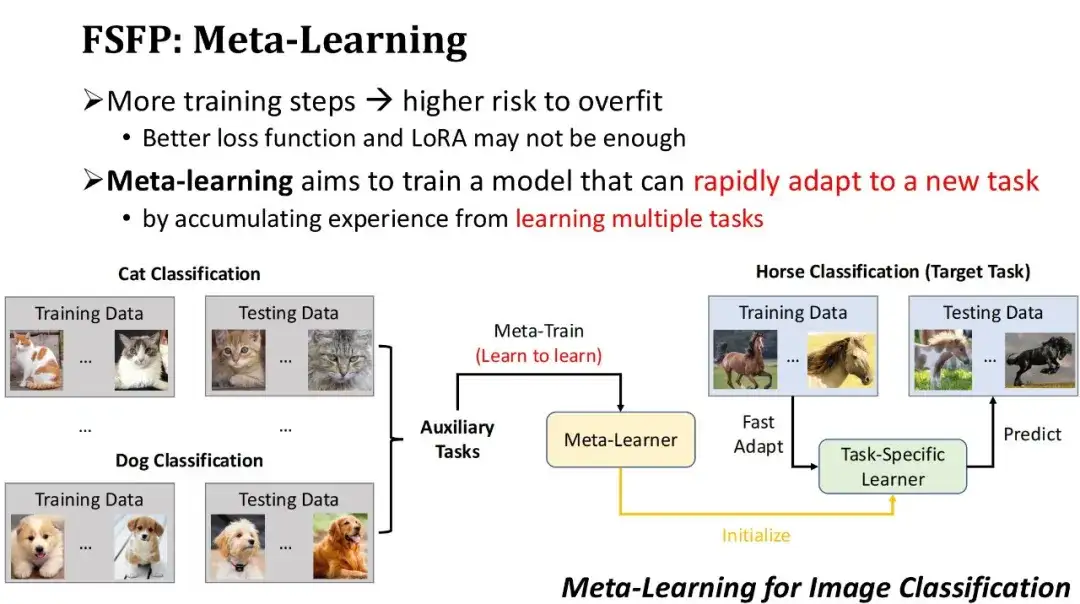
لتجنب الإفراط في التجهيز، لم نستخدم دالة خسارة أفضل فحسب، بل قمنا أيضًا بتقييد كمية المعلمات القابلة للتدريب من خلال تقنية LoRA. ومع ذلك، لا يزال هناك خطر الإفراط في التجهيز إذا تم تنفيذ عدد كبير جدًا من تكرارات التدريب على بيانات تدريب عينة صغيرة. لذلك، نأمل في تحسين أداء النموذج بسرعة باستخدام عدد أقل من تكرارات التدريب.وبناء على هذه الحاجة، اعتمدنا التكنولوجيا الثالثة – التعلم الفوقي. الفكرة الأساسية للتعلم الفوقي هي السماح للنموذج أولاً بتجميع الخبرة في بعض المهام المساعدة للحصول على نموذج أولي، ثم استخدام النموذج الأولي للتكيف بسرعة مع المهام الجديدة.
كما هو موضح في الشكل أدناه، هذا مثال لتصنيف الصور استنادًا إلى التعلم التلوي. لنفترض أن المهمة المستهدفة هي تدريب نموذج لتصنيف الخيول، ولكن هناك بيانات مصنفة حول الخيول قليلة نسبيًا. لذلك، يمكننا أولاً العثور على بعض المهام المساعدة مع كمية كبيرة من البيانات، مثل تصنيف القطط، وتصنيف الكلاب، وما إلى ذلك، واستخدام خوارزميات التعلم الفوقي للتدريب على هذه المهام المساعدة، وتعلم كيفية تعلم مهام جديدة، والحصول على متعلم فوقي. بعد ذلك، باستخدام هذا المتعلم المتطور كنموذج أولي وتدريبه لعدة خطوات باستخدام كمية صغيرة من بيانات الخيول المصنفة، يمكن الحصول على مصنف الخيول بسرعة. من الواضح أن الشرط الأساسي لنجاح التعلم الفوقي هو أن تكون المهام المساعدة المستخدمة قريبة بدرجة كافية من المهام المستهدفة.
كيفية تطبيق التعلم الفوقي على سيناريو التنبؤ باللياقة البدنية؟أولاً وقبل كل شيء، هدفنا هو تصنيف طفرات البروتين المستهدف حسب اللياقة البدنية، والنموذج الذي سيتم تدريبه هو PLM باستخدام تقنية LoRA.
نحن نتبع استراتيجيتين لبناء المهام المساعدة. الطريقة الأولى هي العثور على مجموعات بيانات تجربة الطفرة للبروتينات المماثلة في قاعدة بيانات DMS الموجودة بناءً على التشابه مع البروتين المستهدف، وتحديد أول مجموعتي بيانات كمهمتين مساعدتين.نقطة البداية للقيام بذلك هي أن نأخذ في الاعتبار أن المشهد اللياقة البدنية للبروتينات المماثلة متشابه أيضًا.
الاستراتيجية الثانية هي استخدام نموذج MSA لتسجيل الطفرات المرشحة للبروتين المستهدف لتشكيل مجموعة بيانات شبه وسم واستخدامها كمهمة مساعدة ثالثة.السبب وراء اختيارنا لنموذج MSA هو أن تأثير التنبؤ بالطفرة في نموذج MSA لا يكون عادةً أقل من تأثير نموذج PLM. نأمل في إجراء تحسين للبيانات من خلال MSA وإعطاء اللعب الكامل لقدرة التمثيل لـ PLM.
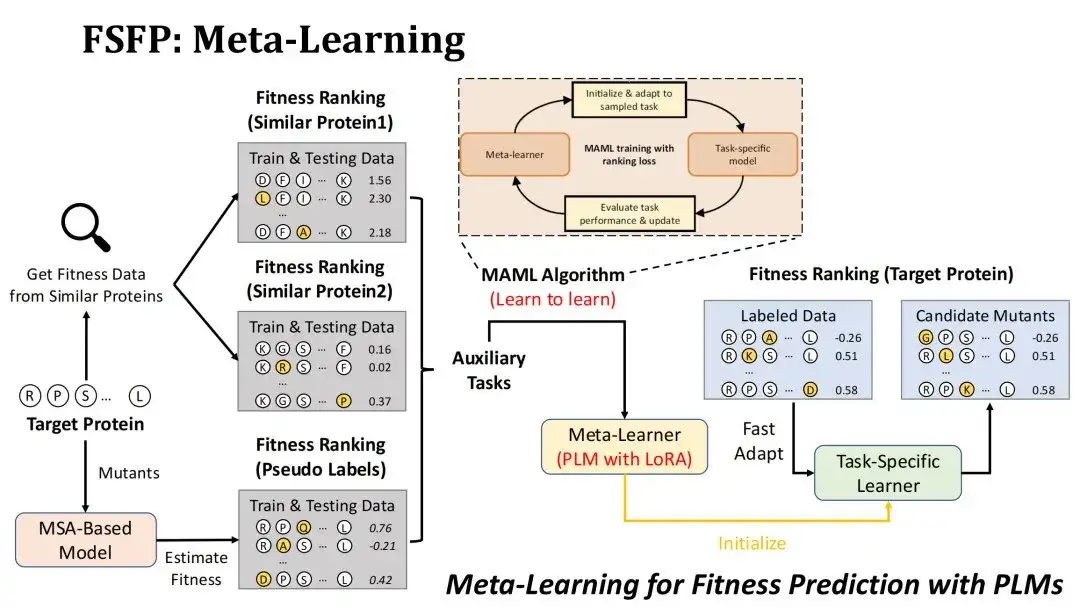
خوارزمية التعلم الفوقي التي نستخدمها هي MAML، والتي يهدف تدريبها إلى جعل خسارة اختبار المتعلم الفوقي صغيرة قدر الإمكان بعد ضبط k خطوة بدقة مع بيانات تدريب مهمة مساعدة، بحيث يمكن أن تتقارب تقريبًا بعد ضبط k خطوة بدقة على المهمة المستهدفة.
تقييم أداء طريقة FSFP في التنبؤ بصحة البروتين
إنشاء معيار
تأتي بياناتنا المعيارية من ProteinGym، والتي كانت تحتوي في الأصل على 87 مجموعة بيانات DMS وتم تحديثها الآن إلى 217.يتم تقسيم البروتينات المقابلة لـ 87 DMSs تقريبًا إلى أربع فئات: حقيقيات النوى، وبدائيات النوى، والبشر، والفيروسات، وتغطي ما مجموعه حوالي 15 مليون طفرة واللياقة المقابلة.
بالنسبة لكل مجموعة بيانات، قمنا باختيار 20 و40 و60 و80 و100 طفرة نقطية واحدة بشكل عشوائي كمجموعات تدريب عينة صغيرة، وتم استخدام الطفرات المتبقية كمجموعات اختبار. تجدر الإشارة إلى أننا لم نستخدم مجموعة تحقق إضافية للتوقف المبكر، ولكن بدلاً من ذلك قمنا بتقدير عدد خطوات التدريب من خلال التحقق المتبادل على مجموعة التدريب.

وقد ذكرنا سابقًا أن التعلم الفوقي يتطلب ثلاث مهام مساعدة، اثنتان منها يتم استرجاعهما من قاعدة بيانات DMS بناءً على تشابههما مع البروتين المستهدف.عند التدريب على مجموعة بيانات، نقوم بالاسترجاع من بقية مجموعات البيانات في ProteinGym، على افتراض أنها قاعدة البيانات.
كما هو موضح في الشكل الموجود على اليمين أدناه، يتم استخدام كل بروتين في ProteinGym كاستعلام، ويتم استرجاع توزيع التشابه للبروتينات الأكثر تشابهًا من خلال MMseqs2 وFoldSeek على التوالي. ويمكن ملاحظة أن متوسط التسلسل أو التشابه البنيوي للبروتينات الأكثر تشابهًا هو حوالي 0.5. تتضمن المهمة المساعدة الثالثة تسجيل الطفرات باستخدام نموذج MSA. لقد اخترنا نموذج GEMME، الذي يبني شجرة تطورية على أساس MSA ويحسب الحفاظ على كل نقطة على الشجرة التطورية لتسجيل الطفرة.
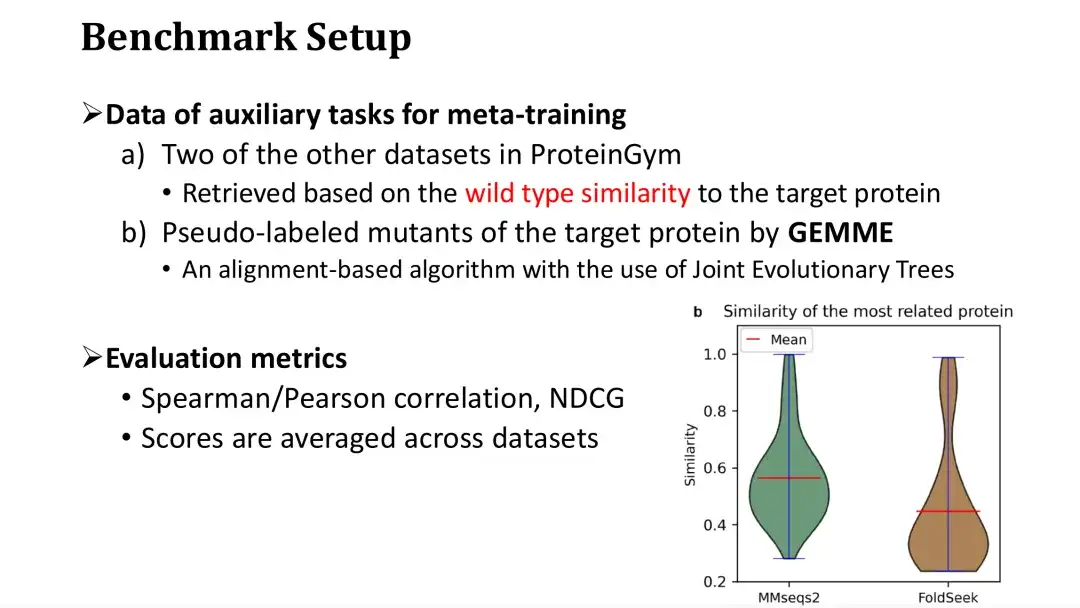
مؤشرات التقييم المستخدمة هي معامل سبيرمان/بيرسون وNDCG، وهي معايير تقييم شائعة في مهام التنبؤ باللياقة البدنية. النتيجة النهائية للتقييم هي متوسط النتيجة على 87 مجموعة بيانات.
تجربة استئصال FSFP على ESM-2
كما هو موضح في الشكل أدناه، يمثل المحور x في الشكل الأيسر حجم مجموعة التدريب، ويمثل المحور y معامل سبيرمان، ويتوافق كل خط مع تكوين نموذج مختلف. يمثل الخط العلوي نموذج FSFP الكامل؛ يمثل السطر الثاني استبدال المهمة المساعدة الثالثة للتعلم التلوي ببيانات DMS لبروتينات مماثلة دون استخدام MSA. يمكن ملاحظة أن أداء النموذج ينخفض بعد إزالة معلومات MSA؛ يمثل الخط الثالث عدم استخدام التعلم الفوقي، والاعتماد فقط على التعلم التصنيفي وLoRA، وينخفض معامل سبيرمان بشكل أكبر.
يمثل الخط الأخضر نموذج الانحدار التلالي الذي تم نشره سابقًا في NBT، وهو أحد النماذج الأساسية القليلة المناسبة حاليًا لسيناريوهات العينات الصغيرة؛ يمثل الخط المنقط الرمادي درجة الصفر لـ ESM-2؛ يمثل الخطان السفليان نتائج تدريب ESM-2 باستخدام طرق الانحدار التقليدية.
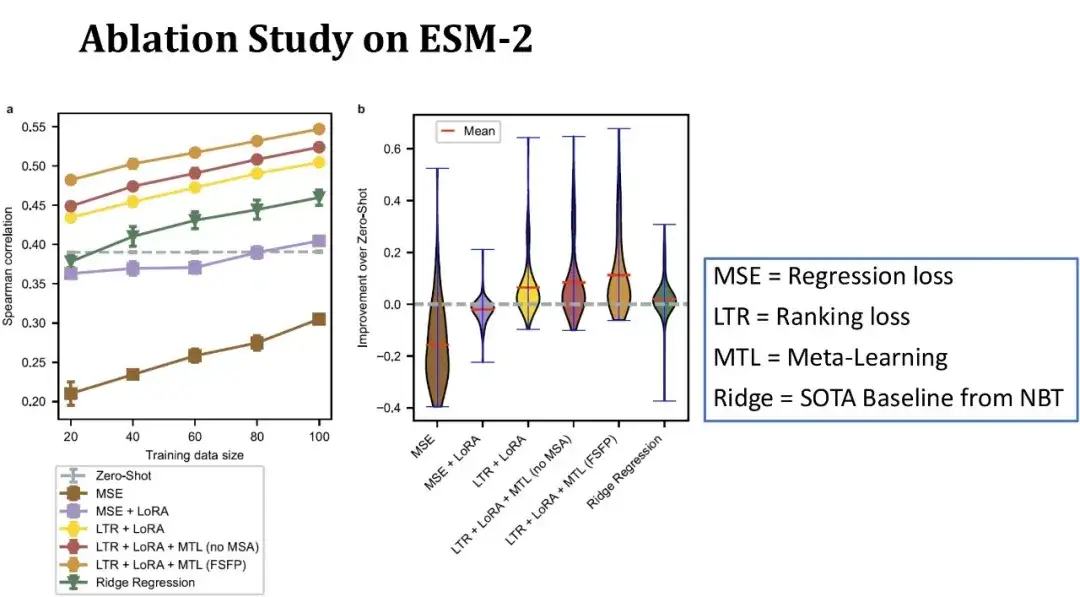
بشكل عام، عندما يكون هناك 20 عينة تدريب فقط، تعمل طريقتنا على تحسين Spearman بمقدار 10 نقاط مقارنةً باللقطة الصفرية، وتلعب كل وحدة دورًا إيجابيًا في أداء النموذج. يوضح الشكل الموجود على اليمين توزيع تحسين الأداء مقارنةً باللقطة الصفرية على 87 مجموعة بيانات، مع حجم مجموعة تدريب يبلغ 40 عينة.يمكننا أن نرى أن طريقتنا قادرة على تحسين أداء النموذج في معظم مجموعات البيانات، بل إن التحسن في بعض مجموعات البيانات يتجاوز 40 نقطة، مما يدل على أداء أكثر استقرارًا من الأداء الأساسي.
فعالية التعلم الفوقي
الهدف من التعلم الفوقي هو تمكين PLM من التقارب بسرعة مع المهمة المستهدفة مع عدد صغير من التكرارات.وفيما يلي بعض الأمثلة لتوضيح ذلك.
تُظهر الرسوم البيانية الثلاثة التالية منحنيات التدريب للضبط الدقيق على 3 مجموعات بيانات باستخدام 40 عينة تدريب. يمثل المحور x عدد خطوات التدريب، ويمثل المحور y معامل سبيرمان في مجموعة الاختبار. الخطوط البرتقالية والحمراء في الأعلى عبارة عن نماذج تم تدريبها باستخدام التعلم الفوقي، حيث يستخدم الأول لغة الاستعلامات البنيوية لبناء المهام المساعدة، بينما لا يستخدم الثاني ذلك. يمثل الخط الأصفر النموذج الذي يستخدم فقط التعلم من أجل الترتيب وLoRA دون التعلم الفوقي.
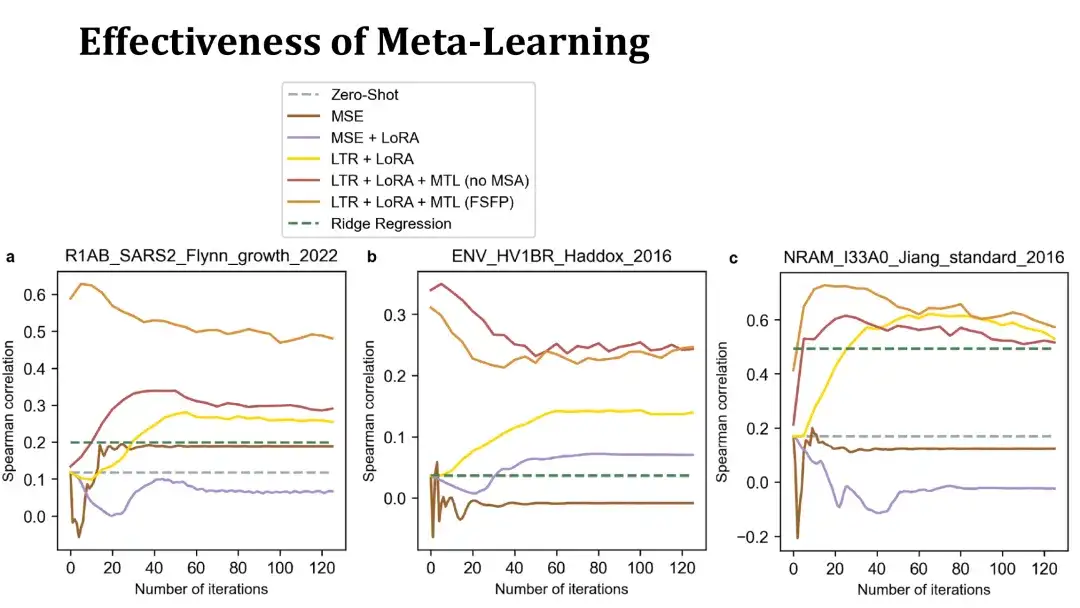
كما ترون،يمكن للنماذج المدربة باستخدام التعلم التلوي تحسين الأداء على البروتينات المستهدفة بسرعة أكبر والوصول إلى درجات أعلى في غضون 20 خطوة، وفي بعض الأحيان تتفوق على النموذج الأولي دون ضبط دقيق. ويشير هذا إلى أن التعلم الفوقي ينتج نموذجًا أوليًا فعالًا.يؤدي النموذج المبني على MSE أدناه أداءً ضعيفًا ويتجاوز الحد بسرعة، مما يجعل من الصعب تجاوز طريقة اللقطة الصفرية.
نتائج تطبيق FSFP على أنظمة إدارة دورة حياة المنتج المختلفة
لقد قمنا باختيار ثلاثة PLMs نموذجية وهي ESM-1v وESM-2 وSaProt.يستخدم النموذجان الأولان معلومات تسلسل البروتين فقط، بينما يجمع SaProt بين رموز البنية الثلاثية للبروتين.
يوضح الرسم البياني الخطي الموجود على اليسار درجة سبيرمان للتنبؤ بتأثير طفرة نقطية واحدة تحت أحجام مختلفة لمجموعة التدريب. يمثل اللون نفسه نفس النموذج، وتمثل الأشكال المختلفة للنقاط أساليب تدريب مختلفة. تمثل النقاط أعلاه طريقة FSFP، ويمثل المثلث المقلوب أدناه الانحدار التلالي، ويمثل الخط المنقط أداء النموذج بدون أي أخطاء. يمثل الخط الأرجواني نموذج GEMME، وهو ليس نموذج PLM، ولكن يمكن دمج طريقة الانحدار التلالي معه.يمكن ملاحظة أن طريقة FSFP يمكنها تحسين أداء كل PLM بشكل مطرد، وهي أفضل بكثير من الانحدار التلالي واللقطة الصفرية للنموذج المقابل.
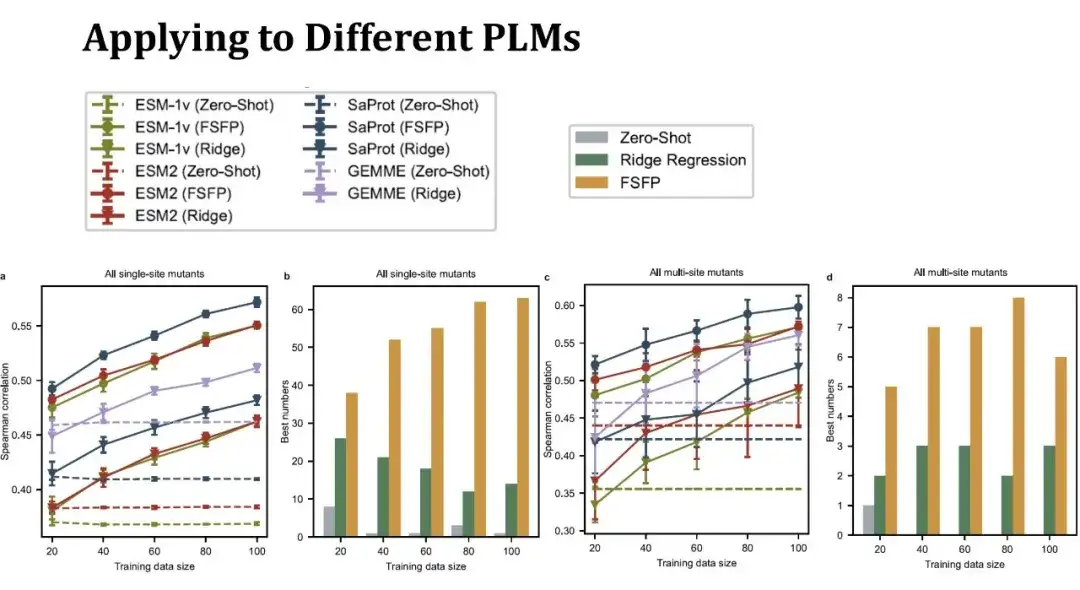
يوضح الرسم البياني الشريطي الثاني عدد أعلى الدرجات التي تم الحصول عليها باستخدام الاستراتيجيات الثلاث (الضربة الصفرية، والانحدار التلالي، وFSFP) على مجموعات بيانات مختلفة. يحقق FSFP أفضل أداء في معظم مجموعات البيانات.الشكلان الموجودان على اليمين يوضحان أداء التنبؤ بالطفرات متعددة النقاط. هناك 11 مجموعة بيانات لطفرة متعددة النقاط متضمنة، والاستنتاجات التي تم الحصول عليها مماثلة لتلك التي تم الحصول عليها من الطفرات ذات النقطة الواحدة. ومع ذلك، فإن نموذج الانحدار التلالي لديه تباين أكبر هنا، مما يشير إلى أنه حساس لتقسيم البيانات.
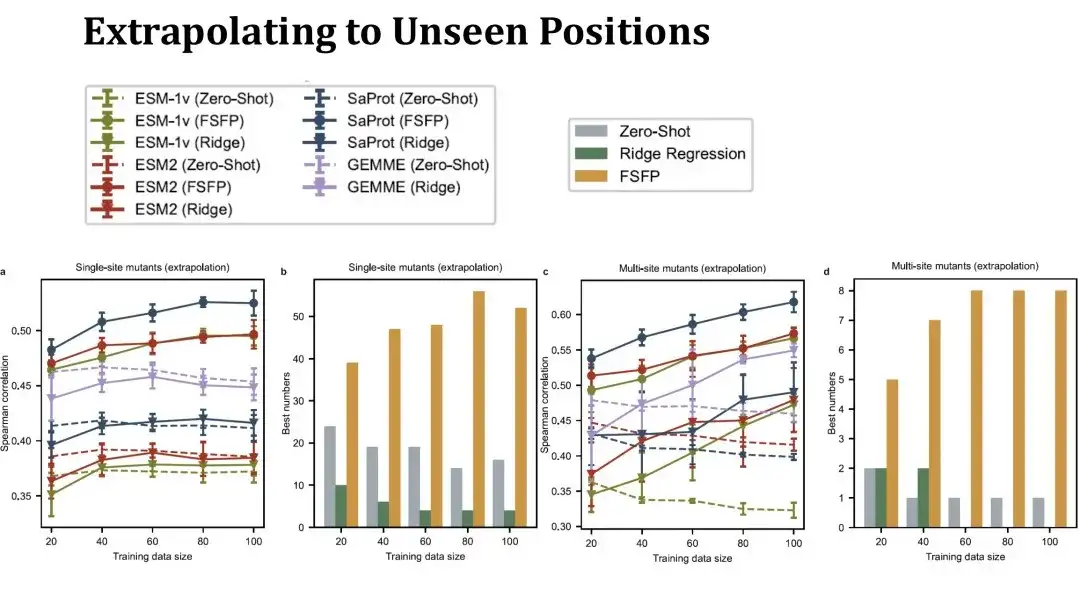
لقد قمنا بعد ذلك بتقييم أداء استقراء FSFP، وتحديدًا تقييم أداء التنبؤ في مواقع الطفرة التي لم يتم رؤيتها في مجموعة التدريب.. في هذه الحالة، ستكون مجموعة الاختبار أصغر بكثير من ذي قبل، وستتغير مجموعة الاختبار بشكل كبير مع تزايد حجم مجموعة التدريب، وبالتالي فإن أداء اللقطة الصفرية في الجدول لم يعد خطًا مستقيمًا. هذا الإعداد أكثر تحديًا. يمكننا أن نرى أن أداء الانحدار التلالي للطفرة ذات النقطة الواحدة على اليسار لا يمكن أن يتجاوز اللقطة الصفرية، ولكن لا يزال بإمكان FSFP تحسين الأداء بشكل مطرد. وتظهر نتائج اختبار الطفرات متعددة النقاط على اليمين أيضًا أن أسلوب التدريب لدينا يتمتع بقدرة تعميم جيدة.
تحويل Phi29 باستخدام FSFP
بالإضافة إلى ذلك، استخدمنا أيضًا FSFP لإجراء دراسة حالة حول تعديل البروتين.البروتين المستهدف هو Phi29، وهو بوليميراز DNA، ونأمل في تحسين Tm الخاص به من خلال طفرة نقطة واحدة.
تتم العملية التجريبية على النحو التالي: أولاً، استخدم ESM-1v لإجراء تسجيل طلقة صفرية على الطفرات المشبعة ذات النقطة الواحدة، واختر أفضل 20 طفرة وقم بإجراء تجارب رطبة لقياس Tm؛ ثم استخدم هذه البيانات التجريبية العشرين كمجموعة تدريب، واستخدم FSFP لتدريب ESM-1v، واستخدم النموذج المدرب لتسجيل الطفرات المفردة المشبعة مرة أخرى، ثم أعد تحديد أفضل 20 طفرة للاختبار.
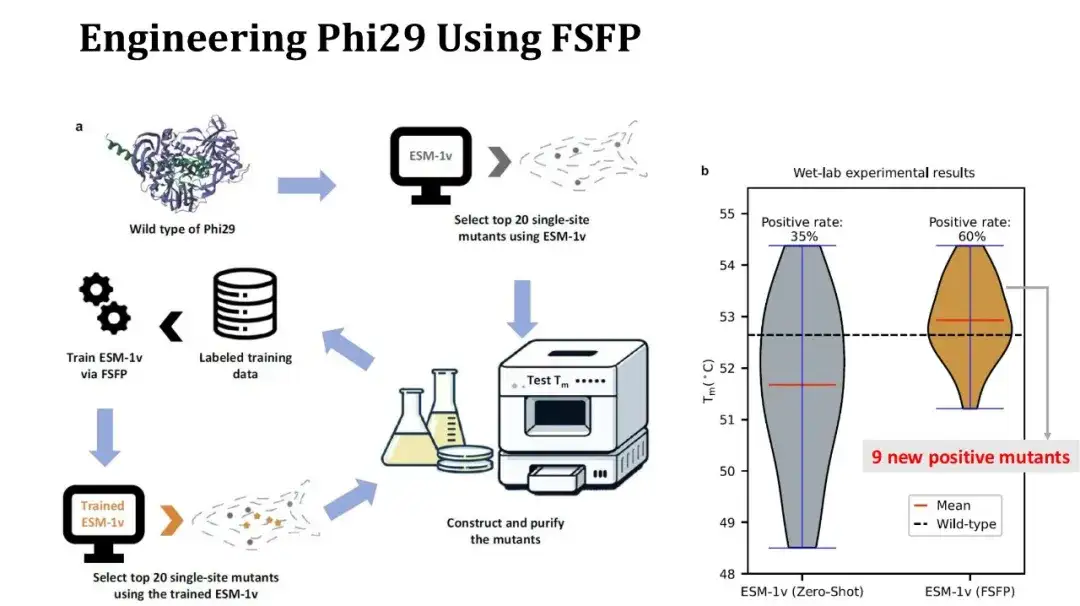
يوضح الشكل الموجود على اليمين مقارنة توزيع Tm قبل وبعد الجولتين من التجارب. كانت سبعة من أصل 20 طفرة في الجولة الأولى إيجابية، وارتفعت إلى 12 في الجولة الثانية، وزاد متوسط Tm بمقدار درجة واحدة. ومن بينها، 9 من الطفرات الإيجابية التي تم العثور عليها في الجولة الثانية كانت جديدة. وعلى الرغم من تحسن المعدل الإيجابي ومتوسط Tm، إلا أن أعلى Tm للأسف لم يرتفع لأن الطفرة ذات أعلى Tm التي تم الحصول عليها في الجولة الثانية لا تزال موجودة في نتائج الجولة الأولى. ومع ذلك، نظرًا لأنه تم الحصول على المزيد من الطفرات الإيجابية في النقطة الواحدة، فيمكننا محاولة الجمع بين هذه المواقع لإجراء تجارب الطفرات ذات النقطة العالية لتحسين Tm بشكل أكبر.
ملخص لمنهجية FSFP وآفاق البحث المستقبلية
FSFP هي استراتيجية تعلم عينة صغيرة لـ PLM، والتي يمكنها تحسين أداء PLM بشكل كبير في التنبؤ بتأثير الطفرة باستخدام عدد صغير (عشرات) من عينات التدريب المسمى، ويمكن تطبيقها بشكل مرن على مجموعة متنوعة من PLMs المختلفة.تظهر التجارب أن تصميم FSFP معقول:
* يلبي التعلم التصنيفي المتطلبات الأساسية لتصنيف الطفرات في هندسة البروتين ويقلل من صعوبة التدريب؛
* يقلل LoRA من خطر الإفراط في التجهيز من خلال التحكم في كمية المعلمات القابلة للتدريب في PLM؛
* يمكن أن يوفر التعلم الفوقي معلمات أولية جيدة للنموذج، مما يتيح للنموذج الانتقال بسرعة إلى المهمة المستهدفة.

وأخيرًا، نناقش الاتجاهات المستقبلية للتطور الموجه بمساعدة الذكاء الاصطناعي. تتمثل العملية العامة للتطور الموجه بمساعدة الذكاء الاصطناعي في البدء بمجموعة من الطفرات الأولية، والحصول على علامات اللياقة البدنية الخاصة بها من خلال التجارب الرطبة، واستخدام البيانات المصنفة التي تم إرجاعها من التجارب لتدريب نموذج التعلم الآلي. بعد ذلك، يتم اختيار الجولة التالية من الطفرات التي سيتم اختبارها بناءً على توقعات النموذج، ويتم تكرار العملية.
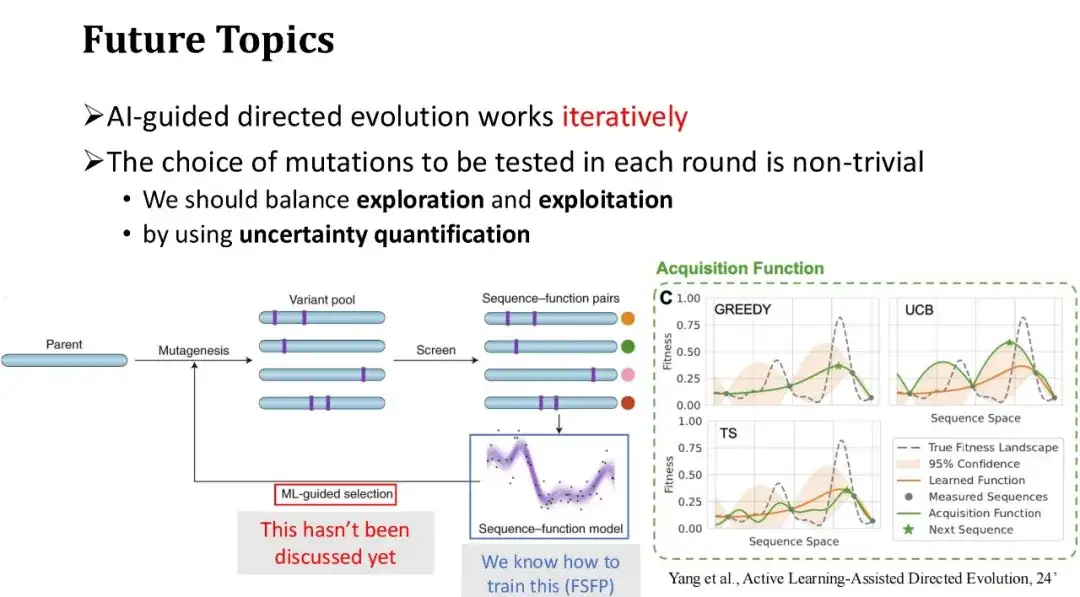
يحل FSFP بشكل أساسي مشكلة تدريب العينة الصغيرة للنموذج في كل جولة من التكرار التجريبي ويحسن دقة التنبؤ بالنموذج.ولكننا لم نناقش بعد كيفية اختيار الطفرات التي سيتم اختبارها في الجولة التالية بشكل فعال، أي عينات التدريب الجديدة التي سيتم إضافتها في الجولة التالية. في المثال السابق لتعديل بروتين Phi29، قمنا باختيار أفضل 20 طفرة ذات أعلى درجات النموذج بشكل مباشر. ومع ذلك، في سيناريو تكراري متعدد الجولات، فإن استراتيجية الاختيار الجشعة ليست بالضرورة أفضل طريقة، لأنها عرضة للوقوع في المثالية المحلية. ولذلك، لا بد من إيجاد التوازن بين الاستكشاف والاستغلال.
في الواقع، تعد عملية اختيار عينات الاختبار بشكل متكرر لوضع العلامات عليها وتوسيع بيانات التدريب تدريجيًا مشكلة تعلم نشطة، مما أدى إلى تحقيق بعض التقدم البحثي في مجال هندسة البروتين. على سبيل المثال، تناقش فرانسيس إتش أرنولد، وهي خبيرة في التطور الموجه، قضايا ذات صلة في مقالتها "التطور الموجه بمساعدة التعلم النشط".
عنوان الورقة:
https://www.biorxiv.org/content/10.1101/2024.07.27.605457v1.full.pdf
يمكننا استخدام تقنيات تحديد كمية عدم اليقين لتقييم عدم اليقين في درجة النموذج لكل متحولة. وبناءً على هذه الشكوك، ستكون استراتيجية اختيار عينات الاختبار أكثر تنوعًا.. الاستراتيجية المستخدمة بشكل شائع هي طريقة UCB، والتي تختار عينات الطفرة ذات أعلى درجة عدم يقين في التنبؤ بالنموذج للجولة التالية من التوضيح، أي أنها تعطي الأولوية للعينات ذات أكبر تباين في التنبؤ. وهذا يشبه عملية التعلم البشري: إذا لم يكن لدينا فهم جيد لبعض نقاط المعرفة أو كنا غير متأكدين منها، فسوف نركز على تعزيز تعلمنا.








