Command Palette
Search for a command to run...
لا وقت لمشاهدة الأفلام أو المسلسلات التلفزيونية، حيث تقوم الذكاء الاصطناعي بتحويل الأفلام والمسلسلات التلفزيونية إلى قصص مصورة بنقرة واحدة

ما هو نوع العملية السحرية لتحويل فيلم أو مسلسل تلفزيوني إلى قصة مصورة؟ اقترح فريق من جامعة داليان للتكنولوجيا وجامعة مدينة هونج كونج مؤخرًا إطار عمل للذكاء الاصطناعي يمكنه تحويل الأفلام والمسلسلات التلفزيونية تلقائيًا إلى قصص مصورة. من الآن فصاعدا، هناك طريقة أخرى لمشاهدة الأفلام والمسلسلات التلفزيونية.
في الوقت الحاضر، أصبحت الأفلام والمسلسلات التلفزيونية ومقاطع الفيديو المختلفة جزءًا لا غنى عنه من حياتنا. تشير التقارير إلى أن إجمالي طول مقاطع الفيديو التي يتم تحميلها على موقع يوتيوب كل يوم قد يستغرق من الشخص أكثر من 82 عامًا لمشاهدتها.
من أجل توفير الوقت في مشاهدة المسلسلات التلفزيونية، أصبح التشغيل بسرعة 2x هو المعيار لمشاهدة المسلسلات التلفزيونية بشراهة.بالإضافة إلى المشاهدة بسرعة مضاعفة، وبطريقة متقطعة، والاستماع إلى تعليقات نقاد السينما، هناك طريقة أخرى لمواكبة المسلسلات التلفزيونية بسرعة، وهي تحويل المسلسلات التلفزيونية إلى قصص مصورة.
في الآونة الأخيرة، نشر باحثون من جامعة داليان للتكنولوجيا وجامعة مدينة هونج كونج دراسة مثيرة للاهتمام يمكنها توليد صور تلقائيًا من المسلسلات التلفزيونية أو الأفلام أو مقاطع الفيديو الأخرى في شكل كوميدي وإضافة فقاعات نصية.

وقال الباحثون في بحثهم: "بالمقارنة مع أنظمة إنتاج القصص المصورة الحديثة، فإن نظامنا قادر على إنتاج قصص مصورة أكثر تعبيرا وجاذبية". "في المستقبل، سيتم توسيع نطاق هذه التكنولوجيا لإنشاء القصص المصورة باستخدام المعلومات النصية."
لقد شاهدت تعديلات للقصص المصورة، لكن هل شاهدت "قصصًا مصورة مقتبسة" من قبل؟
في السابق، كانت هناك بعض نتائج الأبحاث المماثلة في الصناعة، والتي اقترحت أنظمة آلية لتحويل مقاطع الفيديو إلى قصص مصورة، ولكن لا يزال هناك مجال للتحسين من حيث الأتمتة والمؤثرات البصرية وسهولة القراءة وما إلى ذلك. لذلك، لا يزال هذا الاتجاه البحثي مليئًا بالتحديات.
نشر فريق من جامعة داليان للتكنولوجيا وجامعة مدينة هونج كونج مؤخرًا ورقة بحثيةإنشاء قصص مصورة تلقائيًا بتصميمات متعددة الصفحات ونصوص تفاعليةتم اقتراح طريقة أفضل في .

عنوان الورقة: https://arxiv.org/abs/2101.11111
تقترح الورقة نظامًا لإنشاء القصص المصورة آليًا بالكامل.لا حاجةمن خلال أي تعديلات يدوية يقوم بها المستخدم، يمكن إنشاء أي نوع من الفيديو (مسلسلات تلفزيونية، أفلام، رسوم متحركة) في صفحات هزلية عالية الجودة ويمكن تحويل حوارات الشخصيات إلى نص فقاعي.علاوة على ذلك، تتمتع القصص المصورة التي ينتجها النظام بتأثيرات بصرية غنية وسهلة القراءة.
ثلاث وحدات لتحويل الدراما السينمائية والتلفزيونية إلى كتب مصورة
الفكرة الرئيسية المقترحة في هذه الورقة هي أنتصميم الأنظمة بطريقة آلية بالكامل دون أي معلمات أو قيود محددة يدويًا.وفي الوقت نفسه، قدم الفريق تفاعلات المستخدم بشكل انتقائي لجعل التصميم أكثر تخصيصًا وتنوعًا.
بشكل عام، يتكون النظام من ثلاث وحدات رئيسية:اختيار الإطار الرئيسي وتصميم القصص المصورة، وإنشاء تخطيط متعدد الصفحات، وإنشاء فقاعة نصية ووضعها.
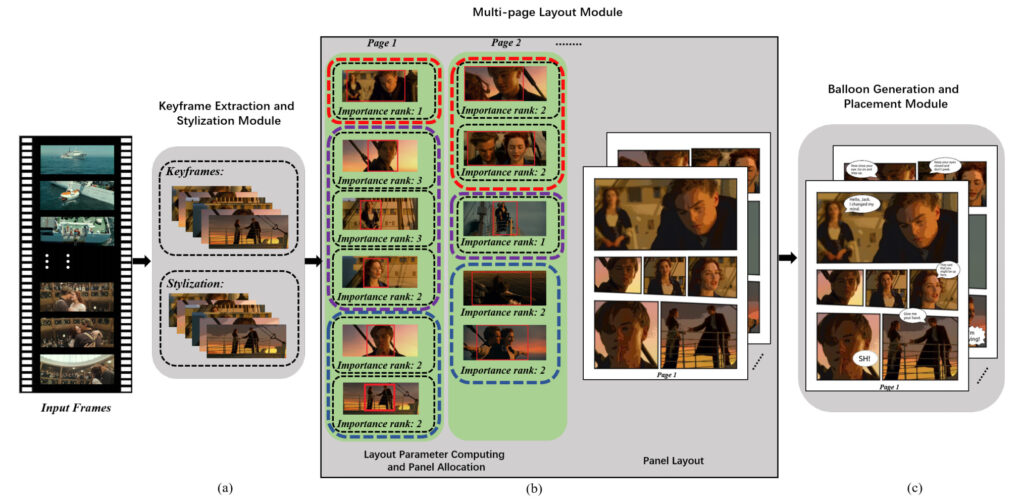
الوحدة 1: استخراج الإطارات الرئيسية وتنسيقها
مدخلات النظام هي مقطع فيديو وترجماته، والتي تحتوي على حوارات ومعلومات طابع زمني بداية ونهاية المقابلة.
قاموا أولاً باختيار إطار من الفيديو الأصلي كل 0.5 ثانية، ثم استخدموا المعلومات الزمنية في الترجمة والتشابه بين إطارين متتاليين لاختيار إطارات رئيسية إعلامية. وأخيرًا، يتم تصميم الإطارات الرئيسية، أي تحويل الصور العادية إلى صور ذات طابع كوميدي.
استخراج الإطارات الرئيسية
يعد اختيار الإطارات الرئيسية مهمة صعبة ومهمة بشكل خاص. يستخدم الفريق بشكل أساسي معلومات الوقت لإجراء الاختيار.

كما هو موضح في الشكل أعلاه، استخدم الفريق أولاً وقت البداية والنهاية لكل عنوان فرعي لتقسيم الفيديو إلى لقطات متعددة. تنقسم هذه اللقطات إلى نوعين: لقطات حوارية (لقطات مع ترجمة) ولقطات غير حوارية (لقطات بدون ترجمة).
للقطات الحوارية:يقوم النظام بحساب تشابه GIST بين إطارين متتاليين تم الحصول عليهما مسبقًا (إذا كان تشابه GIST صغيرًا، فإن الفرق بين الإطارين يكون كبيرًا).
أثناء التنفيذ، إذا كان التشابه أقل من قيمة العتبة المحددة مسبقًا ?1، فسيتم تحديد الإطار التالي كإطار رئيسي.إذا لم يتم تحديد أي من الإطارات المقابلة لمجموعة من الترجمات، فسيتم تحديد الإطار الأوسط كإطار رئيسي.
وباعتبار أن الحوار المستمر والمشهد نفسه قد يتوافقان مع ترجمات متعددة، قام الفريق بحساب تشابه GIST بين الإطارات الرئيسية المتتالية التي تم الحصول عليها مسبقًا. إذا كان التشابه أكبر من الحد المحدد ?2، فسيتم اعتبارهما ينتميان إلى نفس المشهد. ثم، فقط احتفظ بواحدة من الإطارات الرئيسية ودمج الترجمة.
بالإضافة إلى ذلك، في نفس مجموعة الترجمات، قد يقوم النظام باختيار إطارات رئيسية متعددة لأنه بعد الحساب، قد نجد أن هذه الإطارات الرئيسية لها علاقات دلالية وسيتم استخدام هذه الإطارات الرئيسية لتخطيط متعدد الصفحات.
بالنسبة للقطات غير الحوارية:يتم أولاً تحديد الإطارات الأقل تطابقًا مع الإطارات الموجودة في اللقطة الحالية. من أجل تقليل التكرار في الإطارات المحددة، سيقوم النظام بحساب تشابه GIST بين هذه اللقطة والإطار الرئيسي المحدد مسبقًا. سيتم تحديده كإطار رئيسي فقط عندما يكون أقل من الحد الأدنى المحدد مسبقًا.
أخيرًا، يتم تجميع مجموعات الترجمة عن طريق مقارنة أوقات البدء وأوقات الإطارات الرئيسية. سيتم جمع أي ترجمات تقع ضمن نطاق الطابع الزمني لبداية ونهاية إطار رئيسي معًا.
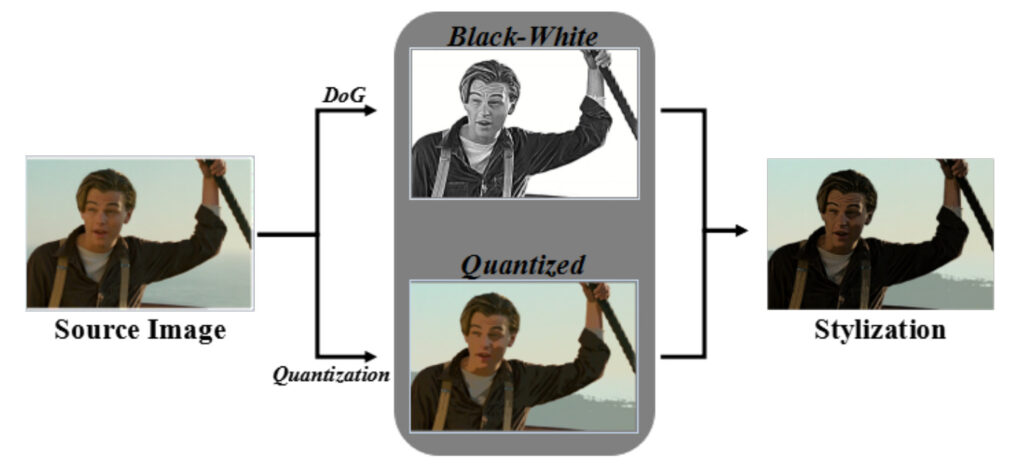
صورة منمقة
استخدم الفريق طريقة الفرق الموسعة في Gaussian لتحويل الصور المصدرية إلى صور بالأبيض والأسود. بعد تناول الوجبة، يتم إجراء كمية الألوان على 128 مستوى للحصول على الصورة الكمية وتحقيق أسلوب الألوان. هكذا هي الحال، سلسلة من لقطات الأفلام الواقعية تحولت إلى أسلوب كوميدي.
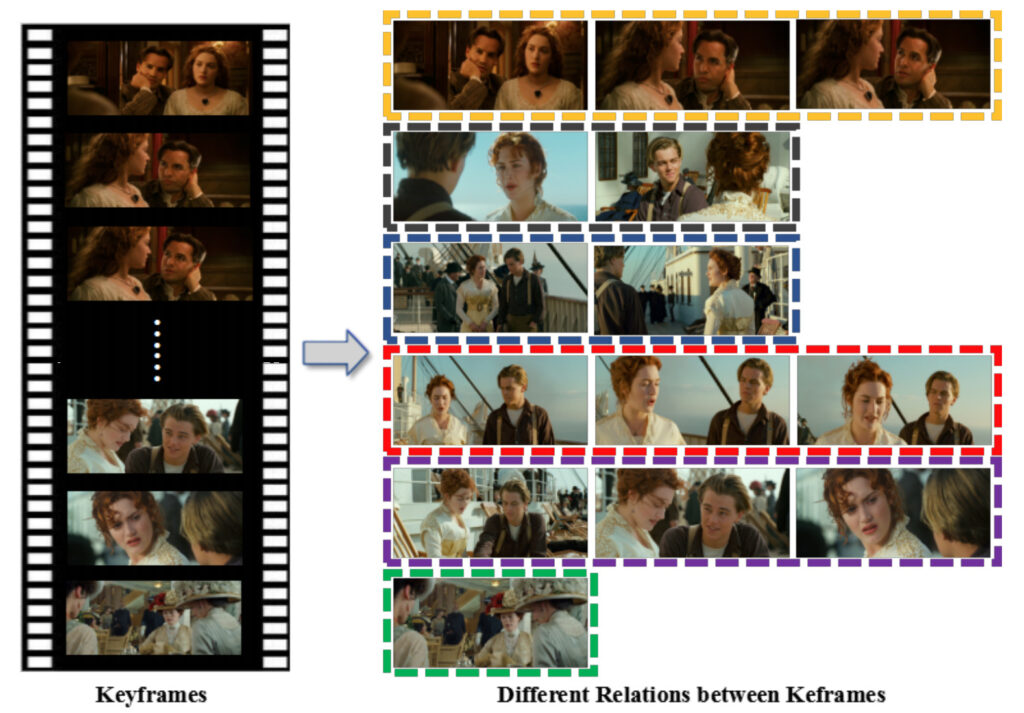
الوحدة 2: تخطيط متعدد الصفحات
اقترح الفريق إطار عمل تخطيط متعدد الصفحات لتخصيص تخطيطات الصفحات وتنظيمها تلقائيًا مع تقديم تأثيرات بصرية أكثر ثراءً.
في هذه الوحدة، نحتاج أولاً إلى حساب أربعة عوامل رئيسية لتوجيه إنشاء تخطيطات متعددة الصفحات، بما في ذلك: منطقة الاهتمام (ROI) للإطارات الرئيسية، ومستوى أهمية الإطارات الرئيسية، والعلاقة الدلالية بين الإطارات الرئيسية، وعدد الألواح على الصفحة.
ثم اقترح الفريق طريقة تعيين لوحة تعتمد على التحسين لتعيين الإطارات الرئيسية لتسلسل الصفحات واستخدم طريقة تجميع تخطيط القصص المصورة القائمة على البيانات لتوليد تخطيط كل صفحة.
الأصدقاء الذين يتابعون القصص المصورة يعرفون أن عدد الإطارات في كل صفحة من الكتاب الهزلي ليس ثابتًا. من أجل توفير تجربة قراءة أفضل للقراء، سيقوم رسامو الكاريكاتير بترتيب عدد الإطارات وفقًا للحبكة.
وفي هذه الدراسة، تعامل الفريق مع هذه المشكلة باعتبارها مشكلة تحسين عالمية لاستكمال تخصيص كل لقطة في صفحة القصص المصورة.
الوحدة 3: إنشاء فقاعات النص ووضعها
إنشاء فقاعات نصية
عادةً في القصص المصورة، يختار المؤلف أشكال فقاعات مختلفة للحوارات في مواقف وعواطف مختلفة، وهو أمر مهم جدًا للتعبير عن محتوى القصص المصورة. ومع ذلك، فإن الدراسات ذات الصلة الموجودة تستخدم عمومًا أشكال الفقاعات الإهليلجية الأساسية فقط، والتي ليست غنية بما يكفي للتعبير عن المشاعر.
ومن النتائج المهمة التي تم اقتراحها في هذه الورقة البحثية طريقة توليد الفقاعات بالاعتماد على إدراك المشاعر، والتي يمكنها استخدام الصوت والفيديو ومعلومات الترجمة التي تحتوي على المشاعر لتوليد أشكال فقاعات نصية مناسبة لها.

في هذا النظام، اعتمد المؤلف ثلاثة أشكال شائعة للفقاعات: الفقاعات البيضاوية، والفقاعات الفكرية، والفقاعات المسننة. الأنواع الثلاثة من الفقاعات مناسبة للمشاعر التالية: المشاعر الهادئة، والأفكار (غير المعلنة)، والمشاعر القوية.
بالنسبة لتدريب مصنف الفقاعات، استخدم الفريق بشكل أساسي بعض مقاطع فيديو الأنمي والكتب المصورة المقابلة لجمع البيانات حول المشاعر الصوتية ومشاعر الترجمة وأنواع الفقاعات.
تحديد موضع الفقاعات ووضعها
على غرار الطريقة السابقة، يستخدم هذا البحث أيضًا اكتشاف المتحدث واكتشاف حركة الشفاه للحصول على موضع الشخص الذي يتحدث في الإطار، ثم يضع البالون بالقرب من الشخص الذي ينتمي إليه.
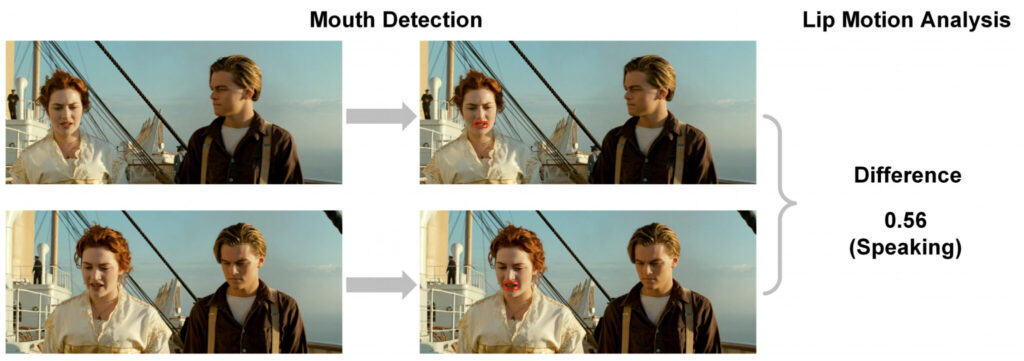
تتم عملية التنفيذ المحددة على النحو التالي:
- أولاً، استخدم مكتبة "Dlib" لاكتشاف الوجه في Python لاكتشاف فم كل حرف في الإطار؛
- ومن ثم يتم استخدام تحليل حركة الشفاه لحساب متوسط الفرق المربع لقيم البكسل في منطقة الفم بين إطارين متتاليين. يتم حساب الفرق في منطقة البحث حول منطقة الفم في الإطار الحالي لتحديد ما إذا كانت الشفاه تتحرك؛
- أخيرًا، قم بتعيين حد لتحديد ما إذا كانت الشخصية تتحدث أم لا.
بمجرد تحديد موقع المتحدث، ضع فقاعة النص بالقرب منه، مع توجيه ذيل الفقاعة نحو فم المتحدث.
استخدم أربعة أفلام كلاسيكية لتقييم تأثير النظام
لاختبار النموذج، قام الفريق بإدخال 16 مقطعًا من أربعة أفلام مختلفة: تيتانيك، والرسالة، والأصدقاء، وفي الهواء.
تراوحت مدة مقاطع الفيديو المدخلة بين دقيقتين إلى 6 دقائق، واحتوى كل مقطع على جزء من الحوار.
بالنسبة لكل مقطع، سجل الفريق المدة التي استغرقها إنشاء كتاب هزلي باستخدام النظام، وقاموا بحساب متوسط الوقت المستغرق لتقييم أداء النظام.

وخلص الباحثون إلى أن طريقة هذه الدراسة متفوقة على الطرق الأخرى مقارنة بالطرق السابقة. ويتجلى ذلك بشكل رئيسي في الجوانب الثلاثة التالية:
- أولاً، يستطيع النظام إنشاء أشكال فقاعات أكثر ثراءً للمحادثات، في حين تستخدم الطرق الحالية فقط بالونات الكلمات البيضاوية البسيطة؛
- ثانيًا، باستخدام طريقة تلخيص النص، يتم دمج بعض العناوين الفرعية ذات الصلة، مما يضمن عدم طول الجمل في فقاعات النص بشكل كبير وتعزيز قابلية القراءة؛
- ثالثًا، من خلال الحصول تلقائيًا على أربعة معلمات مهمة، يتم تحقيق تخطيط متعدد الصفحات تلقائيًا بالكامل (كانت الطرق السابقة شبه آلية في الغالب وتتطلب تدخلًا يدويًا)، وتكون نتائج التخطيط معقولة وغنية.

لتجنب تدخل العوامل الذاتية، قام الفريق أيضًا بتجنيد 40 متطوعًا من خلال Amazon Mechanical Turk لمقارنة النتائج التي أنشأها الفريق مع تلك التي أنشأتها أنظمة أخرى مماثلة.
قام المتطوعون أولاً بمشاهدة الفيديو الأصلي، ثم قرأوا القصص المصورة التي تم إنشاؤها باستخدام طرق مختلفة وأعطوا تقييمًا للتأثير. لتجنب التحيز الذاتي، تم ترتيب مقاطع الفيديو والرسوم المتحركة المقابلة لها بشكل عشوائي.
وكانت النتيجة النهائية هي أن النظام حصل على تقييمات أفضل من الطرق الأخرى، بغض النظر عما إذا كان المتطوعون قد شاهدوا مقاطع الفيديو من قبل أم لا.
إنشاء القصص المصورة بنقرة واحدة، ماذا يمكنك أن تفعل أيضًا؟
على الرغم من حصوله على تقييمات إيجابية من المستخدمين، إلا أن النظام بالتأكيد ليس مثاليًا ولا يزال هناك بعض المشكلات التي تحتاج إلى حل.
على سبيل المثال، عند تحديد الإطارات الرئيسية، قد يظل هناك موقف حيث يكون التشابه مرتفعًا للغاية، مما يؤدي إلى التكرار في الصورة.
بالإضافة إلى ذلك، إذا لم يكن الفيديو المدخل يحتوي على ترجمات، فيجب على النظام أولاً استخراج السطور من خلال التعرف على الصوت قبل إنشاء القصص المصورة. ومع ذلك، فإن نتائج التعرف على الصوت غالباً ما تكون عرضة للأخطاء، لذا فإن هذا أيضاً يشكل تحدياً يواجه النظام. ومع ذلك، قال الفريق إنهم يعتقدون أنه مع التقدم المستمر في تكنولوجيا التعرف على الكلام، سيتم حل هذه المشكلة في المستقبل.
في المستقبل، عندما تصبح هذه التكنولوجيا ناضجة بما فيه الكفاية، فإن العديد من أعمال الفيديو ستحتوي على طريقة إضافية لفتحها. إن "مشاهدة" فيلم على شكل قصص مصورة قد يفتح مجالاً أكبر للخيال لدى القراء.

بالإضافة إلى ذلك، يمكن للأشخاص العاديين تحويل مقاطع الفيديو إلى قصص مصورة بسهولة دون أن تكون لديهم أي مهارات في الرسم. قد يصبح هذا أداة ترفيه جماعية جديدة تمامًا مثل تطبيق Prisma الذي يمكنه تحويل الصور إلى صور بأسلوب الرسم.
ويخطط الفريق أيضًا لتوسيع هذه الطريقة لإنشاء القصص المصورة باستخدام معلومات نصية في الخطوة التالية. بمعنى آخر، طالما تم تقديم نص القصص المصورة، يمكن للنظام إنشاء القصص المصورة تلقائيًا، مما يوفر الكثير من الوقت لرسامي الكاريكاتير.

