Command Palette
Search for a command to run...
مجموعة بيانات WenetSpeech-Chuan Sichuan-Chongqing للهجة الكلامية
التاريخ
المؤسسة
رابط الورقة البحثية
الترخيص
Apache 2.0
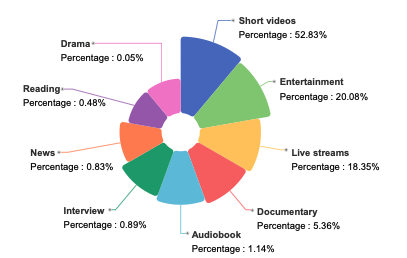
WenetSpeech-Chuan هي مجموعة بيانات واسعة النطاق للهجة سيتشوان-تشونغتشينغ، تم إصدارها عام 2025 من قبل جامعة نورث وسترن بوليتكنيكال بالتعاون مع هيلبيك، ومعهد أبحاث الذكاء الاصطناعي التابع لشركة تشاينا تيليكوم، ومؤسسات أخرى. الورقة البحثية ذات الصلة بعنوان "WenetSpeech-Chuan: مجموعة بيانات واسعة النطاق للغة السيشوانية مع شروح غنية لمعالجة الكلام اللهجي". تحتوي هذه المجموعة من البيانات على 10,013 ساعة من الكلام الأصيل بلهجتي سيتشوان وتشونغتشينغ، منها 3,714 ساعة من البيانات المصنفة بدقة عالية و6,299 ساعة من البيانات المصنفة بشكل أقل دقة. تغطي البيانات تسعة سيناريوهات واقعية، حيث تمثل مقاطع الفيديو القصيرة 52,831 ساعة، بينما تشمل البيانات المتبقية الترفيه، والبث المباشر، والكتب الصوتية، والأفلام الوثائقية، والمقابلات، والأخبار، والقراءة، والمسلسلات التلفزيونية، مما يوفر توزيعًا متنوعًا وواقعيًا للكلام. يُرفق كل كلام بمعلومات تعريفية غنية، مثل محتوى النص، ومستوى الثقة، ودرجة جودة الصوت، وجنس المتحدث وعمره، وعلامات المشاعر.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.