Command Palette
Search for a command to run...
مجموعة بيانات طبية صينية حقيقية JMED
التاريخ
رابط الورقة البحثية
الترخيص
MIT
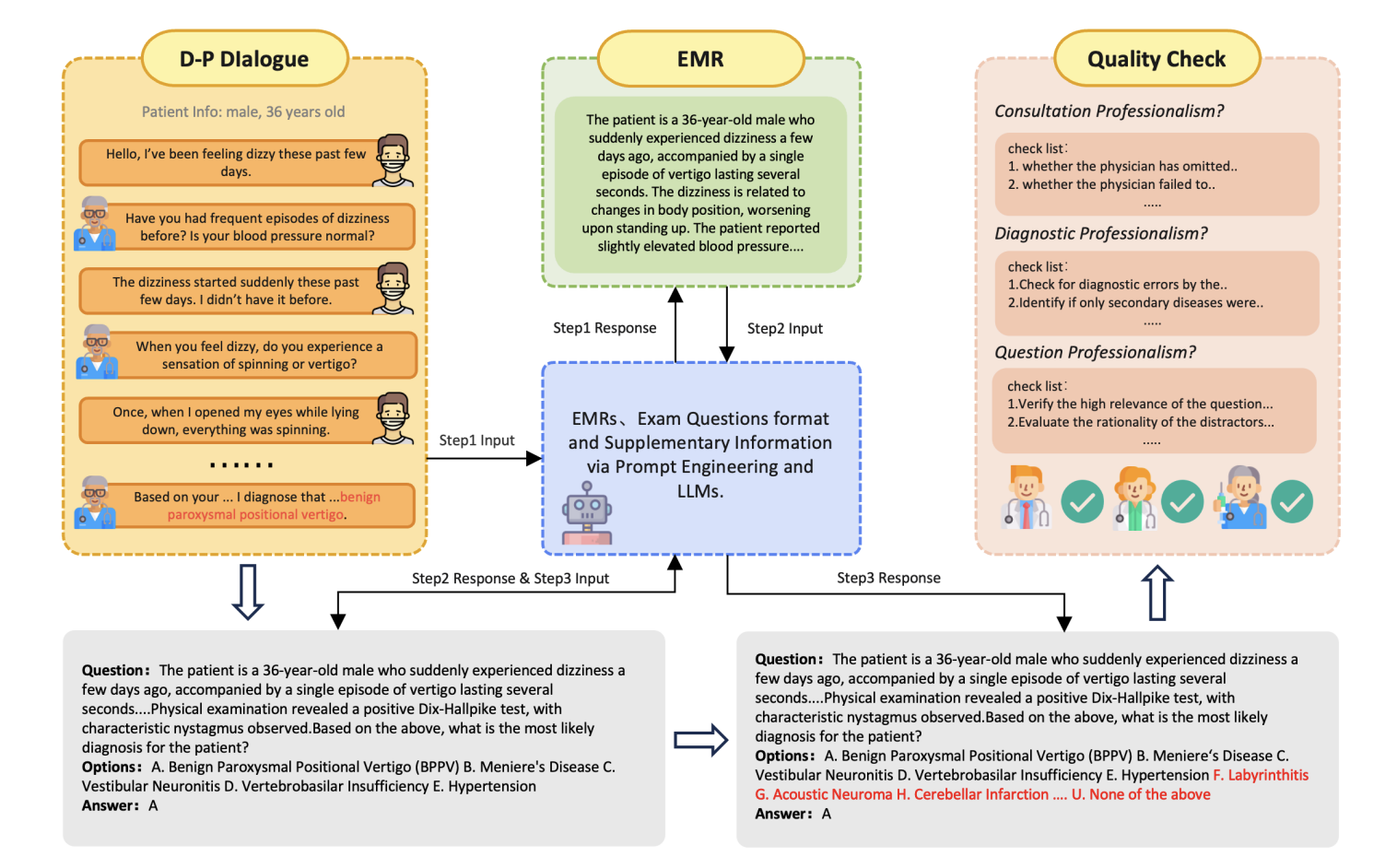
مجموعة بيانات JMED هي مجموعة بيانات جديدة تعتمد على توزيع البيانات الطبية في العالم الحقيقي. تم بناؤه بواسطة فريق الحمضيات في عام 2025. نتائج الورقة ذات الصلة هي "الحمضيات: الاستفادة من المسارات المعرفية المتخصصة في نموذج اللغة الطبية لدعم القرارات الطبية المتقدمة". يتم الحصول على مجموعة البيانات من محادثات مجهولة بين الطبيب والمريض في مستشفى JD Health على الإنترنت ويتم تصفيتها للاحتفاظ بالاستشارات التي تتبع سير عمل تشخيصي موحد. يحتوي الإصدار الأولي على 1000 سجل سريري عالي الجودة يغطي جميع الفئات العمرية (0-90 عامًا) والتخصصات المتعددة. يتضمن كل سؤال 21 خيارًا للإجابة، بما في ذلك خيار "لا شيء مما سبق". يؤدي هذا التصميم إلى زيادة تعقيد وصعوبة التمييز بين الإجابات الصحيحة بشكل كبير، وبالتالي توفير إطار تقييم أكثر صرامة. على عكس مجموعات البيانات الموجودة، يحاكي JMED البيانات السريرية الحقيقية عن كثب مع تسهيل تدريب النموذج الفعال. وعلى الرغم من أنها تستند إلى بيانات استشارية حقيقية، إلا أنها لا تأتي مباشرة من بيانات طبية فعلية، وبالتالي يمكن لفريق البحث دمج العناصر الرئيسية المطلوبة لتدريب النموذج. وبالمقارنة مع مجموعات بيانات ضمان الجودة الطبية الحالية، يتمتع JMED بثلاث مزايا رئيسية: أولاً، يعكس بشكل أكثر دقة غموض أوصاف أعراض المرضى والطبيعة الديناميكية للتشخيص السريري في السيناريوهات الحقيقية. ثانياً، تتطلب خيارات الاستجابة الموسعة مهارات تفكير متقدمة لتحديد الإجابة الصحيحة بين العديد من المشتتات. بالإضافة إلى ذلك، من خلال الاستفادة من كمية كبيرة من بيانات الاستشارة من المستشفيات الرئيسية التابعة لشركة JD، يمكننا بشكل مستمر إنشاء بيانات تتوافق مع خصائص توزيع المرضى الفعلية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.