Command Palette
Search for a command to run...
مجموعة بيانات فهم الحوار متعدد الصور متعدد الأدوار MMDU طويلة جدًا
التاريخ
الحجم
المؤسسة
عنوان URL للنشر
رابط الورقة البحثية
الترخيص
CC BY-NC-SA 3.0
الوسوم
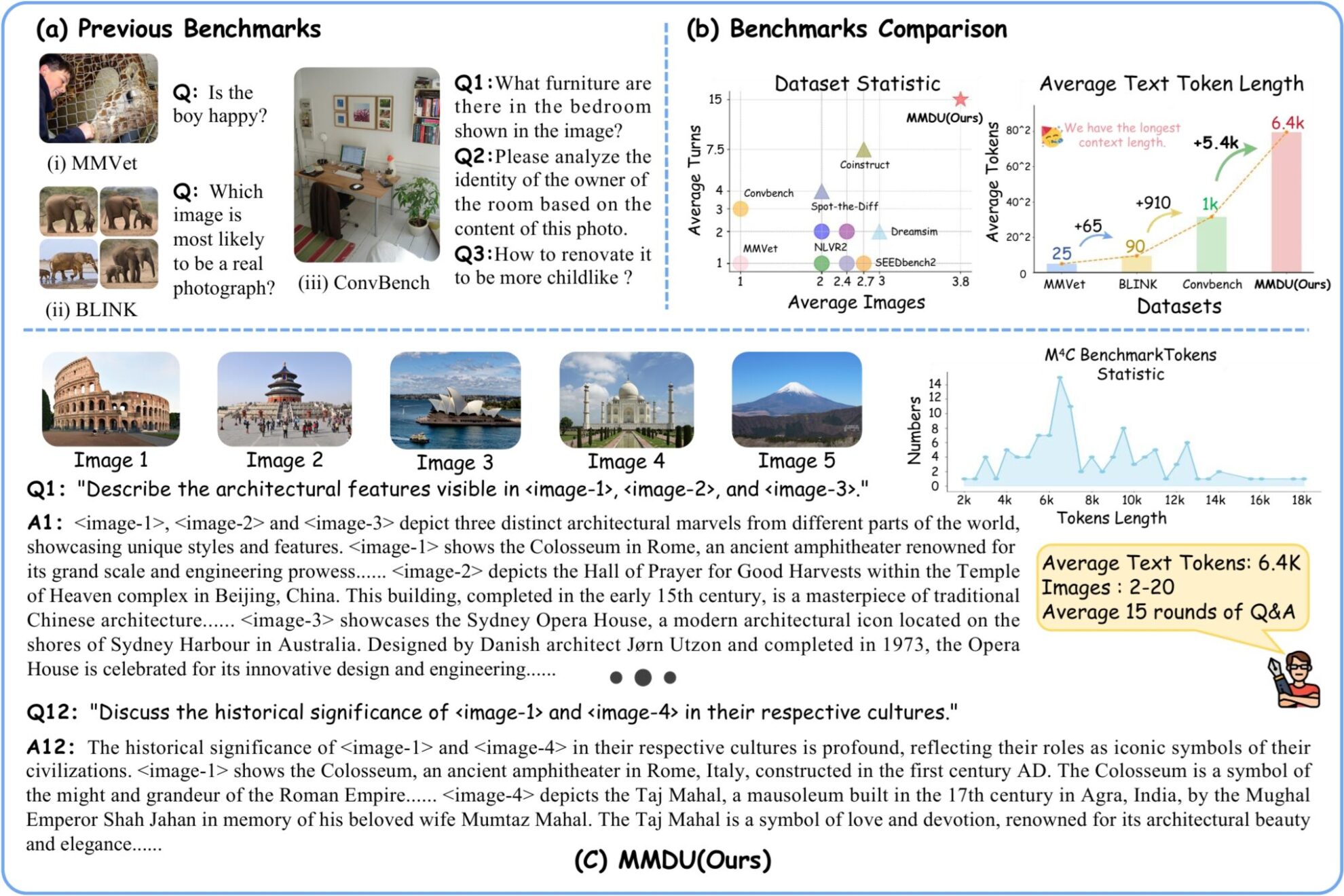
MMDU (فهم الحوار متعدد الصور متعدد الأدوار) هي مجموعة بيانات لفهم الحوار متعدد الصور متعدد الأدوار طويل للغاية تم إطلاقها بشكل مشترك من قبل جامعة ووهان ومختبر الذكاء الاصطناعي في شنغهاي وجامعة هونج كونج الصينية ومور ثريدز في عام 2024. نشر فريق البحث الورقةMMDU: مجموعة بيانات فهم معايير ضبط التعليمات وحوار متعدد الأدوار ومتعدد الصور لأجهزة LVLM"تم اقتراح معيار تقييم جديد متعدد الصور ومتعدد الجولات MMDU ومجموعة بيانات ضبط التعليمات واسعة النطاق MMDU-45k في الورقة، بهدف تقييم وتحسين أداء LVLMs في المحادثات متعددة الجولات ومتعددة الصور. يتكون المعيار من 110 حوارات عالية الجودة متعددة الصور ومتعددة الأدوار مع أكثر من 1600 سؤال، كل منها مع إجابة طويلة مفصلة. تتضمن المعايير السابقة عادةً صورة واحدة فقط أو عددًا صغيرًا من الصور، مع جولات أقل من الأسئلة وإجابات قصيرة. ومع ذلك، فإن MMDU يزيد بشكل كبير من عدد الصور وجولات الأسئلة والأجوبة وطول سياق الأسئلة والأجوبة. تتضمن المشكلات في MMUD ما بين 2 إلى 20 صورة، بمتوسط طول علامة الصورة والنص 8.2 ألف علامة وطول أقصى للصورة والنص 18 ألف علامة، مما يشكل تحديات كبيرة للنماذج واسعة النطاق متعددة الوسائط الحالية. في MMDU-45k، قام فريق البحث ببناء ما مجموعه 45 ألف حوار بيانات ضبط التعليمات. تحتوي كل البيانات في مجموعة البيانات MMDU-45k على سياق طويل للغاية، مع متوسط طول رمز الصورة والنص 5 كيلو بايت وأقصى طول رمز الصورة والنص 17 كيلو بايت. تحتوي كل محادثة على ما معدله 9 جولات من الأسئلة والأجوبة وبحد أقصى 27 جولة. بالإضافة إلى ذلك، تحتوي كل قطعة من البيانات على محتوى 2-5 صور. تم إنشاء مجموعة البيانات بتنسيق مصمم بعناية مع قابلية توسع ممتازة، ويمكن دمجها لتوليد المزيد من المحادثات الطويلة متعددة الرسوم البيانية ومتعددة الأدوار. يتجاوز طول الرسم البياني وعدد الجولات في MMDU-45k جميع مجموعات بيانات ضبط التعليمات الموجودة بشكل كبير. يعمل هذا التحسين على تحسين قدرة النموذج على التعرف على الصور المتعددة وفهمها بشكل كبير، بالإضافة إلى قدرته على التعامل مع المحادثات السياقية الطويلة. يتمتع معيار MMDU بالمزايا التالية: **(1) حوار متعدد الجولات وإدخال صور متعددة:**يتكون معيار MMDU من ما يصل إلى 20 صورة و27 جولة من حوارات الأسئلة والأجوبة، متجاوزًا العديد من المعايير السابقة ويحاكي بشكل واقعي سيناريوهات التفاعل في الدردشة في العالم الحقيقي. **(2) السياق الطويل:**يقوم معيار MMDU بتقييم قدرة LVLMs على معالجة وفهم المعلومات السياقية ذات السجلات السياقية الطويلة من خلال ما يصل إلى 18 ألف رمز نصي + صورة. **(3) التقييم المفتوح:**يبتعد نموذج MMDU عن الأسئلة المغلقة والمخرجات القصيرة (على سبيل المثال، أسئلة الاختيار من متعدد أو الإجابات القصيرة) التي تعتمد عليها معايير التقييم التقليدية، ويتبنى نهج تقييم أكثر واقعية ودقة. يقوم بتقييم أداء LVLM من خلال مخرجات متعددة الجولات ذات شكل حر، مع التركيز على قابلية التوسع وقابلية تفسير نتائج التقييم. في عملية بناء MMDU، اختار الباحثون صورًا ومعلومات نصية ذات صلة عالية من ويكيبيديا مفتوحة المصدر، وبمساعدة نموذج GPT-4o، قام المعلقون البشريون ببناء أزواج من الأسئلة والأجوبة.
الاستشهاد
@article{liu2024mmdu, title={MMDU: مجموعة بيانات معيارية لفهم الحوار متعدد الأدوار ومتعدد الصور وضبط التعليمات لـ LVLMs}, المؤلفون: {ليو، زيو وتشو، تاو وزانغ، يوهانغ ووي، شيلين ودونغ، شياويى وتشانغ، بان وليانغ، زيجيان وشيونغ، يوانجون وتشياو، يو ولين، داهوا وآخرون} journal={arXiv preprint arXiv:2406.11833}, السنة = {2024} }
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.